1、背景
所谓模型过拟合现象:
在训练网络模型的时候,会发现模型在训练集上表现很好,但是在测试集上表现一般或者很差。
总结一句话:已知数据预测的很好,但对未知数据预测得很差的现象。
模型过拟合将图片数据的噪声当成特征点学习进去,导致模型的泛化能力很差,
只能在训练集上表现不错,对未知的其它样本预测表现不佳!
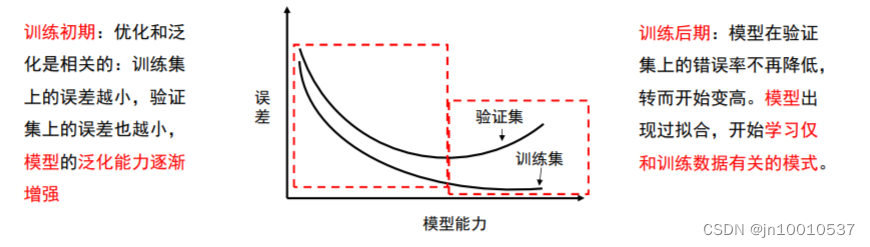
我们通过深度学习或者机器学习的根本问题是解决优化和泛化的问题平衡。
优化问题:训练模型以在训练数据上得到最佳性能。
泛化问题:模型在测试集上的取得很好的性能。
简单分析在模型训练过程的初期和后期:
2、模型拟合
模型拟合分为过拟合和欠拟合以及适度拟合。
下面以表格的形式表示拟合程度的简要判断标准。
| 训练集准确率 | 测试集准确率 | 得出结论 |
|---|---|---|
| 不好 | 不好 | 欠拟合 |
| 好 | 不好 | 过拟合 |
| 好 | 好 | 适度拟合 |
以下是欠拟合、适度拟合、过拟合的抽象数学表达以及形象展示拟合的程度。
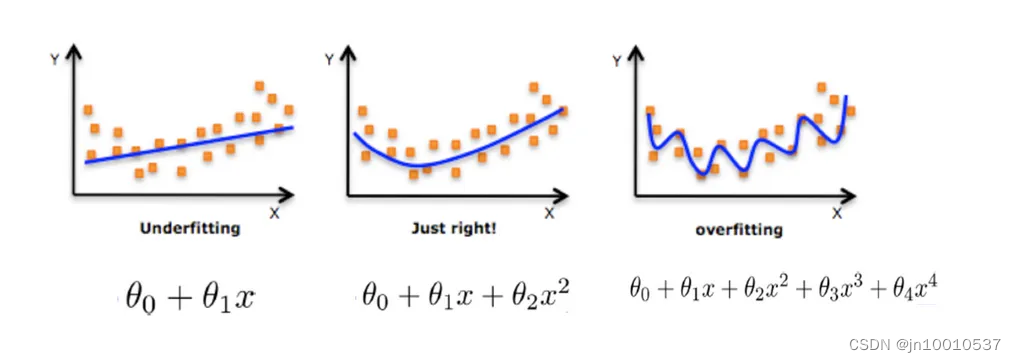
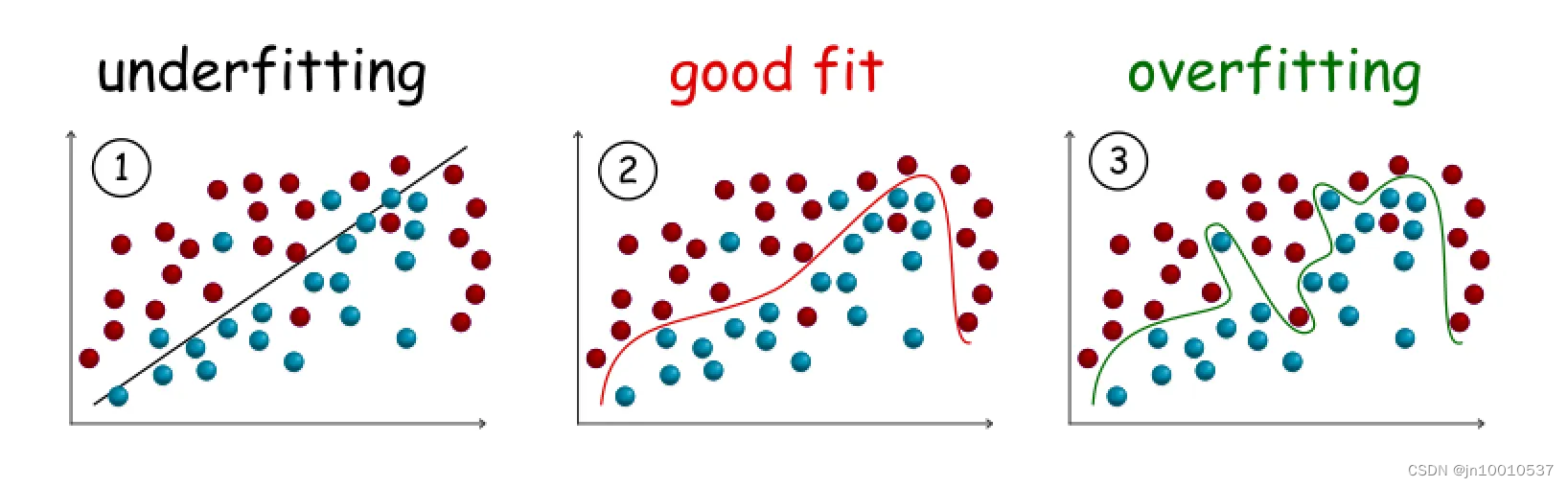
第1组模型欠拟合:模型复杂度过低,抽象出的数学公式过于简单,有很多错分的数据,不能很好的你和我们的训练集。
第2组模型拟合适度:虽然有个别错误数据点,但是预测新数据效果很好。
第3组模型过拟合:模型复杂度过高,抽象出的数学公式非常复杂,很完美的拟合训练集的每个数据,但过度强调拟合原始数据。预测新数据时它的表现性很差。
3、简述原因
欠拟合:
训练的特征量过少。
模型复杂度过低,网络模型过于简单。
训练数据集非常不健康,存在大量的错误标注。
过拟合:
样本数量太少,样本数据不足以代表预定的分类规则。
样本噪音干扰过大,将大部分噪音认为是特征从而扰乱了预设的分类规则。
4、欠拟合解决办法
对于欠拟合:总结一句话是模型简单的,样本数据量不够。
- 扩充样本数据,则增加更多的样本数据特征,使输入数据具有更强的表达能力。
- 增加模型复杂度:更换更复杂的网络模型,或者网络模型取消掉原有的正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数,不过这种方法一般不用,通常是更换更复杂的网络。
- 增加模型训练的迭代次数,模型训练迭代次数太少,训练的数据特征未充分学习。
- 手动调整参数和超参数。
5、过拟合解决办法
对于过拟合:发生过拟合最常见的现象就是数据量太少而模型太复杂。
训练集的数量级和模型的复杂度不匹配,大致思路是训练集的数量级要小于模型的复杂度。
-
首先增加训练数据数的样本数据量,并检查样本标签的准确性,训练集越多,过拟合的概率越小。
最好的是人工标注高质量的数据,可以采用一定的数据增强策略,来实现数据集的扩充。
注意扩充后的图像要手动确认,因为可能会有脏数据,从而会引入一定的噪声,噪声也会影响模型的性能的。 -
样本噪音干扰过大,需要手动清理掉脏数据,否则模型过分学习了噪音特征,反而忽略了真实的输入输出间的关系
-
参数太多,模型复杂度过高,将模型更换为更简单的网络模型,或者正则化L1和L2。 L1是模型各个参数的绝对值之和。L2是模型各个参数的平方和的开方值。
使用正则化约束:损失函数后面添加正则化项,可以避免训练出来的参数过大从而使模型过拟合。使用正则化缓解过拟合的手段广泛应用,不论是在线性回归还是在神经网络的梯度下降计算过程中,都应用到了正则化的方法。常用的正则化有l1正则和l2正则。 -
使用Dropout,即按一定的比例去除隐藏层的神经单元,使神经网络的结构简单化。torch.nn.Dropout(0.6),这里的0.6是神经元不保留的概率。
-
使用BN:Batch Normalization批归一化处理层,作用非常大。使得每一层的数据分布不变,做归一化处理,加快了模型的收敛速度,避免梯度消失、提高准确率。
-
保证训练数据的分布和测试数据的分布要保持一致,否则模型学习识鸟,你用它识别鸡蛋。
-
不要过度训练,提前结束训练early-stopping:训练时间足够长,模型就会把一些噪声隐含的规律学习到,这个时候降低模型的性能是显而易见的。所以建议在模型迭代训练时候记录训练精度(或损失)和验证精度(或损失),如果模型训练的效果不再提高,比如训练误差一直在降低但是验证误差却不再降低甚至上升,这时候便可以结束模型训练了。
-
手动调整参数和超参数。
文章出处登录后可见!