文章目录
Abstract
给定人类的命令,并且用人工标注想要的结果,构成数据集,使用监督学习来微调GPT-3。
然后,我们对模型输出进行排名,构成新的数据集,我们利用强化学习来进一步微调这个监督模型。
我们把产生的模型称为InstructGPT。
Starting with a set of labeler-written prompts and prompts
submitted through the OpenAI API, we collect a dataset of labeler demonstrations
of the desired model behavior, which we use to fine-tune GPT-3 using supervised
learning. We then collect a dataset of rankings of model outputs, which we use to
further fine-tune this supervised model using reinforcement learning from human
feedback. We call the resulting models InstructGPT.
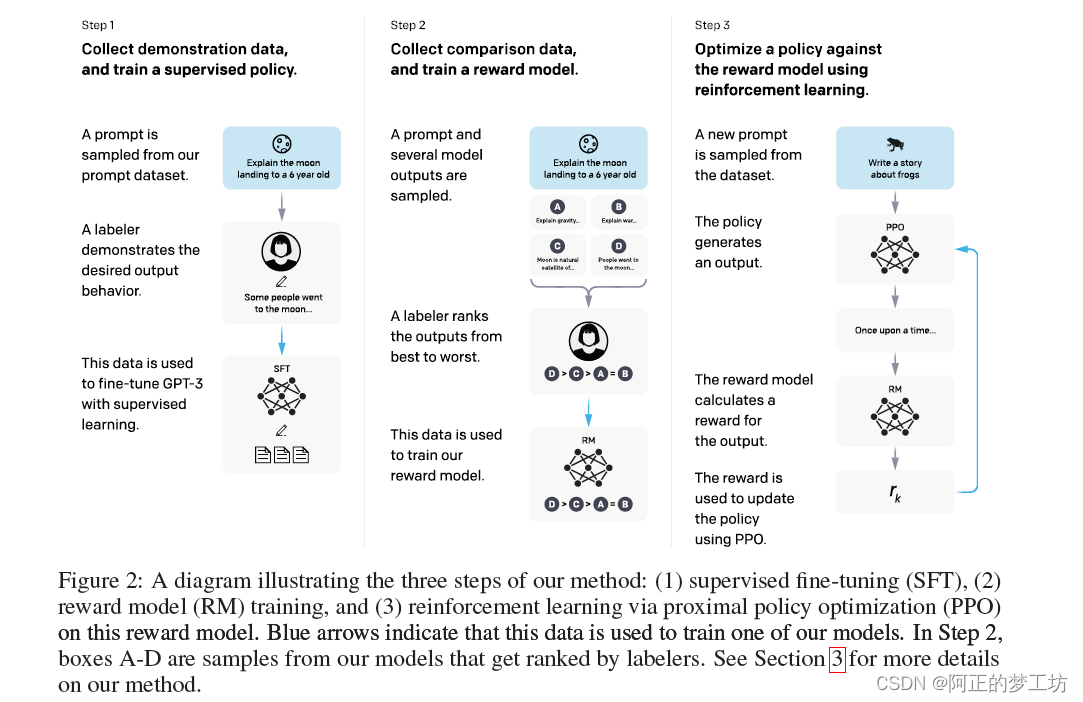
具体实施的三个步骤
- 手动选择一些问题,并手动给出答案,以这个数据集来训练SFT模型。
- 让训练好的SFT模型回答一些问题,人工对答案进行评分排序,然后用这部分数据集来训练奖励模型RM。
- 根据奖励模型RM的评分结果,继续优化SFT模型。
结果
InstructGPT的参数是GPT-3的1/100,但是性能更好。同时,InstructGPT在可信性和减少有害的输出上更好。
In human evaluations on
our prompt distribution, outputs from the 1.3B parameter InstructGPT model are
preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters.
Moreover, InstructGPT models show improvements in truthfulness and reductions
in toxic output generation while having minimal performance regressions on public
NLP datasets.
文章链接:https://arxiv.org/pdf/2203.02155.pdf
文章出处登录后可见!