简介

2020年ECCV最佳论文Neural Radiance Field (NeRF) 将三维场景的隐表示方法推向了新的高度,其本质在于利用神经网络通过多视角2D图像进行3D场景重建,并进行渲染合成新视角的2D图像
视角合成方法通常使用一个中间3D场景表征作为中介来生成高质量的虚拟视角,如何对这个中间3D场景进行表征,分为了“显示表示“和”隐式表示“,然后再对这个中间3D场景进行渲染,生成照片级的视角。
“显示表示”3D场景包括Mesh,Point Cloud,Voxel,Volume等,它能够对场景进行显式建模,但是因为其是离散表示的,导致了不够精细化会造成重叠等伪影,更重要的是,它存储的三维场景表达信息数据量极大,对内存的消耗限制了高分辨率场景的应用。
”隐式表示“3D场景通常用一个函数来描述场景几何,可以理解为将复杂的三维场景表达信息存储在函数的参数中。因为往往是学习一种3D场景的描述函数,因此在表达大分辨率场景的时候它的参数量相对于“显示表示”是较少的,并且”隐式表示“函数是种连续化的表达,对于场景的表达会更为精细。
NeRF做到了利用”隐式表示“实现了照片级的视角合成效果,它选择了Volume作为中间3D场景表征,然后再通过Volume rendering实现了特定视角照片合成效果。可以说NeRF实现了从离散的照片集中学习出了一种隐式的Volume表达,然后在某个特定视角,利用该隐式Volume表达和体渲染得到该视角下的照片。
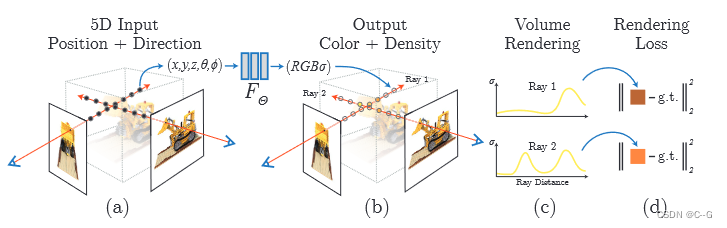
整体流程
数据准备
首先需要准备多张从不同角度拍摄的同场景静态2D图像
还需要各个像素点的位置(x,y,z)和方位视角(θ,φ)作为输入进行重建。为了获得这些数据,NeRF中采用了传统方法COLMAP进行参数估计。通过COLMAP可以得到场景的稀疏重建结果,其输出文件包括相机内参,相机外参和3D点的信息。
然后进一步利用LLFF开源代码中的imgs2poses文件将内外参整合到一个文件poses_boudns.npy中,该文件记录了相机的内参,包括图片分辨率(图片高与宽度)、焦距,共3个维度、外参(包括相机坐标到世界坐标转换的平移矩阵t与旋转矩阵r,其中旋转矩阵为 3×3 的矩阵,共9个维度,平移矩阵为 3×1 的矩阵,3个维度,因此该文件中的数据维度为 N x 17 另有两个维度为光线的始发深度与终止深度,通过COLMAP输出的3D点位置计算得到),其中N为图片样本数。
除了llff数据格式,还有blender、LINEMOD和deepvoxels
数据处理
经过上述数据准备,我们得到图片、相机内外参、旋转矩阵和平移矩阵。
这里使用到计算机图形学的图形变换,将上述参数与2d的图像信息结合,将2d坐标转换为3d坐标
坐标变换
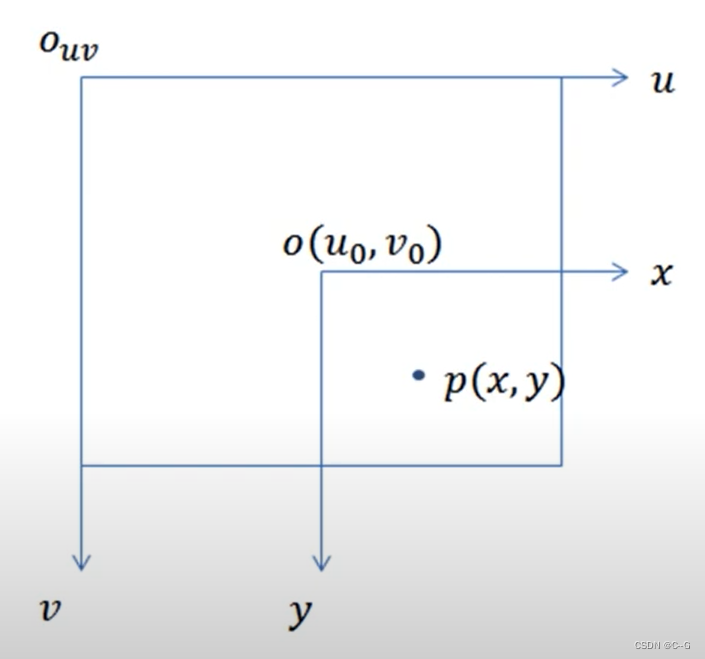
为像素坐标系,
为物理坐标系,首先要将物理坐标系移到像素坐标系(
分别为物理坐标系在像素坐标系下的坐标值,我们一般可以用像素图像宽高一半表示其值,即可
)
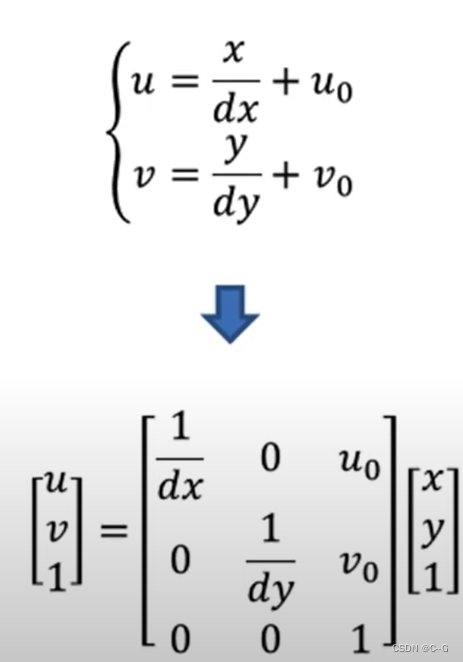
然后我们要进行摄像机变换,将相机坐标拓展到世界坐标系
原理介绍
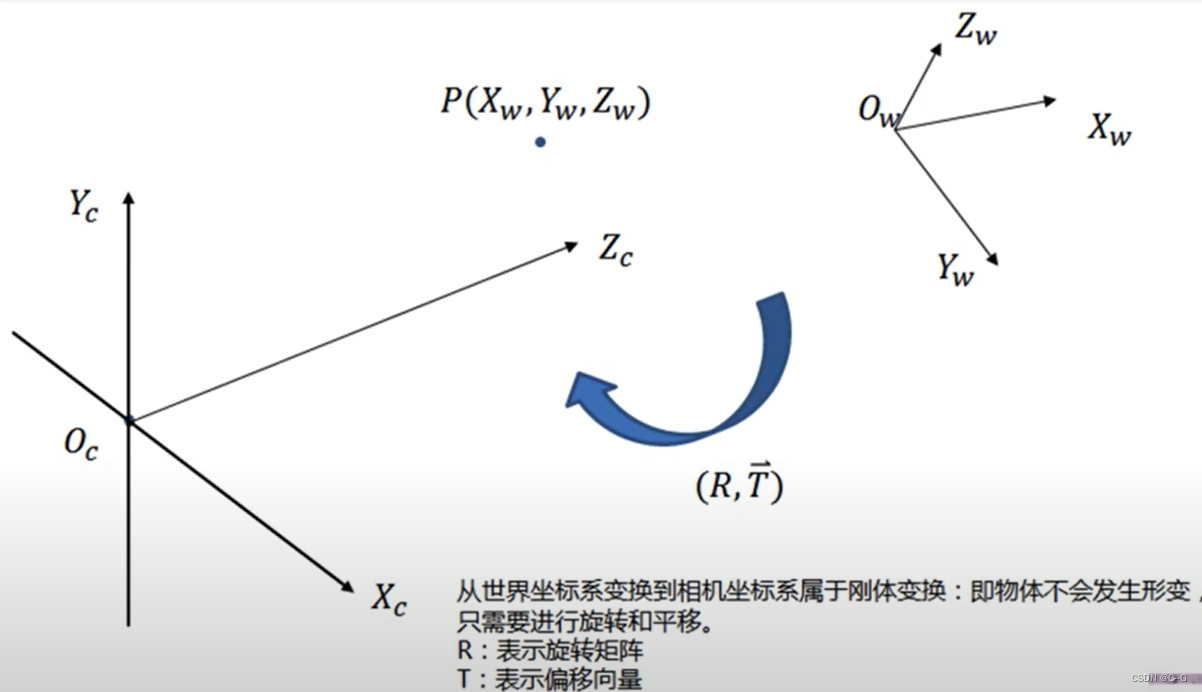
通过平移矩阵,将相机坐标系原点与世界坐标系进行对齐
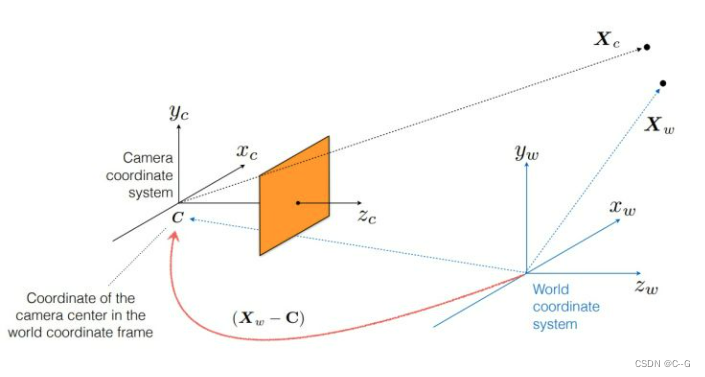
通过旋转矩阵对齐坐标轴的朝向
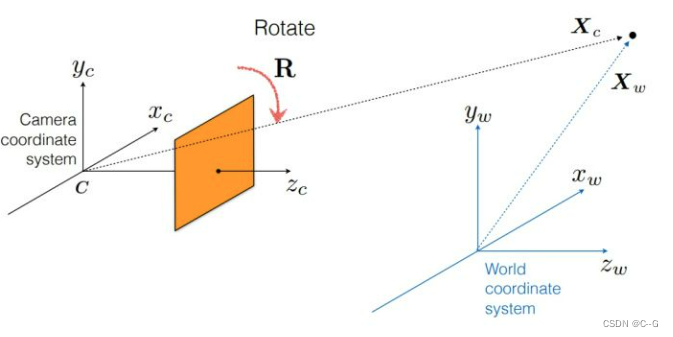
结合上述过程,世界物理坐标转换为相机坐标总公式为:

将所有矩阵总结后得到像素坐标到新建物理坐标的转换矩阵M如下
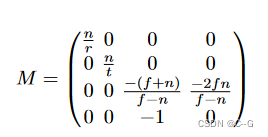
其中 n, f 是近剪切平面和远剪切平面,r 和 t 是近剪切平面上场景的右边界和上边界。(注意,这是在约定中,摄像机是面向 -z方向的。)
输入像素3d坐标进行转换

这样一来我们便通过相机的内外参数成功地将像素坐标转换为了统一的世界坐标下的光线始发点与方向向量,即将 (X,Y,Z)与 (θ,φ) 编码成了光线的方向作为MLP的输入,所以从形式上来讲MLP的输入并不是真正的点的三维坐标(X,Y,Z),而是由像素坐标经过相机外参变换得到的光线始发点与方向向量以及不同的深度值构成的,而方位的输入也并不是 (θ,φ),而是经过标准化的光线方向。不过从本质上来讲,在一个视角下,给定光线始发点o ,特定的光线方向 d 以及不同的深度值 t ,通过文章中的公式 ray = o + td 便可以得到该光线上所有的3D点的表示 ,然后扩展到不同的光线方向便可以得到相机视锥中所有3D点的表示,再进一步扩展到不同的相机拍摄机位,理论上便可以得到该场景所有3D点的表示
NeRF的代码中其实还存在另外一个坐标系统:Normalized device coordinates(ndc)坐标系,一般对于一些forward facing的场景(景深很大)会选择进一步把世界坐标转换为ndc坐标,因为ndc坐标系中会将光线的边界限制在0-1之间以减少在景深比较大的背景下产生的负面影响。但是需要注意ndc坐标系不能和spherify pose(球状多视图采样时)同时使用,这点nerf-pytorch中并没有设置两者的互斥关系,而nerf-pl则明确设置了。

将上述project重写成下列形式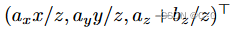
新原点 o′ 和方向 d′ 的分量必须满足
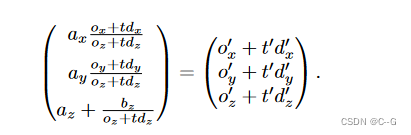
为了消除自由度,我们决定 t′ = 0 和 t = 0 应映射到同一点,得到 NDC 空间原点 o′
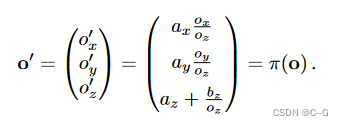
这正是原始射线原点的投影 。通过将其代入方程 10 以代替任意 t,我们可以确定 t′ 和 d′ 的值
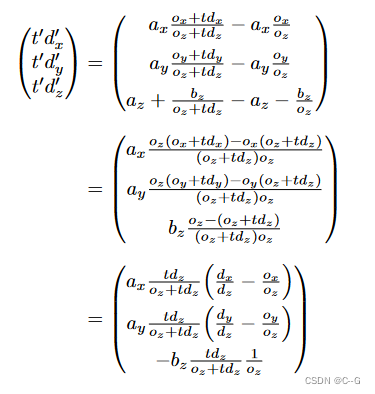
其中 W 和 H 是图像的宽度和高度(以像素为单位), 是相机的焦距。在我们实际的正向捕获中,我们假设远场景边界是无穷大的(这使我们的成本非常低,因为NDC使用z维来表示反深度,即视差)。在此限制中,z 常量简化为
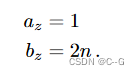
位置编码

首先要介绍一下关于“图像”的一个概念:high-frequency (高频)和 low-frequency(低频)。标号1所处的地方是白色类似于桌布的东西,标号2所处的地方是核桃。在前者的小区域内,移动一点位置,颜色并不会变化很大,但是后者就会。前者的区域对应 low-frequency,后者的区域对应 high-frequency。

深度神经网络偏向于学习图像 low-frequency 的部分,而针对 high-frequency 的部分难以学习,因此需要将输入数据映射到高维空间
论文中使用的公式如下,L的值决定了神经网络能学习到的最高频率的大小
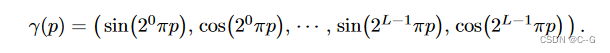
L 的值太小,则会导致 high-frequency 区域难以重现的问题,L 的值太大,则会导致重现出来的图像有很多噪声的情况
NeRF 的作者根据实验结果,发现关于三维点坐标 x 和 单位方向向量 d ,L分别取 10 与 4 的情况,实验效果比较好
三维重建
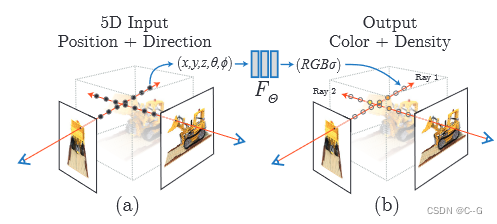
三维重建部分本质上是一个2D到3D的建模过程,利用图片像素点转换到3D点后的位置(X,Y,Z)及方位视角(θ,φ)作为输入,通过多层感知机(MLP)建模该点对应的颜色color(c)及体密度volume density(σ),形成了3D场景的”隐式表示“。
三维重建网络的任务就是要预测从像素点出发的射线上不同深度的采样点的体密度与颜色
论文中网络图像如下图所示
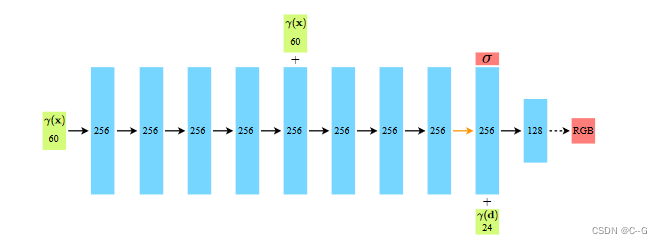
经过数据处理,我们得到了射线 o+dt,将不同的t带入公式即可得到射线上不同采样点的3d坐标(X,Y,Z)和方位视角(θ,φ)
3d坐标(X,Y,Z)经过位置编码后经过5个256维的全连接层后将256维特征向量与60维(X,Y,Z)拼接后再经过3个256维全连接层得到256维特征向量,此时,将256维特征向量经过256维全连接层输出得到体密度,与此同时,256维特征向量拼接24维度方位视角(θ,φ),分别经过283维全连接层、256维全连接层和128维全连接层得到3维特征向量RGB颜色值
总结:体密度由位置坐标预测得到,RGB颜色由位置坐标和方位视角得到
光线采样处理
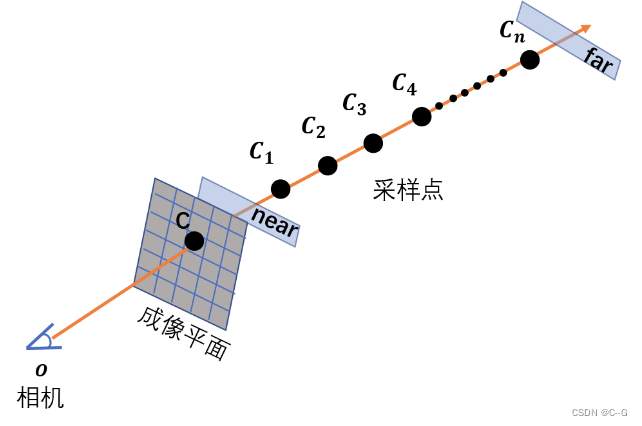
由相机 o 和某个成像点 C 两点确定的射线。以相机为原点o ,射线方向为坐标轴方向建立坐标轴。则坐标轴上任意一点坐标可表示为 o + t d 。其中 t 为该点到原点距离,d为单位方向向量。near,far 实际上是两个垂直于射线,平行于成像平面的平面。在这里,也用near、far表示那两个平面与射线的交点。在射线上采样的范围是从 near 点到 far 点。理论上,如果对于相关的 scene 我们一无所知,near 点应该被设在在原点(相机处),far 点则在 无穷远。但是实际上如果我们要处理的是 synthetic dataset,则会根据已知的物体在 scene 中的范围调整 near 和 far。因为这样可以减少计算量。
首先由于体素渲染需要沿着光线进行积分,而积分在计算机中是以离散的乘积和进行计算的,那么这里就涉及到在光线上进行点的采样。NeRF在光线的点采样过程中的进行了一些设计。首先为了避免大量的点采样导致的计算量的激增,NeRF设计了coarse to fine的采样策略。在coarse采样阶段,采用了带有扰动的均匀采样方法
先在光线的边界之间进行深度空间的均匀采样,然后在规定了下界与上界的范围内将采样点进行扰动,最终coarse采样阶段在每条光线上采样了64个样本点。然后基于coarse采样得到的结果进一步指导fine的点采样,即在对最终颜色贡献更大(权重更大)的点附近进行更加密集的点采样
粗采样中,我们采样64个,细采样中我们根据粗采样结果进行细粒度采样128
在 NeRF中,一共有训练两个 MLP,分别是 Model 和 Model
,它们的模型结构一样,只是参数不同。它们分别对应 Hierarchical Volume Sampling 两次抽样的模型
-
第一次抽样是先将在相机射线上,由 near 和 far 构成的范围 n 等分,然后在每个小区间内均匀采样得到一个采样点,最终一共 n 个采样点。将得到的采样点的位置信息和其他信息输入 MLP,MLP 输出每个采样点的 Volume Density
-
第二次采样是基于第一次采样点的结果。乘上
得到 weight i 为
较大的区域多采样,
首先对 归一化
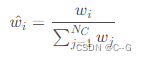
渲染
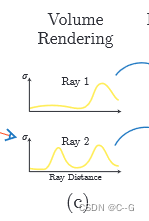
根据三维重建得到射线上不同采样点的体密度与颜色后,我们就可以将其带入到体渲染方程,生成像素点颜色
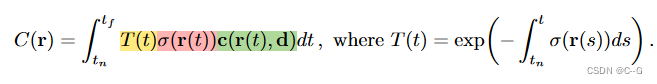
其中函数T(t)表示射线从 到 t 沿射线累积透射率,即射线从
到 t 不碰到任何粒子的概率
从上述公式中,我们不难看出要对射线上的体密度、颜色等进行积分,那就得使用到离散求积法对这个连续积分进行数值估计,这会极大地限制表示的分辨率,因此可通过分层抽样方法,这样使用离散的样本估计积分,但是能够较好地表示一个连续的场景(类似重要性采样,对整个积分域进行非均匀离散化,较能还原原本的积分分布
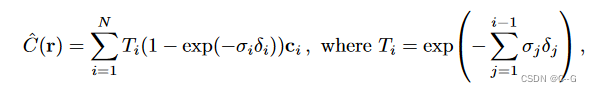
-
σ:(体密度)由三维重建得出
-
δ (两个采样点之间的距离定义)
每个采样点,其到相机 0 的距离为
由
得到,
由
得到,如此类推
我们可以定义两个list
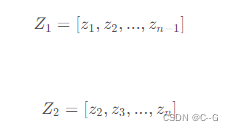
- α (透明度)
这里,我们定义a = 1 – exp(-σδ)

不同相机射线的采样点不同,对应的 不同,那么同一个三维点,从不同方向去看颜色可能不同
当 σ = 0 时,α = 0 ,这表示当 体密度 为 0 时,透明度为 0,完全透明,从相机发出的光继续向后传播,当前点对成像点的颜色无贡献,也不影响后面点对成像点颜色的贡献
当 σ → + ∞ , α → 1 ,这表示此时 透明度为1,完全不透明,使得从相机发出的光被完全阻挡在当前点,使得当前点后面的点对成像点 C 的颜色无贡献
由上面的公式可以得出离散求积公式可以写成下列形式
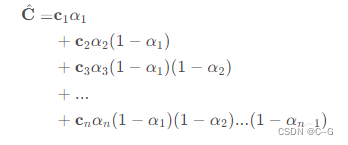
损失
在训练的时候,利用渲染部分得到的2D图像,通过与原始图片做L2损失函数(L2 Loss)进行网络优化
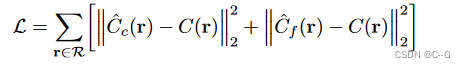
代码分析
源码地址:https://github.com/yenchenlin/nerf-pytorch
超参数
run_nerf.py config_parser()
- 基本参数
# 生成config.txt文件
parser.add_argument('--config', is_config_file=True,
help='config file path')
# 指定实验名称
parser.add_argument("--expname", type=str,
help='experiment name')
# 指定输出目录
parser.add_argument("--basedir", type=str, default='./logs/',
help='where to store ckpts and logs')
# 指定数据目录
parser.add_argument("--datadir", type=str, default='./data/llff/fern',
help='input data directory')
- 训练相关
# training options
# 设置网络的深度,即网络的层数
parser.add_argument("--netdepth", type=int, default=8,
help='layers in network')
# 设置网络的宽度,即每一层神经元的个数
parser.add_argument("--netwidth", type=int, default=256,
help='channels per layer')
parser.add_argument("--netdepth_fine", type=int, default=8,
help='layers in fine network')
parser.add_argument("--netwidth_fine", type=int, default=256,
help='channels per layer in fine network')
# batch size,光束的数量
parser.add_argument("--N_rand", type=int, default=32*32*4,
help='batch size (number of random rays per gradient step)')
# 学习率
parser.add_argument("--lrate", type=float, default=5e-4,
help='learning rate')
# 指数学习率衰减
parser.add_argument("--lrate_decay", type=int, default=250,
help='exponential learning rate decay (in 1000 steps)')
# 并行处理的光线数量,如果溢出则减少
parser.add_argument("--chunk", type=int, default=1024*32,
help='number of rays processed in parallel, decrease if running out of memory')
# 并行发送的点数
parser.add_argument("--netchunk", type=int, default=1024*64,
help='number of pts sent through network in parallel, decrease if running out of memory')
# 一次只能从一张图片中获取随机光线
parser.add_argument("--no_batching", action='store_true',
help='only take random rays from 1 image at a time')
# 不要从保存的模型中加载权重
parser.add_argument("--no_reload", action='store_true',
help='do not reload weights from saved ckpt')
# 为粗网络重新加载特定权重
parser.add_argument("--ft_path", type=str, default=None,
help='specific weights npy file to reload for coarse network')
- 渲染相关
# rendering options
# 每条射线的粗样本数
parser.add_argument("--N_samples", type=int, default=64,
help='number of coarse samples per ray')
# 每条射线附加的细样本数
parser.add_argument("--N_importance", type=int, default=0,
help='number of additional fine samples per ray')
# 抖动
parser.add_argument("--perturb", type=float, default=1.,
help='set to 0. for no jitter, 1. for jitter')
parser.add_argument("--use_viewdirs", action='store_true',
help='use full 5D input instead of 3D')
# 默认位置编码
parser.add_argument("--i_embed", type=int, default=0,
help='set 0 for default positional encoding, -1 for none')
# 多分辨率
parser.add_argument("--multires", type=int, default=10,
help='log2 of max freq for positional encoding (3D location)')
# 2D方向的多分辨率
parser.add_argument("--multires_views", type=int, default=4,
help='log2 of max freq for positional encoding (2D direction)')
# 噪音方差
parser.add_argument("--raw_noise_std", type=float, default=0.,
help='std dev of noise added to regularize sigma_a output, 1e0 recommended')
# 不要优化,重新加载权重和渲染render_poses路径
parser.add_argument("--render_only", action='store_true',
help='do not optimize, reload weights and render out render_poses path')
# 渲染测试集而不是render_poses路径
parser.add_argument("--render_test", action='store_true',
help='render the test set instead of render_poses path')
# 下采样因子以加快渲染速度,设置为 4 或 8 用于快速预览
parser.add_argument("--render_factor", type=int, default=0,
help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')
- 数据准备参数
# training options
parser.add_argument("--precrop_iters", type=int, default=0,
help='number of steps to train on central crops')
parser.add_argument("--precrop_frac", type=float,
default=.5, help='fraction of img taken for central crops')
# dataset options
parser.add_argument("--dataset_type", type=str, default='llff',
help='options: llff / blender / deepvoxels')
# # 将从测试/验证集中加载 1/N 图像,这对于像 deepvoxels 这样的大型数据集很有用
parser.add_argument("--testskip", type=int, default=8,
help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels')
## deepvoxels flags
parser.add_argument("--shape", type=str, default='greek',
help='options : armchair / cube / greek / vase')
## blender flags
parser.add_argument("--white_bkgd", action='store_true',
help='set to render synthetic data on a white bkgd (always use for dvoxels)')
parser.add_argument("--half_res", action='store_true',
help='load blender synthetic data at 400x400 instead of 800x800')
## llff flags
# LLFF下采样因子
parser.add_argument("--factor", type=int, default=8,
help='downsample factor for LLFF images')
parser.add_argument("--no_ndc", action='store_true',
help='do not use normalized device coordinates (set for non-forward facing scenes)')
parser.add_argument("--lindisp", action='store_true',
help='sampling linearly in disparity rather than depth')
parser.add_argument("--spherify", action='store_true',
help='set for spherical 360 scenes')
parser.add_argument("--llffhold", type=int, default=8,
help='will take every 1/N images as LLFF test set, paper uses 8')
# logging/saving options
parser.add_argument("--i_print", type=int, default=100,
help='frequency of console printout and metric loggin')
parser.add_argument("--i_img", type=int, default=500,
help='frequency of tensorboard image logging')
parser.add_argument("--i_weights", type=int, default=10000,
help='frequency of weight ckpt saving')
parser.add_argument("--i_testset", type=int, default=50000,
help='frequency of testset saving')
parser.add_argument("--i_video", type=int, default=50000,
help='frequency of render_poses video saving')
数据处理(blender)
**load_blender.py **
数据加载
def load_blender_data(basedir, half_res=False, testskip=1):
splits = ['train', 'val', 'test']
metas = {}
# 加载相机内外参
for s in splits:
with open(os.path.join(basedir, 'transforms_{}.json'.format(s)), 'r') as fp:
metas[s] = json.load(fp)
all_imgs = []
all_poses = []
counts = [0]
for s in splits:
meta = metas[s]
imgs = []
poses = []
if s=='train' or testskip==0:
skip = 1
else:
skip = testskip
for frame in meta['frames'][::skip]:
fname = os.path.join(basedir, frame['file_path'] + '.png')
imgs.append(imageio.imread(fname))
poses.append(np.array(frame['transform_matrix']))
# 图片
imgs = (np.array(imgs) / 255.).astype(np.float32) # keep all 4 channels (RGBA)
# transform_matrix
poses = np.array(poses).astype(np.float32)
counts.append(counts[-1] + imgs.shape[0])
all_imgs.append(imgs)
all_poses.append(poses)
i_split = [np.arange(counts[i], counts[i+1]) for i in range(3)]
imgs = np.concatenate(all_imgs, 0)
poses = np.concatenate(all_poses, 0)
H, W = imgs[0].shape[:2]
camera_angle_x = float(meta['camera_angle_x'])
focal = .5 * W / np.tan(.5 * camera_angle_x)
render_poses = torch.stack([pose_spherical(angle, -30.0, 4.0) for angle in np.linspace(-180,180,40+1)[:-1]], 0)
if half_res:
H = H//2
W = W//2
focal = focal/2.
imgs_half_res = np.zeros((imgs.shape[0], H, W, 4))
for i, img in enumerate(imgs):
imgs_half_res[i] = cv2.resize(img, (W, H), interpolation=cv2.INTER_AREA)
imgs = imgs_half_res
# imgs = tf.image.resize_area(imgs, [400, 400]).numpy()
return imgs, poses, render_poses, [H, W, focal], i_split
坐标变换
位置编码
run_nerf_helpers.py Embedder 位置编码
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x : x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
if self.kwargs['log_sampling']:
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
模型创建
run_nerf.py create_nerf(args) 创建模型
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
# 创建粗采样模型
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters())
model_fine = None
# 创建精细采样模型(模型结构一致,差别在于输入参数)
if args.N_importance > 0:
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# Create optimizer
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
render_kwargs_train = {
'network_query_fn' : network_query_fn,
'perturb' : args.perturb,
'N_importance' : args.N_importance,
'network_fine' : model_fine,
'N_samples' : args.N_samples,
'network_fn' : model,
'use_viewdirs' : args.use_viewdirs,
'white_bkgd' : args.white_bkgd,
'raw_noise_std' : args.raw_noise_std,
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer
网络结构
NeRF(
(pts_linears): ModuleList(
(0): Linear(in_features=63, out_features=256, bias=True)
(1): Linear(in_features=256, out_features=256, bias=True)
(2): Linear(in_features=256, out_features=256, bias=True)
(3): Linear(in_features=256, out_features=256, bias=True)
(4): Linear(in_features=256, out_features=256, bias=True)
(5): Linear(in_features=319, out_features=256, bias=True)
(6): Linear(in_features=256, out_features=256, bias=True)
(7): Linear(in_features=256, out_features=256, bias=True)
)
(views_linears): ModuleList(
(0): Linear(in_features=283, out_features=128, bias=True)
)
(feature_linear): Linear(in_features=256, out_features=256, bias=True)
(alpha_linear): Linear(in_features=256, out_features=1, bias=True)
(rgb_linear): Linear(in_features=128, out_features=3, bias=True)
)
图像渲染
run_nerf.py raw2outputs
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model. 光线采样点模型预测结果,包含每个采样点的RGB和体密度
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
# 定义透明度计算
raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists)
# 采样点距离
dists = z_vals[...,1:] - z_vals[...,:-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples]
dists = dists * torch.norm(rays_d[...,None,:], dim=-1)
rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3]
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[...,3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
if pytest:
np.random.seed(0)
noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
# 体密度 α
alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
# 像素点颜色权重 a
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
# 渲染结果 C
rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3]
depth_map = torch.sum(weights * z_vals, -1)
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1))
acc_map = torch.sum(weights, -1)
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[...,None])
return rgb_map, disp_map, acc_map, weights, depth_map
光线采样处理
run_nerf.py render_rays
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
network_fn: function. Model for predicting RGB and density at each point
in space.
network_query_fn: function used for passing queries to network_fn.
N_samples: int. Number of different times to sample along each ray.
retraw: bool. If True, include model's raw, unprocessed predictions.
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
N_rays = ray_batch.shape[0]
rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each
viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2])
near, far = bounds[...,0], bounds[...,1] # [-1,1]
# 采样点初始化
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp:
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples])
if perturb > 0.:
# 在规定了下界与上界的范围内将采样点进行扰动
# get intervals between samples
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
z_vals = lower + (upper - lower) * t_rand
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3]
# raw = run_network(pts)
raw = network_query_fn(pts, viewdirs, network_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
if N_importance > 0:
# 精细采样
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
# 根据权重累计分布获取精细采样点
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
raw = network_query_fn(pts, viewdirs, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret
权重累计分布
run_nerf_helpers sample_pdf
根据粗采样结果对权重较大位置加大采样
def sample_pdf(bins, weights, N_samples, det=False, pytest=False):
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
cdf = torch.cat([torch.zeros_like(cdf[...,:1]), cdf], -1) # (batch, len(bins))
# Take uniform samples
if det:
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [N_samples])
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
new_shape = list(cdf.shape[:-1]) + [N_samples]
if det:
u = np.linspace(0., 1., N_samples)
u = np.broadcast_to(u, new_shape)
else:
u = np.random.rand(*new_shape)
u = torch.Tensor(u)
# Invert CDF
u = u.contiguous()
inds = torch.searchsorted(cdf, u, right=True)
below = torch.max(torch.zeros_like(inds-1), inds-1)
above = torch.min((cdf.shape[-1]-1) * torch.ones_like(inds), inds)
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2)
# cdf_g = tf.gather(cdf, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# bins_g = tf.gather(bins, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
denom = (cdf_g[...,1]-cdf_g[...,0])
denom = torch.where(denom<1e-5, torch.ones_like(denom), denom)
t = (u-cdf_g[...,0])/denom
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0])
return samples
文章出处登录后可见!