Focal loss
目前目标检测的算法大致分为两类,One Stage 、Two Stage。
One Stage:主要指类似YOLO、SGD等这样不需要region proposal,直接回归的检测算法,这类算法检测速度很快,但是精度准确率不如使用Two stage的模型。
two Stage:主要指FastRCNN、RFCN等这样需要region proposal的检测算法。这类算法可以达到很高的进度,但是同时检测速度较慢。虽然可以减少Proposal的数量或者降低输入图像的分辨率等方式达到提速。
作者提出Focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。
核心思想:
那么作者one stage 的准确率不如 two stage 的原因是:样本类别不均衡导致的。
而在目标检测领域,一张图可能生成成千上万候选位置(candidate locations)但是一般只有其中一小部分是包含object的,这就带来了类别不均衡。
那么类别不均衡带来的影响是:
负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。
因此作者提出一种focal loss的损失函数方法,在交叉熵的基础上进行构建。
这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
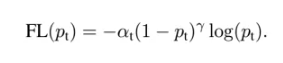
重要性质:
1:当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;
当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。
当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2:当γ=0的时候,focal loss就是传统的交叉熵损失,
当γ增加的时候,调制系数也会增加。 。γ增大能增强调制因子的影响,实验发现γ取2最好。
直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。
当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,
但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
(a)在交叉熵的基础上加上参数a,a=0.5就表示传统的交叉熵,当a=0.75的时候效果最好,AP值提升了0.9。
(b)对比不同的参数γ和a的实验结果,可以看出随着γ的增加,AP提升比较明显。对于固定的α,当γ等于2的时候能达到最高的AP
(c)不同的anchor的scale和aspect ratio,选择2 scale,3 aspect ratio效果最好
参考文章
https://zhuanlan.zhihu.com/p/49981234
文章出处登录后可见!