看到kaggle上的大佬经常用到模型融合策略来提分,所以今天就来一探究竟。
1.常用的模型融合方法
常用的模型融合方法如下:
- 投票法
- 平均法
- 权重法
- stacking法
1.1投票法
投票法常常被用于分类网络,通过对多个模型的预测结果进行vote操作,来得到最终的预测结果,此处就不详细讲了。
1.2平均法
顾名思义,就是对多个模型的预测结果进行平均,得到最终的预测结果,常用于分割等回归问题,实现也较简单,不赘述。
pred = (pred1+pred2+…+predn)/n
1.3权重法
权重法是平均法的改进,即对每个模型的预测结果不是直接进行相加求均值,二者计算每个模型的预测结果占所有模型预测结果的占比,这个占比就是该模型的预测结果权重。
w1 = pred1 / (pred1+pred2+…+predn)
w2 = pred2 / (pred1+pred2+…+predn)
……
pred = (w1*pred1 + w2*pred2 + … wn*predn) / (pred1+pred2+…+predn)
1.4stacking模型融合
1.4.1图解stacking
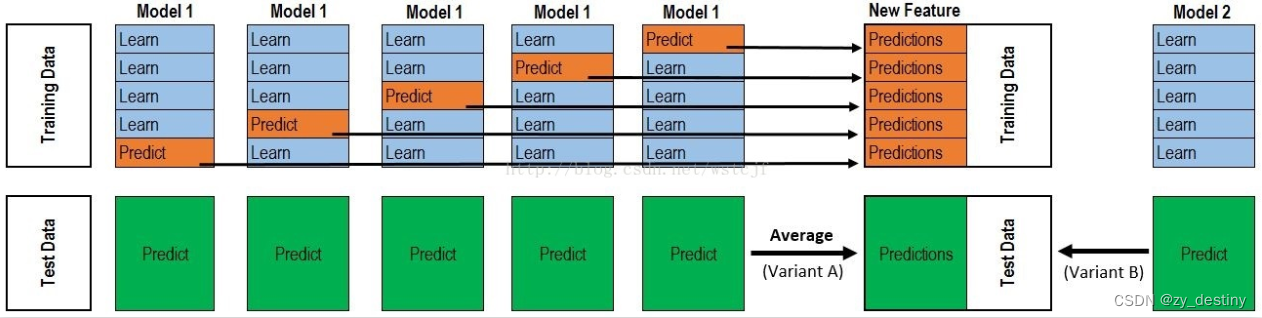
根据上图分析一下stacking具体步骤:
1)TrainingData进行5-fold分割,正好生成5个model,每个model预测训练数据的1/5部分,最后合起来正好是一个完整的训练集Predictions(橙色部分),行数与TrainingData一致。
2)TestData数据,model1-model5每次都对TestData进行预测,形成5份完整的Predict(绿色部分),最后对这个5个Predict取平均值,得到测试集Predictions,行数与TestData一致。。
3)上面的1)与2)步骤只是一个模型的过程,因为我们需要集成很多个模型,那么重复n个模型,做法和上面是一样的,那么我们stacking第一层出来,在验证集上得到的结果特征维度,就是(train_set_number,n),同理,在测试集上的预测结果也就是(test_set_number,n)。
4)stacking第一层出来的(train_set_number,n)维度和training_data的真实label(维度为(train_set_number,1))合起来,就形成了新的训练样本数据,也就是第二层的训练数据;(test_set_number,n)维度的测试集就是第二层的测试数据。(ps:(train_set_number,n)维度的数据作为第二层的输入img,training_data的真实label(维度为(train_set_number,1))为第二层的输入label,进行模型训练。
5)利用meta model(可以是任意一个模型),其实就是再找一种算法对上述第二层训练数据进行建模预测,预测出来的数据就是最终预测结果。
1.4.2代码展示
stack_model = [model1,model2,model3,model4,model5] #此处的model1~model5为自己定义的模型
ntrain = train_data.shape[0]#训练集样本数量
ntest = test_data.shape[0]#测试集样本数量
train_stack = np.zeros(ntrain,5)#5表示5个模型
test_stack = np.zeros(ntest,5)
kf = Kfold.split(train_data,train_label)#k折交叉验证
#第一层stacking
for i ,model in emumerate(stack_model):
for j ,(train_fold,val_fold) in emumerate(kf):
X_train,X_val,label_train,label_val = train_data[train_fold,:],train_data[val_fold,:],train_label[train_fold,:],train_label[val_fold,:]
model.fit(X_train, label_train)
train_stack[val_fold, i] = model.predict(X_val)
test_stack[:,i] = model.predict(test_data)
#第二层stacking
final_model = model6()
final_model.fit(train_stack,train_label)
final_pred = final_model.predict(test_stack)
#final_pred就是最终的输出整理不易,欢迎一键三连!!!
文章出处登录后可见!