【几个问题待解决:1.LDA的先计算联合概率体现在哪里 2.对于theta 的采样的理解,下文中的theta1 ,theta2等其实是指theta向量中的第一个,第二个等,也就是不同文章的不同单词的主题,固定其他,分别重新从计算的概率分布再次抽取主题】
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,因此我们可以考虑对于语料库的表示采用tf-idf的方式表示。
1. 输入:LDA的最小单元输入是文档,不管文档里有多少个字
2. 模型参数:
:是针对每个文档都有一个主题的概率分布,这时得到参数
,是一个K维的向量,K是主题个数
:V*K的矩阵,其中,K是主题个数,V是词库里的单词个数,矩阵中的每个位置是该单词分为某个主题的概率
(注意:LDA时无监督算法,不需要标注,数据放到模型中会自动学习每个文档的主题分布和主题的词分布,也就是模型参数)
3. 假设:
每个文档属于多个主题。
为了更好的理解LDA是一个贝叶斯模型,我们类比LDA和朴素贝叶斯,LDA不像朴素贝叶斯那样,每个文档只有一个主题,就是概率最大的主题,这里每个文档都有一个对应主题的概率分布,这就意味着LDA是一个Soft Classifying,而不是Hard Classifying
同样,这也类似于K-Means和GMM,K-Means也是根据对一个数据点只将其分类为概率最大的类别,而GMM则是对一个数据点所有可能的类别进行判断,这是模型设计就决定的特点。
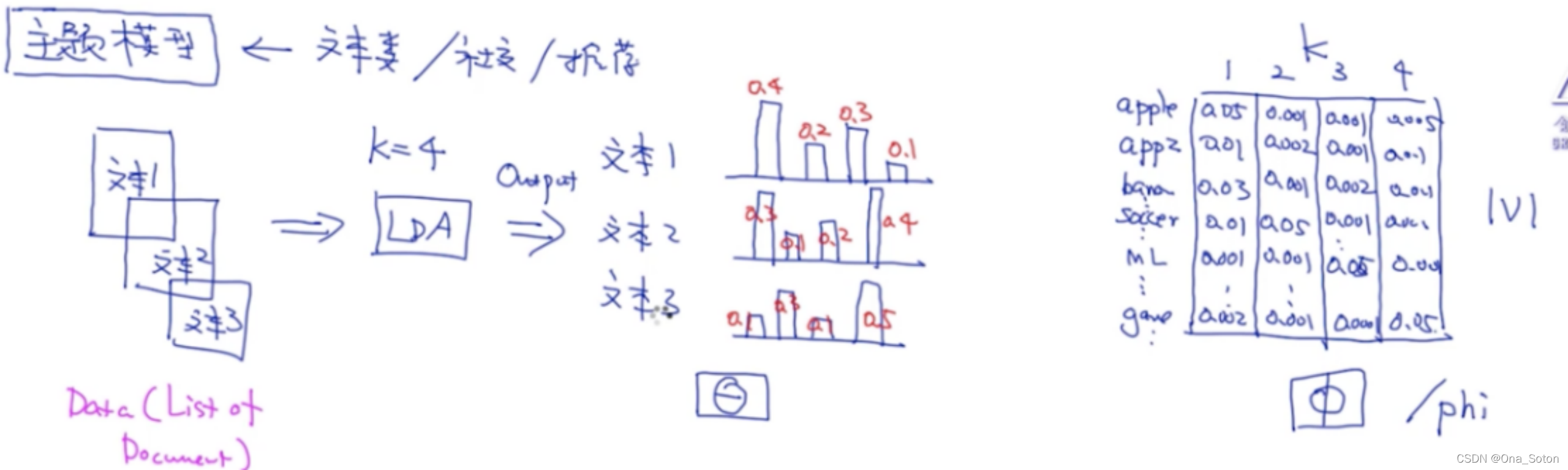
4. LDA的生成过程
理解生成模型一定要理解它的生成过程。
首先明确我们的目标是使用LDA模型生成一个文档,第一步是选定主题,根据文档的主题分布抽取单个或多个主题,其次生成单词,根据抽取的主题和参数生成单词(这里注意:选择主题和选择主题下的单词并不是就一定选择概率最大的,只可以说概率越大的越有可能被选择到)

1)定义变量:
K:主题个数
N:文档个数
Ni:文档i中包含的单词个数
模型参数:i和
超参数: 和
隐含变量:Zij和Wij
2)四个依赖关系
–>
: 服从狄利克雷分布,是
–> Zij的共轭先验
–> Zij:服从多项式分布
–>
:服从狄利克雷分布,是
–> Wij的共轭先验
–> Wij:服从多项式分布
整个生成过程只有Wij是已知的,可以观测到的, 和
又是人为设定的超参数,因此,我们未知的参数就是
还有Z,因为贝叶斯模型最终要计算的就是后验概率,这个很难估计,我们将使用MCMC中很经典的Gibbs Sampling来计算,也就是计算P(
,
,Z|
,
,W)因为一下子采样
三个参数较为困难,因此我们将三个参数展开,(1,
2,
3,…,
1,
2,
3,…,Z1,…),对于Gibbs Sampling,我们先采样
1,假定其他都是已知的,然后求解
2,假定其他都是已知的,以此类推,这就是Gibbs Sampling,这个过程类似于Lasso中的Coordinate Descent
接下来就是计算:
A:首先就是 i的采样
计算需要先根据Markov Blanket的规则提取与 i相关的变量,分别是
和Z
根据Gibbs采样,问题是:P(i|
,Z,W,
,
),但由于只有
和Z和
i有关,因此问题简化为: P(
i|
,Z),要求解这个后验概率,我们根据后验=先验*似然,也就是:
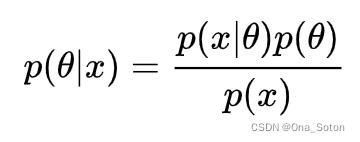
得到:
P(i|
,Z)
P(
i|
)* P(Z|
i)
因为 P(i|
)是服从狄利克雷分布的,而 P(Z|
i)是服从多项式分布的,因此P(
i|
,Z)也是服从狄利克雷分布的,根据狄利克雷分布的公式,我们得到:
P(i|
)=
其中,I为指示函数
提取公共的部分也就是连乘的k,式子变成了:
这个式子又可以还原为Dir分布的表达式,
其中,表示为在第i个文章里,有多少个单词被分类为主题1
注意:这个P的概率分布指的是的概率分布,而它又是服从的
,也就是上边公式中的
,倘若原本的超参数
根据经验设定为
=(1,1,1,……,1)(这里需要注意的是,
的维度是K维的,也就是主题个数),那么通过不断的训练,样本量的增加,那么
会在
人为设定的初始值的条件下不断进行更新从而最终收敛,
(
就是代表第i个文章里,有多少个单词被分类为第k个主题)
B.采样Zij(注意:在训练时,先训练Zij,首先对于每个文章中的每个单词根据根据超参数alpha分随机分配一个主题,然后分别对每个单词再次随机抽样一个新的主题,更新统计它们的主题和文章单词的矩阵(注意这个矩阵是一个中间变量,用于记录每个文章中每个单词的主题),并更新主题的概率分布,依次遍历整个样本集,这是迭代一次的结果,根据设定的迭代次数进行迭代更新,最终得到最后的文章每个单词的主题,然后才会更新和
参数,其实记录文章单词和主题分布的矩阵就相当于
的作用,只是在代码中最后更新,并需要归一化)
首先,我们依然是根据关系图,提取出和Zij有关的变量
右边式子的第一项其实就是参数的具体的某个值,
ik;第二项是参数
,在某个主题下产生某个单词Wij的概率,因此式子变为:
C.采样
过程类似于 i的采样,其也是Dir分布,这里就不再具体解释。这里需要注意
的共轭先验是
的Dir分布,注意
和
都是V维的向量,V是词库的大小。
在代码实现层面:我们需要人为的给定超参数和
的值,其次我们还需要给定文章需要属于的主题个数K,K的确定可以采用Perplexity进行确定。

【理解无监督】
LDA是对于给定的数据集X,X中的每个样本,也就是一条数据代表一个文章,我们预先对于文章中的每个词汇根据预先给定的主题分布参数的先验
分配一个主题,然后进行训练,训练过程中随着样本的增加,不断的更新
,最终收敛
【从生成式模型理解LDA】
所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
一般来说,产生式模型希望通过一个产生过程来帮助读者理解一个模型。这个产生过程本质是描述一个联合概率分布的分解过程。也就是说,这个过程是一个虚拟过程,真实的数据往往并不是这样产生的。这样的产生过程是模型的一个假设,一种描述。任何一个产生过程都可以在数学上完全等价一个联合概率分布。LDA 的产生过程描述了文档以及文档中文字的生成过程。
【LDA是一个典型的贝叶斯模型】
1.不是点估计,不一定选取概率最大的,而是得到概率分布
2.我们在其中加入的先验是针对模型参数加入了一个先验,这就用到了共轭先验,简化了运算,像是多项式分布的共轭先验是狄利克雷分布,二项式分布的共轭先验是Beta分布
文章出处登录后可见!