一、知识蒸馏算法理论讲解
知识蒸馏说真的还是挺重要的,当时看论文的时候,总是会出现老师网络和学生网络,把我说的一脸蒙,所以自己就进行了解了一下,做了一些笔记和大家一起分享!不过大家也可以看同济子豪兄的视频,非常不错。知识蒸馏Pytorch代码实战_哔哩哔哩_bilibili,连接给到大家了。
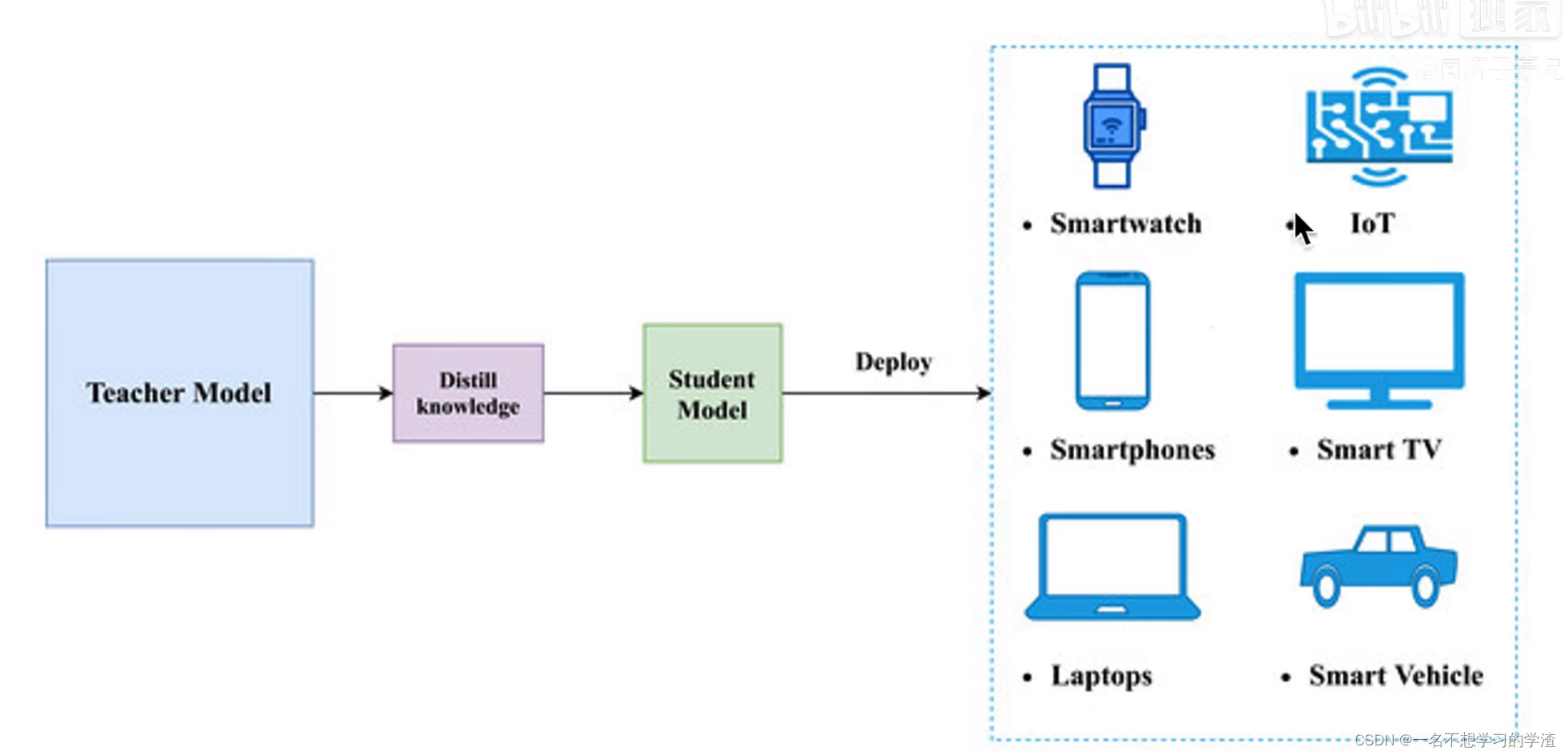
首先我们要知道为什么要进行知识蒸馏,那就是在训练的时候,我们可以去花费一切的资源和算力去训练模型,得到的结果也是非常好的,但是在应用落地的时候,也就是需要在一些嵌入式设备使用的时候,那么这么庞大的模型肯定是不能够在手机端或者其他设备上运行的,或者需要的推理时间非常长,那么这个模型就只能在实验室待着了。
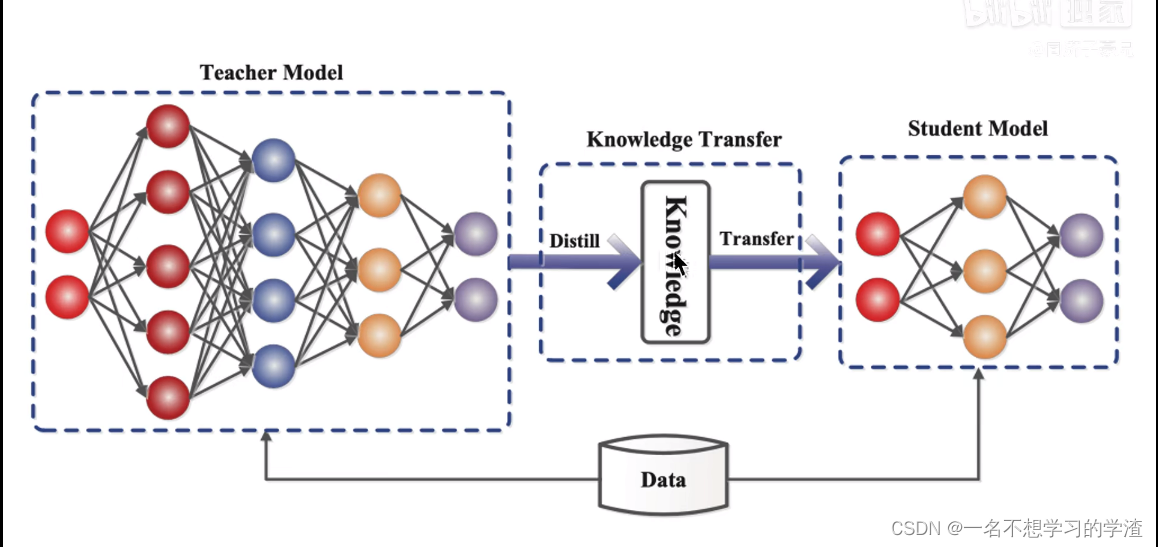
为了解决这样的现象,就提出了知识蒸馏的算法理论,就是将庞大的教师模型的重要的东西让学生模型来逼近和训练,让参数量少的学生模型能够和教师模型的效果差不多,或者比老师模型效果更好。这就是知识蒸馏的简单原理。如下两张图所显示,大家可以仔细参考
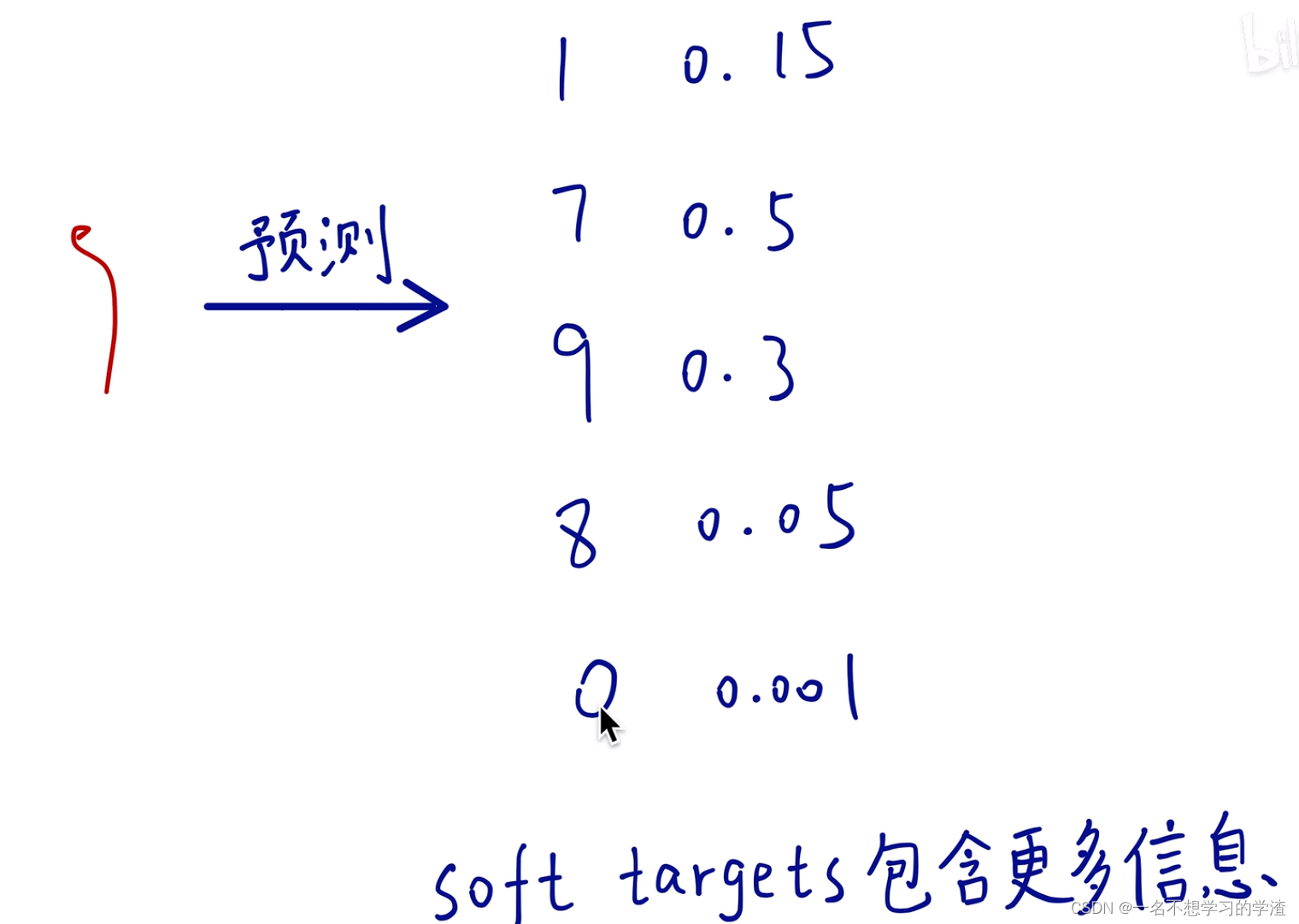
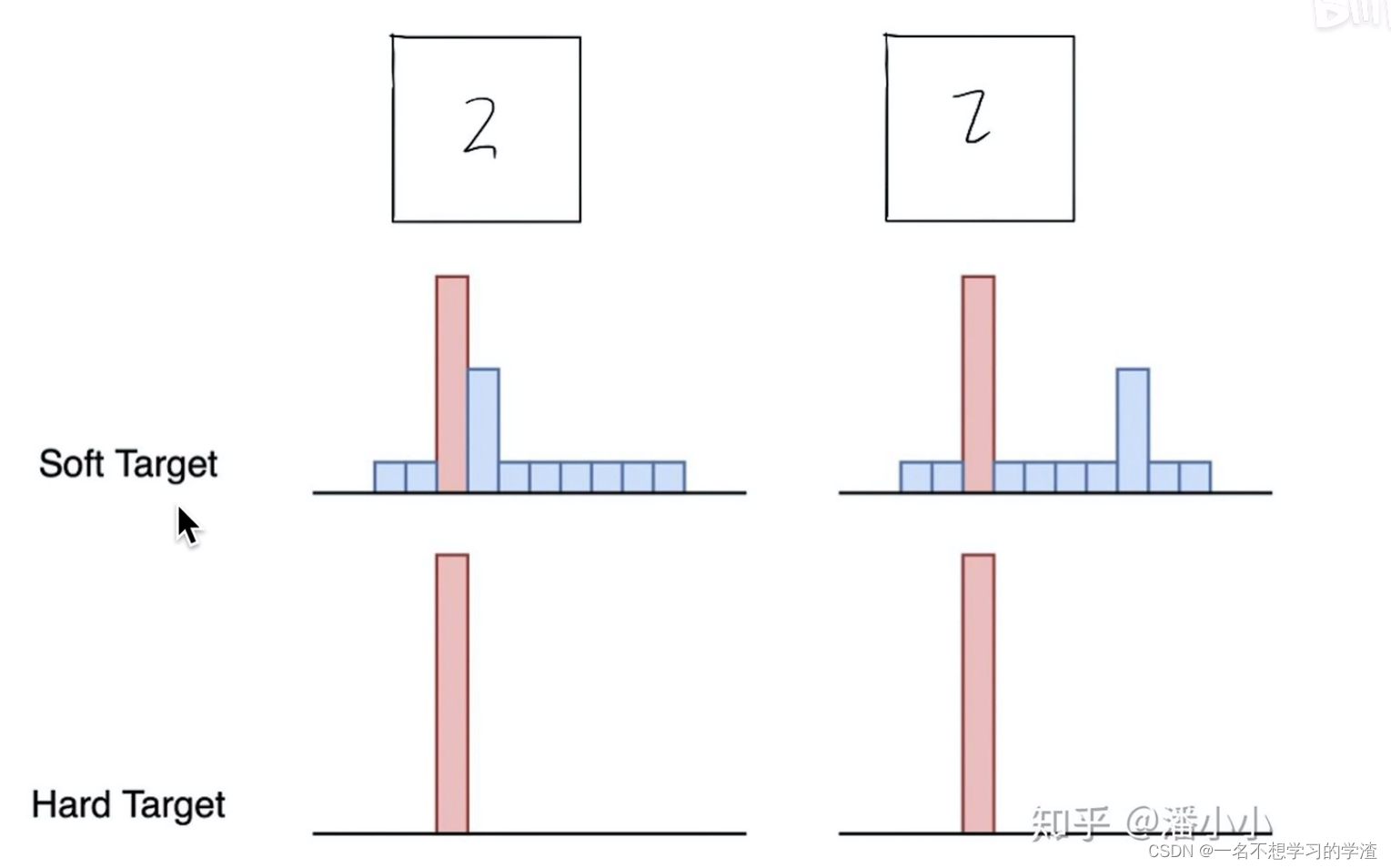
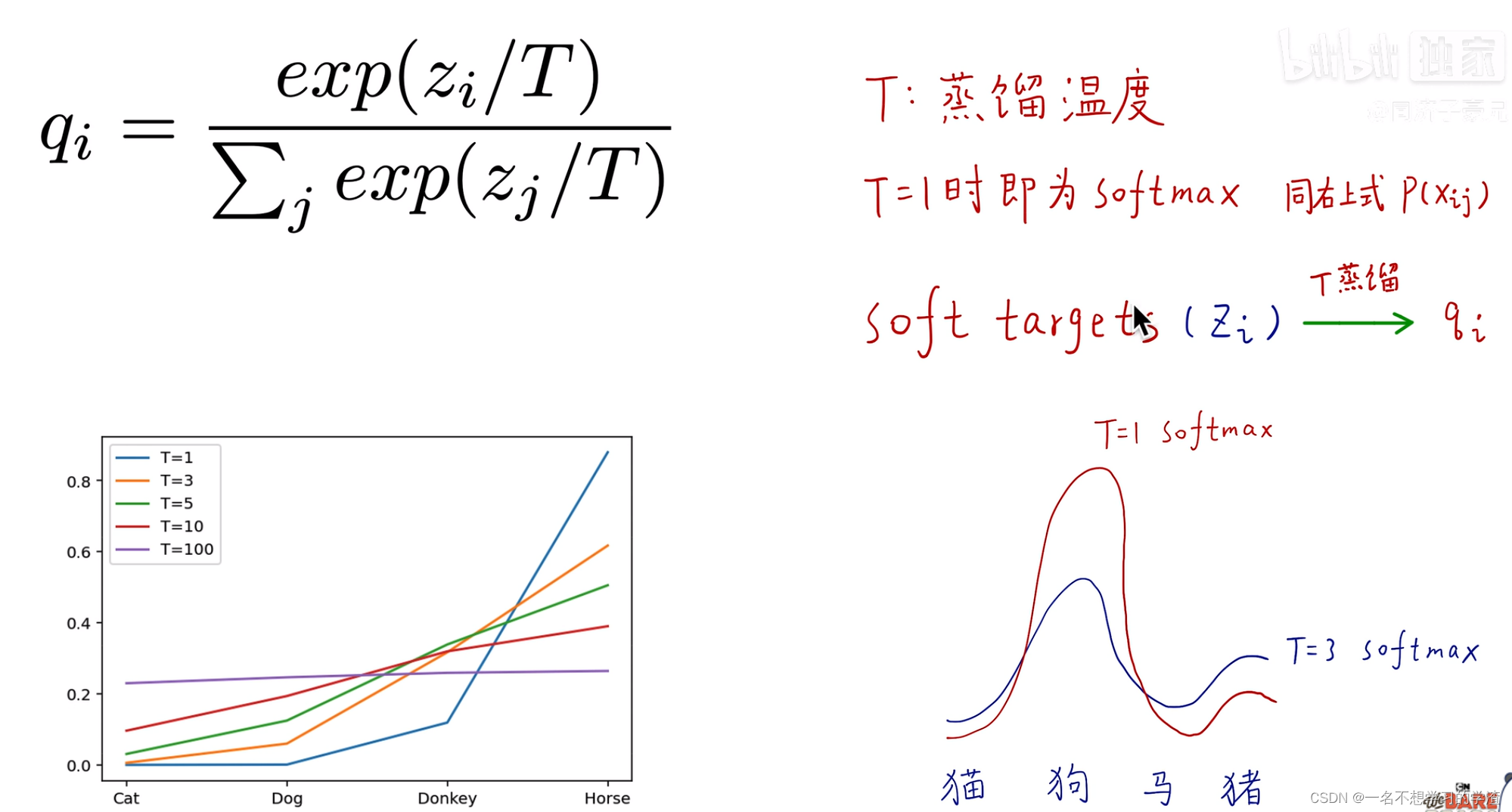
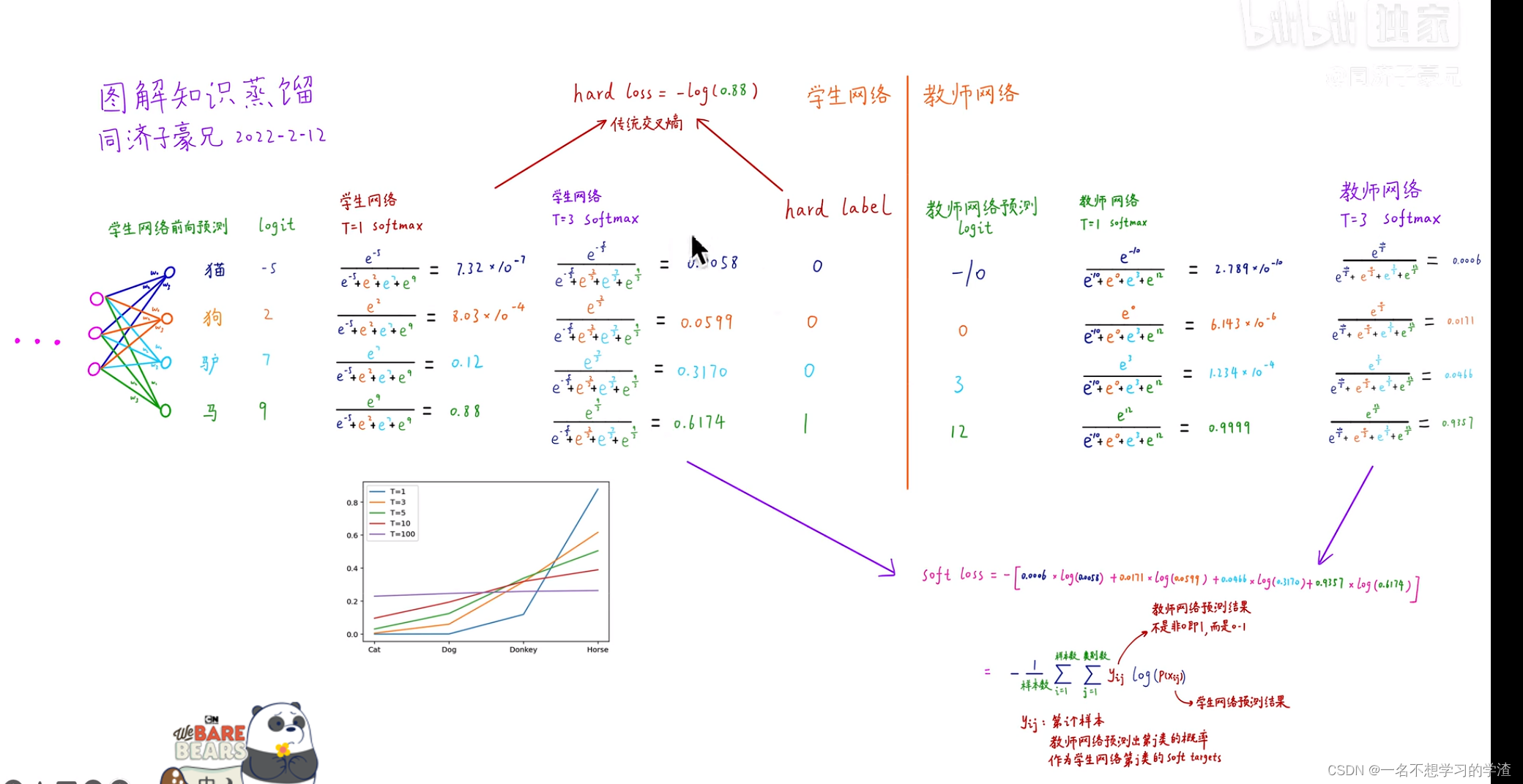
在说到知识蒸馏之前,首先说一下标签问题,在我们刚学习分类任务的时候,比如手写数字集,它的标签就是0,1-9,如下图,或者直接就是用独热编码的形式来作为标签。那么这样的做法到底好不好呢,对于这样的问题就有人说这样的标签容易让网络训练的过于绝对化,根据下面这个图显示,其实马也有一部分像驴,或者说驴也有一部分像马,如果将马的标签变成1,驴和汽车都是0,那么是不是就让驴和汽车的概率等同了,或者说驴和马的潜在关系直接被网络 忽略了。所以就又提出了soft targets。就是把标签要保持驴和马的潜在关系。看下面的图,大家应该都能看懂。这样的话这个网络就能够学到更多的潜在知识。


那么如何制作这样的标签来让学生网络学习到教师网络这种潜在的知识呢,就引出了蒸馏温度,如下图,当温度等于1的时候,就是一般的softmax,当温度稍微大一些的时候,那么原本被抑制成0的概率的类别就会拥有一些小概率,但是如果这个温度无限大的话,就会出现另一种问题,就是几个类别的概率没有了区分度,那么这个网络也就没有用了,所以对于温度T的选择也是非常重要的。
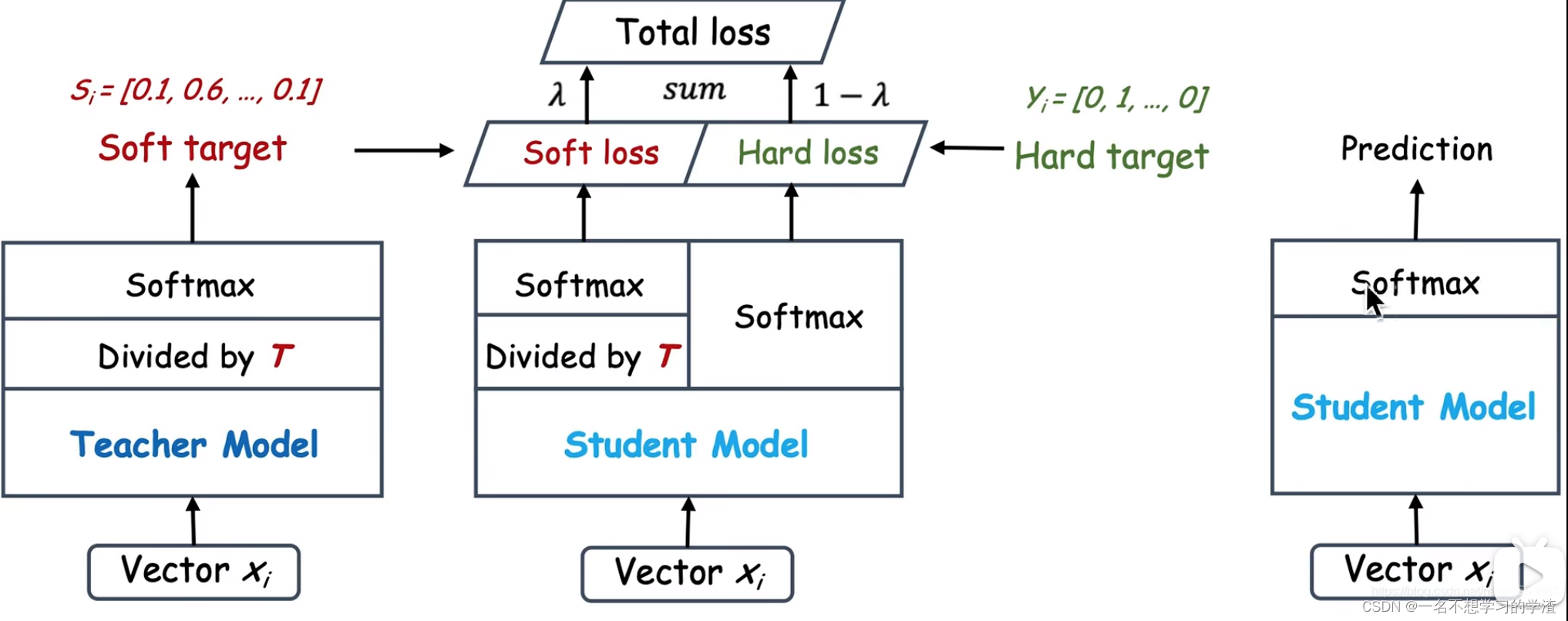
下面我们来看知识蒸馏算法,如下图,就是设计两个网络(学生和教师网络),将x输入两个网络中,其中教师网络是已经训练好了,有了训练权重,将教师网络的结果经过softlabel处理后,再和学生网络的结果经过softlabel处理后进行损失计算(采用的是KL散度损失),然后学生网络的结果再经过一般的sotmax处理后与一般的标签进行损失计算(交叉熵损失),最终两个损失结果在一个系数值的倍数下相乘再相加,最终得到总损失,进行训练。(如果看不懂就直接对着代码看图就能懂了)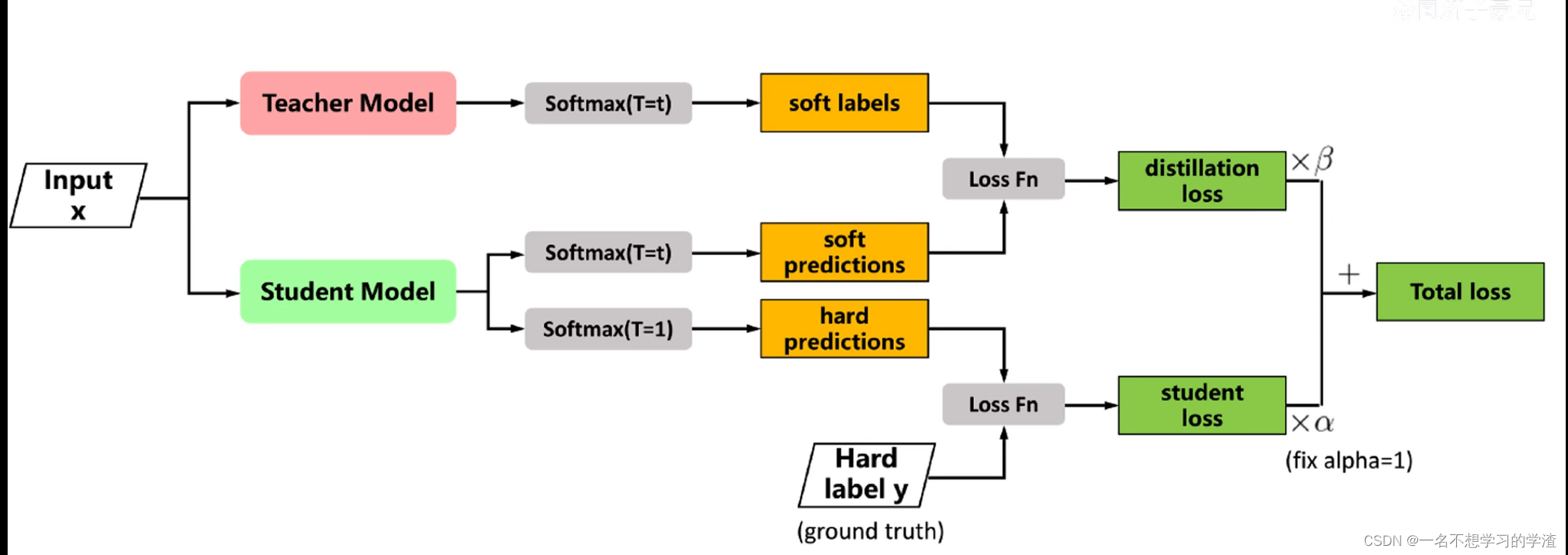
当然在预测的时候,就可以不用教师网络了,直接将训练的权重放到学生网络中就可以直接进行预测了。
二、知识蒸馏代码演示(手写数字集)
知识蒸馏算法(手写数字集算法),本算法建议在jupyter notebooks上面运行,因为一些变量的命名有重复,大家可以自己修改。
1.导入相关包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
from torchinfo import summary2.准备训练集
#设置随机种子
torch.manual_seed(0)
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
#使用cuda进行加速卷积运算
torch.backends.cudnn.benchmark=True
#载入训练集
train_dataset=torchvision.datasets.MNIST(root="dataset/",train=True,transform=transforms.ToTensor(),download=True)
test_dateset=torchvision.datasets.MNIST(root="dataset/",train=False,transform=transforms.ToTensor(),download=True)
train_dataloder=DataLoader(train_dataset,batch_size=32,shuffle=True)
test_dataloder=DataLoader(test_dateset,batch_size=32,shuffle=True)3.搭建教师网络
#搭建网络
class Teacher_model(nn.Module):
def __init__(self,in_channels=1,num_class=10):
super(Teacher_model, self).__init__()
self.fc1=nn.Linear(784,1200)
self.fc2=nn.Linear(1200,1200)
self.fc3=nn.Linear(1200,10)
self.relu=nn.ReLU()
self.dropout=nn.Dropout(0.5)
def forward(self,x):
x=x.view(-1,784)
x=self.fc1(x)
x=self.dropout(x)
x=self.relu(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.relu(x)
x = self.fc3(x)
return x
model=Teacher_model()
model=model.to(device)
#损失函数和优化器
loss_function=nn.CrossEntropyLoss()
optim=torch.optim.Adam(model.parameters(),lr=0.0001)
四.进行训练和预测结果
epoches=6
for epoch in range(epoches):
model.train()
for image,label in train_dataloder:
image,label=image.to(device),label.to(device)
optim.zero_grad()
out=model(image)
loss=loss_function(out,label)
loss.backward()
optim.step()
model.eval()
num_correct=0
num_samples=0
with torch.no_grad():
for image,label in test_dataloder:
image=image.to(device)
label=label.to(device)
out=model(image)
pre=out.max(1).indices
num_correct+=(pre==label).sum()
num_samples+=pre.size(0)
acc=(num_correct/num_samples).item()
model.train()
print("epoches:{},accurate={}".format(epoch,acc))
teacher_model=model
五.搭建学生网络
#构建学生模型
class Student_model(nn.Module):
def __init__(self,in_channels=1,num_class=10):
super(Student_model, self).__init__()
self.fc1 = nn.Linear(784, 20)
self.fc2 = nn.Linear(20, 20)
self.fc3 = nn.Linear(20, 10)
self.relu = nn.ReLU()
#self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
#x = self.dropout(x)
x = self.relu(x)
x = self.fc2(x)
#x = self.dropout(x)
x = self.relu(x)
x = self.fc3(x)
return x
model=Student_model()
model=model.to(device)
#损失函数和优化器
loss_function=nn.CrossEntropyLoss()
optim=torch.optim.Adam(model.parameters(),lr=0.0001)
六.学生网络的训练和预测结果
epoches=6
for epoch in range(epoches):
model.train()
for image,label in train_dataloder:
image,label=image.to(device),label.to(device)
optim.zero_grad()
out=model(image)
loss=loss_function(out,label)
loss.backward()
optim.step()
model.eval()
num_correct=0
num_samples=0
with torch.no_grad():
for image,label in test_dataloder:
image=image.to(device)
label=label.to(device)
out=model(image)
pre=out.max(1).indices
num_correct+=(pre==label).sum()
num_samples+=pre.size(0)
acc=(num_correct/num_samples).item()
model.train()
print("epoches:{},accurate={}".format(epoch,acc))
七.知识蒸馏相关参数设置
#开始进行知识蒸馏算法
teacher_model.eval()
model=Student_model()
model=model.to(device)
#蒸馏温度
T=7
hard_loss=nn.CrossEntropyLoss()
alpha=0.3
soft_loss=nn.KLDivLoss(reduction="batchmean")
optim=torch.optim.Adam(model.parameters(),lr=0.0001)
八.学生网络训练和预测结果
epoches=5
for epoch in range(epoches):
model.train()
for image,label in train_dataloder:
image,label=image.to(device),label.to(device)
with torch.no_grad():
teacher_output=teacher_model(image)
optim.zero_grad()
out=model(image)
loss=hard_loss(out,label)
ditillation_loss=soft_loss(F.softmax(out/T,dim=1),F.softmax(teacher_output/T,dim=1))
loss_all=loss*alpha+ditillation_loss*(1-alpha)
loss.backward()
optim.step()
model.eval()
num_correct=0
num_samples=0
with torch.no_grad():
for image,label in test_dataloder:
image=image.to(device)
label=label.to(device)
out=model(image)
pre=out.max(1).indices
num_correct+=(pre==label).sum()
num_samples+=pre.size(0)
acc=(num_correct/num_samples).item()
model.train()
print("epoches:{},accurate={}".format(epoch,acc))
至此知识蒸馏的一些原理及代码的笔记就完成了,希望大家有所收获,一起学习成长!本博客的来源图是bilibili的同济子豪兄的视频截取。
文章出处登录后可见!