我们的征途是星辰大海,而并非烟尘人间。

文章目录
一、熵权法的原理
1.1 信息熵
熵是热力学的一个物理概念,是体系混乱度或无序度的度量,熵越大表示系统越乱(即携带的信息越少),熵越小表示系统越有序(即携带的信息越多)。信息熵借鉴了热力学中熵的概念,香农把信源所含有的信息量称为信息熵,用于描述平均而言事件信息量的大小,所以在数学上,信息熵是事件所包含的信息量的期望(mean,或称均值,或称期望,是试验中每次可能结果的概率乘以其结果的总和),根据期望的定义,可以设想信息熵的公式大概是:
其中H是信息熵,q是信源消息个数,是消息
出现的概率。
1.2 熵权法
信息是系统有序程度的一个度量,熵是系统无序程度的一个度量;根据信息熵的定义,对于某项指标,可以用熵值来判断某个指标的离散程度,其信息熵值越小,指标的离散程度越大, 该指标对综合评价的影响(即权重)就越大,如果某项指标的值全部相等,则该指标在综合评价中不起作用。因此,可利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
文字转述:我们分析某个因素时,主观地列出了一些有影响力的指标,这些指标已经与因变量存在某种的相关性,不管是正相关还是负相关,在同等变化量时,各指标的值也发生了一些变化,在某个阶段,X1变化了1,X2变化了0.5,因变量变化了1,从相关性的角度看X1的相关性比X2要大,X1对Y的影响更显著,那么再来看X1和X2的指标值,如果说同样按占比方式(一个值除以所有值之和)作归一化处理后,X1看似变化量相对较大,那么归一化后它的数据离散程度就越大,比如[1 1.5 2]和[1.5 1.75 2]归一化后为[0.22 0.33 0.44]和[0.28 0.33 0.38],前者的离散度要大于后者。这种方法虽然简单,但是用于企业的实际问题当中是非常有用的,比如说要根据业务人员的效益和产出情况评价他们的能力水平。
二、熵权法的主要步骤
2.1 数据标准化
首先将各个指标进行去量纲化处理。假设给定了m个指标:
![]()
其中
![]()
假设对各指标数据标准化后的值为
![]()
则
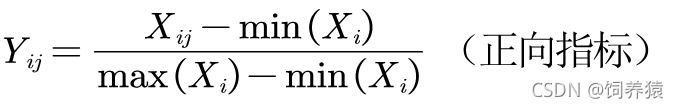
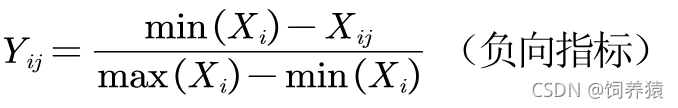
2.2 求各指标在各方案下的比值
设某一级指标有个m二级指标,且已取得n年数据,记为矩阵。在同一指标下,计算出各年取值占全部值的比重,公式如下:
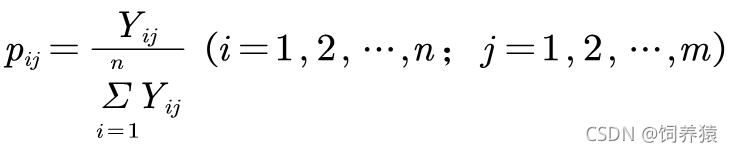
2.3 求各指标的信息熵。
根据信息论中信息熵的定义,一组数据的信息熵为:
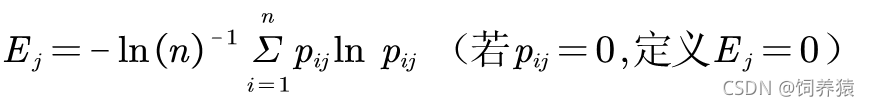
2.4 确定各指标的权重
根据信息熵的计算公式,计算出各个指标的信息熵为E1,E2,…,Em。
2.4.1 通过信息熵计算各指标的权重:
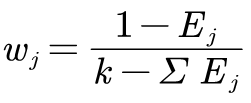
这里k指的是指标个数,即k=m。
2.4.2 通过计算信息冗余度来计算权重:
![]()
然后计算指标权值:
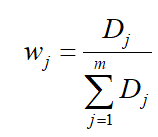
2.5 最后计算每个方案的综合评分
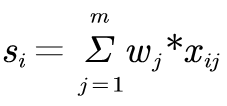
三、程序(MATLAB)
X=[124.3000 2.4200 25.9800 19.0000 3.1000 79.0000 54.1000 6.1400 3.5700 64.0000
134.7000 2.5000 21.0000 19.2500 3.3400 84.0000 53.7000 6.7400 3.5500 64.9600
193.3000 2.5600 29.2600 19.3100 3.4500 92.0000 54.0000 7.1800 3.4000 65.6500
118.6000 2.5200 31.1900 19.3600 3.5700 105.0000 53.9000 8.2000 3.2700 67.0100
94.9000 2.6000 28.5600 19.4500 3.3900 108.0000 53.6000 8.3400 3.2000 65.3400
123.8000 2.6500 28.1200 19.6200 3.5800 108.0000 53.3000 8.5100 3.1000 66.9900];
[n,m]=size(X);
for i=1:n
for j=1:m
p(i,j)=X(i,j)/sum(X(:,j));
end
end
%% 计算第 j 个指标的熵值 e(j)
k=1/log(n);
for j=1:m
e(j)=-k*sum(p(:,j).*log(p(:,j)));
end
d=ones(1,m)-e; % 计算信息熵冗余度
w=d./sum(d) % 求权值 w四、总结
4.1 熵权法的用途
熵权法是建模比赛中最基础的模型之一,其主要用于解决评价类问题(例如:选择哪种方案最好、哪位运动员或者员工表现的更优秀),用于确定每个指标所占权重,权重用于计算最终得分。
4.2 熵权法的优点
熵值法是根据各项指标指标值的变异程度来确定指标权数的,这是一种客观赋权法,避免了人为因素带来的偏差。相对那些主观赋值法,精度较高客观性更强,能够更好的解释所得到的结果。
主观赋值法:层次分析法,功效系数法,模糊综合评价法,综合指数法
4.3 熵权法的缺点
(1)忽略了指标本身重要程度,有时确定的指标权数会与预期的结果相差甚远,同时熵值法不能减少评价指标的维数,也就是熵权法符合数学规律具有严格的数学意义,但往往会忽视决策者主观的意图。
(2)如果指标值的变动很小或者很突然地变大变小,熵权法用起来有局限
在学习中成功、在学习中进步!我们一起学习不放弃~
记得三连哦~ 你们的支持是我最大的动力!!欢迎大家阅读往期文章哈~
小编联系方式如下,欢迎各位巨佬沟通交流。
int[] arr=new int[]{4,8,3,2,6,5,1};
int[] index= new int[]{6,4,5,0,3,0,2,6,3,1};
String QQ = "";
for (int i : index){
QQ +=arr[i];
}
System.out.println("小编的QQ:" + QQ);
文章出处登录后可见!