作为一名深度学习的小白,最近在做LSTM预测股票问题,发现训练集的shuffle必须为true而测试集的shuffle必须为false。如果训练集的shuffle不设置为true的话训练出来的模型不泛化,也就是只适合预测这一个数据集,换到别的数据集上效果不好也有可能在本数据集上预测的效果也不好。而测试集的shuffle不建议设置为true,一般的教程上只是提了要把训练集的shuffle设置为true,没有提测试集的要不要设置为true,所以困扰了我好几天。至于为什么测试集不能设置为true,我还没有整明白,在这里只是记录一下自己的学习过程和错误。
在LSTM预测时序数据的背景下,不把测试集shuffle设置为true是因为:
该模型的目的是去寻找该序列数据的规律,如果把测试集的顺序打乱那么LSTM预测结果的target就是混乱的,而LSTM预测出来的结果还是按照序列数据的那个规律预测的,那么展示的结果就是不准确的,驴唇对马嘴了属于是
最后,
因为LSTM需要的是序列数据,而训练集加载器的shuffle=true的话不就把这个序列打乱了吗?
猜想1:因为在将时序数据切割成监督数据的时候,比如time_step=3,那么就是三个数据一组,这个时候序列数据的顺序还是没有被打乱的,shuffle=true被打乱的顺序只是组与组之间的顺序,而组内数据与数据之间的顺序没有被打乱。
猜想2:如果上面的猜想1不成立的话,有两种解决办法:第一种就是训练集的加载器shuffle不设置为true,第二种方法是向数据中添加一个维度,这个维度代表了数据在序列中的位置信息(也就是顺序)
在预测时间序列的背景下,不管训练集的shuffle还是测试集的shuffle都不能设置为true。因为会打乱时序的前后关系。
Pytorch的DataLoader中的shuffle是先打乱,再取batch。
import sys
import torch
import random
import argparse
import numpy as np
import pandas as pd
import torch.nn as nn
from torch.nn import functional as F
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
from torch.utils.data import TensorDataset, DataLoader, Dataset
class DealDataset(Dataset):
def __init__(self):
xy = np.loadtxt(open('./iris.csv','rb'), delimiter=',', dtype=np.float32)
#data = pd.read_csv("iris.csv",header=None)
#xy = data.values
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dealDataset = DealDataset()
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=2,
shuffle=True)
#print(dealDataset.x_data)
for i, data in enumerate(train_loader2):
inputs, labels = data
#inputs, labels = Variable(inputs), Variable(labels)
print(inputs)
#print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())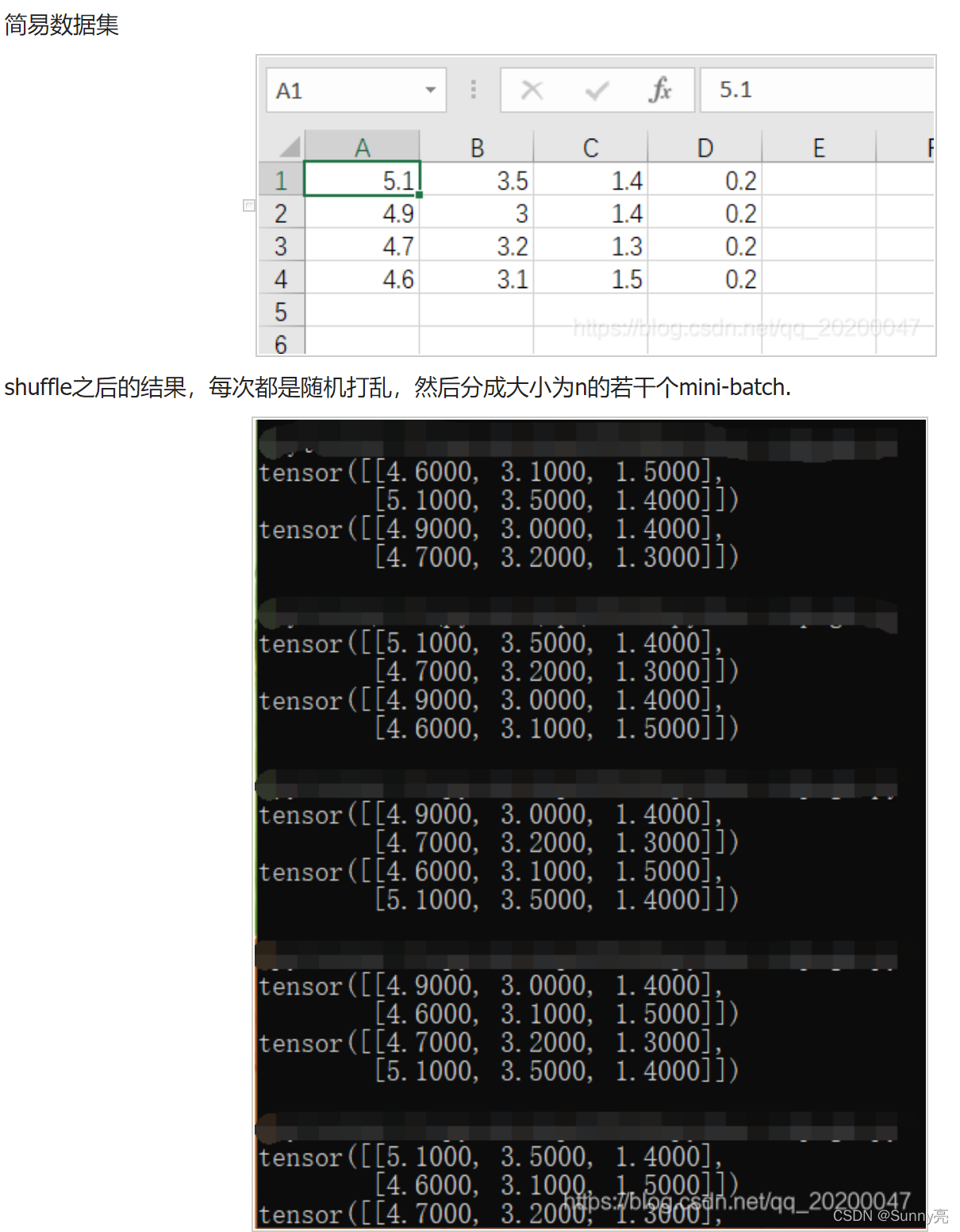
该测试shuffle来自:我对PyTorch dataloader里的shuffle=True的理解
在使用lstm时如果用移动窗口切数据,比如100天的数据,1-10天切一个样本,2-11天切一个样本,依此类推,lstm找寻的是10天内的时序依赖关系,即使打乱顺序,对lstm来说时间序列仍然存在。但是如果你用sgd或者minibatch,那么样本输入的先后对结果会产生影响,但不是来自lstm,而是由于通常先输入的样本会获得较大的梯度,对模型产生更大的影响。不打乱顺序会导致局部的时序关系影响力更大,打乱顺序后训练,效果会更好
二维图像拉成一维向量只能说是一个序列,但是序列中前一个数据与后一个数据有没有时序相关,不能保证,要看具体二维图像怎么抽成向量的,图像的子图像有没有时序相关性。
至于二维图像完全可以拉成一个一维的序列数据啊,比如一个m*n的图像,我们可以处理成m个n维向量,m就是这个序列的长度,每个n维向量是这个序列的元素。图像的信息很好的被继承。这个你可以用mnist数据集做个实验,效果很不错。
文章出处登录后可见!