MMEngine理解
- 1 简介
- 2 上手示例
- 3. 基础模块
- 4. 高级模块
- 5. 恢复训练
- 6. 加速训练
- 7. 节省显存
- 8. 跨库调用模块
1 简介
- MMEngine 是一个用于深度学习模型训练的基础库,基于 PyTorch,支持在 Linux、Windows、macOS 上运行。它具有如下三个亮点:
- 通用:MMEngine 实现了一个高级的通用训练器,它能够:
- 支持用少量代码训练不同的任务,例如仅使用 80 行代码就可以训练 imagenet(pytorch example 400 行)
- 轻松兼容流行的算法库如 TIMM、TorchVision 和 Detectron2 中的模型
- 统一:MMEngine 设计了一个接口统一的开放架构,使得
- 用户可以仅依赖一份代码实现所有任务的轻量化,例如 MMRazor 1.x 相比 MMRazor 0.x 优化了 40% 的代码量
- 上下游的对接更加统一便捷,在为上层算法库提供统一抽象的同时,支持多种后端设备。目前 MMEngine 支持 Nvidia CUDA、Mac MPS、AMD、MLU 等设备进行模型训练。
- 灵活:MMEngine 实现了“乐高”式的训练流程,支持了
- 根据迭代数、 loss 和评测结果等动态调整的训练流程、优化策略和数据增强策略,例如早停(early stopping)机制等
- 任意形式的模型权重平均,如 Exponential Momentum Average (EMA) 和 Stochastic Weight Averaging (SWA)
- 训练过程中针对任意数据和任意节点的灵活可视化和日志控制
- 对神经网络模型中各个层的优化配置进行细粒度调整
- 混合精度训练的灵活控制
1.1 架构
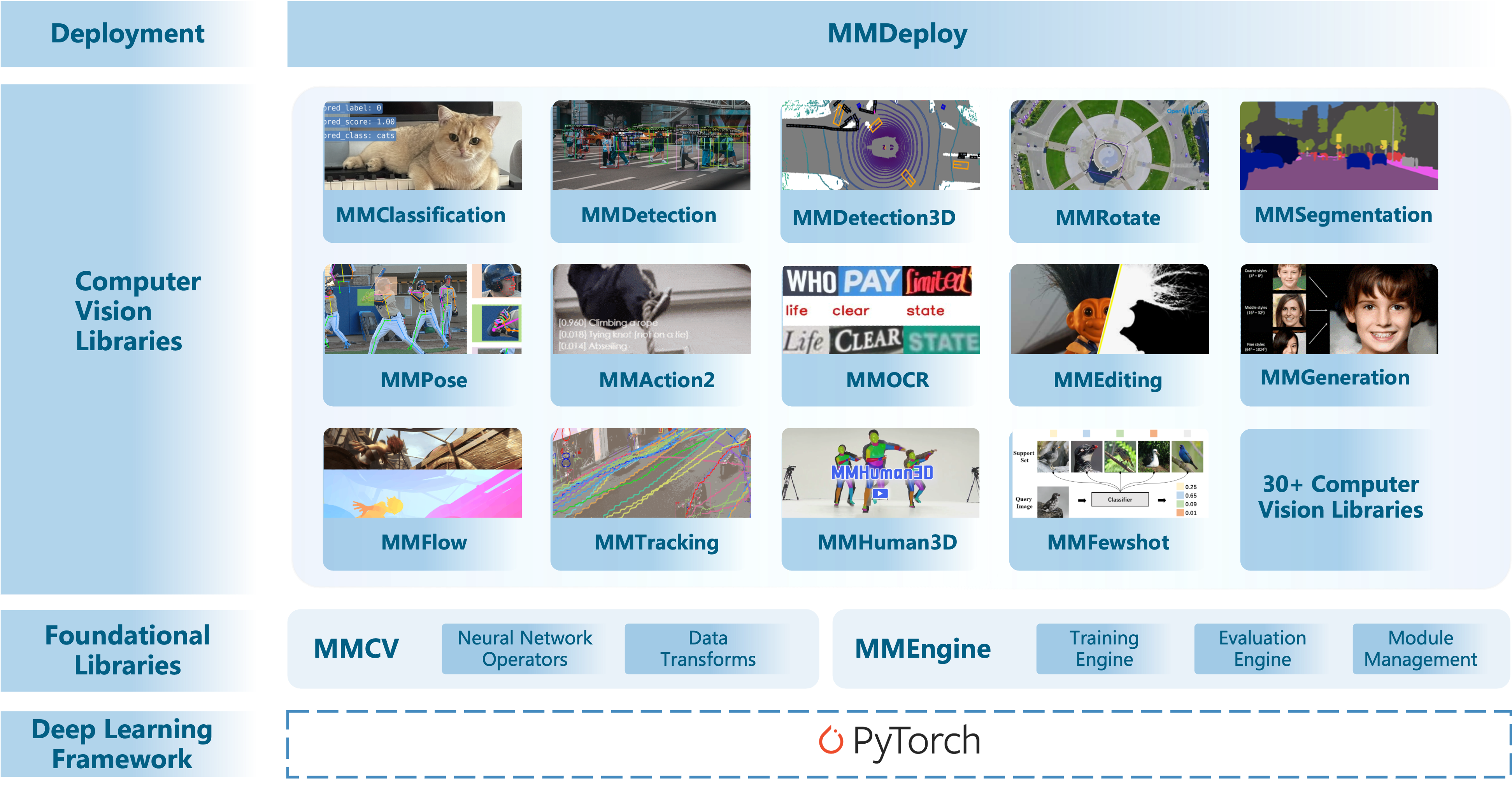
- 上图展示了 MMEngine 在 OpenMMLab 2.0 中的层次。MMEngine 实现了 OpenMMLab 算法库的新一代训练架构,为 OpenMMLab 中的 30 多个算法库提供了统一的执行基座。其核心组件包含训练引擎、评测引擎和模块管理等。
1.2 模块介绍
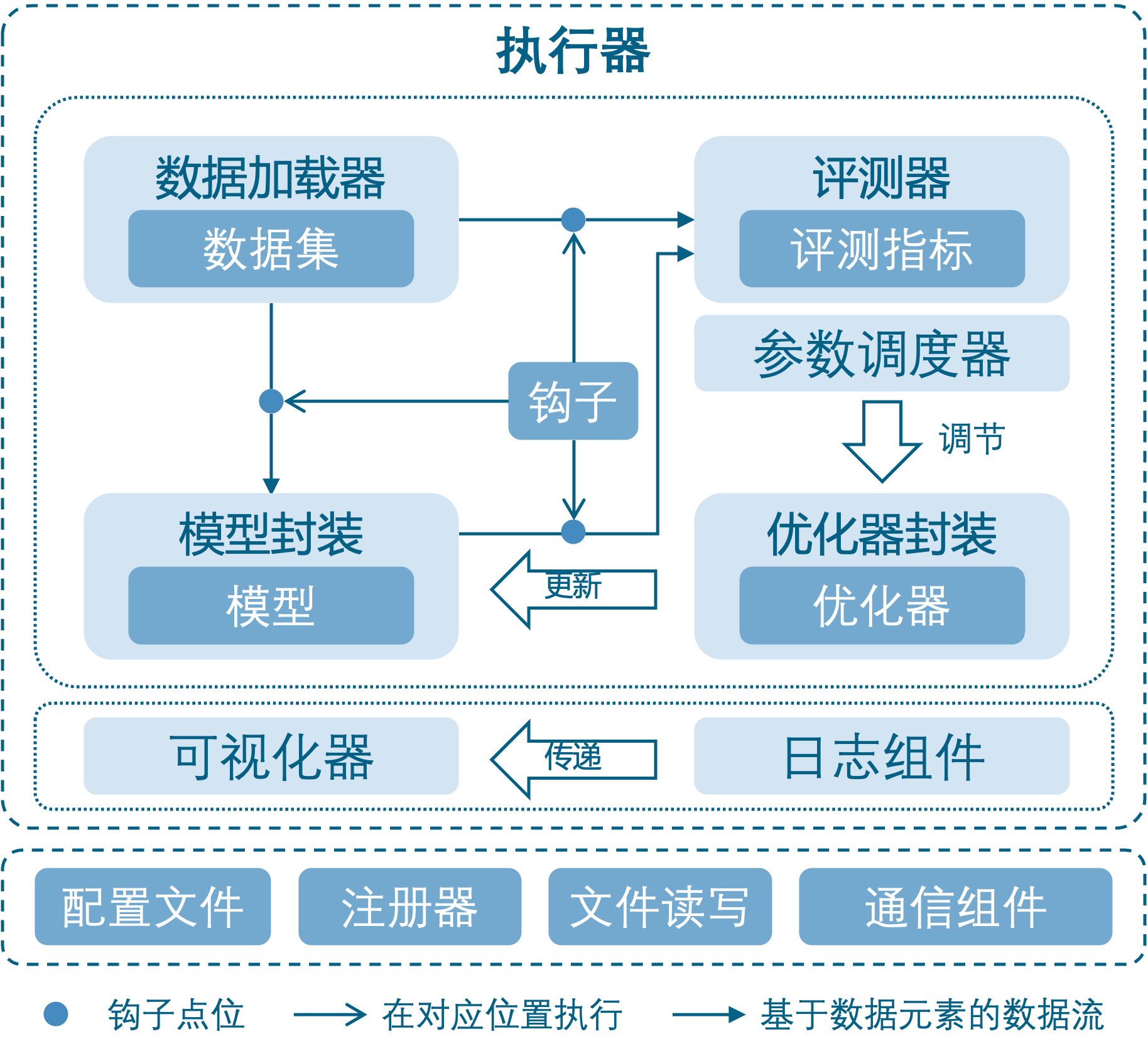
- MMEngine 将训练过程中涉及的组件和它们的关系进行了抽象,如上图所示。不同算法库中的同类型组件具有相同的接口定义。
1.2.1 核心模块与相关组件
- 训练引擎的核心模块是执行器(Runner)。 执行器负责执行训练、测试和推理任务并管理这些过程中所需要的各个组件。在训练、测试、推理任务执行过程中的特定位置,执行器设置了钩子(Hook) 来允许用户拓展、插入和执行自定义逻辑。执行器主要调用如下组件来完成训练和推理过程中的循环:
- 数据集(Dataset):负责在训练、测试、推理任务中构建数据集,并将数据送给模型。实际使用过程中会被数据加载器(DataLoader)封装一层,数据加载器会启动多个子进程来加载数据。
- 模型(Model):在训练过程中接受数据并输出 loss;在测试、推理任务中接受数据,并进行预测。分布式训练等情况下会被模型的封装器(Model Wrapper,如MMDistributedDataParallel)封装一层。
- 优化器封装(Optimizer):优化器封装负责在训练过程中执行反向传播优化模型,并且以统一的接口支持了混合精度训练和梯度累加。
- 参数调度器(Parameter Scheduler):训练过程中,对学习率、动量等优化器超参数进行动态调整。
- 在训练间隙或者测试阶段,评测指标与评测器(Metrics & Evaluator)会负责对模型性能进行评测。其中评测器负责基于数据集对模型的预测进行评估。评测器内还有一层抽象是评测指标,负责计算具体的一个或多个评测指标(如召回率、正确率等)。
- 在训练、推理执行过程中,上述各个组件都可以调用日志管理模块和可视化器进行结构化和非结构化日志的存储与展示。日志管理(Logging Modules):负责管理执行器运行过程中产生的各种日志信息。其中消息枢纽 (MessageHub)负责实现组件与组件、执行器与执行器之间的数据共享,日志处理器(Log Processor)负责对日志信息进行处理,处理后的日志会分别发送给执行器的日志器(Logger)和可视化器(Visualizer)进行日志的管理与展示。可视化器(Visualizer):可视化器负责对模型的特征图、预测结果和训练过程中产生的结构化日志进行可视化,支持 Tensorboard 和 WanDB 等多种可视化后端。
1.2.1 公共基础模块
- MMEngine 中还实现了各种算法模型执行过程中需要用到的公共基础模块,包括:
- 配置类(Config):在 OpenMMLab 算法库中,用户可以通过编写 config 来配置训练、测试过程以及相关的组件。
- 注册器(Registry):负责管理算法库中具有相同功能的模块。MMEngine 根据对算法库模块的抽象,定义了一套根注册器,算法库中的注册器可以继承自这套根注册器,实现模块的跨算法库调用。
- 文件读写(File I/O):为各个模块的文件读写提供了统一的接口,以统一的形式支持了多种文件读写后端和多种文件格式,并具备扩展性。
- 分布式通信原语(Distributed Communication Primitives):负责在程序分布式运行过程中不同进程间的通信。这套接口屏蔽了分布式和非分布式环境的区别,同时也自动处理了数据的设备和通信后端。
- 其他工具(Utils):还有一些工具性的模块,如 ManagerMixin,它实现了一种全局变量的创建和获取方式,执行器内很多全局可见对象的基类就是 ManagerMixin。
2 上手示例
- 以在 CIFAR-10 数据集上训练一个 ResNet-50 模型为例,我们将使用 80 行以内的代码,利用 MMEngine 构建一个完整的、 可配置的训练和验证流程
2.1 构建模型
- 首先,我们需要构建一个模型,在 MMEngine 中,我们约定这个模型应当继承 BaseModel,并且其 forward 方法除了接受来自数据集的若干参数外,还需要接受额外的参数 mode:对于训练,我们需要 mode 接受字符串 “loss”,并返回一个包含 “loss” 字段的字典;对于验证,我们需要 mode 接受字符串 “predict”,并返回同时包含预测信息和真实信息的结果。
import torch.nn.functional as F
import torchvision
from mmengine.model import BaseModel
class MMResNet50(BaseModel):
def __init__(self):
super().__init__()
self.resnet = torchvision.models.resnet50()
def forward(self, imgs, labels, mode):
x = self.resnet(imgs)
if mode == 'loss':
return {'loss': F.cross_entropy(x, labels)}
elif mode == 'predict':
return x, labels
2.2 构建数据集和数据加载器
- 其次,我们需要构建训练和验证所需要的数据集 (Dataset)和数据加载器 (DataLoader)。 对于基础的训练和验证功能,我们可以直接使用符合 PyTorch 标准的数据加载器和数据集。
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
norm_cfg = dict(mean=[0.491, 0.482, 0.447], std=[0.202, 0.199, 0.201])
train_dataloader = DataLoader(batch_size=32,
shuffle=True,
dataset=torchvision.datasets.CIFAR10(
'data/cifar10',
train=True,
download=True,
transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(**norm_cfg)
])))
val_dataloader = DataLoader(batch_size=32,
shuffle=False,
dataset=torchvision.datasets.CIFAR10(
'data/cifar10',
train=False,
download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(**norm_cfg)
])))
2.3 构建评测指标
- 为了进行验证和测试,我们需要定义模型推理结果的评测指标。我们约定这一评测指标需要继承 BaseMetric,并实现 process 和 compute_metrics 方法。其中 process 方法接受数据集的输出和模型 mode=“predict” 时的输出,此时的数据为一个批次的数据,对这一批次的数据进行处理后,保存信息至 self.results 属性。 而 compute_metrics 接受 results 参数,这一参数的输入为 process 中保存的所有信息 (如果是分布式环境,results 中为已收集的,包括各个进程 process 保存信息的结果),利用这些信息计算并返回保存有评测指标结果的字典。
from mmengine.evaluator import BaseMetric
class Accuracy(BaseMetric):
def process(self, data_batch, data_samples):
score, gt = data_samples
# 将一个批次的中间结果保存至 `self.results`
self.results.append({
'batch_size': len(gt),
'correct': (score.argmax(dim=1) == gt).sum().cpu(),
})
def compute_metrics(self, results):
total_correct = sum(item['correct'] for item in results)
total_size = sum(item['batch_size'] for item in results)
# 返回保存有评测指标结果的字典,其中键为指标名称
return dict(accuracy=100 * total_correct / total_size)
2.4 构建执行器并执行任务
- 最后,我们利用构建好的模型,数据加载器,评测指标构建一个执行器 (Runner),同时在其中配置 优化器、工作路径、训练与验证配置等选项,即可通过调用 train() 接口启动训练:
from torch.optim import SGD
from mmengine.runner import Runner
runner = Runner(
# 用以训练和验证的模型,需要满足特定的接口需求
model=MMResNet50(),
# 工作路径,用以保存训练日志、权重文件信息
work_dir='./work_dir',
# 训练数据加载器,需要满足 PyTorch 数据加载器协议
train_dataloader=train_dataloader,
# 优化器包装,用于模型优化,并提供 AMP、梯度累积等附加功能
optim_wrapper=dict(optimizer=dict(type=SGD, lr=0.001, momentum=0.9)),
# 训练配置,用于指定训练周期、验证间隔等信息
train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
# 验证数据加载器,需要满足 PyTorch 数据加载器协议
val_dataloader=val_dataloader,
# 验证配置,用于指定验证所需要的额外参数
val_cfg=dict(),
# 用于验证的评测器,这里使用默认评测器,并评测指标
val_evaluator=dict(type=Accuracy),
)
runner.train()
3. 基础模块
3.1 注册器(Registry)
- OpenMMLab 的算法库支持了丰富的算法和数据集,因此实现了很多功能相近的模块。例如 ResNet 和 SE-ResNet 的算法实现分别基于 ResNet 和 SEResNet 类,这些类有相似的功能和接口,都属于算法库中的模型组件。 为了管理这些功能相似的模块,MMEngine 实现了 注册器。 OpenMMLab 大多数算法库均使用注册器来管理它们的代码模块,包括 MMDetection, MMDetection3D,MMPose, MMClassification 和 MMEditing 等。
3.1.1 什么是注册器
- MMEngine 实现的注册器可以看作一个映射表和模块构建方法(build function)的组合。
- 映射表:维护了一个字符串到类或者函数的映射,使得用户可以借助字符串查找到相应的类或函数,例如维护字符串 “ResNet” 到 ResNet 类或函数的映射,使得用户可以通过 “ResNet” 找到 ResNet 类;
- 模块构建方法:定义了如何根据字符串查找到对应的类或函数以及如何实例化这个类或者调用这个函数,例如,通过字符串 “bn” 找到 nn.BatchNorm2d 并实例化 BatchNorm2d 模块;又或者通过字符串 “build_batchnorm2d” 找到 build_batchnorm2d 函数并返回该函数的调用结果。
- MMEngine 中的注册器默认使用 build_from_cfg 函数来查找并实例化字符串对应的类或者函数。
- 一个注册器:管理的类或函数通常有相似的接口和功能,因此该注册器可以被视作这些类或函数的抽象。例如注册器 MODELS 可以被视作所有模型的抽象,管理了 ResNet, SEResNet 和 RegNetX 等分类网络的类以及 build_ResNet, build_SEResNet 和 build_RegNetX 等分类网络的构建函数。
- 注册器的定义(部分代码)
class Registry:
"""A registry to map strings to classes or functions.
Registered object could be built from registry. Meanwhile, registered
functions could be called from registry.
Args:
name (str): Registry name.
build_func (callable, optional): A function to construct instance
from Registry. :func:`build_from_cfg` is used if neither ``parent``
or ``build_func`` is specified. If ``parent`` is specified and
``build_func`` is not given, ``build_func`` will be inherited
from ``parent``. Defaults to None.
parent (:obj:`Registry`, optional): Parent registry. The class
registered in children registry could be built from parent.
Defaults to None.
scope (str, optional): The scope of registry. It is the key to search
for children registry. If not specified, scope will be the name of
the package where class is defined, e.g. mmdet, mmcls, mmseg.
Defaults to None.
Examples:
>>> # define a registry
>>> MODELS = Registry('models')
>>> # registry the `ResNet` to `MODELS`
>>> @MODELS.register_module()
>>> class ResNet:
>>> pass
>>> # build model from `MODELS`
>>> resnet = MODELS.build(dict(type='ResNet'))
>>> @MODELS.register_module()
>>> def resnet50():
>>> pass
>>> resnet = MODELS.build(dict(type='resnet50'))
>>> # hierarchical registry
>>> DETECTORS = Registry('detectors', parent=MODELS, scope='det')
>>> @DETECTORS.register_module()
>>> class FasterRCNN:
>>> pass
>>> fasterrcnn = DETECTORS.build(dict(type='FasterRCNN'))
More advanced usages can be found at
https://mmengine.readthedocs.io/en/latest/tutorials/registry.html.
"""
def __init__(self,
name: str,
build_func: Optional[Callable] = None,
parent: Optional['Registry'] = None,
scope: Optional[str] = None):
from .build_functions import build_from_cfg
self._name = name
self._module_dict: Dict[str, Type] = dict()
self._children: Dict[str, 'Registry'] = dict()
if scope is not None:
assert isinstance(scope, str)
self._scope = scope
else:
self._scope = self.infer_scope()
# See https://mypy.readthedocs.io/en/stable/common_issues.html#
# variables-vs-type-aliases for the use
self.parent: Optional['Registry']
if parent is not None:
assert isinstance(parent, Registry)
parent._add_child(self)
self.parent = parent
else:
self.parent = None
# self.build_func will be set with the following priority:
# 1. build_func
# 2. parent.build_func
# 3. build_from_cfg
self.build_func: Callable
if build_func is None:
if self.parent is not None:
self.build_func = self.parent.build_func
else:
self.build_func = build_from_cfg
else:
self.build_func = build_func
3.1.2 使用流程
- 使用注册器管理代码库中的模块,需要以下三个步骤:
- 创建注册器
- 创建一个用于实例化类的构建方法(可选,在大多数情况下可以只使用默认方法)
- 将模块加入注册器中
- 假设我们要实现一系列激活模块并且希望仅修改配置就能够使用不同的激活模块而无需修改代码。
3.1.2.1 创建注册器
from mmengine import Registry
# scope 表示注册器的作用域,如果不设置,默认为包名,例如在 mmdetection 中,它的 scope 为 mmdet
ACTIVATION = Registry('activation', scope='mmengine')
3.1.2.2 定义要注册的模块(类或函数)
import torch.nn as nn
# 使用注册器管理模块
@ACTIVATION.register_module()
class Sigmoid(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
print('call Sigmoid.forward')
return x
@ACTIVATION.register_module()
class ReLU(nn.Module):
def __init__(self, inplace=False):
super().__init__()
def forward(self, x):
print('call ReLU.forward')
return x
@ACTIVATION.register_module()
class Softmax(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
print('call Softmax.forward')
return x
- 使用注册器管理模块的关键步骤是,将实现的模块注册到注册表 ACTIVATION 中。通过 @ACTIVATION.register_module() 装饰所实现的模块,字符串和类或函数之间的映射就可以由 ACTIVATION 构建和维护,我们也可以通过 ACTIVATION.register_module(module=ReLU) 实现同样的功能。
- 通过注册,我们就可以通过 ACTIVATION 建立字符串与类或函数之间的映射:
print(ACTIVATION.module_dict)
# {
# 'Sigmoid': __main__.Sigmoid,
# 'ReLU': __main__.ReLU,
# 'Softmax': __main__.Softmax
# }
- 只有模块所在的文件被导入时,注册机制才会被触发,所以我们需要在某处导入该文件或者使用 custom_imports 字段动态导入该模块进而触发注册机制,详情见导入自定义 Python 模块。
3.1.2.3 通过配置激活模块
- 模块成功注册后,我们可以通过配置文件使用这个激活模块。
import torch
input = torch.randn(2)
act_cfg = dict(type='Sigmoid')
activation = ACTIVATION.build(act_cfg)
output = activation(input)
# call Sigmoid.forward
print(output)
#如果我们想使用 ReLU,仅需修改配置。
act_cfg = dict(type='ReLU', inplace=True)
activation = ACTIVATION.build(act_cfg)
output = activation(input)
# call ReLU.forward
print(output)
3.1.3 跨项目调用
- MMEngine 的注册器支持层级注册,利用该功能可实现跨项目调用,即可以在一个项目中使用另一个项目的模块。虽然跨项目调用也有其他方法的可以实现,但 MMEngine 注册器提供了更为简便的方法。
- 为了方便跨库调用,MMEngine 提供了 20 个根注册器:
- RUNNERS: Runner 的注册器
- RUNNER_CONSTRUCTORS: Runner 的构造器
- LOOPS: 管理训练、验证以及测试流程,如 EpochBasedTrainLoop
- HOOKS: 钩子,如 CheckpointHook, ParamSchedulerHook
- DATASETS: 数据集
- DATA_SAMPLERS: DataLoader 的 Sampler,用于采样数据
- TRANSFORMS: 各种数据预处理,如 Resize, Reshape
- MODELS: 模型的各种模块
- MODEL_WRAPPERS: 模型的包装器,如 MMDistributedDataParallel,用于对分布式数据并行
- WEIGHT_INITIALIZERS: 权重初始化的工具
- OPTIMIZERS: 注册了 PyTorch 中所有的 Optimizer 以及自定义的 Optimizer
- OPTIM_WRAPPER: 对 Optimizer 相关操作的封装,如 OptimWrapper,AmpOptimWrapper
- OPTIM_WRAPPER_CONSTRUCTORS: optimizer wrapper 的构造器
- PARAM_SCHEDULERS: 各种参数调度器,如 MultiStepLR
- METRICS: 用于计算模型精度的评估指标,如 Accuracy
- EVALUATOR: 用于计算模型精度的一个或多个评估指标
- TASK_UTILS: 任务强相关的一些组件,如 AnchorGenerator, BboxCoder
- VISUALIZERS: 管理绘制模块,如 DetVisualizer 可在图片上绘制预测框
- VISBACKENDS: 存储训练日志的后端,如 LocalVisBackend, TensorboardVisBackend
- LOG_PROCESSORS: 控制日志的统计窗口和统计方法,默认使用 LogProcessor,如有特殊需求可自定义 LogProcessor
3.2 配置(Config)
- MMEngine 实现了抽象的配置类(Config),为用户提供统一的配置访问接口。配置类能够支持不同格式的配置文件,包括 python,json,yaml,用户可以根据需求选择自己偏好的格式。配置类提供了类似字典或者 Python 对象属性的访问接口,用户可以十分自然地进行配置字段的读取和修改。为了方便算法框架管理配置文件,配置类也实现了一些特性,例如配置文件的字段继承等。
3.2.1 配置文件读取
- 配置类提供了统一的接口 Config.fromfile(),来读取和解析配置文件。
- 合法的配置文件应该定义一系列键值对,这里举几个不同格式配置文件的例子。
- Python 格式:
test_int = 1
test_list = [1, 2, 3]
test_dict = dict(key1='value1', key2=0.1)
- Json 格式:
{
"test_int": 1,
"test_list": [1, 2, 3],
"test_dict": {"key1": "value1", "key2": 0.1}
}
- YAML 格式:
test_int: 1
test_list: [1, 2, 3]
test_dict:
key1: "value1"
key2: 0.1
- 对于以上三种格式的文件,假设文件名分别为 config.py,config.json,config.yml,调用 Config.fromfile(‘config.xxx’) 接口加载这三个文件都会得到相同的结果,构造了包含 3 个字段的配置对象。我们以 config.py 为例,我们先将示例配置文件下载到本地:
from mmengine.config import Config
cfg = Config.fromfile('learn_read_config.py')
print(cfg)
- 输出结果为:
Config (path: learn_read_config.py): {'test_int': 1, 'test_list': [1, 2, 3], 'test_dict': {'key1': 'value1', 'key2': 0.1}}
3.2.2 配置文件的使用
- 通过读取配置文件来初始化配置对象后,就可以像使用普通字典或者 Python 类一样来使用这个变量了。 我们提供了两种访问接口,即类似字典的接口 cfg[‘key’] 或者类似 Python 对象属性的接口 cfg.key。这两种接口都支持读写。
print(cfg.test_int)
print(cfg.test_list)
print(cfg.test_dict)
cfg.test_int = 2
print(cfg['test_int'])
print(cfg['test_list'])
print(cfg['test_dict'])
cfg['test_list'][1] = 3
print(cfg['test_list'])
- 输出结果为:
1
[1, 2, 3]
{'key1': 'value1', 'key2': 0.1}
2
[1, 2, 3]
{'key1': 'value1', 'key2': 0.1}
[1, 3, 3]
- 注意,配置文件中定义的嵌套字段(即类似字典的字段),在 Config 中会将其转化为 ConfigDict 类,该类继承了 Python 内置字典类型的全部接口,同时也支持以对象属性的方式访问数据。
- 在算法库中,可以将配置与注册器结合起来使用,达到通过配置文件来控制模块构造的目的。这里举一个在配置文件中定义优化器的例子。
- 假设我们已经定义了一个优化器的注册器 OPTIMIZERS,包括了各种优化器。那么首先写一个 config_sgd.py:
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
- 然后在算法库中可以通过如下代码构造优化器对象。
from mmengine import Config, optim
from mmengine.registry import OPTIMIZERS # 在mmengine root.py中定义
import torch.nn as nn
cfg = Config.fromfile('config_sgd.py')
model = nn.Conv2d(1, 1, 1)
cfg.optimizer.params = model.parameters()
optimizer = OPTIMIZERS.build(cfg.optimizer)
print(optimizer)
- 输出结果为:
SGD (
Parameter Group 0
dampening: 0
foreach: None
lr: 0.1
maximize: False
momentum: 0.9
nesterov: False
weight_decay: 0.0001
)
3.2.3 配置文件的继承
- 有时候,两个不同的配置文件之间的差异很小,可能仅仅只改了一个字段,我们就需要将所有内容复制粘贴一次,而且在后续观察的时候,不容易定位到具体差异的字段。又有些情况下,多个配置文件可能都有相同的一批字段,我们不得不在这些配置文件中进行复制粘贴,给后续的修改和维护带来了不便。
- 为了解决这些问题,我们给配置文件增加了继承的机制,即一个配置文件 A 可以将另一个配置文件 B 作为自己的基础,直接继承了 B 中所有字段,而不必显式复制粘贴。
- 这里我们举一个例子来说明继承机制。定义如下两个配置文件
- optimizer_cfg.py:
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
- resnet50.py:
_base_ = ['optimizer_cfg.py']
model = dict(type='ResNet', depth=50)
- 虽然我们在 resnet50.py 中没有定义 optimizer 字段,但由于我们写了 _base_ = [‘optimizer_cfg.py’],会使这个配置文件获得 optimizer_cfg.py 中的所有字段。
cfg = Config.fromfile('resnet50.py')
print(cfg.optimizer)
- 输出结果为:
{'type': 'SGD', 'lr': 0.02, 'momentum': 0.9, 'weight_decay': 0.0001}
- 这里 _base_ 是配置文件的保留字段,指定了该配置文件的继承来源。支持继承多个文件,将同时获得这多个文件中的所有字段,但是要求继承的多个文件中没有相同名称的字段,否则会报错。
- runtime_cfg.py:
gpu_ids = [0, 1]
- resnet50_runtime.py:
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
model = dict(type='ResNet', depth=50)
- 这时,读取配置文件 resnet50_runtime.py 会获得 3 个字段 model,optimizer,gpu_ids。
cfg = Config.fromfile('resnet50_runtime.py')
print(cfg.optimizer)
- 输出结果为:
{'type': 'SGD', 'lr': 0.02, 'momentum': 0.9, 'weight_decay': 0.0001}
- 通过这种方式,我们可以将配置文件进行拆分,定义一些通用配置文件,在实际配置文件中继承各种通用配置文件,可以减少具体任务的配置流程。
3.2.4 修改继承字段
- 有时候,我们继承一个配置文件之后,可能需要对其中个别字段进行修改,例如继承了 optimizer_cfg.py 之后,想将学习率从 0.02 修改为 0.01。
- 这时候,只需要在新的配置文件中,重新定义一下需要修改的字段即可。注意由于 optimizer 这个字段是一个字典,我们只需要重新定义这个字典里面需修改的下级字段即可。这个规则也适用于增加一些下级字段。
- resnet50_lr0.01.py:
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
model = dict(type='ResNet', depth=50)
optimizer = dict(lr=0.01)
- 读取这个配置文件之后,就可以得到期望的结果。
cfg = Config.fromfile('resnet50_lr0.01.py')
print(cfg.optimizer)
- 输出结果为:
{'type': 'SGD', 'lr': 0.01, 'momentum': 0.9, 'weight_decay': 0.0001}
- 对于非字典类型的字段,例如整数,字符串,列表等,重新定义即可完全覆盖,例如下面的写法就将 gpu_ids 这个字段的值修改成了 [0]。
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
model = dict(type='ResNet', depth=50)
gpu_ids = [0]
3.2.5 删除字典中的 key
- 有时候我们对于继承过来的字典类型字段,不仅仅是想修改其中某些 key,可能还需要删除其中的一些 key。这时候在重新定义这个字典时,需要指定 delete=True,表示将没有在新定义的字典中出现的 key 全部删除。
- resnet50_delete_key.py:
_base_ = ['optimizer_cfg.py', 'runtime_cfg.py']
model = dict(type='ResNet', depth=50)
optimizer = dict(_delete_=True, type='SGD', lr=0.01)
- 这时候,optimizer 这个字典中就只有 type 和 lr 这两个 key,momentum 和 weight_decay 将不再被继承。
cfg = Config.fromfile('resnet50_delete_key.py')
print(cfg.optimizer)
- 输出结果为:
{'type': 'SGD', 'lr': 0.01}
3.3 执行器(Runner)
- 深度学习算法的训练、验证和测试通常都拥有相似的流程,因此 MMEngine 提供了执行器以帮助用户简化这些任务的实现流程。 用户只需要准备好模型训练、验证、测试所需要的模块构建执行器,便能够通过简单调用执行器的接口来完成这些任务。用户如果需要使用这几项功能中的某一项,只需要准备好对应功能所依赖的模块即可。
- 构建模块的方式:
- 手动构建这些模块的实例
- 通过编写配置文件,由执行器自动从注册器中构建所需要的模块
- Runner接口
@RUNNERS.register_module()
class Runner:
"""A training helper for PyTorch.
Runner object can be built from config by ``runner = Runner.from_cfg(cfg)``
where the ``cfg`` usually contains training, validation, and test-related
configurations to build corresponding components. We usually use the
same config to launch training, testing, and validation tasks. However,
only some of these components are necessary at the same time, e.g.,
testing a model does not need training or validation-related components.
To avoid repeatedly modifying config, the construction of ``Runner`` adopts
lazy initialization to only initialize components when they are going to be
used. Therefore, the model is always initialized at the beginning, and
training, validation, and, testing related components are only initialized
when calling ``runner.train()``, ``runner.val()``, and ``runner.test()``,
respectively.
Args:
model (:obj:`torch.nn.Module` or dict): The model to be run. It can be
a dict used for build a model.
work_dir (str): The working directory to save checkpoints. The logs
will be saved in the subdirectory of `work_dir` named
:attr:`timestamp`.
train_dataloader (Dataloader or dict, optional): A dataloader object or
a dict to build a dataloader. If ``None`` is given, it means
skipping training steps. Defaults to None.
See :meth:`build_dataloader` for more details.
val_dataloader (Dataloader or dict, optional): A dataloader object or
a dict to build a dataloader. If ``None`` is given, it means
skipping validation steps. Defaults to None.
See :meth:`build_dataloader` for more details.
test_dataloader (Dataloader or dict, optional): A dataloader object or
a dict to build a dataloader. If ``None`` is given, it means
skipping test steps. Defaults to None.
See :meth:`build_dataloader` for more details.
train_cfg (dict, optional): A dict to build a training loop. If it does
not provide "type" key, it should contain "by_epoch" to decide
which type of training loop :class:`EpochBasedTrainLoop` or
:class:`IterBasedTrainLoop` should be used. If ``train_cfg``
specified, :attr:`train_dataloader` should also be specified.
Defaults to None. See :meth:`build_train_loop` for more details.
val_cfg (dict, optional): A dict to build a validation loop. If it does
not provide "type" key, :class:`ValLoop` will be used by default.
If ``val_cfg`` specified, :attr:`val_dataloader` should also be
specified. If ``ValLoop`` is built with `fp16=True``,
``runner.val()`` will be performed under fp16 precision.
Defaults to None. See :meth:`build_val_loop` for more details.
test_cfg (dict, optional): A dict to build a test loop. If it does
not provide "type" key, :class:`TestLoop` will be used by default.
If ``test_cfg`` specified, :attr:`test_dataloader` should also be
specified. If ``ValLoop`` is built with `fp16=True``,
``runner.val()`` will be performed under fp16 precision.
Defaults to None. See :meth:`build_test_loop` for more details.
auto_scale_lr (dict, Optional): Config to scale the learning rate
automatically. It includes ``base_batch_size`` and ``enable``.
``base_batch_size`` is the batch size that the optimizer lr is
based on. ``enable`` is the switch to turn on and off the feature.
optim_wrapper (OptimWrapper or dict, optional):
Computing gradient of model parameters. If specified,
:attr:`train_dataloader` should also be specified. If automatic
mixed precision or gradient accmulation
training is required. The type of ``optim_wrapper`` should be
AmpOptimizerWrapper. See :meth:`build_optim_wrapper` for
examples. Defaults to None.
param_scheduler (_ParamScheduler or dict or list, optional):
Parameter scheduler for updating optimizer parameters. If
specified, :attr:`optimizer` should also be specified.
Defaults to None.
See :meth:`build_param_scheduler` for examples.
val_evaluator (Evaluator or dict or list, optional): A evaluator object
used for computing metrics for validation. It can be a dict or a
list of dict to build a evaluator. If specified,
:attr:`val_dataloader` should also be specified. Defaults to None.
test_evaluator (Evaluator or dict or list, optional): A evaluator
object used for computing metrics for test steps. It can be a dict
or a list of dict to build a evaluator. If specified,
:attr:`test_dataloader` should also be specified. Defaults to None.
default_hooks (dict[str, dict] or dict[str, Hook], optional): Hooks to
execute default actions like updating model parameters and saving
checkpoints. Default hooks are ``OptimizerHook``,
``IterTimerHook``, ``LoggerHook``, ``ParamSchedulerHook`` and
``CheckpointHook``. Defaults to None.
See :meth:`register_default_hooks` for more details.
custom_hooks (list[dict] or list[Hook], optional): Hooks to execute
custom actions like visualizing images processed by pipeline.
Defaults to None.
data_preprocessor (dict, optional): The pre-process config of
:class:`BaseDataPreprocessor`. If the ``model`` argument is a dict
and doesn't contain the key ``data_preprocessor``, set the argument
as the ``data_preprocessor`` of the ``model`` dict.
Defaults to None.
load_from (str, optional): The checkpoint file to load from.
Defaults to None.
resume (bool): Whether to resume training. Defaults to False. If
``resume`` is True and ``load_from`` is None, automatically to
find latest checkpoint from ``work_dir``. If not found, resuming
does nothing.
launcher (str): Way to launcher multi-process. Supported launchers
are 'pytorch', 'mpi', 'slurm' and 'none'. If 'none' is provided,
non-distributed environment will be launched.
env_cfg (dict): A dict used for setting environment. Defaults to
dict(dist_cfg=dict(backend='nccl')).
log_processor (dict, optional): A processor to format logs. Defaults to
None.
log_level (int or str): The log level of MMLogger handlers.
Defaults to 'INFO'.
visualizer (Visualizer or dict, optional): A Visualizer object or a
dict build Visualizer object. Defaults to None. If not
specified, default config will be used.
default_scope (str): Used to reset registries location.
Defaults to "mmengine".
randomness (dict): Some settings to make the experiment as reproducible
as possible like seed and deterministic.
Defaults to ``dict(seed=None)``. If seed is None, a random number
will be generated and it will be broadcasted to all other processes
if in distributed environment. If ``cudnn_benchmarch`` is
``True`` in ``env_cfg`` but ``deterministic`` is ``True`` in
``randomness``, the value of ``torch.backends.cudnn.benchmark``
will be ``False`` finally.
experiment_name (str, optional): Name of current experiment. If not
specified, timestamp will be used as ``experiment_name``.
Defaults to None.
cfg (dict or Configdict or :obj:`Config`, optional): Full config.
Defaults to None.
Examples:
>>> from mmengine.runner import Runner
>>> cfg = dict(
>>> model=dict(type='ToyModel'),
>>> work_dir='path/of/work_dir',
>>> train_dataloader=dict(
>>> dataset=dict(type='ToyDataset'),
>>> sampler=dict(type='DefaultSampler', shuffle=True),
>>> batch_size=1,
>>> num_workers=0),
>>> val_dataloader=dict(
>>> dataset=dict(type='ToyDataset'),
>>> sampler=dict(type='DefaultSampler', shuffle=False),
>>> batch_size=1,
>>> num_workers=0),
>>> test_dataloader=dict(
>>> dataset=dict(type='ToyDataset'),
>>> sampler=dict(type='DefaultSampler', shuffle=False),
>>> batch_size=1,
>>> num_workers=0),
>>> auto_scale_lr=dict(base_batch_size=16, enable=False),
>>> optim_wrapper=dict(type='OptimizerWrapper', optimizer=dict(
>>> type='SGD', lr=0.01)),
>>> param_scheduler=dict(type='MultiStepLR', milestones=[1, 2]),
>>> val_evaluator=dict(type='ToyEvaluator'),
>>> test_evaluator=dict(type='ToyEvaluator'),
>>> train_cfg=dict(by_epoch=True, max_epochs=3, val_interval=1),
>>> val_cfg=dict(),
>>> test_cfg=dict(),
>>> custom_hooks=[],
>>> default_hooks=dict(
>>> timer=dict(type='IterTimerHook'),
>>> checkpoint=dict(type='CheckpointHook', interval=1),
>>> logger=dict(type='LoggerHook'),
>>> optimizer=dict(type='OptimizerHook', grad_clip=False),
>>> param_scheduler=dict(type='ParamSchedulerHook')),
>>> launcher='none',
>>> env_cfg=dict(dist_cfg=dict(backend='nccl')),
>>> log_processor=dict(window_size=20),
>>> visualizer=dict(type='Visualizer',
>>> vis_backends=[dict(type='LocalVisBackend',
>>> save_dir='temp_dir')])
>>> )
>>> runner = Runner.from_cfg(cfg)
>>> runner.train()
>>> runner.test()
"""
cfg: Config
_train_loop: Optional[Union[BaseLoop, Dict]]
_val_loop: Optional[Union[BaseLoop, Dict]]
_test_loop: Optional[Union[BaseLoop, Dict]]
def __init__(
self,
model: Union[nn.Module, Dict],
work_dir: str,
train_dataloader: Optional[Union[DataLoader, Dict]] = None,
val_dataloader: Optional[Union[DataLoader, Dict]] = None,
test_dataloader: Optional[Union[DataLoader, Dict]] = None,
train_cfg: Optional[Dict] = None,
val_cfg: Optional[Dict] = None,
test_cfg: Optional[Dict] = None,
auto_scale_lr: Optional[Dict] = None,
optim_wrapper: Optional[Union[OptimWrapper, Dict]] = None,
param_scheduler: Optional[Union[_ParamScheduler, Dict, List]] = None,
val_evaluator: Optional[Union[Evaluator, Dict, List]] = None,
test_evaluator: Optional[Union[Evaluator, Dict, List]] = None,
default_hooks: Optional[Dict[str, Union[Hook, Dict]]] = None,
custom_hooks: Optional[List[Union[Hook, Dict]]] = None,
data_preprocessor: Union[nn.Module, Dict, None] = None,
load_from: Optional[str] = None,
resume: bool = False,
launcher: str = 'none',
env_cfg: Dict = dict(dist_cfg=dict(backend='nccl')),
log_processor: Optional[Dict] = None,
log_level: str = 'INFO',
visualizer: Optional[Union[Visualizer, Dict]] = None,
default_scope: str = 'mmengine',
randomness: Dict = dict(seed=None),
experiment_name: Optional[str] = None,
cfg: Optional[ConfigType] = None,
):
self._work_dir = osp.abspath(work_dir)
mmengine.mkdir_or_exist(self._work_dir)
# recursively copy the `cfg` because `self.cfg` will be modified
# everywhere.
if cfg is not None:
if isinstance(cfg, Config):
self.cfg = copy.deepcopy(cfg)
elif isinstance(cfg, dict):
self.cfg = Config(cfg)
else:
self.cfg = Config(dict())
# lazy initialization
training_related = [train_dataloader, train_cfg, optim_wrapper]
if not (all(item is None for item in training_related)
or all(item is not None for item in training_related)):
raise ValueError(
'train_dataloader, train_cfg, and optimizer should be either '
'all None or not None, but got '
f'train_dataloader={train_dataloader}, '
f'train_cfg={train_cfg}, '
f'optim_wrapper={optim_wrapper}.')
self._train_dataloader = train_dataloader
self._train_loop = train_cfg
self.optim_wrapper: Optional[Union[OptimWrapper, dict]]
self.optim_wrapper = optim_wrapper
self.auto_scale_lr = auto_scale_lr
# If there is no need to adjust learning rate, momentum or other
# parameters of optimizer, param_scheduler can be None
if param_scheduler is not None and self.optim_wrapper is None:
raise ValueError(
'param_scheduler should be None when optimizer is None, '
f'but got {param_scheduler}')
# Parse `param_scheduler` to a list or a dict. If `optim_wrapper` is a
# `dict` with single optimizer, parsed param_scheduler will be a
# list of parameter schedulers. If `optim_wrapper` is
# a `dict` with multiple optimizers, parsed `param_scheduler` will be
# dict with multiple list of parameter schedulers.
self._check_scheduler_cfg(param_scheduler)
self.param_schedulers = param_scheduler
val_related = [val_dataloader, val_cfg, val_evaluator]
if not (all(item is None
for item in val_related) or all(item is not None
for item in val_related)):
raise ValueError(
'val_dataloader, val_cfg, and val_evaluator should be either '
'all None or not None, but got '
f'val_dataloader={val_dataloader}, val_cfg={val_cfg}, '
f'val_evaluator={val_evaluator}')
self._val_dataloader = val_dataloader
self._val_loop = val_cfg
self._val_evaluator = val_evaluator
test_related = [test_dataloader, test_cfg, test_evaluator]
if not (all(item is None for item in test_related)
or all(item is not None for item in test_related)):
raise ValueError(
'test_dataloader, test_cfg, and test_evaluator should be '
'either all None or not None, but got '
f'test_dataloader={test_dataloader}, test_cfg={test_cfg}, '
f'test_evaluator={test_evaluator}')
self._test_dataloader = test_dataloader
self._test_loop = test_cfg
self._test_evaluator = test_evaluator
self._launcher = launcher
if self._launcher == 'none':
self._distributed = False
else:
self._distributed = True
# self._timestamp will be set in the `setup_env` method. Besides,
# it also will initialize multi-process and (or) distributed
# environment.
self.setup_env(env_cfg)
# self._deterministic and self._seed will be set in the
# `set_randomness`` method
self._randomness_cfg = randomness
self.set_randomness(**randomness)
if experiment_name is not None:
self._experiment_name = f'{experiment_name}_{self._timestamp}'
elif self.cfg.filename is not None:
filename_no_ext = osp.splitext(osp.basename(self.cfg.filename))[0]
self._experiment_name = f'{filename_no_ext}_{self._timestamp}'
else:
self._experiment_name = self.timestamp
self._log_dir = osp.join(self.work_dir, self.timestamp)
mmengine.mkdir_or_exist(self._log_dir)
# Used to reset registries location. See :meth:`Registry.build` for
# more details.
self.default_scope = DefaultScope.get_instance(
self._experiment_name, scope_name=default_scope)
# Build log processor to format message.
log_processor = dict() if log_processor is None else log_processor
self.log_processor = self.build_log_processor(log_processor)
# Since `get_instance` could return any subclass of ManagerMixin. The
# corresponding attribute needs a type hint.
self.logger = self.build_logger(log_level=log_level)
# Collect and log environment information.
self._log_env(env_cfg)
# collect information of all modules registered in the registries
registries_info = count_registered_modules(
self.work_dir if self.rank == 0 else None, verbose=False)
self.logger.debug(registries_info)
# Build `message_hub` for communication among components.
# `message_hub` can store log scalars (loss, learning rate) and
# runtime information (iter and epoch). Those components that do not
# have access to the runner can get iteration or epoch information
# from `message_hub`. For example, models can get the latest created
# `message_hub` by
# `self.message_hub=MessageHub.get_current_instance()` and then get
# current epoch by `cur_epoch = self.message_hub.get_info('epoch')`.
# See `MessageHub` and `ManagerMixin` for more details.
self.message_hub = self.build_message_hub()
# visualizer used for writing log or visualizing all kinds of data
self.visualizer = self.build_visualizer(visualizer)
if self.cfg:
self.visualizer.add_config(self.cfg)
self._load_from = load_from
self._resume = resume
# flag to mark whether checkpoint has been loaded or resumed
self._has_loaded = False
# build a model
if isinstance(model, dict) and data_preprocessor is not None:
# Merge the data_preprocessor to model config.
model.setdefault('data_preprocessor', data_preprocessor)
self.model = self.build_model(model)
# wrap model
self.model = self.wrap_model(
self.cfg.get('model_wrapper_cfg'), self.model)
# get model name from the model class
if hasattr(self.model, 'module'):
self._model_name = self.model.module.__class__.__name__
else:
self._model_name = self.model.__class__.__name__
self._hooks: List[Hook] = []
# register hooks to `self._hooks`
self.register_hooks(default_hooks, custom_hooks)
# dump `cfg` to `work_dir`
self.dump_config()
3.3.1手动构建模块来使用执行器
3.3.1.1 手动构建模块进行训练
- 使用执行器的某一项功能时需要准备好对应功能所依赖的模块。以使用执行器的训练功能为例,用户需要准备
- 模型
- 优化器
- 参数调度器
- 训练数据集
# 准备训练任务所需要的模块
import torch
from torch import nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
from mmengine.model import BaseModel
from mmengine.optim.scheduler import MultiStepLR
# 定义一个多层感知机网络
class Network(BaseModel):
def __init__(self):
super().__init__()
self.mlp = nn.Sequential(nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 10))
self.loss = nn.CrossEntropyLoss()
def forward(self, batch_inputs: torch.Tensor, data_samples = None, mode: str = 'tensor'):
x = batch_inputs.flatten(1)
x = self.mlp(x)
if mode == 'loss':
return {'loss': self.loss(x, data_samples)}
elif mode == 'predict':
return x.argmax(1)
else:
return x
model = Network()
# 构建优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 构建参数调度器用于调整学习率
lr_scheduler = MultiStepLR(optimizer, milestones=[2], by_epoch=True)
# 构建手写数字识别 (MNIST) 数据集
train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
# 构建数据加载器
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
- 在创建完符合上述文档规范的模块的对象后,就可以使用这些模块初始化执行器:
from mmengine.runner import Runner
# 训练相关参数设置,按迭代次数训练,训练9000次迭代
#train_cfg = dict(by_epoch=False, max_iters=9000)
# 训练相关参数设置,按轮次训练,训练3轮
train_cfg = dict(by_epoch=True, max_epochs=3)
# 初始化执行器
runner = Runner(model,
work_dir='./train_mnist', # 工作目录,用于保存模型和日志
train_cfg=train_cfg,
train_dataloader=train_dataloader,
optim_wrapper=dict(optimizer=optimizer),
param_scheduler=lr_scheduler)
# 执行训练
runner.train()
- 上面的例子中,我们手动构建了一个多层感知机网络和手写数字识别 (MNIST) 数据集,以及训练所需要的优化器和学习率调度器,使用这些模块初始化了执行器,并且设置了训练配置 train_cfg,让执行器将模型训练3个轮次,最后通过调用执行器的 train 方法进行模型训练。
3.3.1.2 手动构建模块进行测试
- 模型的测试需要用户准备:
- 模型
- 训练好的权重路径
- 测试数据集
- 评测器
from mmengine.evaluator import BaseMetric
class MnistAccuracy(BaseMetric):
def process(self, data, preds) -> None:
self.results.append(((data[1] == preds.cpu()).sum(), len(preds)))
def compute_metrics(self, results):
correct, batch_size = zip(*results)
acc = sum(correct) / sum(batch_size)
return dict(accuracy=acc)
model = Network()
test_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
test_dataloader = DataLoader(dataset=test_dataset)
metric = MnistAccuracy()
test_evaluator = Evaluator(metric)
# 初始化执行器
runner = Runner(model=model,
test_dataloader=test_dataloader,
test_evaluator=test_evaluator,
load_from='./train_mnist/epoch_3.pth',
work_dir='./test_mnist')
# 执行测试
runner.test()
- 这个例子中重新手动构建了一个多层感知机网络,以及测试用的手写数字识别数据集和使用 (Accuracy) 指标的评测器,并使用这些模块初始化执行器,最后通过调用执行器的 test 函数进行模型测试。
3.3.1.3 手动构建模块在训练过程中进行验证
- 在模型训练过程中,通常会按一定的间隔在验证集上对模型进行验证。在使用 MMEngine 时,只需要构建训练和验证的模块,并在训练配置中设置验证间隔即可
# 准备训练任务所需要的模块
optimzier = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
lr_scheduler = MultiStepLR(milestones=[2], by_epoch=True)
train_dataset = datasets.MNIST(root="MNIST", download=True, train=True, transform=transforms.ToTensor())
train_dataloader = DataLoader(dataset=train_dataset, batch_size=10, num_workers=2)
# 准备验证需要的模块
val_dataset = datasets.MNIST(root="MNIST", download=True, train=False, transform=transforms.ToTensor())
val_dataloader = Dataloader(dataset=val_dataset)
metric = MnistAccuracy()
val_evaluator = Evaluator(metric)
# 训练相关参数设置
train_cfg = dict(by_epoch=True, # 按轮次训练
max_epochs=5, # 训练5轮
val_begin=2, # 从第 2 个 epoch 开始验证
val_interval=1) # 每隔1轮进行1次验证
# 初始化执行器
runner = Runner(model=model,
optim_wrapper=dict(optimizer=optimzier),
param_scheduler=lr_scheduler,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader,
val_evaluator=val_evaluator,
train_cfg=train_cfg,
work_dir='./train_val_mnist')
# 执行训练
runner.train()
3.3.2 通过配置文件使用执行器
- OpenMMLab 的开源项目普遍使用注册器 + 配置文件的方式来管理和构建模块
- MMEngine 中的执行器也推荐使用配置文件进行构建。 下面是一个通过配置文件使用执行器的例子:
from mmengine import Config
from mmengine.runner import Runner
# 加载配置文件
config = Config.fromfile('configs/resnet/resnet50_8xb32_in1k.py')
# 通过配置文件初始化执行器
runner = Runner.build_from_cfg(config)
# 执行训练
runner.train()
# 执行测试
runner.test()
- 与手动构建模块来使用执行器不同的是,通过调用 Runner 类的 build_from_cfg 方法,执行器能够自动读取配置文件中的模块配置,从相应的注册器中构建所需要的模块,用户不再需要考虑训练和测试分别依赖哪些模块,也不需要为了切换训练的模型和数据而大量改动代码。
- 下面是一个典型的使用配置文件调用 MMClassification 中的模块训练分类器的简单例子:
# 工作目录,保存权重和日志
work_dir = './train_resnet'
# 默认注册器域
default_scope = 'mmcls' # 默认使用 `mmcls` (MMClassification) 注册器中的模块
# 模型配置
model = dict(type='ImageClassifier',
backbone=dict(type='ResNet', depth=50),
neck=dict(type='GlobalAveragePooling'),
head=dict(type='LinearClsHead',num_classes=1000))
# 数据配置
train_dataloader = dict(dataset=dict(type='ImageNet', pipeline=[...]),
sampler=dict(type='DefaultSampler', shuffle=True),
batch_size=32,
num_workers=4)
val_dataloader = ...
test_dataloader = ...
# 优化器配置
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
# 参数调度器配置
param_scheduler = dict(
type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
#验证和测试的评测器配置
val_evaluator = dict(type='Accuracy')
test_evaluator = dict(type='Accuracy')
# 训练、验证、测试流程配置
train_cfg = dict(
by_epoch=True,
max_epochs=100,
val_begin=20, # 从第 20 个 epoch 开始验证
val_interval=1 # 每隔一个 epoch 进行一次验证
)
val_cfg = dict()
test_cfg = dict()
# 自定义钩子 (可选)
custom_hooks = [...]
# 默认钩子 (可选,未在配置文件中写明时将使用默认配置)
default_hooks = dict(
runtime_info=dict(type='RuntimeInfoHook'), # 运行时信息钩子
timer=dict(type='IterTimerHook'), # 计时器钩子
sampler_seed=dict(type='DistSamplerSeedHook'), # 为每轮次的数据采样设置随机种子的钩子
logger=dict(type='TextLoggerHook'), # 训练日志钩子
param_scheduler=dict(type='ParamSchedulerHook'), # 参数调度器执行钩子
checkpoint=dict(type='CheckpointHook', interval=1), # 模型保存钩子
)
# 环境配置 (可选,未在配置文件中写明时将使用默认配置)
env_cfg = dict(
cudnn_benchmark=False, # 是否使用 cudnn_benchmark
dist_cfg=dict(backend='nccl'), # 分布式通信后端
mp_cfg=dict(mp_start_method='fork') # 多进程设置
)
# 日志处理器 (可选,未在配置文件中写明时将使用默认配置)
log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
# 日志等级配置
log_level = 'INFO'
# 加载权重的路径 (None 表示不加载)
load_from = None
# 从加载的权重文件中恢复训练
resume = False
- 一个完整的配置文件主要由模型、数据、优化器、参数调度器、评测器等模块的配置,训练、验证、测试等流程的配置,还有执行流程过程中的各种钩子模块的配置,以及环境和日志等其他配置的字段组成。 通过配置文件构建的执行器采用了懒初始化 (lazy initialization),只有当调用到训练或测试等执行函数时,才会根据配置文件去完整初始化所需要的模块。
3.3.3 加载权重或恢复训练
- 执行器可以通过 load_from 参数加载检查点(checkpoint)文件中的模型权重,只需要将 load_from 参数设置为检查点文件的路径即可。
runner = Runner(model=model,
test_dataloader=test_dataloader,
test_evaluator=test_evaluator,
load_from='./resnet50.pth')
- 如果是通过配置文件使用执行器,只需修改配置文件中的 load_from 字段即可。
- 用户也可通过设置 resume=True 来加载检查点中的训练状态信息来恢复训练。当 load_from 和 resume=True 同时被设置时,执行器将加载 load_from 路径对应的检查点文件中的训练状态。
- 如果仅设置 resume=True,执行器将会尝试从 work_dir 文件夹中寻找并读取最新的检查点文件
3.4 钩子(Hook)
- 钩子编程是一种编程模式,是指在程序的一个或者多个位置设置位点(挂载点),当程序运行至某个位点时,会自动调用运行时注册到位点的所有方法。钩子编程可以提高程序的灵活性和拓展性,用户将自定义的方法注册到位点便可被调用而无需修改程序中的代码。
3.4.1 内置钩子
- MMEngine 提供了很多内置的钩子,将内置钩子分为两类,分别是默认钩子以及自定义钩子,前者表示会默认往执行器注册,后者表示需要用户自己注册。
- 每个钩子都有对应的优先级,在同一位点,钩子的优先级越高,越早被执行器调用,如果优先级一样,被调用的顺序和钩子注册的顺序一致。优先级列表如下:
- HIGHEST (0)
- VERY_HIGH (10)
- HIGH (30)
- ABOVE_NORMAL (40)
- NORMAL (50)
- BELOW_NORMAL (60)
- LOW (70)
- VERY_LOW (90)
- LOWEST (100)
- 默认钩子
| 名称 | 用途 | 优先级 |
|---|---|---|
| RuntimeInfoHook | 往 message hub 更新运行时信息 | VERY_HIGH (10) |
| IterTimerHook | 统计迭代耗时 | NORMAL (50) |
| DistSamplerSeedHook | 确保分布式 Sampler 的 shuffle 生效 | NORMAL (50) |
| LoggerHook | 打印日志 | BELOW_NORMAL (60) |
| ParamSchedulerHook | 调用 ParamScheduler 的 step 方法 | LOW (70) |
| CheckpointHook | 按指定间隔保存权重 | VERY_LOW (90) |
- 自定义钩子
| 名称 | 用途 | 优先级 |
|---|---|---|
| EMAHook | 模型参数指数滑动平均 | NORMAL (50) |
| EmptyCacheHook | PyTorch CUDA 缓存清理 | NORMAL (50) |
| SyncBuffersHook | 同步模型的 buffer | NORMAL (50) |
| NaiveVisualizationHook | 可视化 | LOWEST (100) |
- 不建议修改默认钩子的优先级,因为优先级低的钩子可能会依赖优先级高的钩子。例如 CheckpointHook 的优先级需要比 ParamSchedulerHook 低,这样保存的优化器状态才是正确的状态。另外,自定义钩子的优先级默认为 NORMAL (50)。
- 两种钩子在执行器中的设置不同,默认钩子的配置传给执行器的 default_hooks 参数,自定义钩子的配置传给 custom_hooks 参数,如下所示:
from mmengine.runner import Runner
default_hooks = dict(
runtime_info=dict(type='RuntimeInfoHook'),
timer=dict(type='IterTimerHook'),
sampler_seed=dict(type='DistSamplerSeedHook'),
logger=dict(type='LoggerHook'),
param_scheduler=dict(type='ParamSchedulerHook'),
checkpoint=dict(type='CheckpointHook', interval=1),
)
custom_hooks = [
dict(type='NaiveVisualizationHook', priority='LOWEST'),
]
runner = Runner(default_hooks=default_hooks, custom_hooks=custom_hooks, ...)
runner.train()
3.4.1.1 CheckpointHook
- CheckpointHook 按照给定间隔保存模型的权重,如果是分布式多卡训练,则只有主(master)进程会保存权重。CheckpointHook 的主要功能如下:
- 按照间隔保存权重,支持按 epoch 数或者 iteration 数保存权重
# by_epoch 的默认值为 True, 每隔 5 个 epoch 保存一次权重
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, by_epoch=True))
# 以迭代次数作为保存间隔,则可以将 by_epoch 设为 False,
# interval=5 则表示每迭代 5 次保存一次权重
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, by_epoch=False))
- 保存最新的多个权重
# 假如一共训练 20 个 epoch,那么会在第 5, 10, 15, 20 个 epoch 保存模型,
# 但是在第 15 个 epoch 的时候会删除第 5 个 epoch 保存的权重,在第 20 个 epoch 的时候
# 会删除第 10 个 epoch 的权重,最终只有第 15 和第 20 个 epoch 的权重才会被保存。
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, max_keep_ckpts=2))
- 保存最优权重
# 如果想要保存训练过程验证集的最优权重,可以设置 save_best 参数,如果设置为 'auto',
# 则会根据验证集的第一个评价指标(验证集返回的评价指标是一个有序字典)判断当前权重是否最优。
default_hooks = dict(checkpoint=dict(type='CheckpointHook', save_best='auto'))
- 保存最优权重参数规则:
- 也可以直接指定 save_best 的值为评价指标,例如在分类任务中,可以指定为 save_best=‘top-1’,则会根据 ‘top-1’ 的值判断当前权重是否最优。
- 除了 save_best 参数,和保存最优权重相关的参数还有 rule,greater_keys 和 less_keys,这三者用来判断 save_best 的值是越大越好还是越小越好。例如指定了 save_best=‘top-1’,可以指定 rule=‘greater’,则表示该值越大表示权重越好。
- 指定保存权重的路径
- 权重默认保存在工作目录(work_dir),但可以通过设置 out_dir 改变保存路径。
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, out_dir='/path/of/directory'))
3.4.1.2 LoggerHook
- LoggerHook 负责收集日志并把日志输出到终端或者输出到文件、TensorBoard 等后端。
- 如果我们希望每迭代 20 次就输出(或保存)一次日志,我们可以设置 interval 参数,配置如下:
default_hooks = dict(logger=dict(type='LoggerHook', interval=20))
3.4.2 自定义钩子
- 如果 MMEngine 提供的默认钩子不能满足需求,用户可以自定义钩子,只需继承钩子基类并重写相应的位点方法。
- 例如,如果希望在训练的过程中判断损失值是否有效,如果值为无穷大则无效,我们可以在每次迭代后判断损失值是否无穷大,因此只需重写 after_train_iter 位点。
import torch
from mmengine.registry import HOOKS
from mmengine.hooks import Hook
@HOOKS.register_module()
class CheckInvalidLossHook(Hook):
"""Check invalid loss hook.
This hook will regularly check whether the loss is valid
during training.
Args:
interval (int): Checking interval (every k iterations).
Defaults to 50.
"""
def __init__(self, interval=50):
self.interval = interval
def after_train_iter(self, runner, batch_idx, data_batch=None, outputs=None):
"""All subclasses should override this method, if they need any
operations after each training iteration.
Args:
runner (Runner): The runner of the training process.
batch_idx (int): The index of the current batch in the train loop.
data_batch (dict or tuple or list, optional): Data from dataloader.
outputs (dict, optional): Outputs from model.
"""
if self.every_n_train_iters(runner, self.interval):
assert torch.isfinite(outputs['loss']),\
runner.logger.info('loss become infinite or NaN!')
- 我们只需将钩子的配置传给执行器的 custom_hooks 的参数,执行器初始化的时候会注册钩子
from mmengine.runner import Runner
custom_hooks = dict(
dict(type='CheckInvalidLossHook', interval=50)
)
runner = Runner(custom_hooks=custom_hooks, ...) # 实例化执行器,主要完成环境的初始化以及各种模块的构建
runner.train() # 执行器开始训练
3.5 模型(Model)
- 在训练深度学习任务时,我们通常需要定义一个模型来实现算法的主体。在基于 MMEngine 开发时,模型由执行器管理,需要实现 train_step,val_step 和 test_step 方法。
- 对于检测、识别、分割一类的深度学习任务,上述方法通常为标准的流程,例如在 train_step 里更新参数,返回损失;val_step 和 test_step 返回预测结果。因此 MMEngine 抽象出模型基类 BaseModel,实现了上述接口的标准流程。我们只需要让模型继承自模型基类,并按照一定的规范实现 forward,就能让模型在执行器中运行起来。
- 模型基类继承自模块基类,能够通过配置 init_cfg 灵活的选择初始化方式。
3.5.1 接口约定
3.5.1.1 forward
- forward: forward 的入参需要和 DataLoader 的输出保持一致 (自定义数据预处理器除外),如果 DataLoader 返回元组类型的数据 data,forward 需要能够接受 *data 的解包后的参数;如果返回字典类型的数据 data,forward 需要能够接受 **data 解包后的参数。 mode 参数用于控制 forward 的返回结果:
- mode=‘loss’:loss 模式通常在训练阶段启用,并返回一个损失字典。损失字典的 key-value 分别为损失名和可微的 torch.Tensor。字典中记录的损失会被用于更新参数和记录日志。模型基类会在 train_step 方法中调用该模式的 forward。
- mode=‘predict’: predict 模式通常在验证、测试阶段启用,并返回列表/元组形式的预测结果,预测结果需要和 process 接口的参数相匹配。OpenMMLab 系列算法对 predict 模式的输出有着更加严格的约定,需要输出列表形式的数据元素。模型基类会在 val_step,test_step 方法中调用该模式的 forward。
- mode=‘tensor’:tensor 和 predict 模式均返回模型的前向推理结果,区别在于 tensor 模式下,forward 会返回未经后处理的张量,例如返回未经非极大值抑制(nms)处理的检测结果,返回未经 argmax 处理的分类结果。我们可以基于 tensor 模式的结果进行自定义的后处理。
3.5.1.2 train_step
- train_step: 调用 loss 模式的 forward 接口,得到损失字典。模型基类基于优化器封装 实现了标准的梯度计算、参数更新、梯度清零流程。
3.5.1.3 val_step
- val_step: 调用 predict 模式的 forward,返回预测结果,预测结果会被进一步传给评测器的 process 接口和钩子(Hook)的 after_val_iter 接口。
3.5.1.4 test_step
- test_step: 同 val_step,预测结果会被进一步传给 after_test_iter 接口。
3.5.1.5 实例
- 基于上述接口约定,我们定义了继承自模型基类的 NeuralNetwork,配合执行器来训练 FashionMNIST:
from torch.utils.data import DataLoader
from torch import nn
from torchvision import datasets
from torchvision.transforms import ToTensor
from mmengine.model import BaseModel
from mmengine.evaluator import BaseMetric
from mmengine.runner import Runner
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(dataset=training_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
class NeuralNetwork(BaseModel):
def __init__(self, data_preprocessor=None):
super(NeuralNetwork, self).__init__(data_preprocessor)
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
self.loss = nn.CrossEntropyLoss()
def forward(self, img, label, mode='tensor'):
x = self.flatten(img)
pred = self.linear_relu_stack(x)
loss = self.loss(pred, label)
if mode == 'loss':
return dict(loss=loss)
elif mode=='predict':
return pred.argmax(1), loss.item()
else:
return pred
class FashionMnistMetric(BaseMetric):
def process(self, data, preds) -> None:
# data 参数为 Dataloader 返回的元组,即 (img, label)
# predict 为模型 `predict` 模式下,返回的元组,分别为 `pred.argmax(1) 和 `loss``
self.results.append(((data[1] == preds[0].cpu()).sum(), preds[1], len(preds[0])))
def compute_metrics(self, results):
correct, loss, batch_size = zip(*results)
test_loss, correct = sum(loss) / len(self.results), sum(correct) / sum(batch_size)
return dict(Accuracy=correct, Avg_loss=test_loss)
runner = Runner(
model=NeuralNetwork(),
work_dir='./work_dir',
train_dataloader=train_dataloader,
optim_wrapper=dict(optimizer=dict(type='SGD', lr=1e-3)),
train_cfg=dict(by_epoch=True, max_epochs=5, val_interval=1),
val_cfg=dict(fp16=True),
val_dataloader=test_dataloader,
val_evaluator=dict(metrics=FashionMnistMetric()))
runner.train()
- 在本例中,NeuralNetwork.forward 存在着以下跨模块的接口约定:
- 由于 train_dataloader 会返回一个 (img, label) 形式的元组,因此 forward 接口的前两个参数分别需要为 img 和 label。
- 由于 forward 在 predict 模式下会返回 (pred, loss) 形式的元组,因此 process 的 preds 参数应当同样为相同形式的元组。
3.5.2 数据预处理器(DataPreprocessor)
- 如果你的电脑配有 GPU(或其他能够加速训练的硬件,如 mps、ipu 等),并运行了上节的代码示例。你会发现 Pytorch 的示例是在 CPU 上运行的,而 MMEngine 的示例是在 GPU 上运行的。MMEngine 是在何时把数据和模型从 CPU 搬运到 GPU 的呢?
- 事实上,执行器会在构造阶段将模型搬运到指定设备,而数据则会在 train_step、val_step、test_step 中,被基础数据预处理器(BaseDataPreprocessor)搬运到指定设备,进一步将处理好的数据传给模型。数据预处理器作为模型基类的一个属性,会在模型基类的构造过程中被实例化。
- 为了体现数据预处理器起到的作用,我们仍然以上一节训练 FashionMNIST 为例, 实现了一个简易的数据预处理器,用于搬运数据和归一化:
from torch.optim import SGD
from mmengine.model import BaseDataPreprocessor, BaseModel
class NeuralNetwork1(NeuralNetwork):
def __init__(self, data_preprocessor):
super().__init__(data_preprocessor=data_preprocessor)
self.data_preprocessor = data_preprocessor
def train_step(self, data, optimizer):
img, label = self.data_preprocessor(data)
loss = self(img, label, mode='loss')['loss'].sum()
loss.backward()
optimizer.step()
optimizer.zero_grad()
return dict(loss=loss)
def test_step(self, data):
img, label = self.data_preprocessor(data)
return self(img, label, mode='predict')
def val_step(self, data):
img, label = self.data_preprocessor(data)
return self(img, label, mode='predict')
class NormalizeDataPreprocessor(BaseDataPreprocessor):
def forward(self, data, training=False):
img, label = [item for item in data]
img = (img - 127.5) / 127.5
return img, label
model = NeuralNetwork1(data_preprocessor=NormalizeDataPreprocessor())
optimizer = SGD(model.parameters(), lr=0.01)
data = (torch.full((3, 28, 28), fill_value=127.5), torch.ones(3, 10))
model.train_step(data, optimizer)
model.val_step(data)
model.test_step(data)
- 上例中,我们实现了 BaseModel.train_step、BaseModel.val_step 和 BaseModel.test_step 的简化版。数据经 NormalizeDataPreprocessor.forward 归一化处理,解包后传给 NeuralNetwork.forward,进一步返回损失或者预测结果。如果想实现自定义的参数优化或预测逻辑,可以自行实现 train_step、val_step 和 test_step,具体例子可以参考:使用 MMEngine 训练生成对抗网络
3.6 模型精度评测(Evaluation)
- 在模型验证和模型测试中,通常需要对模型精度做定量评测。在 MMEngine 中实现了评测指标(Metric)和评测器(Evaluator)模块来完成这一功能:
- 评测指标: 用于根据测试数据和模型预测结果,完成模型特定精度指标的计算。在 OpenMMLab 各算法库中提供了对应任务的常用评测指标,如 MMClassification 中提供了分类正确率指标(Accuracy) 用于计算分类模型的 Top-k 分类正确率。
- 评测器: 是评测指标的上层模块,用于在数据输入评测指标前完成必要的格式转换,并提供分布式支持。在模型训练和测试中,评测器由执行器(Runner)自动构建。用户亦可根据需求手动创建评测器,进行离线评测。
3.6.1 在模型训练或测试中进行评测
3.6.1.1 评测指标配置
- 在基于 MMEngine 进行模型训练或测试时,执行器会自动构建评测器进行评测,用户只需要在配置文件中通过 val_evaluator 和 test_evaluator 2 个字段分别指定模型验证和测试阶段的评测指标即可。例如,用户在使用 MMClassification 训练分类模型时,希望在模型验证阶段评测 top-1 和 top-5 分类正确率,可以按以下方式配置:
val_evaluator = dict(type='Accuracy', top_k=(1, 5)) # 使用分类正确率评测指标
- 如果需要同时评测多个指标,也可以将 val_evaluator 或 test_evaluator 设置为一个列表,其中每一项为一个评测指标的配置信息。例如,在使用 MMDetection 训练全景分割模型时,希望在模型测试阶段同时评测模型的目标检测(COCO AP/AR)和全景分割精度,可以按以下方式配置:
test_evaluator = [
# 目标检测指标
dict(
type='COCOMetric',
metric=['bbox', 'segm'],
ann_file='annotations/instances_val2017.json',
),
# 全景分割指标
dict(
type='CocoPanopticMetric',
ann_file='annotations/panoptic_val2017.json',
seg_prefix='annotations/panoptic_val2017',
)
]
3.6.1.2 自定义评测指标
- 如果算法库中提供的常用评测指标无法满足需求,用户也可以增加自定义的评测指标。具体的方法可以参考评测指标和评测器设计。
3.6.2 使用离线结果进行评测
- 另一种常见的模型评测方式,是利用提前保存在文件中的模型预测结果进行离线评测。此时,由于不存在执行器,用户需要手动构建评测器,并调用评测器的相应接口完成评测。以下是一个离线评测示例:
from mmengine.evaluator import Evaluator
from mmengine.fileio import load
# 构建评测器。参数 `metrics` 为评测指标配置
evaluator = Evaluator(metrics=dict(type='Accuracy', top_k=(1, 5)))
# 从文件中读取测试数据。数据格式需要参考具使用的 metric。
data = load('test_data.pkl')
# 从文件中读取模型预测结果。该结果由待评测算法在测试数据集上推理得到。
# 数据格式需要参考具使用的 metric。
predictions = load('prediction.pkl')
# 调用评测器离线评测接口,得到评测结果
# chunk_size 表示每次处理的样本数量,可根据内存大小调整
results = evaluator.offline_evaluate(data, predictions, chunk_size=128)
3.7 优化器封装(OptimWrapper)
- MMEngine 实现了优化器封装,为用户提供了统一的优化器访问接口。优化器封装支持不同的训练策略,包括混合精度训练、梯度累加和梯度截断。用户可以根据需求选择合适的训练策略。优化器封装还定义了一套标准的参数更新流程,用户可以基于这一套流程,实现同一套代码,不同训练策略的切换。
3.7.1 优化器封装 vs 优化器
- 分别基于 Pytorch 内置的优化器和 MMEngine 的优化器封装进行单精度训练、混合精度训练和梯度累加,对比二者实现上的区别。
3.7.1.1 基于 Pytorch 的 SGD 优化器实现单精度训练
import torch
from torch.optim import SGD
import torch.nn as nn
import torch.nn.functional as F
inputs = [torch.zeros(10, 1, 1)] * 10
targets = [torch.ones(10, 1, 1)] * 10
model = nn.Linear(1, 1)
optimizer = SGD(model.parameters(), lr=0.01)
optimizer.zero_grad()
for input, target in zip(inputs, targets):
output = model(input)
loss = F.l1_loss(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
3.7.1.2 使用 MMEngine 的优化器封装实现单精度训练
from mmengine.optim import OptimWrapper
optim_wrapper = OptimWrapper(optimizer=optimizer)
for input, target in zip(inputs, targets):
output = model(input)
loss = F.l1_loss(output, target)
optim_wrapper.update_params(loss)

- 优化器封装的 update_params 实现了标准的梯度计算、参数更新和梯度清零流程,可以直接用来更新模型参数。
3.7.1.3 基于 Pytorch 的 SGD 优化器实现混合精度训练
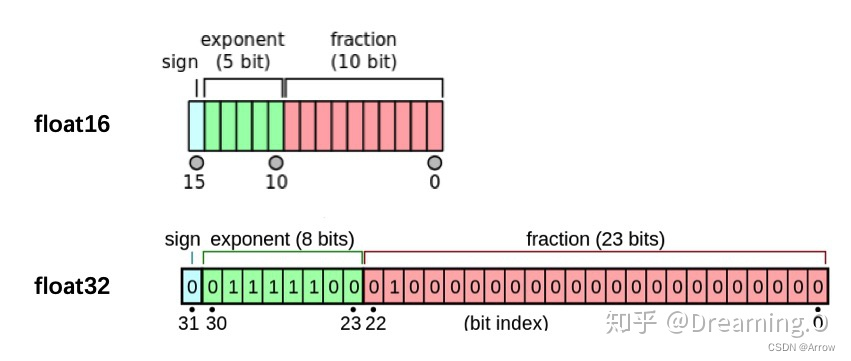
- 混合精度训练:单精度 float和半精度 float16 混合,其优势为:
- 内存占用更少
- 计算更快
from torch.cuda.amp import autocast
model = model.cuda()
inputs = [torch.zeros(10, 1, 1, 1)] * 10
targets = [torch.ones(10, 1, 1, 1)] * 10
for input, target in zip(inputs, targets):
with autocast():
output = model(input.cuda())
loss = F.l1_loss(output, target.cuda())
loss.backward()
optimizer.step()
optimizer.zero_grad()
3.7.1.4 基于 MMEngine 的 优化器封装实现混合精度训练
from mmengine.optim import AmpOptimWrapper
optim_wrapper = AmpOptimWrapper(optimizer=optimizer)
for input, target in zip(inputs, targets):
with optim_wrapper.optim_context(model):
output = model(input.cuda())
loss = F.l1_loss(output, target.cuda())
optim_wrapper.update_params(loss)

- 混合精度训练需要使用 AmpOptimWrapper,他的 optim_context 接口类似 autocast,会开启混合精度训练的上下文。除此之外他还能加速分布式训练时的梯度累加,这个我们会在下一个示例中介绍
3.7.1.5 基于 Pytorch 的 SGD 优化器实现混合精度训练和梯度累加
for idx, (input, target) in enumerate(zip(inputs, targets)):
with autocast():
output = model(input.cuda())
loss = F.l1_loss(output, target.cuda())
loss.backward()
if idx % 2 == 0:
optimizer.step()
optimizer.zero_grad()
3.7.1.6 基于 MMEngine 的优化器封装实现混合精度训练和梯度累加
optim_wrapper = AmpOptimWrapper(optimizer=optimizer, accumulative_counts=2)
for input, target in zip(inputs, targets):
with optim_wrapper.optim_context(model):
output = model(input.cuda())
loss = F.l1_loss(output, target.cuda())
optim_wrapper.update_params(loss)

- 只需要配置 accumulative_counts 参数,并调用 update_params 接口就能实现梯度累加的功能。除此之外,分布式训练情况下,如果我们配置梯度累加的同时开启了 optim_wrapper 上下文,可以避免梯度累加阶段不必要的梯度同步。
- 优化器封装同样提供了更细粒度的接口,方便用户实现一些自定义的参数更新逻辑:
- backward:传入损失,用于计算参数梯度
- step: 同 optimizer.step,用于更新参数
- zero_grad: 同 optimizer.zero_grad,用于参数的梯度清0
- 可以使用上述接口实现和 Pytorch 优化器相同的参数更新逻辑:
for idx, (input, target) in enumerate(zip(inputs, targets)):
optimizer.zero_grad()
with optim_wrapper.optim_context(model):
output = model(input.cuda())
loss = F.l1_loss(output, target.cuda())
optim_wrapper.backward(loss) # 计算参数梯度
if idx % 2 == 0:
optim_wrapper.step() # 更新参数
optim_wrapper.zero_grad() # 参数的梯度清0
- 为优化器封装配置梯度裁减策略:
# 基于 torch.nn.utils.clip_grad_norm_ 对梯度进行裁减
optim_wrapper = AmpOptimWrapper(
optimizer=optimizer, clip_grad=dict(max_norm=1))
# 基于 torch.nn.utils.clip_grad_value_ 对梯度进行裁减
optim_wrapper = AmpOptimWrapper(
optimizer=optimizer, clip_grad=dict(clip_value=0.2))
3.7.1.7 获取学习率/动量
- 优化器封装提供了 get_lr 和 get_momentum 接口用于获取优化器的一个参数组的学习率
import torch.nn as nn
from torch.optim import SGD
from mmengine.optim import OptimWrapper
model = nn.Linear(1, 1)
optimizer = SGD(model.parameters(), lr=0.01)
optim_wrapper = OptimWrapper(optimizer)
print(optimizer.param_groups[0]['lr']) # -1.01
print(optimizer.param_groups[0]['momentum']) # 0
print(optim_wrapper.get_lr()) # {'lr': [0.01]}
print(optim_wrapper.get_momentum()) # {'momentum': [0]}
# 输出结果
#0.01
#0
#{'lr': [0.01]}
#{'momentum': [0]}
3.7.1.8 导出/加载状态字典
- 优化器封装和优化器一样,提供了 state_dict 和 load_state_dict 接口,用于导出/加载优化器状态,对于 AmpOptimWrapper,优化器封装还会额外导出混合精度训练相关的参数:
import torch.nn as nn
from torch.optim import SGD
from mmengine.optim import OptimWrapper, AmpOptimWrapper
model = nn.Linear(1, 1)
optimizer = SGD(model.parameters(), lr=0.01)
optim_wapper = OptimWrapper(optimizer=optimizer)
amp_optim_wapper = AmpOptimWrapper(optimizer=optimizer)
# 导出状态字典
optim_state_dict = optim_wapper.state_dict()
amp_optim_state_dict = amp_optim_wapper.state_dict()
print(optim_state_dict)
print(amp_optim_state_dict)
optim_wapper_new = OptimWrapper(optimizer=optimizer)
amp_optim_wapper_new = AmpOptimWrapper(optimizer=optimizer)
# 加载状态字典
amp_optim_wapper_new.load_state_dict(amp_optim_state_dict)
optim_wapper_new.load_state_dict(optim_state_dict)
- 输出结果:
{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'params': [0, 1]}]}
{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'params': [0, 1]}], 'loss_scaler': {'scale': 65536.0, 'growth_factor': 2.0, 'backoff_factor': 0.5, 'growth_interval': 2000, '_growth_tracker': 0}}
3.7.1.9 使用多个优化器
- 考虑到生成对抗网络之类的算法通常需要使用多个优化器来训练生成器和判别器,因此优化器封装提供了优化器封装的容器类:OptimWrapperDict 来管理多个优化器封装。OptimWrapperDict 以字典的形式存储优化器封装,并允许用户像字典一样访问、遍历其中的元素,即优化器封装实例。
- 与普通的优化器封装不同,OptimWrapperDict 没有实现 update_params、 optim_context, backward、step 等方法,无法被直接用于训练模型。我们建议直接访问 OptimWrapperDict 管理的优化器实例,来实现参数更新逻辑。
- 你或许会好奇,既然 OptimWrapperDict 没有训练的功能,那为什么不直接使用 dict 来管理多个优化器。事实上,OptimWrapperDict 的核心功能是支持批量导出/加载所有优化器封装的状态字典;支持获取多个优化器封装的学习率、动量。如果没有 OptimWrapperDict,MMEngine 就需要在很多位置对优化器封装的类型做 if else 判断,以获取所有优化器封装的状态。
from torch.optim import SGD
import torch.nn as nn
from mmengine.optim import OptimWrapper, OptimWrapperDict
gen = nn.Linear(1, 1)
disc = nn.Linear(1, 1)
optimizer_gen = SGD(gen.parameters(), lr=0.01)
optimizer_disc = SGD(disc.parameters(), lr=0.01)
optim_wapper_gen = OptimWrapper(optimizer=optimizer_gen)
optim_wapper_disc = OptimWrapper(optimizer=optimizer_disc)
optim_dict = OptimWrapperDict(gen=optim_wapper_gen, disc=optim_wapper_disc)
print(optim_dict.get_lr()) # {'gen.lr': [0.01], 'disc.lr': [0.01]}
print(optim_dict.get_momentum()) # {'gen.momentum': [0], 'disc.momentum': [0]}
- 输出内容:
{'gen.lr': [0.01], 'disc.lr': [0.01]}
{'gen.momentum': [0], 'disc.momentum': [0]}
- 如上例所示,OptimWrapperDict 可以非常方便的导出所有优化器封装的学习率和动量,同样的,优化器封装也能够导出/加载所有优化器封装的状态字典。
3.7.2 在执行器中配置优化器封装
3.7.2.1 简单配置
- 优化器封装需要接受 optimizer 参数,因此我们首先需要为优化器封装配置 optimizer。 MMEngine 会自动将 PyTorch 中的所有优化器都添加进 OPTIMIZERS 注册表中,用户可以用字典的形式来指定优化器,所有支持的优化器见 PyTorch 优化器列表。
- 以配置一个 SGD 优化器封装为例:
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer)
- 这样我们就配置好了一个优化器类型为 SGD 的优化器封装,学习率、动量等参数如配置所示。考虑到 OptimWrapper 为标准的单精度训练,因此我们也可以不配置 type 字段:
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optim_wrapper = dict(optimizer=optimizer)
- 要想开启混合精度训练和梯度累加,需要将 type 切换成 AmpOptimWrapper,并指定 accumulative_counts 参数
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optim_wrapper = dict(type='AmpOptimWrapper', optimizer=optimizer, accumulative_counts=2)
3.8 优化器参数调整策略(Parameter Scheduler)
- 在模型训练过程中,我们往往不是采用固定的优化参数,例如学习率等,会随着训练轮数的增加进行调整。最简单常见的学习率调整策略就是阶梯式下降,例如每隔一段时间将学习率降低为原来的几分之一。PyTorch 中有学习率调度器 LRScheduler 来对各种不同的学习率调整方式进行抽象,但支持仍然比较有限,在 MMEngine 中,我们对其进行了拓展,实现了更通用的参数调度器,可以对学习率、动量等优化器相关的参数进行调整,并且支持多个调度器进行组合,应用更复杂的调度策略。
3.8.1 参数调度器的使用
- 这里我们先简单介绍一下如何使用 PyTorch 内置的学习率调度器来进行学习率的调整。下面是参考 PyTorch 官方文档 实现的一个例子,我们构造一个 ExponentialLR,并且在每个 epoch 结束后调用 scheduler.step(),实现了随 epoch 指数下降的学习率调整策略。
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR
model = torch.nn.Linear(1, 1)
dataset = [torch.randn((1, 1, 1)) for _ in range(20)]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(10):
for data in dataset:
optimizer.zero_grad()
output = model(data)
loss = 1 - output
loss.backward()
optimizer.step()
scheduler.step()
- 在 MMEngine 中,我们支持大部分 PyTorch 中的学习率调度器,例如 ExponentialLR,LinearLR,StepLR,MultiStepLR 等,使用方式也基本一致,所有支持的调度器见调度器接口文档。同时增加了对动量的调整,在类名中将 LR 替换成 Momentum 即可,例如 ExponentialMomentum,LinearMomentum。更进一步地,我们实现了通用的参数调度器 ParamScheduler,用于调整优化器的中的其他参数,包括 weight_decay 等。这个特性可以很方便地配置一些新算法中复杂的调整策略。
- 与 PyTorch 文档中所给示例不同,MMEngine 中通常不需要手动来实现训练循环以及调用 optimizer.step(),而是在执行器(Runner)中对训练流程进行自动管理,同时通过 ParamSchedulerHook 来控制参数调度器的执行。
3.8.2 使用单一的学习率调度器
- 如果整个训练过程只需要使用一个学习率调度器, 那么和 PyTorch 自带的学习率调度器没有差异。
from mmengine.optim.scheduler import MultiStepLR
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = MultiStepLR(optimizer, milestones=[8, 11], gamma=0.1)
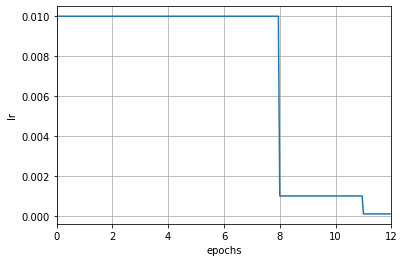
- 如果配合注册器和配置文件使用的话,我们可以设置配置文件中的 scheduler 字段来指定优化器, 执行器(Runner)会根据此字段以及执行器中的优化器自动构建学习率调度器:
scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.1)
- 注意这里增加了初始化参数 by_epoch,控制的是学习率调整频率,当其为 True 时表示按轮次(epoch) 调整,为 False 时表示按迭代次数(iteration)调整,默认值为 True。 在上面的例子中,表示按照轮次进行调整,此时其他参数的单位均为 epoch,例如 milestones 中的 [8, 11] 表示第 8 和 11 轮次结束时,学习率将会被调整为上一轮次的 0.1 倍。
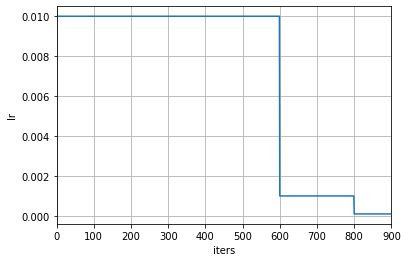
- 当修改了学习率调整频率后,调度器中与计数相关设置的含义也会相应被改变。当 by_epoch=True 时,milestones 中的数字表示在哪些轮次进行学习率衰减,而当 by_epoch=False 时则表示在进行到第几次迭代时进行学习率衰减。下面是一个按照迭代次数进行调整的例子,在第 600 和 800 次迭代结束时,学习率将会被调整为原来的 0.1 倍。
scheduler = dict(type='MultiStepLR', by_epoch=False, milestones=[600, 800], gamma=0.1)
3.9 数据变换 (Data Transform)
- 在 OpenMMLab 算法库中,数据集的构建和数据的准备是相互解耦的。通常,数据集的构建只对数据集进行解析,记录每个样本的基本信息;而数据的准备则是通过一系列的数据变换,根据样本的基本信息进行数据加载、预处理、格式化等操作。
3.9.1 使用数据变换类
- 在 MMEngine 中,我们使用各种可调用的数据变换类来进行数据的操作。这些数据变换类可以接受若干配置参数进行实例化,之后通过调用的方式对输入的数据字典进行处理。 同时,我们约定所有数据变换都接受一个字典作为输入,并将处理后的数据输出为一个字典。一个简单的例子如下:
import numpy as np
from mmcv.transforms import Resize
transform = Resize(scale=(224, 224))
data_dict = {'img': np.random.rand(256, 256, 3)}
data_dict = transform(data_dict)
print(data_dict['img'].shape)
# (224, 224, 3)
3.9.2 在配置文件中使用
- 在配置文件中,我们将一系列数据变换组合成为一个列表,称为数据流水线(Data Pipeline),传给数据集的 pipeline 参数。通常数据流水线由以下几个部分组成:
- 数据加载,通常使用 LoadImageFromFile
- 标签加载,通常使用 LoadAnnotations
- 数据处理及增强,例如 RandomResize
- 数据格式化,根据任务不同,在各个仓库使用自己的变换操作,通常名为 PackXXXInputs,其中 XXX 是任务的名称,如 分类任务中的 PackClsInputs。
- 以分类任务为例,我们在下图展示了一个典型的数据流水线。对每个样本,数据集中保存的基本信息是一个如图中最左侧所示的字典,之后每经过一个由蓝色块代表的数据变换操作,数据字典中都会加入新的字段(标记为绿色)或更新现有的字段(标记为橙色)。
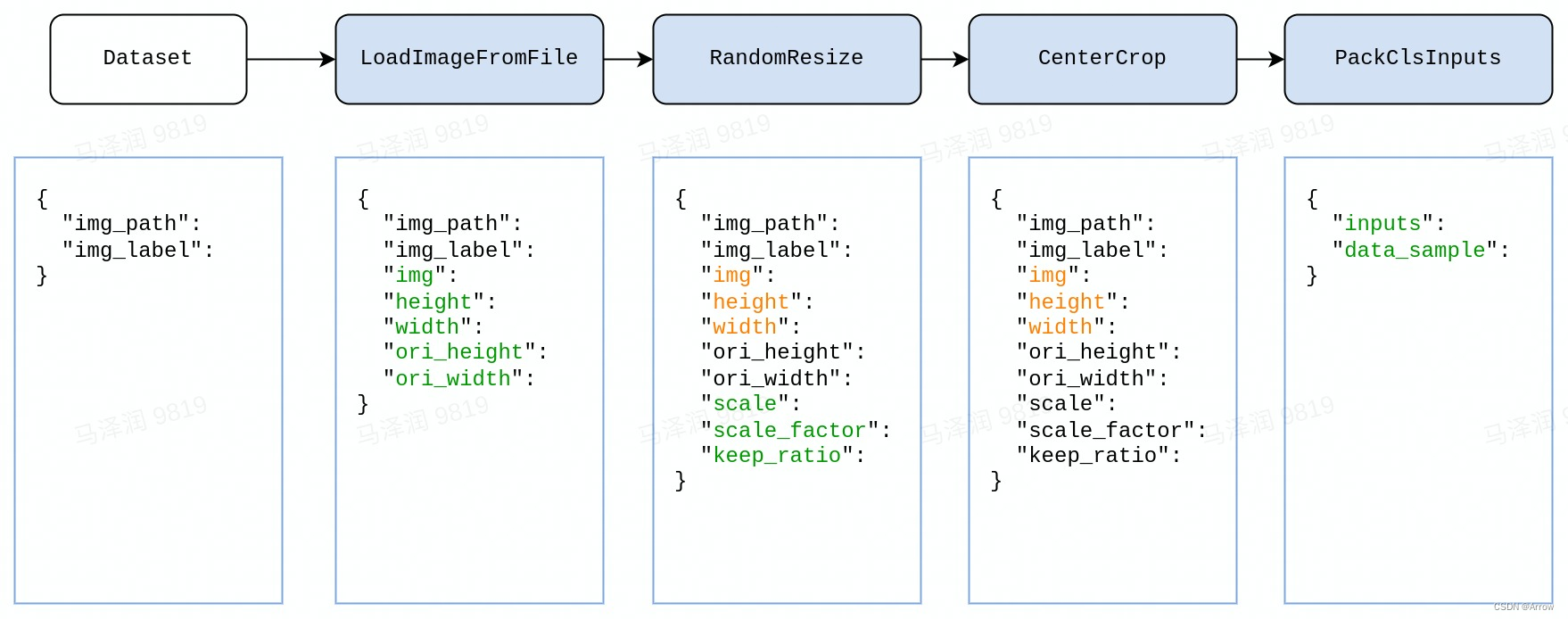
- 如果我们希望在测试中使用上述数据流水线,则配置文件如下所示:
test_dataloader = dict(
batch_size=32,
dataset=dict(
type='ImageNet',
data_root='data/imagenet',
pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=256, keep_ratio=True),
dict(type='CenterCrop', crop_size=224),
dict(type='PackClsInputs'),
]
)
)
3.9.3 常用的数据变换类
- 按照功能,常用的数据变换类可以大致分为数据加载、数据预处理与增强、数据格式化。我们在 MMCV 中提供了一系列常用的数据变换类:
3.9.3.1 数据加载
- 为了支持大规模数据集的加载,通常在数据集初始化时不加载数据,只加载相应的路径。因此需要在数据流水线中进行具体数据的加载。
| 数据变换类 | 功能 |
|---|---|
| LoadImageFromFile | 根据路径加载图像 |
| LoadAnnotations | 加载和组织标注信息,如 bbox、语义分割图等 |
3.9.3.2 数据预处理及增强
- 数据预处理和增强通常是对图像本身进行变换,如裁剪、填充、缩放等。
| 数据变换类 | 功能 |
|---|---|
| Pad | 填充图像边缘 |
| CenterCrop | 居中裁剪 |
| Normalize | 对图像进行归一化 |
| Resize | 按照指定尺寸或比例缩放图像 |
| RandomResize | 缩放图像至指定范围的随机尺寸 |
| RandomChoiceResize | 缩放图像至多个尺寸中的随机一个尺寸 |
| RandomGrayscale | 随机灰度化 |
| RandomFlip | 图像随机翻转 |
3.9.3.3 数据格式化
- 数据格式化操作通常是对数据进行的类型转换。
| 数据变换类 | 功能 |
|---|---|
| ToTensor | 将指定的数据转换为 torch.Tensor |
| ImageToTensor | 将图像转换为 torch.Tensor |
3.9.4 自定义数据变换类
- 要实现一个新的数据变换类,需要继承 BaseTransform,并实现 transform 方法。这里,我们使用一个简单的翻转变换(MyFlip)作为示例:
import random
import mmcv
from mmcv.transforms import BaseTransform, TRANSFORMS
@TRANSFORMS.register_module()
class MyFlip(BaseTransform):
def __init__(self, direction: str):
super().__init__()
self.direction = direction
def transform(self, results: dict) -> dict:
img = results['img']
results['img'] = mmcv.imflip(img, direction=self.direction)
return results
- 从而,我们可以实例化一个 MyFlip 对象,并将之作为一个可调用对象,来处理我们的数据字典。
import numpy as np
transform = MyFlip(direction='horizontal')
data_dict = {'img': np.random.rand(224, 224, 3)}
data_dict = transform(data_dict)
processed_img = data_dict['img']
- 又或者,在配置文件的 pipeline 中使用 MyFlip 变换
pipeline = [
...
dict(type='MyFlip', direction='horizontal'),
...
]
4. 高级模块
4.1 数据集基类(BaseDataset)
4.1.1 基本介绍
- 算法库中的数据集类负责在训练/测试过程中为模型提供输入数据,OpenMMLab 下各个算法库中的数据集有一些共同的特点和需求,比如需要高效的内部数据存储格式,需要支持数据集拼接、数据集重复采样等功能。
- 因此 MMEngine 实现了一个数据集基类(BaseDataset)并定义了一些基本接口,且基于这套接口实现了一些数据集包装(DatasetWrapper)。OpenMMLab 算法库中的大部分数据集都会满足这套数据集基类定义的接口,并使用统一的数据集包装。
- 数据集基类的基本功能是加载数据集信息,这里我们将数据集信息分成两类:
- 一种是元信息 (meta information),代表数据集自身相关的信息,有时需要被模型或其他外部组件获取,比如在图像分类任务中,数据集的元信息一般包含类别信息 classes,因为分类模型 model 一般需要记录数据集的类别信息;
- 另一种为数据信息 (data information),在数据信息中,定义了具体样本的文件路径、对应标签等的信息。除此之外,数据集基类的另一个功能为不断地将数据送入数据流水线(data pipeline)中,进行数据预处理。
4.1.1.1 数据标注文件规范
- 为了统一不同任务的数据集接口,便于多任务的算法模型训练,OpenMMLab 制定了 OpenMMLab 2.0 数据集格式规范, 数据集标注文件需符合该规范,数据集基类基于该规范去读取与解析数据标注文件。如果用户提供的数据标注文件不符合规定格式,用户可以选择将其转化为规定格式,并使用 OpenMMLab 的算法库基于该数据标注文件进行算法训练和测试。
- OpenMMLab 2.0 数据集格式规范规定,标注文件必须为 json 或 yaml,yml 或 pickle,pkl 格式;标注文件中存储的字典必须包含 metainfo 和 data_list 两个字段。
- metainfo: 是一个字典,里面包含数据集的元信息;
- data_list: 是一个列表,列表中每个元素是一个字典,该字典定义了一个原始数据(raw data),每个原始数据包含一个或若干个训练/测试样本。
- 以下是一个 JSON 标注文件的例子(该例子中每个原始数据只包含一个训练/测试样本):
{
'metainfo':
{
'classes': ('cat', 'dog'),
...
},
'data_list':
[
{
'img_path': "xxx/xxx_0.jpg",
'img_label': 0,
...
},
{
'img_path': "xxx/xxx_1.jpg",
'img_label': 1,
...
},
...
]
}
- 同时假设数据存放路径如下:
data
├── annotations
│ ├── train.json
├── train
│ ├── xxx/xxx_0.jpg
│ ├── xxx/xxx_1.jpg
│ ├── ...
4.1.1.2 数据集基类的初始化流程
- 数据集基类的初始化流程如下图所示:
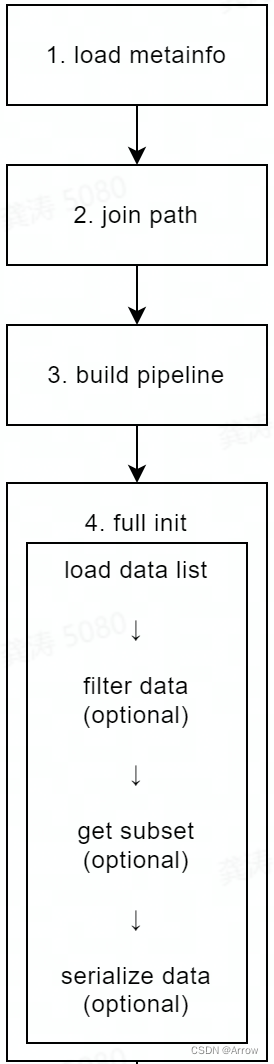
- load metainfo:获取数据集的元信息,元信息有三种来源,优先级从高到低为:
- __init__() 方法中用户传入的 metainfo 字典;改动频率最高,因为用户可以在实例化数据集时,传入该参数;
- 类属性 BaseDataset.METAINFO 字典;改动频率中等,因为用户可以改动自定义数据集类中的类属性 BaseDataset.METAINFO;
- 标注文件中包含的 metainfo 字典;改动频率最低,因为标注文件一般不做改动。
- 如果三种来源中有相同的字段,优先级最高的来源决定该字段的值,这些字段的优先级比较是:用户传入的 metainfo 字典里的字段 > BaseDataset.METAINFO 字典里的字段 > 标注文件中 metainfo 字典里的字段。
- join path:处理数据与标注文件的路径;
- build pipeline:构建数据流水线(data pipeline),用于数据预处理与数据准备;
- full init:完全初始化数据集类,该步骤主要包含以下操作:
- load data list:读取与解析满足 OpenMMLab 2.0 数据集格式规范的标注文件,该步骤中会调用 parse_data_info() 方法,该方法负责解析标注文件里的每个原始数据;
- filter data (可选):根据 filter_cfg 过滤无用数据,比如不包含标注的样本等;默认不做过滤操作,下游子类可以按自身所需对其进行重写;
- get subset (可选):根据给定的索引或整数值采样数据,比如只取前 10 个样本参与训练/测试;默认不采样数据,即使用全部数据样本;
- serialize data (可选):序列化全部样本,以达到节省内存的效果,详情请参考节省内存;默认操作为序列化全部样本。
- 数据集基类中包含的 parse_data_info() 方法用于将标注文件里的一个原始数据处理成一个或若干个训练/测试样本的方法。因此对于自定义数据集类,用户需要实现 parse_data_info() 方法。
4.1.1.3 数据集基类提供的接口
- 与 torch.utils.data.Dataset 类似,数据集初始化后,支持 __getitem__ 方法,用来索引数据,以及 __len__ 操作获取数据集大小,除此之外,OpenMMLab 的数据集基类主要提供了以下接口来访问具体信息:
- metainfo:返回元信息,返回值为字典
- get_data_info(idx):返回指定 idx 的样本全量信息,返回值为字典
- __getitem__(idx):返回指定 idx 的样本经过 pipeline 之后的结果(也就是送入模型的数据),返回值为字典
- __len__():返回数据集长度,返回值为整数型
- get_subset_(indices):根据 indices 以 inplace 的方式修改原数据集类。如果 indices 为 int,则原数据集类只包含前若干个数据样本;如果 indices 为 Sequence[int],则原数据集类包含根据 Sequence[int] 指定的数据样本。
- get_subset(indices):根据 indices 以非 inplace 的方式返回子数据集类,即重新复制一份子数据集。如果 indices 为 int,则返回的子数据集类只包含前若干个数据样本;如果 indices 为 Sequence[int],则返回的子数据集类包含根据 Sequence[int] 指定的数据样本。
4.1.2 使用数据集基类自定义数据集类
- 在了解了数据集基类的初始化流程与提供的接口之后,就可以基于数据集基类自定义数据集类。
4.1.2.1 对于满足 OpenMMLab 2.0 数据集格式规范的标注文件
- 如上所述,对于满足 OpenMMLab 2.0 数据集格式规范的标注文件,用户可以重载 parse_data_info() 来加载标签。以下是一个使用数据集基类来实现某一具体数据集的例子。
import os.path as osp
from mmengine.dataset import BaseDataset
class ToyDataset(BaseDataset):
# 以上面标注文件为例,在这里 raw_data_info 代表 `data_list` 对应列表里的某个字典:
# {
# 'img_path': "xxx/xxx_0.jpg",
# 'img_label': 0,
# ...
# }
def parse_data_info(self, raw_data_info):
data_info = raw_data_info
img_prefix = self.data_prefix.get('img_path', None)
if img_prefix is not None:
data_info['img_path'] = osp.join(
img_prefix, data_info['img_path'])
return data_info
- 使用自定义数据集类:在定义了数据集类后,就可以通过如下配置实例化 ToyDataset:
class LoadImage:
def __call__(self, results):
results['img'] = cv2.imread(results['img_path'])
return results
class ParseImage:
def __call__(self, results):
results['img_shape'] = results['img'].shape
return results
pipeline = [
LoadImage(),
ParseImage(),
]
toy_dataset = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='train/'),
ann_file='annotations/train.json',
pipeline=pipeline)
- 同时可以使用数据集类提供的对外接口访问具体的样本信息:
toy_dataset.metainfo
# dict(classes=('cat', 'dog'))
toy_dataset.get_data_info(0)
# {
# 'img_path': "data/train/xxx/xxx_0.jpg",
# 'img_label': 0,
# ...
# }
len(toy_dataset)
# 2
toy_dataset[0]
# {
# 'img_path': "data/train/xxx/xxx_0.jpg",
# 'img_label': 0,
# 'img': a ndarray with shape (H, W, 3), which denotes the value of the image,
# 'img_shape': (H, W, 3) ,
# ...
# }
# `get_subset` 接口不对原数据集类做修改,即完全复制一份新的
sub_toy_dataset = toy_dataset.get_subset(1)
len(toy_dataset), len(sub_toy_dataset)
# 2, 1
# `get_subset_` 接口会对原数据集类做修改,即 inplace 的方式
toy_dataset.get_subset_(1)
len(toy_dataset)
# 1
-
经过以上步骤,可以了解基于数据集基类如何自定义新的数据集类,以及如何使用自定义数据集类。
-
自定义视频的数据集类:在上面的例子中,标注文件的每个原始数据只包含一个训练/测试样本(通常是图像领域)。如果每个原始数据包含若干个训练/测试样本(通常是视频领域),则只需保证 parse_data_info() 的返回值为 list[dict] 即可:
from mmengine.dataset import BaseDataset
class ToyVideoDataset(BaseDataset):
# raw_data_info 仍为一个字典,但它包含了多个样本
def parse_data_info(self, raw_data_info):
data_list = []
...
for ... :
data_info = dict()
...
data_list.append(data_info)
return data_list
4.1.2.2 对于不满足 OpenMMLab 2.0 数据集格式规范的标注文件
- 对于不满足 OpenMMLab 2.0 数据集格式规范的标注文件,有两种方式来使用数据集基类:
- 将不满足规范的标注文件转换成满足规范的标注文件,再通过上述方式使用数据集基类。
- 实现一个新的数据集类,继承自数据集基类,并且重载数据集基类的 load_data_list(self): 函数,处理不满足规范的标注文件,并保证返回值为 list[dict],其中每个 dict 代表一个数据样本。
4.1.3 数据集基类的其它特性
4.1.3.1 懒加载(lazy init)
- 在数据集类实例化时,需要读取并解析标注文件,因此会消耗一定时间。然而在某些情况比如预测可视化时,往往只需要数据集类的元信息,可能并不需要读取与解析标注文件。为了节省这种情况下数据集类实例化的时间,数据集基类支持懒加载:
pipeline = [
LoadImage(),
ParseImage(),
]
toy_dataset = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='train/'),
ann_file='annotations/train.json',
pipeline=pipeline,
# 在这里传入 lazy_init 变量
lazy_init=True)
- 当 lazy_init=True 时,ToyDataset 的初始化方法只执行了数据集基类的初始化流程中的 1、2、3 步骤,此时 toy_dataset 并未被完全初始化,因为 toy_dataset 并不会读取与解析标注文件,只会设置数据集类的元信息(metainfo)。
- 自然的,如果之后需要访问具体的数据信息,可以手动调用 toy_dataset.full_init() 接口来执行完整的初始化过程,在这个过程中数据标注文件将被读取与解析。调用 get_data_info(idx), len(), getitem(idx),get_subset_(indices), get_subset(indices) 接口也会自动地调用 full_init() 接口来执行完整的初始化过程(仅在第一次调用时,之后调用不会重复地调用 full_init() 接口):
# 完整初始化
toy_dataset.full_init()
# 初始化完毕,现在可以访问具体数据
len(toy_dataset)
# 2
toy_dataset[0]
# {
# 'img_path': "data/train/xxx/xxx_0.jpg",
# 'img_label': 0,
# 'img': a ndarray with shape (H, W, 3), which denotes the value the image,
# 'img_shape': (H, W, 3) ,
# ...
# }
- 以上通过设置 lazy_init=True 未进行完全初始化,之后根据需求再进行完整初始化的方式,称为懒加载。
4.1.3.2 节省内存
- 在具体的读取数据过程中,数据加载器(dataloader)通常会起多个 worker 来预取数据,多个 worker 都拥有完整的数据集类备份,因此内存中会存在多份相同的 data_list,为了节省这部分内存消耗,数据集基类可以提前将 data_list 序列化存入内存中,使得多个 worker 可以共享同一份 data_list,以达到节省内存的目的。
数据集基类默认是将 data_list 序列化存入内存,也可以通过 serialize_data 变量(默认为 True)来控制是否提前将 data_list 序列化存入内存中:
pipeline = [
LoadImage(),
ParseImage(),
]
toy_dataset = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='train/'),
ann_file='annotations/train.json',
pipeline=pipeline,
# 在这里传入 serialize_data 变量
serialize_data=False)
- 上面例子不会提前将 data_list 序列化存入内存中,因此不建议在使用数据加载器开多个 worker 加载数据的情况下,使用这种方式实例化数据集类。
4.1.4 数据集基类包装
- 除了数据集基类,MMEngine 也提供了若干个数据集基类包装:ConcatDataset, RepeatDataset, ClassBalancedDataset。这些数据集基类包装同样也支持懒加载与拥有节省内存的特性。
4.1.4.1 ConcatDataset
- MMEngine 提供了 ConcatDataset 包装来拼接多个数据集,使用方法如下:
from mmengine.dataset import ConcatDataset
pipeline = [
LoadImage(),
ParseImage(),
]
toy_dataset_1 = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='train/'),
ann_file='annotations/train.json',
pipeline=pipeline)
toy_dataset_2 = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='val/'),
ann_file='annotations/val.json',
pipeline=pipeline)
toy_dataset_12 = ConcatDataset(datasets=[toy_dataset_1, toy_dataset_2])
4.1.4.2 RepeatDataset
- MMEngine 提供了 RepeatDataset 包装来重复采样某个数据集若干次,使用方法如下:
from mmengine.dataset import RepeatDataset
pipeline = [
LoadImage(),
ParseImage(),
]
toy_dataset = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='train/'),
ann_file='annotations/train.json',
pipeline=pipeline)
# 将数据集的 train 部分重复采样了 5 次。
toy_dataset_repeat = RepeatDataset(dataset=toy_dataset, times=5)
4.1.4.3 ClassBalancedDataset
- MMEngine 提供了 ClassBalancedDataset 包装,来基于数据集中类别出现频率,重复采样相应样本。
- ClassBalancedDataset 包装假设了被包装的数据集类支持 get_cat_ids(idx) 方法,get_cat_ids(idx) 方法返回一个列表,该列表包含了 idx 指定的 data_info 包含的样本类别,使用方法如下:
from mmengine.dataset import BaseDataset, ClassBalancedDataset
class ToyDataset(BaseDataset):
def parse_data_info(self, raw_data_info):
data_info = raw_data_info
img_prefix = self.data_prefix.get('img_path', None)
if img_prefix is not None:
data_info['img_path'] = osp.join(
img_prefix, data_info['img_path'])
return data_info
# 必须支持的方法,需要返回样本的类别
def get_cat_ids(self, idx):
data_info = self.get_data_info(idx)
return [int(data_info['img_label'])]
pipeline = [
LoadImage(),
ParseImage(),
]
toy_dataset = ToyDataset(
data_root='data/',
data_prefix=dict(img_path='train/'),
ann_file='annotations/train.json',
pipeline=pipeline)
toy_dataset_repeat = ClassBalancedDataset(dataset=toy_dataset, oversample_thr=1e-3)
- 上述例子将数据集的 train 部分以 oversample_thr=1e-3 重新采样,具体地,对于数据集中出现频率低于 1e-3 的类别,会重复采样该类别对应的样本,否则不重复采样,具体采样策略请参考 ClassBalancedDataset API 文档。
4.2 抽象数据接口
- 在模型的训练/测试过程中,组件之间往往有大量的数据需要传递,不同的算法需要传递的数据经常是不一样的,例如,训练单阶段检测器需要获得数据集的标注框(ground truth bounding boxes)和标签(ground truth box labels),训练 Mask R-CNN 时还需要实例掩码(instance masks)。 训练这些模型时的代码如下所示
# 训练单阶段检测器
for img, img_metas, gt_bboxes, gt_labels in data_loader:
loss = retinanet(img, img_metas, gt_bboxes, gt_labels)
# 训练 Mask R-CNN
for img, img_metas, gt_bboxes, gt_masks, gt_labels in data_loader:
loss = mask_rcnn(img, img_metas, gt_bboxes, gt_masks, gt_labels)
- 可以发现,在不加封装的情况下,不同算法所需数据的不一致导致了不同算法模块之间接口的不一致,影响了算法库的拓展性,同时一个算法库内的模块为了保持兼容性往往在接口上存在冗余。 上述弊端在算法库之间会体现地更加明显,导致在实现多任务(同时进行如语义分割、检测、关键点检测等多个任务)感知模型时模块难以复用,接口难以拓展。
- 为了解决上述问题,MMEngine 定义了一套抽象的数据接口来封装模型运行过程中的各种数据。假设将上述不同的数据封装进 data_sample ,不同算法的训练都可以被抽象和统一成如下代码
for img, data_sample in dataloader:
loss = model(img, data_sample)
- 通过对各种数据提供统一的封装,抽象数据接口统一并简化了算法库中各个模块的接口,可以被用于算法库中 dataset,model,visualizer,和 evaluator 组件之间,或者 model 内各个模块之间的数据传递。 抽象数据接口实现了基本的增/删/改/查功能,同时支持不同设备之间的迁移,支持类字典和张量的操作,可以充分满足算法库对于这些数据的使用要求。 基于 MMEngine 的算法库可以继承这套抽象数据接口并实现自己的抽象数据接口来适应不同算法中数据的特点与实际需要,在保持统一接口的同时提高了算法模块的拓展性。
- 在实际实现过程中,算法库中的各个组件所具备的数据接口,一般为如下两个种:
- 数据样本(DataSample) = 图片+标注+预测:一个训练或测试样本(例如一张图像)的所有的标注信息和预测信息的集合,数据样存在于以下接口处:
- 数据集的输出
- 模型的输入
- 可视化器的输入
- 数据元素(XXXData) = 标注或预测:单一类型的预测或标注,一般是算法模型中某个子模块的输出, 例如:
- 二阶段检测中RPN的输出
- 语义分割模型的输出
- 关键点分支的输出
- GAN中生成器的输出
- 数据样本(DataSample) = 图片+标注+预测:一个训练或测试样本(例如一张图像)的所有的标注信息和预测信息的集合,数据样存在于以下接口处:
4.2.1 数据基类(BaseDataElement)
- BaseDataElement是数据样本和数据元素的基类。
- BaseDataElement 中存在两种类型的数据,一种是 data 类型,如标注框、框的标签、和实例掩码等;另一种是 metainfo 类型,包含数据的元信息以确保数据的完整性,如 img_shape, img_id 等数据所在图片的一些基本信息,方便可视化等情况下对数据进行恢复和使用。用户在创建 BaseDataElement 的过程中需要对这两类属性的数据进行显式地区分和声明。
- 为了能够更加方便地使用 BaseDataElement,data 和 metainfo 中的数据均为 BaseDataElement 的属性。我们可以通过访问类属性的方式直接访问 data 和 metainfo 中的数据。此外,BaseDataElement 还提供了很多方法,方便我们操作 data 内的数据:
- 增/删/改/查 data 中不同字段的数据
- 将 data 迁移至目标设备
- 支持像访问字典/张量一样访问 data 内的数据 以充分满足算法库对于这些数据的使用要求。
4.2.1.1 数据元素的创建
- BaseDataElement 的 data 参数可以直接通过 key=value 的方式自由添加,metainfo 的字段需要显式通过关键字 metainfo 指定。
import torch
from mmengine.structures import BaseDataElement
# 可以声明一个空的 object
data_element = BaseDataElement()
bboxes = torch.rand((5, 4)) # 假定 bboxes 是一个 Nx4 维的 tensor,N 代表框的个数
scores = torch.rand((5,)) # 假定框的分数是一个 N 维的 tensor,N 代表框的个数
img_id = 0 # 图像的 ID
H = 800 # 图像的高度
W = 1333 # 图像的宽度
# 直接设置 BaseDataElement 的 data 参数
data_element = BaseDataElement(bboxes=bboxes, scores=scores)
# 显式声明来设置 BaseDataElement 的参数 metainfo
data_element = BaseDataElement(
bboxes=bboxes,
scores=scores,
metainfo=dict(img_id=img_id, img_shape=(H, W)))
print(data_element)
"""
<BaseDataElement(
META INFORMATION
img_shape: (800, 1333)
img_id: 0
DATA FIELDS
scores: tensor([0.1767, 0.2362, 0.5024, 0.7247, 0.0613])
bboxes: tensor([[0.0883, 0.4035, 0.7266, 0.7671],
[0.8268, 0.7697, 0.7792, 0.9232],
[0.2775, 0.4771, 0.6462, 0.2814],
[0.7525, 0.5250, 0.2409, 0.0831],
[0.8166, 0.0321, 0.1296, 0.9569]])
) at 0x284063edb08>
"""
4.2.1.2 new与clone函数
- 用户可以使用 new() 函数通过已有的数据接口创建一个具有相同状态和数据的抽象数据接口。用户可以在创建新 BaseDataElement 时设置 metainfo 和 data,用于创建仅 data 或 metainfo 具有相同状态和数据的抽象接口。比如 new(metainfo=xx) 使得新的 BaseDataElement 与被 clone 的 BaseDataElement 包含相同的 data 内容,但 metainfo 为新设置的内容。 也可以直接使用 clone() 来获得一份深拷贝,clone() 函数的行为与 PyTorch 中 Tensor 的 clone() 参数保持一致。
data_element = BaseDataElement(
bboxes=torch.rand((5, 4)),
scores=torch.rand((5,)),
metainfo=dict(img_id=1, img_shape=(640, 640)))
# 可以在创建新 `BaseDataElement` 时设置 metainfo 和 data,使得新的 BaseDataElement 有相同未被设置的数据
data_element1 = data_element.new(metainfo=dict(img_id=2, img_shape=(320, 320)))
print('bboxes is in data_element1:', 'bboxes' in data_element1) # True
print('bboxes in data_element1 is same as bbox in data_element', (data_element1.bboxes == data_element.bboxes).all())
print('img_id in data_element1 is', data_element1.img_id == 2) # True
data_element2 = data_element.new(label=torch.rand(5,))
print('bboxes is not in data_element2', 'bboxes' not in data_element2) # True
print('img_id in data_element2 is same as img_id in data_element', data_element2.img_id == data_element.img_id)
print('label in data_element2 is', 'label' in data_element2)
# 也可以通过 `clone` 构建一个新的 object,新的 object 会拥有和 data_element 相同的 data 和 metainfo 内容以及状态。
data_element2 = data_element1.clone()
"""
bboxes is in data_element1: True
bboxes in data_element1 is same as bbox in data_element tensor(True)
img_id in data_element1 is True
bboxes is not in data_element2 True
img_id in data_element2 is same as img_id in data_element True
label in data_element2 is True
"""
4.2.1.3 属性的增加与查询
- 对增加属性而言,用户可以像增加类属性那样增加 data 内的属性;对metainfo 而言,一般储存的为一些图像的元信息,一般情况下不会修改,如果需要增加,用户应当使用 set_metainfo 接口显示地修改。
- 对查询而言,用户可以可以通过 keys,values,和 items 来访问只存在于 data 中的键值,也可以通过 metainfo_keys,metainfo_values,和metainfo_items 来访问只存在于 metainfo 中的键值。 用户还能通过 all_keys,all_values, all_items 来访问 BaseDataElement 的所有的属性并且不区分他们的类型。
- 同时为了方便使用,用户可以像访问类属性一样访问 data 与 metainfo 内的数据,或着类字典方式通过 get() 接口访问数据。
- 限制:
- BaseDataElement 不支持 metainfo 和 data 属性中有同名的字段,所以用户应当避免 metainfo 和 data 属性中设置相同的字段,否则 BaseDataElement 会报错。
- 考虑到 InstanceData 和 PixelData 支持对数据进行切片操作,为了避免 [] 用法的不一致,同时减少同种需求的不同方法,BaseDataElement 不支持像字典那样访问和设置它的属性,所以类似 BaseDataElement[name] 的取值赋值操作是不被支持的。
- 设置和访问metainfo
data_element = BaseDataElement()
# 通过 `set_metainfo`设置 data_element 的 metainfo 字段,
# 同时 img_id 和 img_shape 成为 data_element 的属性
data_element.set_metainfo(dict(img_id=9, img_shape=(100, 100)))
# 查看 metainfo 的 key, value 和 item
print("metainfo'keys are", data_element.metainfo_keys())
print("metainfo'values are", data_element.metainfo_values())
for k, v in data_element.metainfo_items():
print(f'{k}: {v}')
print("通过类属性查看 img_id 和 img_shape")
print('img_id:', data_element.img_id)
print('img_shape:', data_element.img_shape)
"""
metainfo'keys are ['img_id', 'img_shape']
metainfo'values are [9, (100, 100)]
img_id: 9
img_shape: (100, 100)
通过类属性查看 img_id 和 img_shape
img_id: 9
img_shape: (100, 100)
"""
- 设置和访问data
# 通过类属性直接设置 BaseDataElement 中的 data 字段
data_element.scores = torch.rand((5,))
data_element.bboxes = torch.rand((5, 4))
print("data's key is:", data_element.keys())
print("data's value is:", data_element.values())
for k, v in data_element.items():
print(f'{k}: {v}')
print("通过类属性查看 scores 和 bboxes")
print('scores:', data_element.scores)
print('bboxes:', data_element.bboxes)
print("通过 get() 查看 scores 和 bboxes")
print('scores:', data_element.get('scores', None))
print('bboxes:', data_element.get('bboxes', None))
print('fake:', data_element.get('fake', 'not exist'))
- 设置和访问ALL (metainfo+data)
print("All key in data_element is:", data_element.all_keys())
print("The length of values in data_element is", len(data_element.all_values()))
for k, v in data_element.all_items():
print(f'{k}: {v}')
4.2.1.4 属性的删改
- 用户可以像修改实例属性一样修改 BaseDataElement 的 data, 对metainfo 而言 一般储存的为一些图像的元信息,一般情况下不会修改,如果需要修改,用户应当使用 set_metainfo 接口显示的修改。
- 同时为了操作的便捷性,对 data 和 metainfo 中的数据可以通过 del 直接删除,也支持 pop 在访问属性后删除属性。
- 初始化数据
data_element = BaseDataElement(
bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
metainfo=dict(img_id=0, img_shape=(640, 640))
)
for k, v in data_element.all_items():
print(f'{k}: {v}')
- 对 data 进行修改
# 对 data 进行修改
data_element.bboxes = data_element.bboxes * 2
data_element.scores = data_element.scores * -1
for k, v in data_element.items():
print(f'{k}: {v}')
# 删除 data 中的属性
del data_element.bboxes
for k, v in data_element.items():
print(f'{k}: {v}')
data_element.pop('scores', None)
print('The keys in data is', data_element.keys())
- 对 metainfo 进行修改
# 对 metainfo 进行修改
data_element.set_metainfo(dict(img_shape = (1280, 1280), img_id=10))
print(data_element.img_shape) # (1280, 1280)
for k, v in data_element.metainfo_items():
print(f'{k}: {v}')
# 提供了便捷的属性删除和访问操作 pop
del data_element.img_shape
for k, v in data_element.metainfo_items():
print(f'{k}: {v}')
data_element.pop('img_id')
print('The keys in metainfo is', data_element.metainfo_keys())
4.2.1.5 类张量操作
- 用户可以像 torch.Tensor 那样对 BaseDataElement 的 data 进行状态转换,目前支持 cuda, cpu, to, numpy 等操作。 其中,to 函数拥有和 torch.Tensor.to() 相同的接口,使得用户可以灵活地将被封装的 tensor 进行状态转换。 注意: 这些接口只会处理类型为 np.array,torch.Tensor,或者数字的序列,其他属性的数据(如字符串)会被跳过处理。
data_element = BaseDataElement(
bboxes=torch.rand((6, 4)), scores=torch.rand((6,)),
metainfo=dict(img_id=0, img_shape=(640, 640))
)
# 将所有 data 转移到 GPU 上
cuda_element_1 = data_element.cuda()
print('cuda_element_1 is on the device of', cuda_element_1.bboxes.device) # cuda:0
cuda_element_2 = data_element.to('cuda:0')
print('cuda_element_1 is on the device of', cuda_element_2.bboxes.device) # cuda:0
# 将所有 data 转移到 cpu 上
cpu_element_1 = cuda_element_1.cpu()
print('cpu_element_1 is on the device of', cpu_element_1.bboxes.device) # cpu
cpu_element_2 = cuda_element_2.to('cpu')
print('cpu_element_2 is on the device of', cpu_element_2.bboxes.device) # cpu
# 将所有 data 变成 FP16
fp16_instances = cuda_element_1.to(
device=None, dtype=torch.float16, non_blocking=False, copy=False,
memory_format=torch.preserve_format)
print('The type of bboxes in fp16_instances is', fp16_instances.bboxes.dtype) # torch.float16
# 阻断所有 data 的梯度
cuda_element_3 = cuda_element_2.detach()
print('The data in cuda_element_3 requires grad: ', cuda_element_3.bboxes.requires_grad)
# 转移 data 到 numpy array
np_instances = cpu_element_1.numpy()
print('The type of cpu_element_1 is convert to', type(np_instances.bboxes))
"""
>>> print(data_element)
<BaseDataElement(
META INFORMATION
img_shape: (640, 640)
img_id: 0
DATA FIELDS
scores: tensor([0.5568, 0.2954, 0.5363, 0.6763, 0.5107, 0.3845])
bboxes: tensor([[0.3709, 0.9651, 0.8044, 0.4766],
[0.4687, 0.0177, 0.8829, 0.9091],
[0.2350, 0.7447, 0.4824, 0.5225],
[0.2682, 0.9656, 0.2816, 0.9145],
[0.4085, 0.2216, 0.7311, 0.6659],
[0.3735, 0.2475, 0.6794, 0.3832]])
) at 0x284063f3908>
>>>
>>> np_insts = data_element.numpy()
>>> print(np_insts)
<BaseDataElement(
META INFORMATION
img_shape: (640, 640)
img_id: 0
DATA FIELDS
scores: array([0.5568036 , 0.29543215, 0.53628564, 0.67632824, 0.51071906,
0.38445634], dtype=float32)
bboxes: array([[0.3709125 , 0.96512437, 0.8044025 , 0.47661138],
[0.46872175, 0.01766497, 0.882925 , 0.90907574],
[0.23501879, 0.74472183, 0.48235476, 0.5224898 ],
[0.26816165, 0.9656316 , 0.28161776, 0.91453063],
[0.40851545, 0.22162563, 0.7311081 , 0.6659277 ],
[0.3735103 , 0.24753934, 0.6794118 , 0.383223 ]], dtype=float32)
) at 0x284063f3648>
"""
4.2.1.6 属性的展示
- BaseDataElement 还实现了 __repr__,因此,用户可以直接通过 print 函数看到其中的所有数据信息。 同时,为了便捷开发者 debug,BaseDataElement 中的属性都会添加进 __dict__ 中,方便用户在 IDE 界面可以直观看到 BaseDataElement 中的内容。 一个完整的属性展示如下
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
instance_data = BaseDataElement(metainfo=img_meta)
instance_data.det_labels = torch.LongTensor([0, 1, 2, 3])
instance_data.det_scores = torch.Tensor([0.01, 0.1, 0.2, 0.3])
print(instance_data)
4.2.2 数据元素(xxxData)
- MMEngine 将数据元素情况划分为三个类别:
- 实例数据(InstanceData): 主要针对的是**上层任务(high-level)**中,对图像中所有实例相关的数据进行封装,比如检测框(bounding boxes), 物体类别(box labels),实例掩码(instance masks), 关键点(key points), 文字边界(polygons), 跟踪id(tracking ids) 等. 所有实例相关的数据的长度一致,均为图像中实例的个数。
- 像素数据(PixelData): 主要针对底层任务(low-level) 以及需要感知像素级别标签的部分上层任务。像素数据对像素级相关的数据进行封装,比如语义分割中的分割图(segmentation map), 光流任务中的光流图(flow map), 全景分割中的全景分割图(panoptic seg map);底层任务中生成的各种图像,比如超分辨图,去噪图,以及生成的各种风格图。这些数据的特点是都是三维或四维数组,最后两维度为数据的高度(height)和宽度(width),且具有相同的height和width
- 标签数据(LabelData): 主要标签级别的数据进行封装,比如图像分类,多分类中的类别,图像生成中生成图像的类别内容,或者文字识别中的文本等。
4.2.2.1 实例数据InstanceData
- InstanceData 在 BaseDataElement 的基础上,对 data 存储的数据做了限制,即要求存储在 data 中的数据的长度一致。比如在目标检测中, 假设一张图像中有 N 个目标(instance),可以将图像的所有边界框(bbox),类别(label)等存储在 InstanceData 中, InstanceData 的 bbox 和 label 的长度相同。 基于上述假定对 InstanceData进行了扩展,包括:
- 对 InstanceData 中 data 所存储的数据进行了长度校验
- data 部分支持类字典访问和设置它的属性
- 支持基础索引,切片以及高级索引功能
- 支持具有相同的 key 但是不同 InstanceData 的拼接功能。 这些扩展功能除了支持基础的数据结构, 比如torch.tensor, numpy.dnarray, list, str, tuple, 也可以是自定义的数据结构,只要自定义数据结构实现了 __len__, __getitem__ and cat.
- 数据校验
4.2.2.2 类字典访问和设置属性
- InstanceData 中 data 的数据长度要保持一致,如果传入不同长度的新数据,将会报错。
from mmengine.structures import InstanceData
import torch
import numpy as np
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
instance_data = InstanceData(metainfo=img_meta)
instance_data.det_labels = torch.LongTensor([2, 3])
instance_data.det_scores = torch.Tensor([0.8, 0.7])
instance_data.bboxes = torch.rand((2, 4))
print('The length of instance_data is', len(instance_data)) # 2
instance_data.bboxes = torch.rand((3, 4))
"""
The length of instance_data is 2
AssertionError: the length of values 3 is not consistent with the length of this :obj:`InstanceData` 2
"""
- InstanceData 支持类似字典的操作访问和设置其 data 属性。
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
instance_data = InstanceData(metainfo=img_meta)
instance_data["det_labels"] = torch.LongTensor([2, 3])
instance_data["det_scores"] = torch.Tensor([0.8, 0.7])
instance_data.bboxes = torch.rand((2, 4))
print(instance_data)
- 索引与切片:InstanceData 支持 Python 中类似列表的索引与切片,同时也支持类似 numpy 的高级索引操作。
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
instance_data = InstanceData(metainfo=img_meta)
instance_data.det_labels = torch.LongTensor([2, 3])
instance_data.det_scores = torch.Tensor([0.8, 0.7])
instance_data.bboxes = torch.rand((2, 4))
print(instance_data)
"""
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([2, 3])
det_scores: tensor([0.8000, 0.7000])
bboxes: tensor([[0.1872, 0.1669, 0.7563, 0.8777],
[0.3421, 0.7104, 0.6000, 0.1518]])
) at 0x7f9f312b4dc0>
"""
- 索引(只对data)
print(instance_data[1])
"""
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([3])
det_scores: tensor([0.7000])
bboxes: tensor([[0.3421, 0.7104, 0.6000, 0.1518]])
) at 0x7f9f312b4610>
"""
- 切片(只对data)
print(instance_data[0:1])
"""
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([2])
det_scores: tensor([0.8000])
bboxes: tensor([[0.1872, 0.1669, 0.7563, 0.8777]])
) at 0x7f9f312b4e20>
"""
- 列表索引
sorted_results = instance_data[instance_data.det_scores.sort().indices]
print(sorted_results)
"""
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([3, 2])
det_scores: tensor([0.7000, 0.8000])
bboxes: tensor([[0.3421, 0.7104, 0.6000, 0.1518],
[0.1872, 0.1669, 0.7563, 0.8777]])
) at 0x7f9f312b4a90>
"""
- 布尔索引
filter_results = instance_data[instance_data.det_scores > 0.75]
print(filter_results)
"""
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([2])
det_scores: tensor([0.8000])
bboxes: tensor([[0.1872, 0.1669, 0.7563, 0.8777]])
) at 0x7fa061299dc0>
"""
- 结果为空
empty_results = instance_data[instance_data.det_scores > 1]
print(empty_results)
"""
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([], dtype=torch.int64)
det_scores: tensor([])
bboxes: tensor([], size=(0, 4))
) at 0x7f9f439cccd0>
"""
- 拼接(cat)
- 用户可以将两个具有相同 key 的 InstanceData 拼接成一个 InstanceData。对于长度分别为 N 和 M 的两个 InstanceData, 拼接后为长度 N + M 的新的 InstanceData
img_meta = dict(img_shape=(800, 1196, 3), pad_shape=(800, 1216, 3))
instance_data = InstanceData(metainfo=img_meta)
instance_data.det_labels = torch.LongTensor([2, 3])
instance_data.det_scores = torch.Tensor([0.8, 0.7])
instance_data.bboxes = torch.rand((2, 4))
print('The length of instance_data is', len(instance_data))
cat_results = InstanceData.cat([instance_data, instance_data])
print('The length of instance_data is', len(cat_results))
print(cat_results)
"""
The length of instance_data is 2
The length of instance_data is 4
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
det_labels: tensor([2, 3, 2, 3])
det_scores: tensor([0.8000, 0.7000, 0.8000, 0.7000])
bboxes: tensor([[0.5341, 0.8962, 0.9043, 0.2824],
[0.3864, 0.2215, 0.7610, 0.7060],
[0.5341, 0.8962, 0.9043, 0.2824],
[0.3864, 0.2215, 0.7610, 0.7060]])
) at 0x7fa061d4a9d0>
"""
4.2.2.3 PixelData
- PixelData 在 BaseDataElement 的基础上,同样对 data 中存储的数据做了限制:
- 所有 data 内的数据均为 3 维,并且顺序为 (通道,高, 宽)
- 所有在 data 内的数据要有相同的长和宽 基于上述假定对 PixelData进行了扩展,包括:
- 对 PixelData 中 data 所存储的数据进行了尺寸的校验
- 支持对 data 部分的数据对实例进行空间维度的索引和切片。
4.2.2.4 数据校验 (PixelData)
- PixelData 会对传入到 data 的数据进行维度与长宽的校验。
from mmengine.structures import PixelData
import random
import torch
import numpy as np
metainfo = dict(
img_id=random.randint(0, 100),
img_shape=(random.randint(400, 600), random.randint(400, 600)))
image = np.random.randint(0, 255, (4, 20, 40))
featmap = torch.randint(0, 255, (10, 20, 40))
pixel_data = PixelData(metainfo=metainfo,
image=image,
featmap=featmap)
print('The shape of pixel_data is', pixel_data.shape)
# set
pixel_data.map3 = torch.randint(0, 255, (20, 40))
print('The shape of pixel_data is', pixel_data.map3.shape)
pixel_data.map2 = torch.randint(0, 255, (3, 20, 30))
# AssertionError: the height and width of values (20, 30) is not consistent with the length of this :obj:`PixelData` (20, 40)
pixel_data.map2 = torch.randint(0, 255, (1, 3, 20, 40))
# AssertionError: The dim of value must be 2 or 3, but got 4
4.2.2.5 空间维度索引 (PixelData)
- PixelData 支持对 data 部分的数据对实例进行空间维度的索引和切片,只需传入长宽的索引即可。
metainfo = dict(
img_id=random.randint(0, 100),
img_shape=(random.randint(400, 600), random.randint(400, 600)))
image = np.random.randint(0, 255, (4, 20, 40))
featmap = torch.randint(0, 255, (10, 20, 40))
pixel_data = PixelData(metainfo=metainfo,
image=image,
featmap=featmap)
print('The shape of pixel_data is', pixel_data.shape)
# The shape of pixel_data is (20, 40)
- 索引
index_data = pixel_data[10, 20]
print('The shape of index_data is', index_data.shape)
# The shape of index_data is (1, 1)
- 切片
slice_data = pixel_data[10:20, 20:40]
print('The shape of slice_data is', slice_data.shape)
# The shape of slice_data is (10, 20)
4.2.2.6 LabelData
- LabelData 主要用来封装标签数据,如场景分类标签,文字识别标签等。LabelData 没有对 data 做任何限制,只提供了两个额外功能:onehot 与 index 的转换。
from mmengine.structures import LabelData
import torch
item = torch.tensor([1], dtype=torch.int64)
num_classes = 10
onehot = LabelData.label_to_onehot(label=item, num_classes=num_classes)
print(f'{num_classes} is convert to ', onehot)
index = LabelData.onehot_to_label(onehot=onehot)
print(f'{onehot} is convert to ', index)
"""
10 is convert to tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0])
tensor([0, 1, 0, 0, 0, 0, 0, 0, 0, 0]) is convert to tensor([1])
"""
4.2.3 数据样本(DataSample)
- 数据样本作为不同模块最外层的接口,提供了 xxxDataSample 用于单任务中各模块之间统一格式的传递,同时为了各个模块从统一字段获取或写入信息,数据样本中的命名以及类型要进行约束和统一,保证各模块接口的统一性。 OpenMMLab 中各个算法库的命名规范可以参考 OpenMMLab 中的命名规范。
4.2.3.1 下游库使用
- 以 MMDet 为例,说明下游库中数据样本的使用,以及数据样本字段的约束和命名。MMDet 中定义了 DetDataSample, 同时定义了 7 个字段,分别为:
- 标注信息
- gt_instance(InstanceData): 实例标注信息,包括实例的类别、边界框等, 类型约束为 InstanceData。
- gt_panoptic_seg(PixelData): 全景分割的标注信息,类型约束为 PixelData。
- gt_semantic_seg(PixelData): 语义分割的标注信息, 类型约束为 PixelData。
- 预测结果
- pred_instance(InstanceData): 实例预测结果,包括实例的类别、边界框等, 类型约束为 InstanceData。
- pred_panoptic_seg(PixelData): 全景分割的预测结果,类型约束为 PixelData。
- pred_semantic_seg(PixelData): 语义分割的预测结果, 类型约束为 PixelData。
- 中间结果
- proposal(InstanceData): 主要为二阶段中 RPN 的预测结果, 类型约束为 InstanceData。
- 标注信息
4.2.3.2 类型约束
- DetDataSample 的用法如下所示,在数据类型不符合要求的时候(例如用 torch.Tensor 而非 InstanceData 定义 proposals 时),DetDataSample 就会报错。
from mmdet.structures import DetDataSample
data_sample = DetDataSample()
data_sample.proposals = InstanceData(data=dict(bboxes=torch.rand((5,4))))
print(data_sample)
"""
<DetDataSample(
META INFORMATION
DATA FIELDS
proposals: <InstanceData(
META INFORMATION
DATA FIELDS
data:
bboxes: tensor([[0.7513, 0.9275, 0.6169, 0.5581],
[0.6019, 0.6861, 0.7915, 0.0221],
[0.5977, 0.8987, 0.9541, 0.7877],
[0.0309, 0.1680, 0.1374, 0.0556],
[0.3842, 0.9965, 0.0747, 0.6546]])
) at 0x7f9f1c090310>
) at 0x7f9f1c090430>
"""
4.2.4 接口的简化
- 下面以 MMDetection 为例更具体地说明 OpenMMLab 的算法库将如何迁移使用抽象数据接口,以简化模块和组件接口的。我们假定 MMDetection 和 MMEngine 中实现了 DetDataSample 和 InstanceData。
4.2.4.1 组件接口的简化
- 检测器的外部接口可以得到显著的简化和统一。MMDet 2.X 中单阶段检测器和单阶段分割算法的接口如下。在训练过程中,SingleStageDetector 需要获取 img, img_metas, gt_bboxes, gt_labels, gt_bboxes_ignore 作为输入,但是 SingleStageInstanceSegmentor 还需要 gt_masks,导致 detector 的训练接口不一致,影响了代码的灵活性。
class SingleStageDetector(BaseDetector):
...
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
class SingleStageInstanceSegmentor(BaseDetector):
...
def forward_train(self,
img,
img_metas,
gt_masks,
gt_labels,
gt_bboxes=None,
gt_bboxes_ignore=None,
**kwargs):
- 在 MMDet 3.0 中,所有检测器的训练接口都可以使用 DetDataSample 统一简化为 img 和 data_samples,不同模块可以根据需要去访问 data_samples 封装的各种所需要的属性。
class SingleStageDetector(BaseDetector):
...
def forward_train(self,
img,
data_samples):
class SingleStageInstanceSegmentor(BaseDetector):
...
def forward_train(self,
img,
data_samples):
4.2.4.2 模块接口的简化
- MMDet 2.X 中 HungarianAssigner 和 MaskHungarianAssigner 分别用于在训练过程中将检测框和实例掩码和标注的实例进行匹配。他们内部的匹配逻辑实现是一样的,只是接口和损失函数的计算不同。 但是,接口的不同使得 HungarianAssigner 中的代码无法被复用,MaskHungarianAssigner 中重写了很多冗余的逻辑。
class HungarianAssigner(BaseAssigner):
def assign(self,
bbox_pred,
cls_pred,
gt_bboxes,
gt_labels,
img_meta,
gt_bboxes_ignore=None,
eps=1e-7):
class MaskHungarianAssigner(BaseAssigner):
def assign(self,
cls_pred,
mask_pred,
gt_labels,
gt_mask,
img_meta,
gt_bboxes_ignore=None,
eps=1e-7):
- InstanceData 可以封装实例的框、分数、和掩码,将 HungarianAssigner 的核心参数简化成 pred_instances,gt_instancess,和 gt_instances_ignore 使得 HungarianAssigner 和 MaskHungarianAssigner 可以合并成一个通用的 HungarianAssigner。
class HungarianAssigner(BaseAssigner):
def assign(self,
pred_instances,
gt_instancess,
gt_instances_ignore=None,
eps=1e-7):
4.3 可视化
- 可视化可以给深度学习的模型训练和测试过程提供直观解释。
- MMEngine 提供了 Visualizer 可视化器用以可视化和存储模型训练和测试过程中的状态以及中间结果,具备如下功能:
- 支持基础绘图接口以及特征图可视化
- 支持本地, TensorBoard 以及 WandB 等多种后端,可以将训练状态例如 loss 、lr 或者性能评估指标以及可视化的结果写入指定的单一或多个后端
- 允许在代码库任意位置调用,对任意位置的特征,图像,状态等进行可视化和存储。
4.3.1 基础绘制接口
- 可视化器提供了常用对象的绘制接口,例如绘制检测框、点、文本、线、圆、多边形和二值掩码。这些基础 API 支持以下特性:
- 可以多次调用,实现叠加绘制需求
- 均支持多输入,除了要求文本输入的绘制接口外,其余接口同时支持 Tensor 以及 Numpy array 的输入
4.3.1.1 绘制检测框、掩码和文本等
import torch
import mmcv
from mmengine.visualization import Visualizer
image = mmcv.imread('docs/en/_static/image/cat_and_dog.png', channel_order='rgb')
visualizer = Visualizer(image=image)
# 绘制单个检测框, xyxy 格式
visualizer.draw_bboxes(torch.tensor([72, 13, 179, 147]))
# 绘制多个检测框
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
visualizer.show()
visualizer.set_image(image=image)
visualizer.draw_texts("cat and dog", torch.tensor([10, 20]))
visualizer.show()
- 也可以通过各个绘制接口中提供的参数来定制绘制对象的颜色和宽度等等
visualizer.set_image(image=image)
visualizer.draw_bboxes(torch.tensor([72, 13, 179, 147]), edge_colors='r', line_widths=3)
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220]]),line_styles='--')
visualizer.show()
4.3.1.2 叠加显示
上述绘制接口可以多次调用,从而实现叠加显示需求
visualizer.set_image(image=image)
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
visualizer.draw_texts("cat and dog",
torch.tensor([10, 20])).draw_circles(torch.tensor([40, 50]), torch.tensor([20]))
visualizer.show()

4.3.2 特征图绘制
- 特征图可视化功能较多,目前只支持单张特征图的可视化,为了方便理解,将其对外接口梳理如下:
@staticmethod
def draw_featmap(featmap: torch.Tensor, # 输入格式要求为 CHW
overlaid_image: Optional[np.ndarray] = None, # 如果同时输入了 image 数据,则特征图会叠加到 image 上绘制
channel_reduction: Optional[str] = 'squeeze_mean', # 多个通道压缩为单通道的策略
topk: int = 10, # 可选择激活度最高的 topk 个特征图显示
arrangement: Tuple[int, int] = (5, 2), # 多通道展开为多张图时候布局
resize_shape:Optional[tuple] = None, # 可以指定 resize_shape 参数来缩放特征图
alpha: float = 0.5) -> np.ndarray: # 图片和特征图绘制的叠加比例
- 输入的 Tensor 一般是包括多个通道的,channel_reduction 参数可以将多个通道压缩为单通道,然后和图片进行叠加显示
- squeeze_mean 将输入的 C 维度采用 mean 函数压缩为一个通道,输出维度变成 (1, H, W)
- select_max 从输入的 C 维度中先在空间维度 sum,维度变成 (C, ),然后选择值最大的通道
- None 表示不需要压缩,此时可以通过 topk 参数可选择激活度最高的 topk 个特征图显示
- 在 channel_reduction 参数为 None 的情况下,topk 参数生效,其会按照激活度排序选择 topk 个通道,然后和图片进行叠加显示,并且此时会通过 arrangement 参数指定显示的布局
- 如果 topk 不是 -1,则会按照激活度排序选择 topk 个通道显示
- 如果 topk = -1,此时通道 C 必须是 1 或者 3 表示输入数据是图片,否则报错提示用户应该设置 channel_reduction来压缩通道。
- 考虑到输入的特征图通常非常小,函数支持输入 resize_shape 参数,方便将特征图进行上采样后进行可视化。
- 常见用法如下:以预训练好的 ResNet18 模型为例,通过提取 layer4 层输出进行特征图可视化
- (1) 将多通道特征图采用 select_max 参数压缩为单通道并显示
import torch
import mmcv
import numpy as np
from mmengine.visualization import Visualizer
from torchvision.models import resnet18, ResNet18_Weights
from torchvision.transforms import Compose, Normalize, ToTensor
image = mmcv.imread('docs/en/_static/image/cat_and_dog.png', channel_order='rgb')
#visualizer = Visualizer(image=image)
visualizer = Visualizer(image=image, vis_backends=[dict(type='LocalVisBackend')], save_dir='temp_dir')
visualizer.show()
def preprocess_image(img, mean, std):
preprocessing = Compose([
ToTensor(),
Normalize(mean=mean, std=std)
])
return preprocessing(img.copy()).unsqueeze(0)
model = resnet18(weights=ResNet18_Weights.DEFAULT)
def _forward(x):
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
x1 = model.layer1(x)
x2 = model.layer2(x1)
x3 = model.layer3(x2)
x4 = model.layer4(x3)
return x4
model.forward = _forward
image_norm = np.float32(image) / 255
input_tensor = preprocess_image(image_norm,
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
feat = model(input_tensor)[0]
print(feat.size()) # torch.Size([512, 7, 7])
visualizer = Visualizer()
drawn_img = visualizer.draw_featmap(feat, channel_reduction='select_max')
visualizer.show(drawn_img)
- 由于输出的 feat 特征图尺寸为 7×7,直接可视化效果不佳,用户可以通过叠加输入图片或者 resize_shape 参数来缩放特征图。如果传入图片尺寸和特征图大小不一致,会强制将特征图采样到和输入图片相同空间尺寸
drawn_img = visualizer.draw_featmap(feat, image, channel_reduction='select_max')
visualizer.show(drawn_img)

- (2) 利用 topk=5 参数选择多通道特征图中激活度最高的 5 个通道并采用 2×3 布局显示
drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None, topk=5, arrangement=(2, 3))
visualizer.show(drawn_img)
- 用户可以通过 arrangement 参数选择自己想要的布局
drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None, topk=5, arrangement=(4, 2))
visualizer.show(drawn_img)
4.3.3 基础存储接口
- 在绘制完成后,可以选择本地窗口显示,也可以存储到不同后端中,目前 MMEngine 内置了本地存储、Tensorboard 存储和 WandB 存储 3 个后端,且支持存储绘制后的图片、loss 等标量数据和配置文件。
4.3.3.1 存储绘制后的图片
- 假设存储后端为本地存储
import torch
import mmcv
import numpy as np
from mmengine.visualization import Visualizer
from torchvision.models import resnet18, ResNet18_Weights
from torchvision.transforms import Compose, Normalize, ToTensor
image = mmcv.imread('docs/en/_static/image/cat_and_dog.png', channel_order='rgb')
visualizer = Visualizer(image=image, vis_backends=[dict(type='LocalVisBackend')], save_dir='temp_dir')
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
visualizer.draw_texts("cat and dog", torch.tensor([10, 20]))
visualizer.draw_circles(torch.tensor([40, 50]), torch.tensor([20]))
# 会生成 temp_dir/vis_data/vis_image/demo_0.png
visualizer.add_image('demo', visualizer.get_image())
- 其中生成的后缀 0 是用来区分不同 step 场景
# 会生成 temp_dir/vis_data/vis_image/demo_1.png
visualizer.add_image('demo', visualizer.get_image(), step=1)
# 会生成 temp_dir/vis_data/vis_image/demo_3.png
visualizer.add_image('demo', visualizer.get_image(), step=3)
- 如果想使用其他后端,则只需要修改配置文件即可
# TensorboardVisBackend
visualizer = Visualizer(image=image, vis_backends=[dict(type='TensorboardVisBackend')], save_dir='temp_dir')
# 或者 WandbVisBackend
visualizer = Visualizer(image=image, vis_backends=[dict(type='WandbVisBackend')], save_dir='temp_dir')
4.3.3.2 存储特征图
visualizer = Visualizer(vis_backends=[dict(type='LocalVisBackend')], save_dir='temp_dir')
drawn_img = visualizer.draw_featmap(feat, image, channel_reduction=None, topk=5, arrangement=(2, 3))
# 会生成 temp_dir/vis_data/vis_image/feat_0.png
visualizer.add_image('feat', drawn_img)
4.3.3.3 存储loss 等标量数据
# 会生成 temp_dir/vis_data/scalars.json
# 保存 loss
visualizer.add_scalar('loss', 0.2, step=0)
visualizer.add_scalar('loss', 0.1, step=1)
# 保存 acc
visualizer.add_scalar('acc', 0.7, step=0)
visualizer.add_scalar('acc', 0.8, step=1)
- 也可以一次性保存多个标量数据
# 会将内容追加到 temp_dir/vis_data/scalars.json
visualizer.add_scalars({'loss': 0.3, 'acc': 0.8}, step=3)
4.3.3.4 保存配置文件
from mmengine import Config
cfg=Config.fromfile('tests/data/config/py_config/config.py')
# 会生成 temp_dir/vis_data/config.py
visualizer.add_config(cfg)
4.3.4 多后端存储
- 实际上,任何一个可视化器都可以配置任意多个存储后端,可视化器会循环调用配置好的多个存储后端,从而将结果保存到多后端中。
visualizer = Visualizer(image=image, vis_backends=[dict(type='TensorboardVisBackend'),
dict(type='LocalVisBackend')],
save_dir='temp_dir')
# 会生成 temp_dir/vis_data/events.out.tfevents.xxx 文件
visualizer.draw_bboxes(torch.tensor([[33, 120, 209, 220], [72, 13, 179, 147]]))
visualizer.draw_texts("cat and dog", torch.tensor([10, 20]))
visualizer.draw_circles(torch.tensor([40, 50]), torch.tensor([20]))
visualizer.add_image('demo', visualizer.get_image())
- 注意:如果多个存储后端中存在同一个类的多个后端,那么必须指定 name 字段,否则无法区分是哪个存储后端
visualizer = Visualizer(image=image, vis_backends=[dict(type='TensorboardVisBackend', name='tb_1', save_dir='temp_dir_1'),
dict(type='TensorboardVisBackend', name='tb_2', save_dir='temp_dir_2'),
dict(type='LocalVisBackend', name='local')],
save_dir='temp_dir')
4.3.5 任意点位进行可视化
- 在深度学习过程中,会存在在某些代码位置插入可视化函数,并将其保存到不同后端的需求,这类需求主要用于可视化分析和调试阶段。MMEngine 设计的可视化器支持在任意点位获取同一个可视化器然后进行可视化的功能。 用户只需要在初始化时候通过 get_instance 接口实例化可视化对象,此时该可视化对象即为全局可获取唯一对象,后续通过 Visualizer.get_current_instance() 即可在代码任意位置获取。
# 在程序初始化时候调用
visualizer1 = Visualizer.get_instance(name='vis', vis_backends=[dict(type='LocalVisBackend')])
# 在任何代码位置都可调用
visualizer2 = Visualizer.get_current_instance()
visualizer2.add_scalar('map', 0.7, step=0)
assert id(visualizer1) == id(visualizer2)
- 也可以通过字段配置方式全局初始化
from mmengine.registry import VISUALIZERS
visualizer_cfg=dict(
type='Visualizer',
name='vis_new',
vis_backends=[dict(type='LocalVisBackend')])
VISUALIZERS.build(visualizer_cfg)
4.3.6 扩展存储后端和可视化器
4.3.6.1 调用特定存储后端
- 目前存储后端仅仅提供了保存配置、保存标量等基本功能,但是由于 WandB 和 Tensorboard 这类存储后端功能非常强大, 用户可能会希望利用到这类存储后端的其他功能。因此,存储后端提供了 experiment 属性来方便用户获取后端对象,满足各类定制化功能。 例如 WandB 提供了表格显示的 API 接口,用户可以通过 experiment属性获取 WandB 对象,然后调用特定的 API 来将自定义数据保存为表格显示
import torch
import mmcv
import numpy as np
from mmengine.visualization import Visualizer
image = mmcv.imread('docs/en/_static/image/cat_and_dog.png', channel_order='rgb')
visualizer = Visualizer(image=image, vis_backends=[dict(type='WandbVisBackend')],
save_dir='temp_dir')
# 获取 wandb 对象
wandb = visualizer.get_backend('WandbVisBackend').experiment
# 追加表格数据
table = wandb.Table(columns=["step", "mAP"])
table.add_data(1, 0.2)
table.add_data(2, 0.5)
table.add_data(3, 0.9)
# 保存
wandb.log({"table": table})
4.3.6.2 扩展存储后端
- 用户可以方便快捷的扩展存储后端。只需要继承自 BaseVisBackend 并实现各类 add_xx 方法即可
from mmengine.registry import VISBACKENDS
from mmengine.visualization import BaseVisBackend
@VISBACKENDS.register_module()
class DemoVisBackend(BaseVisBackend):
def add_image(self, **kwargs):
pass
visualizer = Visualizer(vis_backends=[dict(type='DemoVisBackend')], save_dir='temp_dir')
visualizer.add_image('demo',image)
4.3.6.3 扩展可视化器
- 同样的,用户可以通过继承 Visualizer 并实现想覆写的函数来方便快捷的扩展可视化器。大部分情况下,用户需要覆写 add_datasample来进行拓展。数据中通常包括标注或模型预测的检测框和实例掩码,该接口为各个下游库绘制 datasample 数据的抽象接口。以 MMDetection 为例,datasample 数据中通常包括标注 bbox、标注 mask 、预测 bbox 或者预测 mask 等数据,MMDetection 会继承 Visualizer 并实现 add_datasample 接口,在该接口内部会针对检测任务相关数据进行可视化绘制,从而简化检测任务可视化需求。
from mmengine.registry import VISUALIZERS
@VISUALIZERS.register_module()
class DetLocalVisualizer(Visualizer):
def add_datasample(self,
name,
image: np.ndarray,
data_sample: Optional['BaseDataElement'] = None,
draw_gt: bool = True,
draw_pred: bool = True,
show: bool = False,
wait_time: int = 0,
step: int = 0) -> None:
pass
visualizer_cfg = dict(
type='DetLocalVisualizer', vis_backends=[dict(type='WandbVisBackend')], name='visualizer')
# 全局初始化
VISUALIZERS.build(visualizer_cfg)
# 任意代码位置
det_local_visualizer = Visualizer.get_current_instance()
det_local_visualizer.add_datasample('det', image, data_sample)
4.4 初始化
- 基于 Pytorch 构建模型时,我们通常会选择 nn.Module 作为模型的基类,搭配使用 Pytorch 的初始化模块 torch.nn.init,完成模型的初始化。MMEngine 在此基础上抽象出基础模块(BaseModule),让我们能够通过传参或配置文件来选择模型的初始化方式。此外,MMEngine 还提供了一系列模块初始化函数,让我们能够更加方便灵活地初始化模型参数。
4.5 分布式通信原语
- 在分布式训练或测试的过程中,不同进程有时需要根据分布式的环境信息执行不同的代码逻辑,同时不同进程之间也经常会有相互通信的需求,对一些数据进行同步等操作。 PyTorch 提供了一套基础的通信原语用于多进程之间张量的通信,基于这套原语,MMEngine 实现了更高层次的通信原语封装以满足更加丰富的需求。基于 MMEngine 的通信原语,算法库中的模块可以
- 在使用通信原语封装时不显式区分分布式/非分布式环境
- 进行除 Tensor 以外类型数据的多进程通信
- 无需了解底层通信后端或框架
- 这些通信原语封装的接口和功能可以大致归类为如下三种,我们在后续章节中逐个介绍
- 分布式初始化:init_dist 负责初始化执行器的分布式环境
- 分布式信息获取与控制:包括 get_world_size 等函数获取当前的 rank 和 world_size 等信息
- 分布式通信接口:包括如 all_reduce 等通信函数(collective functions)
4.6 记录日志
- 执行器(Runner)在运行过程中会产生很多日志,例如损失、迭代时间、学习率等。MMEngine 实现了一套灵活的日志系统让我们能够在配置执行器时,选择不同类型日志的统计方式;在代码的任意位置,新增需要被统计的日志。
- 我们可以通过在构建执行器时候配置日志处理器,来灵活地选择日志统计方式。如果不为执行器配置日志处理器,则会按照日志处理器的默认参数构建实例,效果等价于:
log_processor = dict(window_size=10, by_epoch=True, custom_cfg=None, num_digits=4)
4.7 文件读写
- MMEngine 实现了一套统一的文件读写接口,可以用同一个函数来处理不同的文件格式,如 json、 yaml 和 pickle,并且可以方便地拓展其它的文件格式。除此之外,文件读写模块还支持从多种文件存储后端读写文件,包括本地磁盘、Petrel(内部使用)、Memcached、LMDB 和 HTTP。
5. 恢复训练
- 恢复训练是指从之前某次训练保存下来的状态开始继续训练,这里的状态包括模型的权重、优化器和优化器参数调整策略的状态。
5.1 自动恢复训练
- 用户可以设置 Runner 的 resume 参数开启自动恢复训练的功能。在启动训练时,设置 Runner 的 resume 等于 True,Runner 会从 work_dir 中加载最新的 checkpoint。如果 work_dir 中有最新的 checkpoint(例如该训练在上一次训练时被中断),则会从该 checkpoint 恢复训练,否则(例如上一次训练还没来得及保存 checkpoint 或者启动了新的训练任务)会重新开始训练。下面是一个开启自动恢复训练的示例
runner = Runner(
model=ResNet18(),
work_dir='./work_dir',
train_dataloader=train_dataloader_cfg,
optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
train_cfg=dict(by_epoch=True, max_epochs=3),
resume=True,
)
runner.train()
5.2 指定 checkpoint 路径
- 如果希望指定恢复训练的路径,除了设置 resume=True,还需要设置 load_from 参数。需要注意的是,如果只设置了 load_from 而没有设置 resume=True,则只会加载 checkpoint 中的权重并重新开始训练,而不是接着之前的状态继续训练。
runner = Runner(
model=ResNet18(),
work_dir='./work_dir',
train_dataloader=train_dataloader_cfg,
optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
train_cfg=dict(by_epoch=True, max_epochs=3),
load_from='./work_dir/epoch_2.pth',
resume=True,
)
runner.train()
6. 加速训练
6.1 分布式训练
- MMEngine 支持 CPU、单卡、单机多卡以及多机多卡的训练。当环境中有多张显卡时,我们可以使用以下命令开启单机多卡或者多机多卡的方式从而缩短模型的训练时间。
6.1.1 单机多卡
- 假设当前机器有 8 张显卡,可以使用以下命令开启多卡训练
python -m torch.distributed.launch --nproc_per_node=8 examples/train.py --launcher pytorch
- 如果需要指定显卡的编号,可以设置 CUDA_VISIBLE_DEVICES 环境变量,例如使用第 0 和第 3 张卡
CUDA_VISIBLE_DEVICES=0,3 python -m torch.distributed.launch --nproc_per_node=2 examples/train.py --launcher pytorch
6.1.2 多机多卡
- 假设有 2 台机器,每台机器有 8 张卡。
- 第一台机器运行以下命令
python -m torch.distributed.launch \
--nnodes 8 \
--node_rank 0 \
--master_addr 127.0.0.1 \
--master_port 29500 \
--nproc_per_node=8 \
examples/train.py --launcher pytorch
- 第 2 台机器运行以下命令
python -m torch.distributed.launch \
--nnodes 8 \
--node_rank 1 \
--master_addr 127.0.0.1 \
--master_port 29500 \
--nproc_per_node=8 \
examples/train.py --launcher pytorch
- 如果在 slurm 集群运行 MMEngine,只需运行以下命令即可开启 2 机 16 卡的训练
srun -p mm_dev \
--job-name=test \
--gres=gpu:8 \
--ntasks=16 \
--ntasks-per-node=8 \
--cpus-per-task=5 \
--kill-on-bad-exit=1 \
python examples/train.py --launcher="slurm"
6.2 混合精度训练
- Nvidia 在 Volta 和 Turing 架构中引入 Tensor Core 单元,来支持 FP32 和 FP16 混合精度计算。开启自动混合精度训练后,部分算子的操作精度是 FP16,其余算子的操作精度是 FP32。这样在不改变模型、不降低模型训练精度的前提下,可以缩短训练时间,降低存储需求,因而能支持更大的 batch size、更大模型和尺寸更大的输入的训练。
- PyTorch 从 1.6 开始官方支持 amp。如果你对自动混合精度的实现感兴趣,可以阅读 torch.cuda.amp: 自动混合精度详解。
- MMEngine 提供自动混合精度的封装 AmpOptimWrapper,只需在 optim_wrapper 设置 type=‘AmpOptimWrapper’ 即可开启自动混合精度训练,无需对代码做其他修改。
runner = Runner(
model=ResNet18(),
work_dir='./work_dir',
train_dataloader=train_dataloader_cfg,
optim_wrapper=dict(type='AmpOptimWrapper', optimizer=dict(type='SGD', lr=0.001, momentum=0.9)),
train_cfg=dict(by_epoch=True, max_epochs=3),
)
runner.train()
7. 节省显存
- 在深度学习训练推理过程中显存容量至关重要,其决定了模型是否能成功运行。常见的节省显存办法包括:
- 梯度累加
- 梯度累加是指在每计算一个批次的梯度后,不进行清零而是进行梯度累加,当累加到一定的次数之后,再更新网络参数和梯度清零。 通过这种参数延迟更新的手段,实现与采用大 batch 尺寸相近的效果,达到节省显存的目的。但是需要注意如果模型中包含 batch normalization 层,使用梯度累加会对性能有一定影响。
- 梯度检查点
- 梯度检查点是一种以时间换空间的方法,通过减少保存的激活值来压缩模型占用空间,但是在计算梯度时必须重新计算没有存储的激活值。在 torch.utils.checkpoint 包中已经实现了对应功能。简要实现过程是:在前向阶段传递到 checkpoint 中的 forward 函数会以 torch.no_grad 模式运行,并且仅仅保存输入参数和 forward 函数,在反向阶段重新计算其 forward 输出值。
- 大模型训练技术
- 最近的研究表明大型模型训练将有利于提高模型质量,但是训练如此大的模型需要巨大的资源,单卡显存已经越来越难以满足存放整个模型,因此诞生了大模型训练技术,典型的如 DeepSpeed ZeRO 和 FairScale 的完全分片数据并行(Fully Sharded Data Parallel, FSDP)技术,其允许在数据并行进程之间分片模型的参数、梯度和优化器状态,并同时仍然保持数据并行的简单性。
- MMEngine 目前支持梯度累加和大模型训练 FSDP 技术 。下面说明其用法。
7.1 梯度累加
- 配置写法如下所示:
optim_wrapper_cfg = dict(
type='OptimWrapper',
optimizer=dict(type='SGD', lr=0.001, momentum=0.9),
# 累加 4 次参数更新一次
accumulative_counts=4)
- 配合 Runner 使用的完整例子如下:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from mmengine.runner import Runner
from mmengine.model import BaseModel
train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
train_dataloader = DataLoader(train_dataset, batch_size=2)
class ToyModel(BaseModel):
def __init__(self) -> None:
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, img, label, mode):
feat = self.linear(img)
loss1 = (feat - label).pow(2)
loss2 = (feat - label).abs()
return dict(loss1=loss1, loss2=loss2)
runner = Runner(
model=ToyModel(),
work_dir='tmp_dir',
train_dataloader=train_dataloader,
train_cfg=dict(by_epoch=True, max_epochs=1),
optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01),
accumulative_counts=4)
)
runner.train()
7.2 大模型训练
- PyTorch 1.11 中已经原生支持了 FSDP 技术。配置写法如下所示:
# 位于 cfg 配置文件中
model_wrapper_cfg=dict(type='MMFullyShardedDataParallel', cpu_offload=True)
- 配合 Runner 使用的完整例子如下:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from mmengine.runner import Runner
from mmengine.model import BaseModel
train_dataset = [(torch.ones(1, 1), torch.ones(1, 1))] * 50
train_dataloader = DataLoader(train_dataset, batch_size=2)
class ToyModel(BaseModel):
def __init__(self) -> None:
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, img, label, mode):
feat = self.linear(img)
loss1 = (feat - label).pow(2)
loss2 = (feat - label).abs()
return dict(loss1=loss1, loss2=loss2)
runner = Runner(
model=ToyModel(),
work_dir='tmp_dir',
train_dataloader=train_dataloader,
train_cfg=dict(by_epoch=True, max_epochs=1),
optim_wrapper=dict(optimizer=dict(type='SGD', lr=0.01)),
cfg=dict(model_wrapper_cfg=dict(type='MMFullyShardedDataParallel', cpu_offload=True))
)
runner.train()
- 注意:必须在分布式训练环境中 FSDP 才能生效。
8. 跨库调用模块
- 通过使用 MMEngine 的注册器(Registry)和配置文件(Config),用户可以实现跨软件包的模块构建。
- 例如,在 MMDetection 中使用 MMClassification 的 Backbone,或者在 MMRotate 中使用 MMDetection 的 Transform,或者在 MMTracking 中使用 MMDetection 的 Detector。 一般来说,同类模块都可以进行跨库调用,只需要在配置文件的模块类型前加上软件包名的前缀即可。
8.1 跨库调用 Backbone
- 以在 MMDetection 中调用 MMClassification 的 ConvNeXt 为例,首先需要在配置中加入 custom_imports 字段将 MMClassification 的 Backbone 添加进注册器,然后只需要在 Backbone 的配置中的 type 加上 MMClassification 的软件包名 mmcls 作为前缀,即 mmcls.ConvNeXt 即可:
# 使用 custom_imports 将 mmcls 的 models 添加进注册器
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
model = dict(
type='MaskRCNN',
data_preprocessor=dict(...),
backbone=dict(
type='mmcls.ConvNeXt', # 添加 mmcls 前缀完成跨库调用
arch='tiny',
out_indices=[0, 1, 2, 3],
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth',
prefix='backbone.')),
neck=dict(...),
rpn_head=dict(...))
8.2 跨库调用Transform
- 与上文的跨库调用 Backbone 一样,使用 custom_imports 和添加前缀即可实现跨库调用
# 使用 custom_imports 将 mmdet 的 transforms 添加进注册器
custom_imports = dict(imports=['mmdet.datasets.transforms'], allow_failed_imports=False)
# 添加 mmdet 前缀完成跨库调用
train_pipeline=[
dict(type='mmdet.LoadImageFromFile'),
dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
dict(type='mmdet.Resize', scale=(1024, 2014), keep_ratio=True),
dict(type='mmdet.RandomFlip', prob=0.5),
dict(type='mmdet.PackDetInputs')
]
8.3 跨库调用Detector
- 跨库调用算法是一个比较复杂的例子,一个算法会包含多个子模块,因此每个子模块也需要在type中增加前缀,以在 MMTracking 中调用 MMDetection 的 YOLOX 为例:
# 使用 custom_imports 将 mmdet 的 models 添加进注册器
custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
model = dict(
type='mmdet.YOLOX',
backbone=dict(type='mmdet.CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
neck=dict(
type='mmdet.YOLOXPAFPN',
in_channels=[320, 640, 1280],
out_channels=320,
num_csp_blocks=4),
bbox_head=dict(
type='mmdet.YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
train_cfg=dict(assigner=dict(type='mmdet.SimOTAAssigner', center_radius=2.5)))
- 为了避免给每个子模块手动增加前缀,配置文件中引入了 _scope_ 关键字,当某一模块的配置中添加了 scope 关键字后,该模块配置文件下面的所有子模块配置都会从该关键字所对应的软件包内去构建:
# 使用 custom_imports 将 mmdet 的 models 添加进注册器
custom_imports = dict(imports=['mmdet.models'], allow_failed_imports=False)
model = dict(
_scope_='mmdet', # 使用 _scope_ 关键字,避免给所有子模块添加前缀
type='YOLOX',
backbone=dict(type='CSPDarknet', deepen_factor=1.33, widen_factor=1.25),
neck=dict(
type='YOLOXPAFPN',
in_channels=[320, 640, 1280],
out_channels=320,
num_csp_blocks=4),
bbox_head=dict(
type='YOLOXHead', num_classes=1, in_channels=320, feat_channels=320),
train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)))
- 以上这两种写法互相等价。
文章出处登录后可见!
已经登录?立即刷新