初入深度学习2——如何使用一个深度学习库
学习前言
在完成仓库的下载与打开后,下一步就要开始使用这个仓库了,使用仓库的要求并不高,一般只需要按环境配置好,然后按照Readme运行就可以了。

使用一个深度学习仓库
一般来讲,使用深度学习仓库包含三个部分,第一部分是环境配置,第二部分是训练,第三部分是预测。
一、环境配置
环境配置部分需要仓库提供者提供使用的环境,有些开发者会提供这个requirements.txt,有些开发者可能只在Readme里面简单提及,各位同学在下载库的时候就要注意。
1、仓库包含requirements.txt
如果开发者提供了requirements.txt,事情就会变得简单起来。requirements.txt里面包括了所需要用到的python库,以YoloV5为例,它提供的requirements.txt是这样的。https://github.com/ultralytics/yolov5
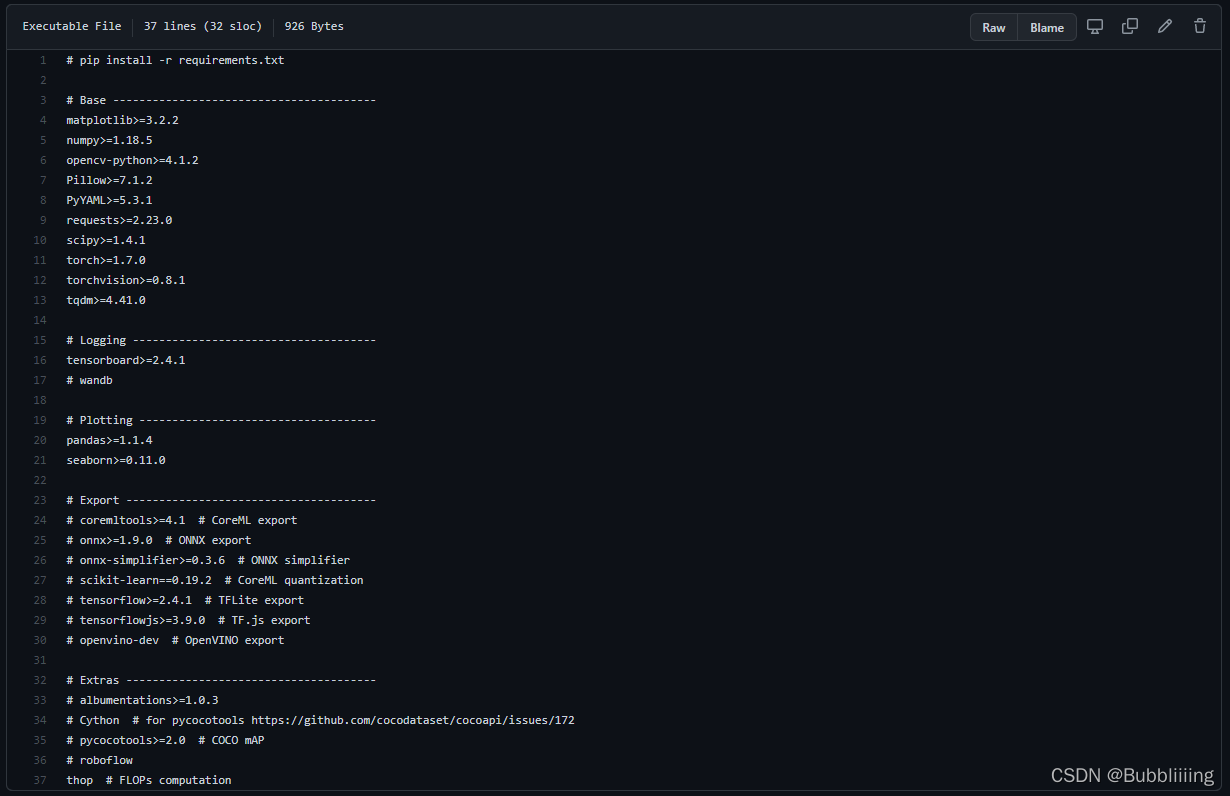
如果各位想使用YoloV5的官方库的话,就直接利用pip来安装这个requirements就可以了。YoloV5提供的步骤是这样的。
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
利用pip install -r就可以直接安装requirements.txt。
由于深度学习需要考虑CUDA和CUDNN的版本,各位在安装前需要注意配置所需的CUDA和CUDNN呀,不可一味只是配置python库,系统的深度学习环境同样重要,这个地方只能靠各位百度或者Google了。
2、仓库不包含requirements.txt
如果开发者不提供requirements.txt,事情会变得稍微复杂起来,不过大多数开发者还是会比较良心的在Readme里面写好所需要的环境,以qqwweee的keras-yolo3库为例,尽管它没有提供requirements.txt,但在Readme的最下部分提供了所需要的最重要的环境。
https://github.com/qqwweee/keras-yolo3
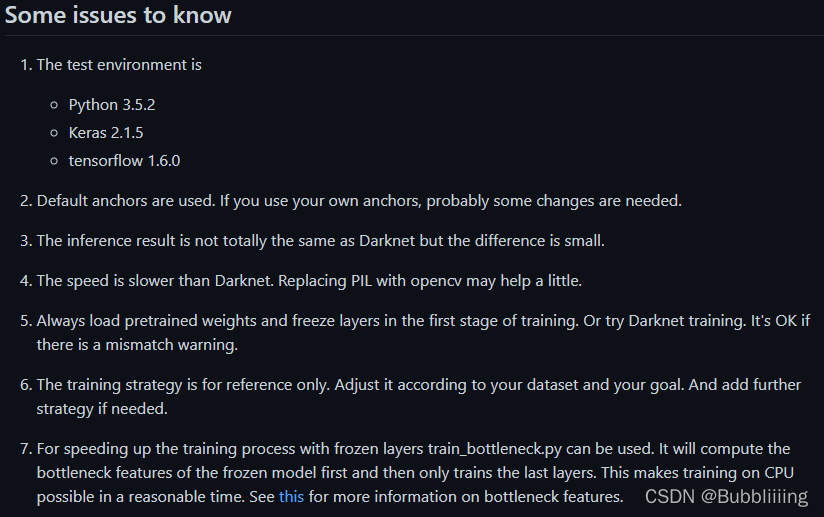
这种库就需要各位自己耐心去寻找了,没有定式了,找到所需的必要环境后,就去百度或者Google,寻找对应的环境配置教程进行安装即可,中间不免会踩坑,所以要多查查。
如果开发者不提供requirements.txt,也不在Readme里提供环境,那这个库的开发者一般比较不靠谱(虽然我曾经也是这样…不过现在基本上都提供了)。新手的话,我的建议是放弃这个库,多搜搜,同一个模型一般会有多个复现,看看别人的吧。老手的话,可以自己看看~
二、训练
1、训练通用数据集
训练部分其实主要也是看Readme,Readme一般会有个上手指南,关键词一般是train,需要搜一下。如果没有上手指南,那么还是同样的话,这个库的开发者一般比较不靠谱。新手的话,我的建议是放弃这个库。
还是以YoloV5为例,它提供的训练的方案。https://github.com/ultralytics/yolov5。
训练其实只需要这样一个指令,这个指令运行后,如果环境配置无误,应该会自动下载数据集并且开始训练。但由于都是自动配置,可能并不适合本身。熟悉仓库后可以尝试进行修改,不熟悉的话建议还是按默认来。
python train.py --data coco.yaml --cfg yolov5n.yaml --weights '' --batch-size 128
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 16
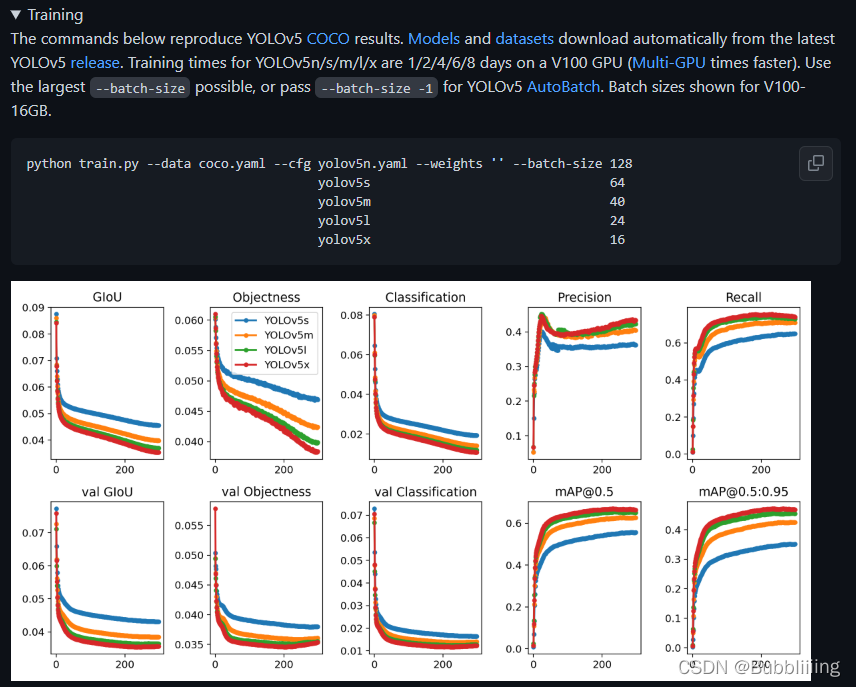
YoloV5的自动化程度很高,只需要配置好环境,基本上运行就没什么压力了。
以我提供的仓库为例,自动化程度就没有YoloV5官方库来的高,以我提供的YoloV4为例,https://github.com/bubbliiiing/yolov4-pytorch,就需要自己下载训练集,然后按照训练步骤进行。

这两种方式有利有弊,各位自己斟酌就好。
2、训练自己的数据集
训练自己的数据集的话,其实主要也是看Readme,Readme一般会有个上手指南,关键词一般还是train,需要搜一下。如果没有上手指南,那么还是同样的话,这个库的开发者一般比较不靠谱。新手的话,我的建议是放弃这个库。
还是以YoloV5为例,它提供了训练自己数据集的方案。https://github.com/ultralytics/yolov5。图上的Train Custom Data 就是训练自定义数据集。它给的训练过程非常齐全,按步骤走就能完成训练。

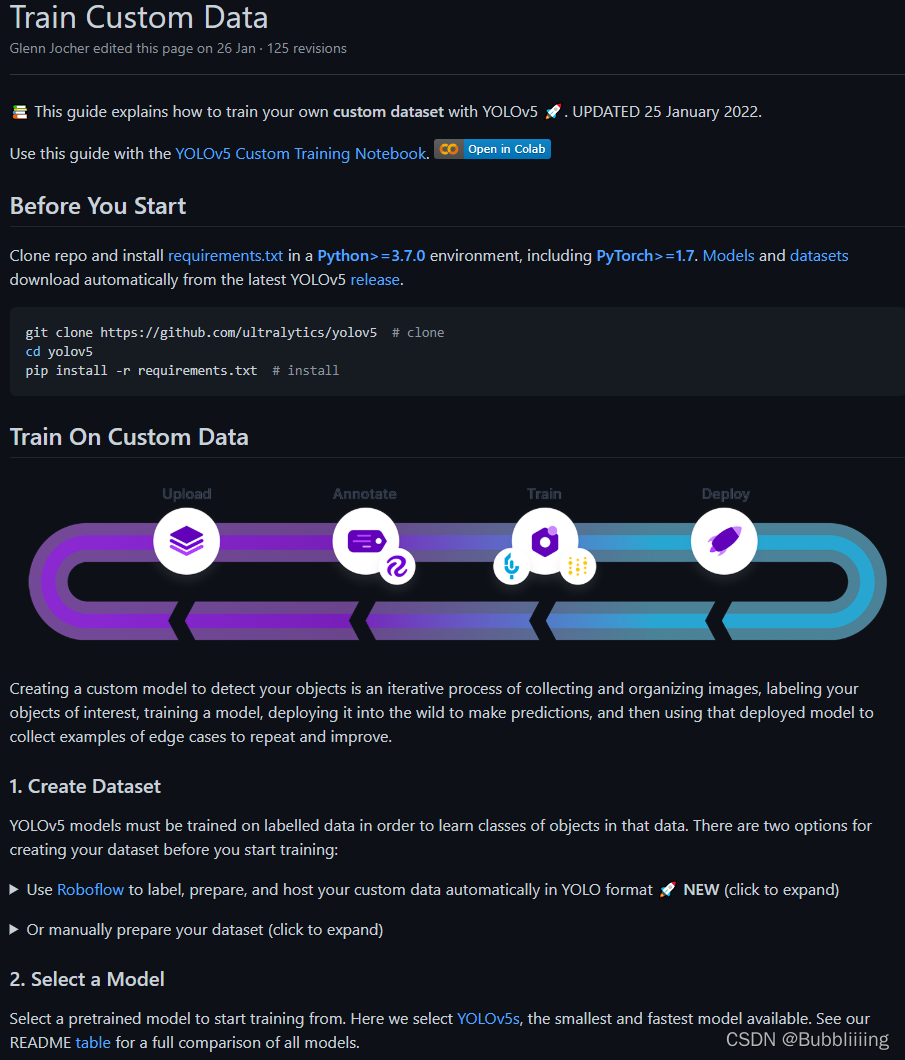
YoloV5的自动化程度很高,且Readme非常齐全,使用起来还是很简单的。
以我提供的仓库为例,自动化程度就没有YoloV5官方库来的高,步骤没有YoloV5来的齐全,可以结合视频进行标注与训练。

三、预测
预测部分其实主要也是看Readme,Readme一般会有个上手指南,关键词一般是predict或者Inference(当然也有别的,比如detect、image等),需要搜一下。如果没有上手指南,那么还是同样的话,这个库的开发者一般比较不靠谱。新手的话,我的建议是放弃这个库。
还是以YoloV5为例,它提供预测的方案。https://github.com/ultralytics/yolov5。预测同样只需要一个指令
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
还是非常容易理解的。
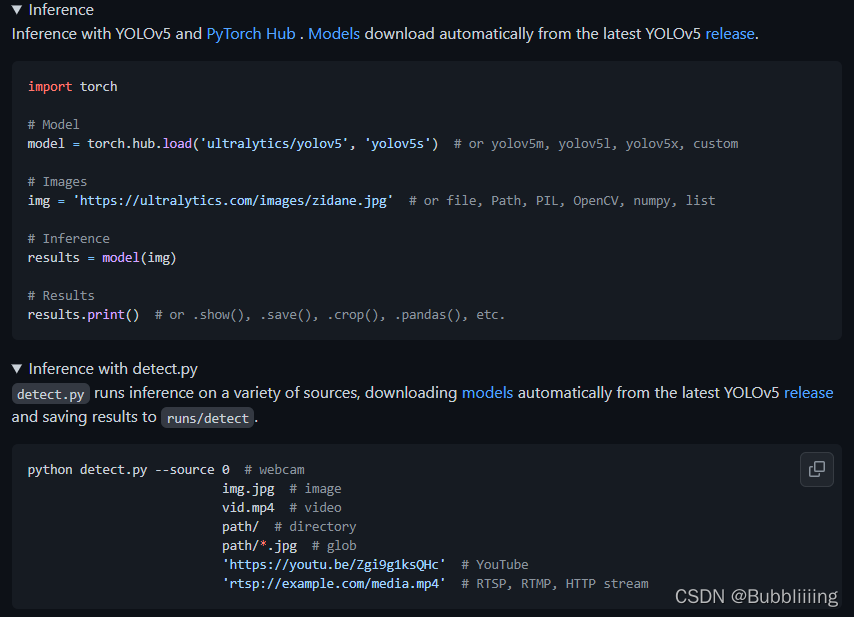
YoloV5的自动化程度很高,只需要配置好环境,基本上运行就没什么压力了。
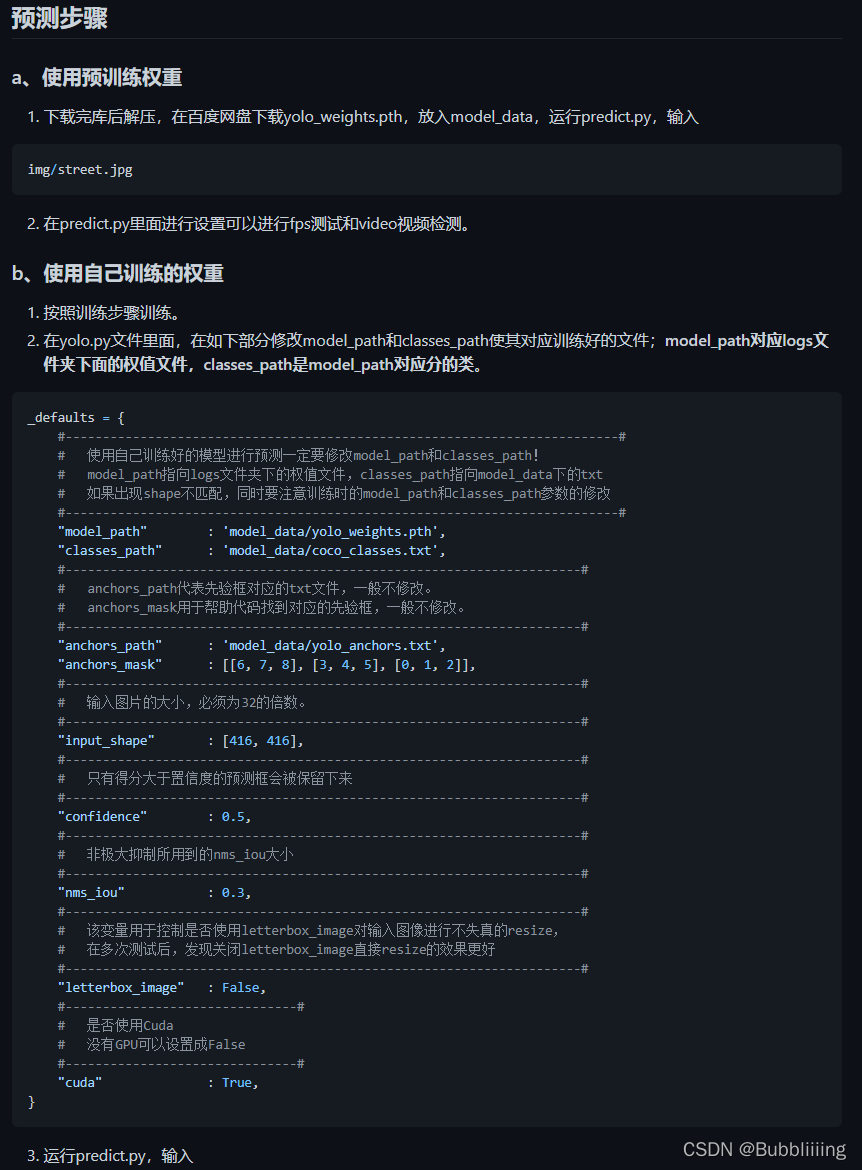
以我提供的仓库为例,自动化程度就没有YoloV5官方库来的高,以我提供的YoloV4为例,https://github.com/bubbliiiing/yolov4-pytorch,就需要自己下载权值,然后运行predict.py进行预测。
总结
对于Github上的仓库而言,Readme绝对是非常重要的,毕竟人家的名字就叫做 看我。那为什么不看它呢,好好阅读Readme,有利于各位使用各种深度学习仓库。
当然使用别人的是轻松的,如果各位自己上传深度学习仓库的话,也要写好Readme呢。
文章出处登录后可见!