



截止2022年7月25日,DINO是目标检测的SOTA。
本人根据源码的复现感受和DINO论文的精读心得,撰写本篇博客,希望对你有所帮助。
目录
一、摘要
我们推出DINO (DETR with Improved deNoising anchOr boxes),一款最先进的端到端对象检测器。DINO通过使用:
- 对比的去噪训练方式;
- 用于锚点初始化的混合查询选择方法;
- 用于框预测的向前两次方案;
- 本文章会对以上三种创新方法逐点击破。
在性能和效率上改进了以前的DETR模型。使用ResNet – 50主干和多尺度特征,DINO在12个epoch获得49.4 AP,在24个epoch获得51.3 AP( 收敛极快!),与之前的DN-DETR模型( 最好的DETR-like模型 )相比,分别获得+ 6.0 AP和+ 2.7 AP的显著提升。DINO在模型规模和数据规模上均表现良好。在没有铃铛和口哨的情况下,经过在带有SwinL主干的Objects365数据集上的预训练,DINO在COCO val2017 ( 63.2AP )和test – dev ( 63.3AP )上都获得了最好的结果。与排行榜上的其他模型相比,DINO显著减少了模型大小和预训练数据大小,同时取得了更好的效果。
Keywords: Object Detection; Detection Transformer; End-to-End Detector
论文链接:https://arxiv.org/abs/2203.03605
源码链接:https://github.com/IDEACVR/DINO
补充: 名词 + ‘-like’ >>> 形容词,意思是“似…的,像…样的,喜欢…的”
二、结论
在本文中,我们提出了一种具有对比去噪训练、混合查询选择和两次前瞻的强端到端Transformer检测器DINO,显著提高了训练效率和最终检测性能。因此,在COCO val2017上,在使用多尺度特征的12阶和36阶场景中,DINO都优于之前所有基于ResNet – 50的模型。受改进的启发,我们进一步探索在更大的数据集上训练具有更强骨干的DINO,并在COCO 2017 test-dev上实现了最新技术63.3 AP。这个结果建立了类似DETR的模型作为一个主流的检测框架,不仅因为它新颖的端到端检测优化,而且因为它优越的性能。
作者在开篇处便炫耀了SOTA结果,如图1 所示:
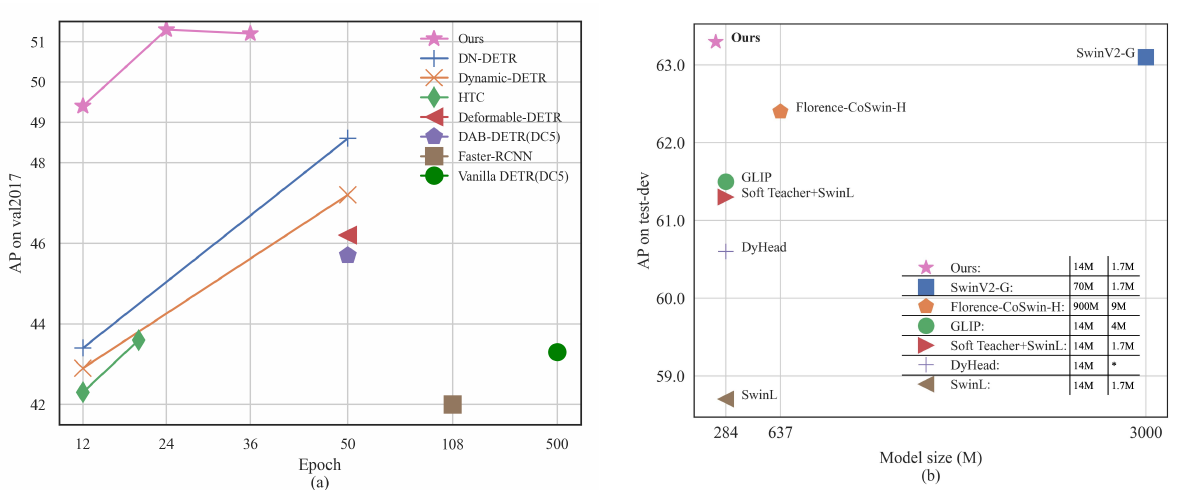
图1 DINO在COCO数据集上与其他检测模型的比较
- 图1 (a) 与ResNet – 50主干w . r . t .训练历元模型的比较。其中,DC5标记的模型使用的是扩展的更大分辨率的特征图,其他模型使用多尺度特征。
- 图1 (b)预训练数据规模和模型规模与SOTA模型的比较。SOTA型号来自COCO test-dev排行榜。在图例中,我们列出了骨干预训练数据大小(第一个数字)和检测预训练数据大小(第二个数字)。
总结:DINO模型经过很少的epoch便达到了其他模型无法企及的精度,并且预训练数据规模和模型规模也比其他的模型精简。
三、解析DINO模型
(1)概述DINO模型借鉴了前人的那些工作
正如在Conditional DETR [ 25 ]和DAB – DETR [ 21 ]中所研究的那样,DETR [ 3 ]中的查询由两部分组成:位置部分和内容部分,在本文中称为位置查询和内容查询。DAB – DETR [ 21 ]将DETR中的每个位置查询显式地表示为一个4D锚点框( x , y , w , h),其中x和y是框的中心坐标,w和h对应其宽度和高度。这种显式的锚框格式使得在解码器中动态地逐层细化锚框变得很容易。
怎样解决DETR收敛慢的问题?
DN-DETR [ 17 ]引入一种去噪( DN )训练方法来加速DETR – like模型的训练收敛。这表明DETR中的慢收敛问题是由二分匹配的不稳定性引起的。为了缓解这个问题,DN – DETR建议在Transformer解码器中添加带噪的 ground-truth (GT) 标签和框,并训练模型来重建地面实况。添加的噪声 ![]()
![]()


注释:λ :虽然 DN – DETR 模型使用 λ1 和 λ2 表示中心偏移和 box 缩放的噪声尺度,但设置了 λ1 = λ2。为了简单起见,本文用 λ 代替λ1和λ2。
Deformable DETR [ 41 ]是另一个早期加快DETR收敛速度的工作。为了计算可变形注意力,它引入了参考点的概念,使得可变形注意力能够关注到参考点周围的一个小的关键采样点集。参考点的概念使得开发几种技术来进一步提高DETR性能成为可能。第一种技术是“two-stage”,它直接从编码器中选择特征和参考框作为解码器的输入。第二种技术是迭代绑定框精化,在两个解码器层之间进行仔细的梯度分离设计。在我们的论文中,我们把“two-stage”和梯度分离技术分别称为 “query selection” 和 "look forward once"。
在DAB – DETR和DN – DETR之后,DINO将位置查询表示为动态锚框,并使用额外的DN损失进行训练。值得注意的是,DN – DETR还采用了Deformable DETR的一些技术来实现更好的性能,包括它的可变形注意力机制和层参数更新中的 "向前看一次" 实现。DINO进一步采用了Deformable DETR中的查询选择思想来更好地初始化位置查询。基于这个强大的基线,DINO引入了三种新方法来进一步提高检测性能,这将在Sec中描述。3.3,Sec。3 . 4和Sec .分别为3.5。
(2)概述DINO模型
如图2 所示,我们的改进主要体现在Transformer编码器和解码器上。最后一层中的 top-K 编码器特性被选中来初始化Transformer解码器的位置查询( positional queries ),而内容查询( content queries )则作为可学习的参数保留。我们的解码器还包含一个具有正负样本的对比去噪( Contrastive DeNoising: CDN )部分。
关键词解释:
Flatten:平铺
Matching:匹配
Pos Neg:正负样本
Init Anchors:初始化锚框
CDN:Contrastive DeNoising
Position Embeddings:位置嵌入
Multi-Scale Feature:多尺度特征
Encodor Layers × N:N个编码层的编码器
Decodor Layers × N:N个解码层的解码器
GT + Noise:带有噪声的 Ground Truth标签框
Learning Content Queries:可学习的内容查询
Transformer 中的 K、V、Q:Key、Value、Query
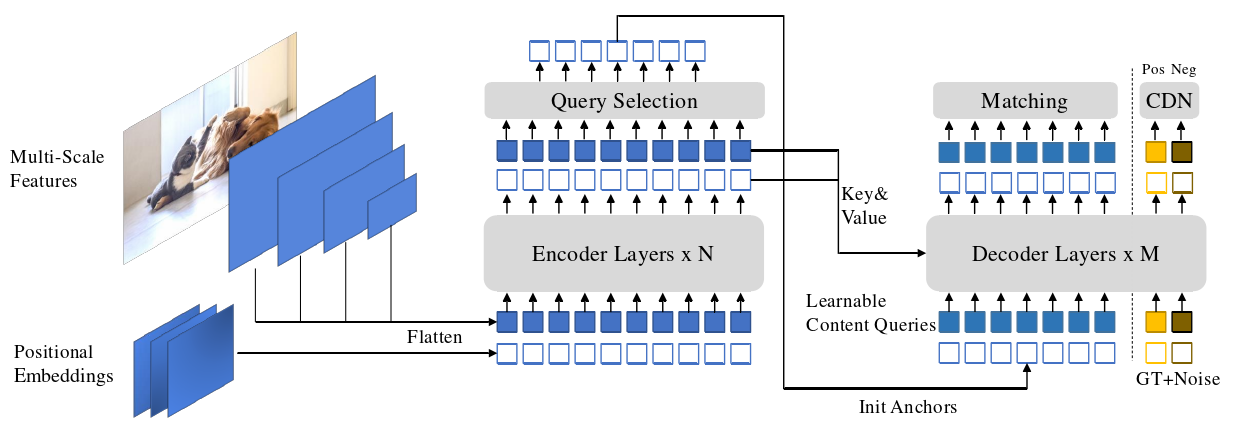

图2 DINO模型的框架
作为一个类似DETR的模型,DINO是一个端到端的架构,包含一个骨干、一个多层Transformer 编码器、一个多层Transformer解码器和多个预测头。整体 pipeline 如图2 所示。
DINO模型的传播过程,以及部分模块的改进:
- 给定一幅图像,我们用ResNet或Swin Transformer等主干提取多尺度特征。
- 然后用相应的位置嵌入输入到 Transformer 编码器中,进行特征增强。
- 在使用编码器层进行特征增强之后,我们提出了一种新的混合查询选择策略( mixed query selection strategy )来初始化锚点作为解码器的位置查询。注意,这种策略并不初始化内容查询,而是让它们具有可学习性。
- 利用初始化的 anchors 和可学习的内容查询,我们使用可变形注意力[ 41 ]来组合编码器输出的特征,并逐层更新查询。
- 最终的输出由精炼的锚框和精炼的内容特征预测的分类结果形成。
- 与DN – DETR一样,我们有一个额外的DN分支来进行去噪训练。除了标准的DN方法,我们提出了一种新的对比去噪训练方法( contrastive denoising training approach ),这种训练方法通过考虑硬负样本实现。
- 为了充分利用后面层的精化盒子信息来帮助优化其相邻的早期层的参数,提出了一种新的向前两次的方法( look forward twice method )来传递相邻层之间的梯度。
四、创新方法
(1)什么是 Contrastive DeNoising Training ?
DN – DETR在稳定训练和加速收敛方面非常有效。在DN查询的帮助下,它学习基于附近有GT框的锚进行预测。然而,它缺乏对附近没有对象的锚预测" no object "的能力。为了解决这个问题,我们提出了一种对比去噪( Contrastive DeNoising:CDN )方法来拒绝无用的锚。
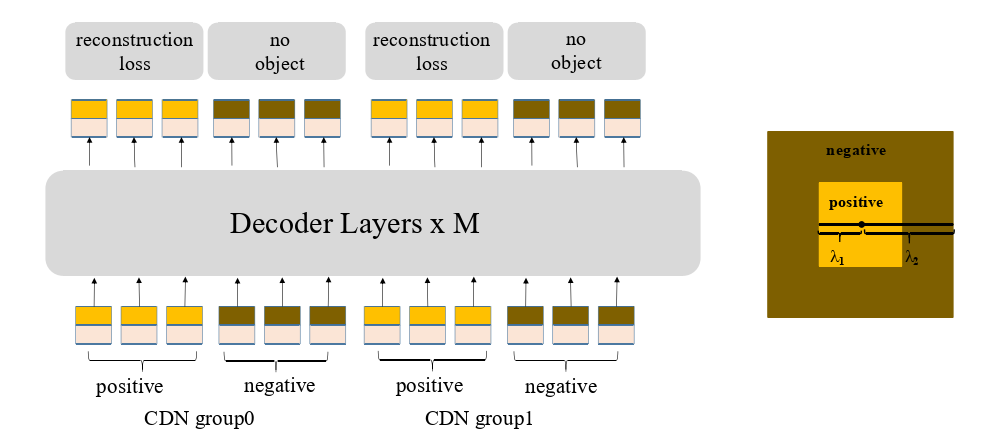

图3 CDN组的结构和正反例的演示
如上图所示,虽然正例和反例都是4D锚点,可以表示为4D空间中的点,但为了简单起见,我们在同心方格上将它们表示为2D空间中的点。假设正方形中心是一个GT盒子,则:
- 内方形内的点被视为正例。
- 内方形和外方形之间的点被视为负例。
a) CDN 实现:DN – DETR有一个超参数 λ 来控制噪声尺度。生成的噪声不大于 λ,因为DN – DETR希望模型从中等噪声的查询中重构出真实数据( GT )。在我们的方法中,我们有两个超参数 λ1 和 λ2,其中 λ1 < λ2 。如图3 中的同心方框所示,我们生成两种类型的CDN查询:正查询和负查询。内部正方形内的正查询具有小于 λ1 的噪声规模,预计将重构正查询对应的背景真值框。内部和外部方块之间的负查询具有大于 λ1 和小于 λ2 的噪声尺度,负查询被期待预言 'no object'。我们通常采用较小的 λ2,因为更接近GT盒的硬负样本更有助于提高性能 。(注意

如图3 所示,每个CDN组都有一组正查询和负查询。如果一幅图像有n个GT框,一个CDN组将有2 × n个查询,每个GT框产生一个正查询和一个负查询。与DN – DETR类似,我们也使用多个CDN组来提高我们方法的有效性。
b) 损失函数的选取:
- BOX 回归的重构损失( reconstruction loss )为
- 用于分类的焦点损失《Focal loss for dense object detection》。
- 将负样本归类为背景的损失也是Focal loss。
- 注:Focal loss 是由何凯明提出的解决样本不均衡问题的损失函数 。

c) 分析CDN方法为什么有效:因为它可以抑制混淆,并选择高质量的锚(查询)来预测边界框。当多个锚点靠近一个物体时,会产生混淆。在这种情况下,模型很难决定选择哪个锚。这种混乱可能导致两个问题。
- 第一个问题是重复的预测。虽然DETR – like模型可以借助基于集合的损失和自注意力来抑制重复框《DETR:End-to-end object detection with transformers》,但是这种能力是有限的。如图8 左图所示,当用DN查询替换我们的CDN查询时,箭头所指的男孩有3个重复预测。通过CDN查询,我们的模型可以区分锚点之间的细微差别,避免重复预测,如图8右图所示。
- 第二个问题是,可能会选择离 GT box 更远的不需要的锚。尽管去噪训练改进了模型选择邻近锚点的能力,但CDN通过教导模型拒绝更远的锚点,进一步提升了这种能力。


图8 左图是使用 DN 查询训练的模型的检测结果,右图是 CDN 的结果。在左图像中,箭头指向的男孩有3个重复的边界框。为了清晰起见,我们只展示了类 "person" 的 box。
d) 验证CDN的有效性:为了证明CDN的有效性,我们定义了平均Top – K距离( Average Top-K Distance,ATD ( k ) ),并在匹配部分使用它来评估锚点离目标GT框的距离。与DETR一样,每个锚对应一个预测,该预测可能与一个GT框或背景匹配。在这里我们只考虑那些与GT box匹配。假设在一个验证集中有N个GT绑定框( b0,b2,..,bN-1 ),其中 ![]()
![]()




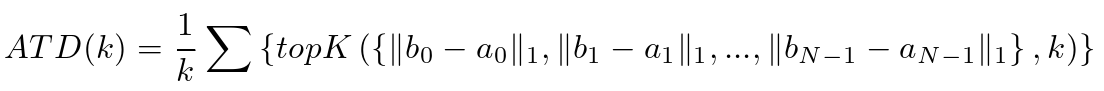

其中![]()
![]()
![]()



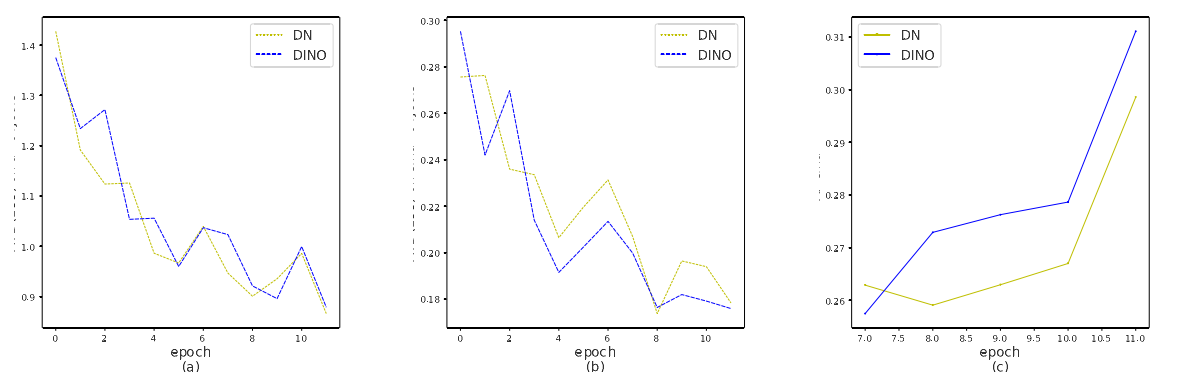

图4 ( a )及( b ):分别在所有物体及小型物体上 ATD( 100 );( c ):小物体上的AP。
(2)什么是 Mixed Query Selection ?
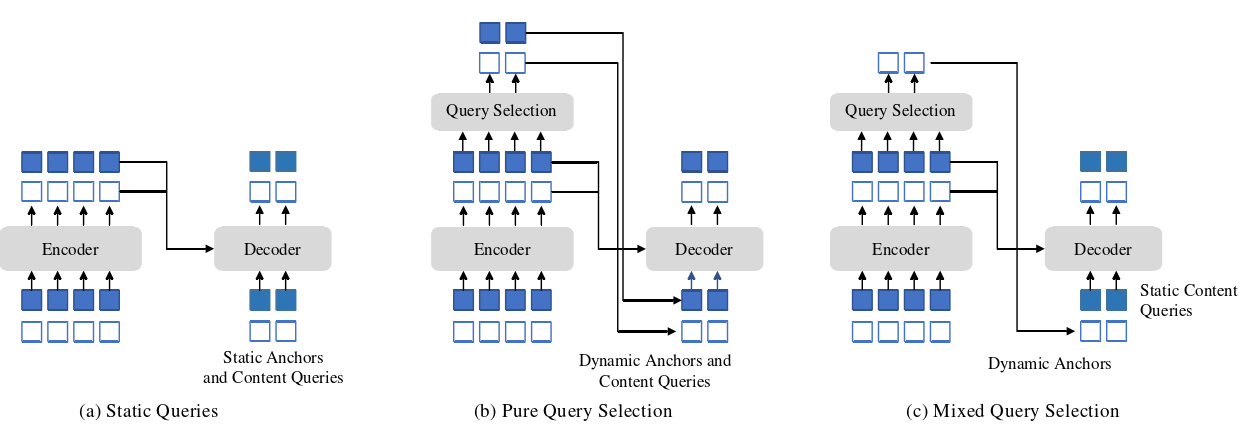
图5 三种不同查询初始化方法的比较(注意图中的英文名词)
术语 "static" 是指在推理中,对于不同的图像,它们将保持相同。对于这些静态( static )查询,一种常见的实现方式是使其具有可学习性。
Static Queries:在DETR 和DN – DETR 中,解码器查询是静态嵌入,不需要从单个图像中提取任何编码器特征,如图5 ( a )所示。他们直接从训练数据中学习 anchors (在DN – DETR和DAB – DETR中)或位置查询( in DETR ),并将所有内容查询设置为0向量。
Pure Query Selection:Deformable DETR 同时学习位置查询和内容查询,是静态查询初始化的另一种实现。为了进一步提高性能,Deformable DETR 提出了一个查询选择变体( "两阶段" ),它从最后一个编码器层选择前 K 个编码器特征作为先验来增强解码器查询。如图5 ( b )所示,位置和内容查询都是由所选特征的线性变换生成的。此外,这些选择的特征被馈送到一个辅助检测头以得到预测框,这些预测框用于初始化参考框。类似地,Efficient DETR 也是根据每个编码器特征的客观(类)评分选择前K个特征。
Mixed Query Selection:在我们的模型中,查询的动态4D锚框格式使其与解码器位置查询密切相关,可以通过查询选择来改进。我们遵循上述实践并提出了一种混合查询选择方法。如图5 ( c )所示,我们只使用与所选top – K特性相关联的位置信息初始化锚框,但与前面一样保持内容查询是静态的。请注意,Deformable DETR利用top – K特性不仅增强了位置查询,还增强了内容查询。由于选取的特征是初步的内容特征,没有进一步细化,可能会对解码器产生歧义和误导。例如,一个选定的特征可能包含多个对象或者只是一个对象的一部分。相比之下,我们的混合查询选择方法只增强了具有top – K选择特征的位置查询,并保持了内容查询的可学习性。这有助于模型利用更好的位置信息从编码器中汇集更全面的内容特征。
(3)什么是 Look Forward Twice ?
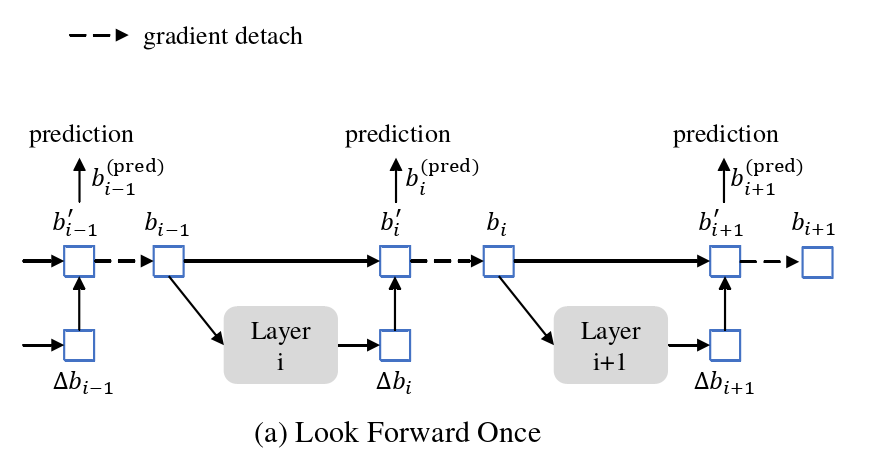

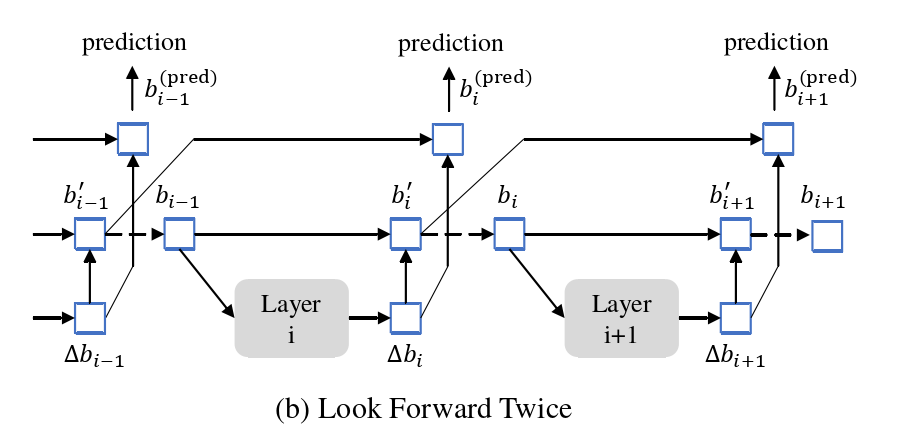

图6 Deformable DETR 中 box update 与本文方法的比较
Look Forward Once:我们在这一部分提出了一种新的 box 预测方法。Deformable DETR 中的 iterative box refinement 可以阻止梯度反向传播来稳定训练。我们将方法命名为向前一次( Look Forward Once ),因为第 i 层的参数是仅仅根据 box 的辅助损失
Look Forward Twice:然而,我们猜想,来自后一层的改进的 box 信息可能更有助于修正其相邻的早期层的盒子预测。因此,我们提出了另一种叫做两次向前看( Look Forward Twice )的方法来执行box更新,其中第 i 层的参数受到第 i 层和( i + 1)层的损失的影响,如图6 ( b )所示。对于每个预测的偏移量 ![]()
![]()



Look Forward Twice 的具体实现过程如下:
预测框![]()


向前一次方案只优化后者,因为梯度信息从第 i 层分离到第( i-1 )层。相反,我们同时改进了初始盒子 ![]()
![]()

更具体地说,给定第 i 层的一个输入框 ![]()

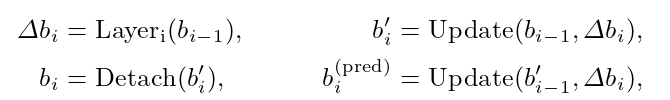

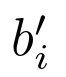
- Gradient Detach:
- 术语Update(·,·)是一个函数:通过预测的框偏移量

我们采用与 Deformable DETR 中相同的 box update 方法:Deformable DETR 在模型中使用了 box 的标准化形式,因此 box 的每个值都是0到1之间的浮点数。给定两个 box,在逆sigmoid之后对它们求和,然后通过sigmoid变换求和。
五、实验方面
(1)数据集和网络骨干
数据集:我们在COCO 2017目标检测数据集[ 20 ]上进行评估,该数据集分为train2017和val2017 (也称为minival )。
网络骨干:我们使用两种不同的主干报告结果:
- 在 ImageNet – 1k 上预训练的ResNet – 50。
《Deep residual learningfor image recognition》 - 在 ImageNet – 22k 上预训练的 SwinL。
《Swin transformer:Hierarchical vision transformer using shifted windows》
使用ResNet – 50的DINO在没有额外数据的情况下在train2017上训练,而使用SwinL的DINO首先在Object365《Objects365: A large-scale,high-quality dataset for objectdetection》上预训练,然后在train2017上微调。我们报告了val2017在不同IoU阈值和对象尺度下的标准平均精度( AP )结果。我们还报告了DINO与SwinL的测试结果。
(2)实现细节
DINO由一个主干、一个Transformer编码器、一个Transformer解码器和多个预测头组成。在附录D中,我们提供了更多的实现细节,包括在我们的模型中使用的所有超参数和工程技术,供那些希望再现我们的结果的人使用。我们将在盲审之后发布代码(已经发布,本人已经跑通,稍后更新)。
附录D:一些训练优化技巧、超参数的选取、和使用的GPU信息,阅读源码时,可以参考附录;部分超参数如表8 所示:
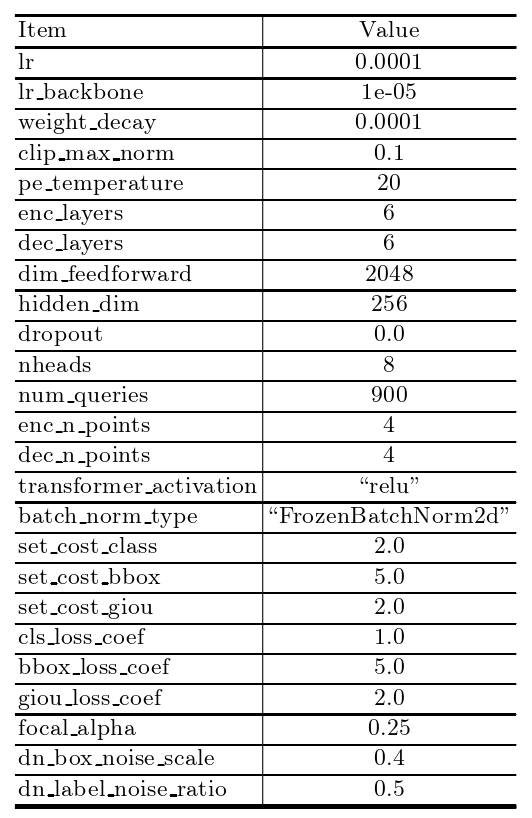

表8 DINO模型使用的超参数
六、熠熠生辉的数据可视化
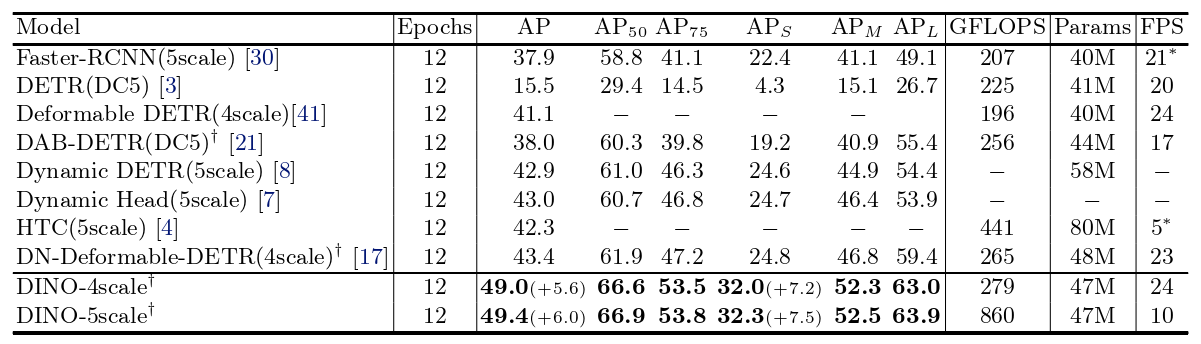

表1 在COCO val2017上使用ResNet50网络主干的DINO和其他检测模型的结果使用12 epoch(所谓的1 ×设置)进行训练。对于没有多尺度特征的模型,我们测试它们的GFLOPS和FPS,以获得最佳模型ResNet-50-DC5。
- DINO 使用900个查询。
- 标识
- 其他 DETR – like 模型除 DETR ( 100个查询 )使用300个查询外。
- *表示使用 mmdetection 框架进行测试。
- 4scale and 5scale:多尺度特征图(multi-scale features)。

补充:
GFLOPS:Giga Floating-point Operations Per Second, 即每秒10亿次的浮点运算数,常作为GPU性能参数但不一定代表GPU的实际表现。它是一个衡量计算机计算能力的量,这个量经常使用在那些需要大量浮点运算的科学运算中。
MMDetection 是商汤和港中文大学针对目标检测任务推出的一个开源项目,它基于Pytorch实现了大量的目标检测算法,把数据集构建、模型搭建、训练策略等过程都封装成了一个个模块,通过模块调用的方式,我们能够以很少的代码量实现一个新算法,大大提高了代码复用率。DINO源码用到了mmcv中的config.py文件。
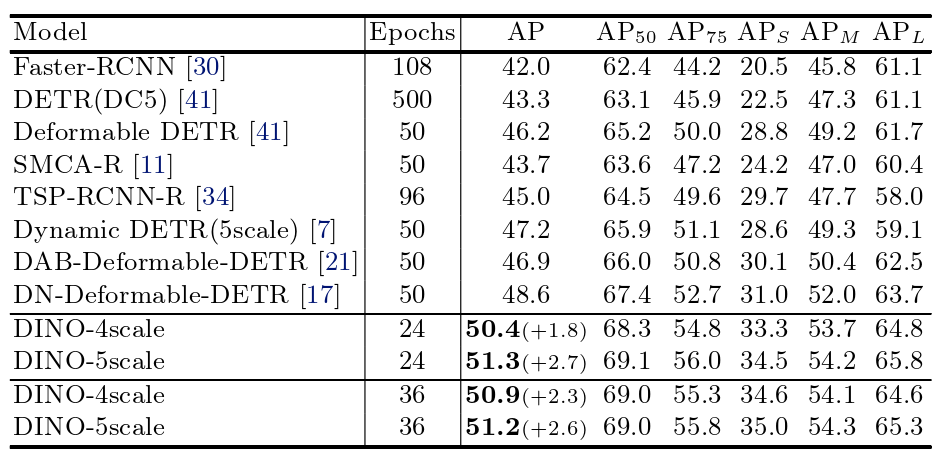

表2 DINO等检测模型在COCO val2017上以ResNet – 50为主干,使用更多epoch训练的结果
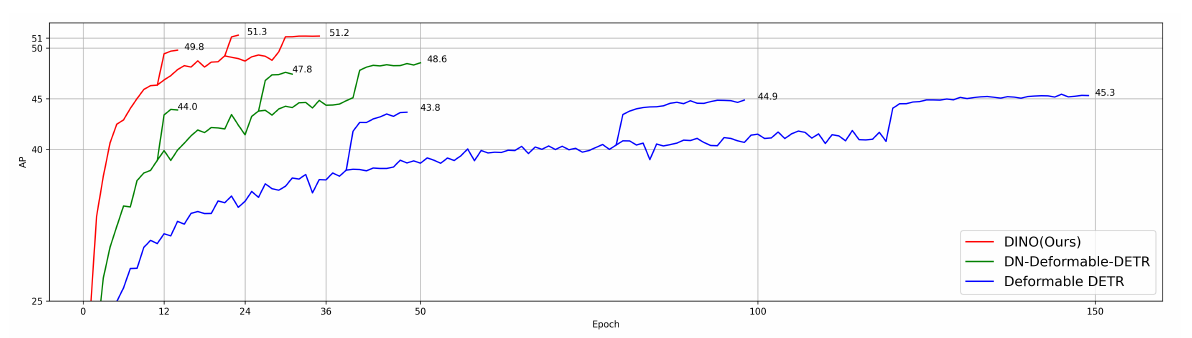

图7 使用多尺度特征在COCO val2017上评估DINO和两个先前最先进的ResNet-50模型的训练收敛曲线。充分体现了DINO在保证提升精度的同时,收敛速度有羚羊的速度提升到了猎豹的速度。本人在DETR上面用一快GPU训练30个小时达到的效果和在DINO上训练三个多小时的效果差不多。
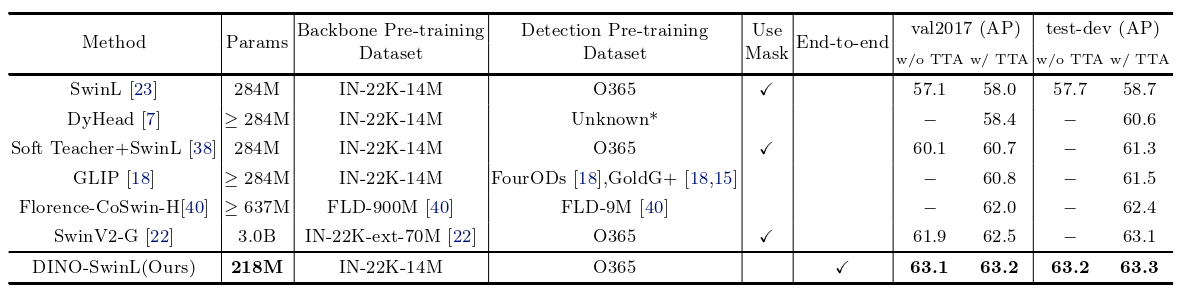

表3 在MS – COCO上,DINO与以往最佳检测模型的比较
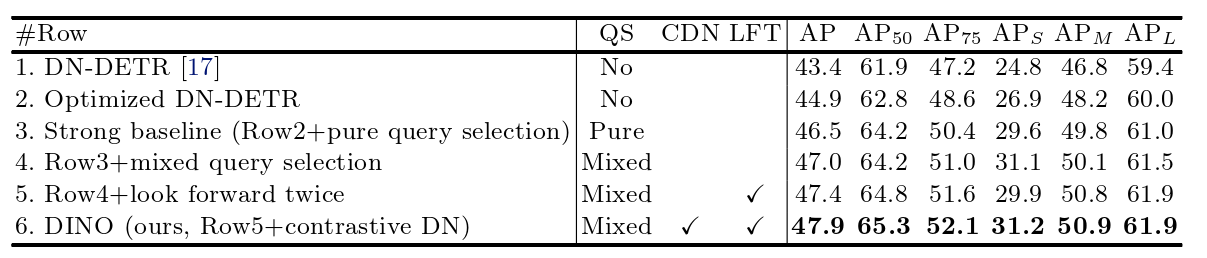

表4 对于提出的创新模块的消融实验结果
>>> 如有疑问,欢迎评论区一起探讨。
计算机视觉论文精度大纲_Flying Bulldog的博客-CSDN博客![]()

文章出处登录后可见!