提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
ViT (Vision Transformer) 是首次成功将 Transformer引入到视觉领域的尝试,开辟了视觉Transformer的先河。这里先对ViT的原理进行阐述,并对预训练文件ViT-B_16.npz的内容做一个简要介绍。
一、ViT原理图
ViT (Vision Transformer) 是首次成功将 Transformer引入到视觉领域的尝试,开辟了视觉Transformer的先河。其原理如图1所示。
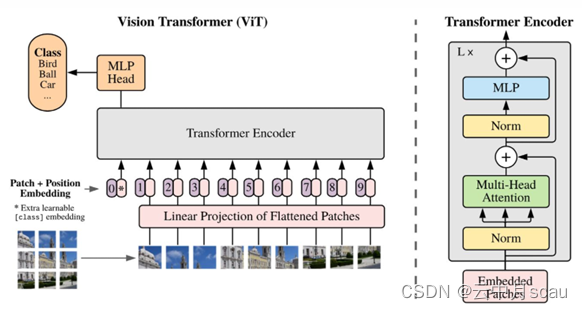
如图1所示,ViT将一张图片拆分成9个patch,增加一个用于分类的patch(星号),图中的数字0,1,2,…,8,9用于记录图片的位置信息。
图片分类中通常不需要解码器模块,所以这里只需关注编码器部分,其中主要包括:位置编码模块Positional Encoding、多头自注意力模块Muti-Head Attention、前向网络模块 Feed Forward (MLP) 以及必要的Norm、Dropout 和残差模块等。各模快的功能简介如下:
(1)位置编码模块Positional Encoding:用于给输入的序列增加额外的位置信息。
(2)多头自注意力模块 Muti-Head Attention:用于计算全局空间注意力。
(3)前向网络模块 Feed Forward(MLP):用于对通道维度信息进行混合。
(4)Norm、Dropout 和残差模块:提供了更好的收敛速度和性能。
二、算法实现过程
2.1 实现过程
首先,将图片分成无重叠的固定大小 Patch (例如16×16),然后将每个 Patch 拉成一维向量,n个Patch相当于NLP中的输入序列长度。假设输入图片是 224x224x3,每个 patch大小是16×16,则n是(224/16)2 =196。而一维向量长度等价于词向量编码长度,等于(图片通道数3)x(patch的大小)= 3 x16 x 16=768, 即每个序列的向量长度是768)。
其次,考虑到一维向量维度较大(196),需要将拉伸后的 Patch序列经过线性投影 ( nn.Linear ) 压缩维度(本模型未压缩维度),同时也可以实现特征变换功能,这两个步骤可以称为图片 Token化过程 (Patch Embedding)。为了方便后续分类,还额外引入一个可学习的 Class Token,该 Token 插入到图片 token 化后所得序列的开始位置。
然后,将上述序列加上可学习的位置编码并输入到 N个串行的 Transformer 编码器中进行全局注意力计算和特征提取,其中内部的多头自注意模块用于进行 Patch间或者序列间特征提取,而后面的 Feed Forward (Linear+ GELU+Dropout+ Linear+ Dropout) 模块对每个Patch或者序列进行特征变换。
最后,将最后一个Transformer编码器输出序列的第0位置( Class Token位置对应输出)提取出来,后面接MLP分类后,然后正常分类即可。
2.2 实现过程的张量维度变化
对于标准的Transformer模型,要求输入的应该是token(向量)序列,即二维矩阵[num_token, token_dim]。其中,num_token表示token长度,如前述的196,token_dim表示每个token的编码成度,也叫embedding长度,如前述的768。
在代码实现中,直接通过一个二维卷积层实现,如本模型ViT-B/16,使用卷积核大小16 x16,stride为16,卷积核个数为768,然后展平变成二维张量。计算过程的维度变化如下:
[224,224,3] -> [14,14,768]-> [196,768]
在输入Transformer Encoder之前,需要加上[class] token以及位置编码position embedding,两者都是可训练参数。在patch token序列上拼接class token,然后加上位置编码,计算过程及维度变化如下:
拼接[class] token:cat ([1,768], [196,768] ) à [197,768]
叠加Position Embedding:[196,768] à [197,768]
然后,这个叠加后的数据就可以输入Transformer Encoder层进行自注意力计算和特征提取。
三 、ViT-B/16结构详图
3.1 模型整体结构图
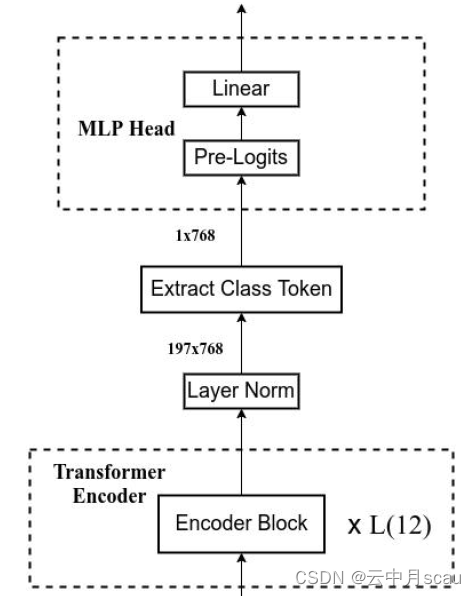
Vit-B/16模型的结构如图2所示,右侧的运算紧接左侧进行。注:Transformer Encoder 前有一个Dropout层,后有一个Layer Norm层。训练自己的网络时,可简单将MLP Head层看作一个全连接层。
|
|
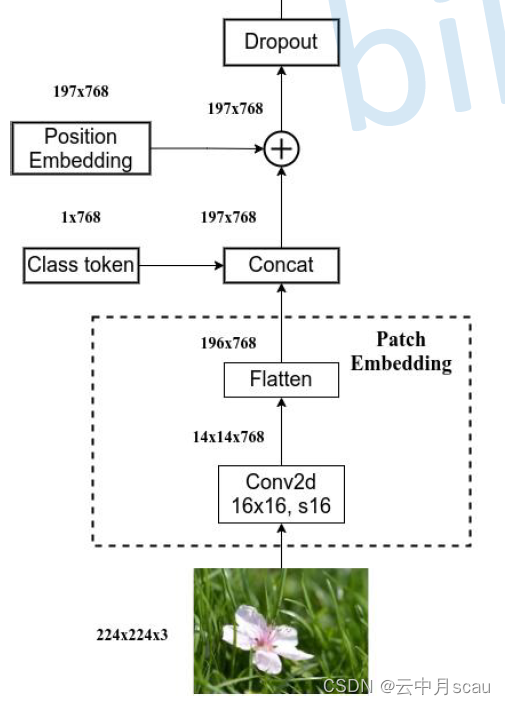
图2 Vit-B/16模型结构图
3.2 模型结构详图
模型结构包括了两个主要部分,即Encoder Block和MLP Block。
(1)Encoder Block结构
Encoder Block结构中,接收经过Position Embedding叠加后的Patch Embedding张量,先后执行两个带残差处理的模块。第一模块中,经过Layer Normalization -> Multi head Attention -> Dropout,并进行残差处理。第二部分,经过Layer Normalization -> MLP Block -> Dropout,并进行残差处理。处理后的张量维度不变,也为[197, 768]。
|
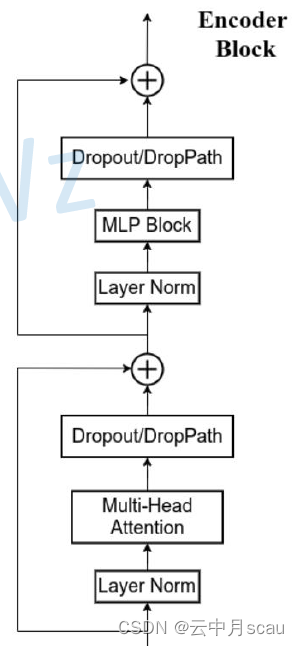
图3 Encoder Block结构
(2)MLP Block结构
MLP Block模快含有两层Feed Forward Network,具体包含Linear、激活函数GELU、Dropout、Linear、Dropout等子模块,完成每个Patch或者序列的特征变换。
|
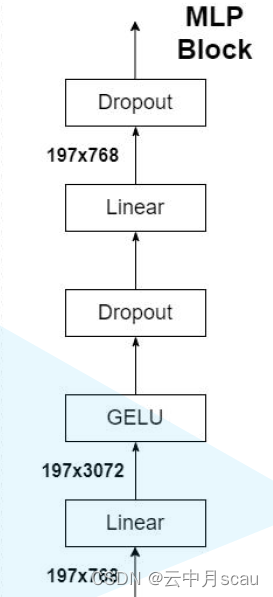
图4 MLP Block结构图
四、ViT-B/16预训练权重简析
ViT-B/16的预训练权重ViT-B_16.npz,这是一个numpy数组的压缩文件,可用numpy.load函数打开。
import numpy as np
vitfile = np.load(‘ViT-B_16.npz’)
vitfile.files #显示权重文件包含了数组名
vitfile[‘cls’] #查看数组cls的内容,cls为Numpy数组名
vitfile[‘cls’].shape #查看数组cls的维度
权重文件结构:
如前所示,ViT-B/16包括了位置编码模块Positional Encoding、多头自注意力模块Muti-Head Attention、前向网络模块 Feed Forward 以及必要的Norm、Dropout和残差模块。其中,ViT-B/16网络的Transformer Encoder堆叠了12层(L=12)Encoder,即有12个Encoder Block。因此,权重文件数组名及其维度如下:
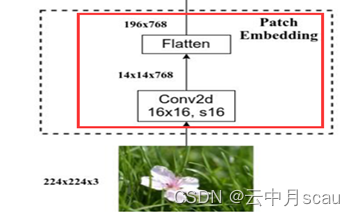
(1)图像Patch Embedding
'embedding/bias' #embedding偏置,维度(768,)
'embedding/kernel' #embedding权重,维度(16,16,3,768,)—kernel size,stride,in-channel,out-channel。权重数据在方框中的模块中。
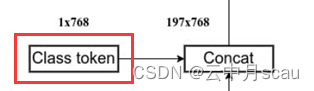
(2)分类Token(Class Token)
'cls' #分类Token,维度为(1, 1, 768)
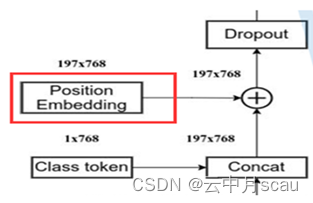
(3)位置编码
'Transformer/posembed_input/pos_embedding' #位置编码, 维度为(1, 577, 768) 。代码中会调整至(1, 197, 768)。
(4)Transformer Encoder模快
由于ViT-B/16的Transformer Encoder共有12个Encoder Block,序号为0-11,其结构相同,这里以第0个Encoder Block权重为例介绍。(#号后数字是维度信息)
'Transformer/encoderblock_0/LayerNorm_0/bias' # (768,)
'Transformer/encoderblock_0/LayerNorm_0/scale' # (768,)
'Transformer/encoderblock_0/LayerNorm_2/bias' # (768,)
'Transformer/encoderblock_0/LayerNorm_2/scale' # (768,)
'Transformer/encoderblock_0/MlpBlock_3/Dense_0/bias' # (3072,)
'Transformer/encoderblock_0/MlpBlock_3/Dense_0/kernel' # (768, 3072)
'Transformer/encoderblock_0/MlpBlock_3/Dense_1/bias' # (768,)
'Transformer/encoderblock_0/MlpBlock_3/Dense_1/kernel' # (3072, 768)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/key/bias' # (12, 64)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/key/kernel' # (768, 12, 64)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/out/bias' # (768,)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/out/kernel' #(12, 64, 768)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/query/bias' # (12, 64)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/query/kernel' #(768, 12, 64)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/value/bias' #(12, 64)
'Transformer/encoderblock_0/MultiHeadDotProductAttention_1/value/kernel' #(768, 12, 64)
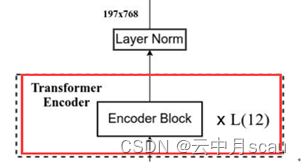
(5)Transformer Encoder之后的Layer Norm层
'Transformer/encoder_norm/bias', 维度:(768,)
'Transformer/encoder_norm/scale', 维度:(768,)
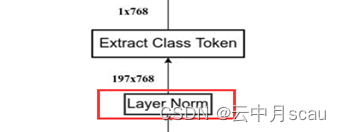
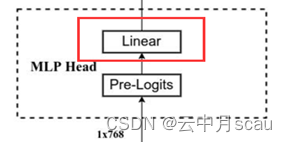
(6)MLP Head模块
'head/bias', #分类头偏置,维度:(1000,)
'head/kernel' #分类头权重,维度:(768, 1000),分类数为1000.
总结
本文仅仅简单介绍了Transformer Vision的基本原理,并对ViT-B/16 网络结构和权重数据进行了简单介绍。
参考文献:
文章出处登录后可见!