从本期开始,会探索图像恢复领域的论文和代码。本次先阅读一下综述。
传统方法一个很大的假设是我们相信我们可以在缺失区域之外找到相似的patch,但是如果缺失区域之外没有任何类似的patch,就没有办法正确修复图像了。
1 经典GAN方法
1.1 context encode:U-net生成器
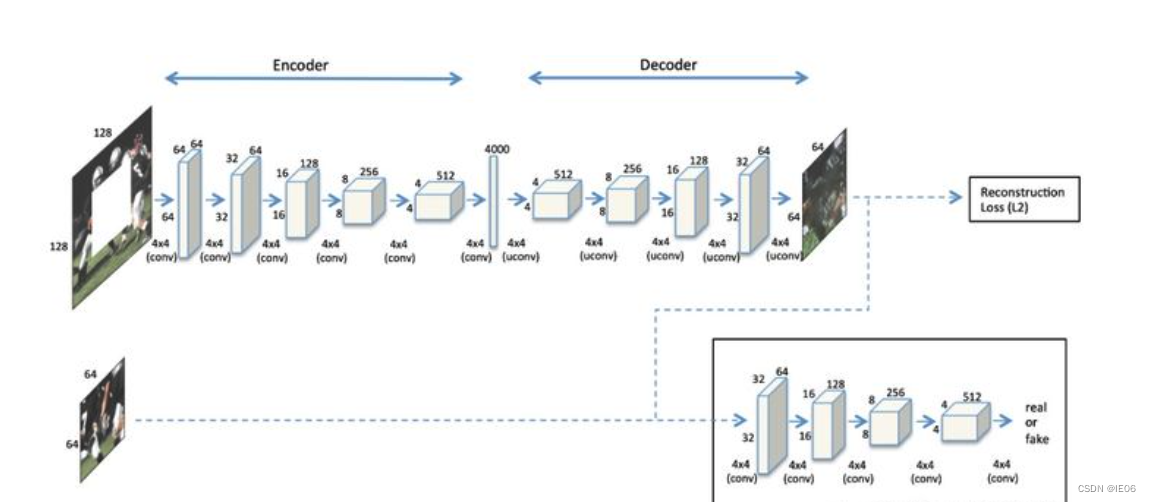
2016年出现的基准的GAN算法,生成器为一个U型网络,判别器为多层卷积网络。损失包括像素级别的重建损失(L2)和鉴别器产出的对抗损失。
1.2 MSNPS:添加纹理生成器
2016年升级版的context encode,其生成器包含两部分,增加了生成纹理的卷积网络:
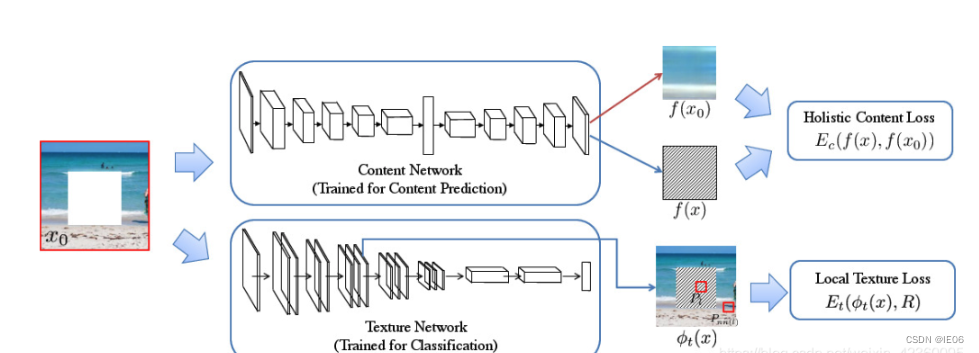
上面的U型网络用于生成内容,损失函数包括L2损失和对抗损失。
下面的卷积网络用于生成纹理,并寻找缺失区域外最近的神经网络响应来计算损失。这里的做法类似风格转移,将完整部分的风格迁移到损失部分。
1.3 GLCIC:添加局部鉴别器
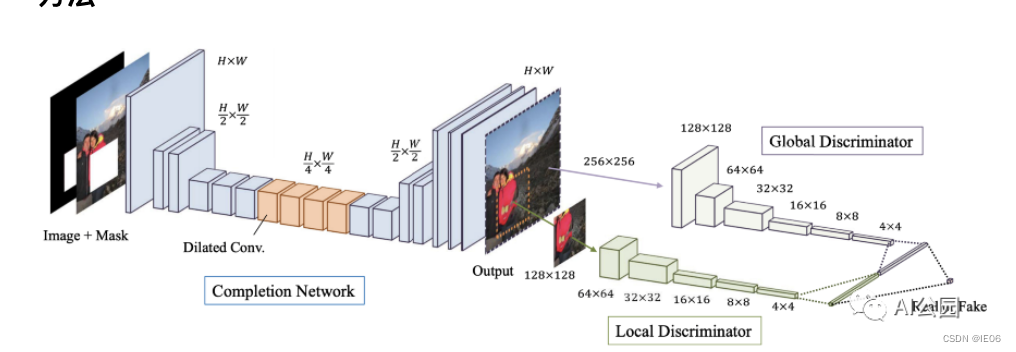
这里生成器使用了膨胀卷积用来增加感受野。
训练分为3步:
- 生成器L2损失,注意L2损失是在缺失区域内计算的。
- 训练判别器
- 生成器加上对抗损失,与判别器交替训练
图像后处理采用fast marching+泊松图像混合
1.4 PGGAN:添加矩阵鉴别器
GLCIC太依赖于预先定义好的缺失区域,而实际场景中的残缺经常是未知的,因此仍需改进。
典型GAN鉴别器的输出是0 ~ 1的单个值。这意味着鉴别器会看整个图像,判断这幅图像是真的还是假的,我们称之为GlobalGAN。而PatchGAN判别器的输出是一个矩阵,这个矩阵中的每个元素都在0到1之间。注意,每个元素代表输入图像中的一个局部区域。
两者结合,叫做PGGAN
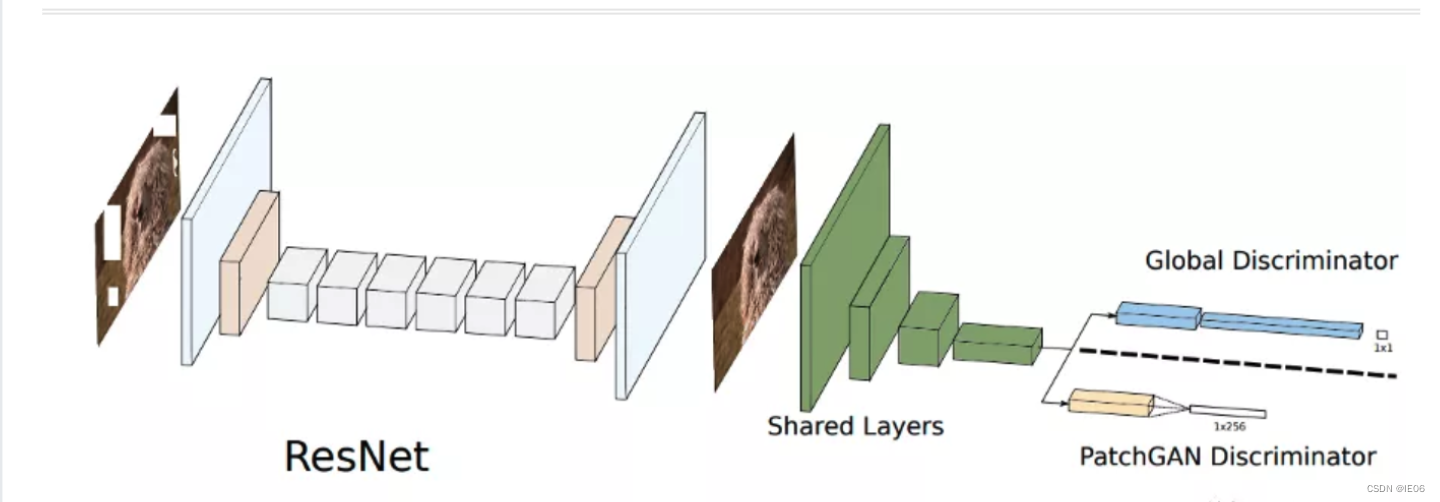
结构和GLCIC很相似,其中生成模块改成了膨胀残差网络,此外将标准反卷积改成了插值卷积用以消除伪影。
1.5 shiftGAN:U-net生成器添加shift连接
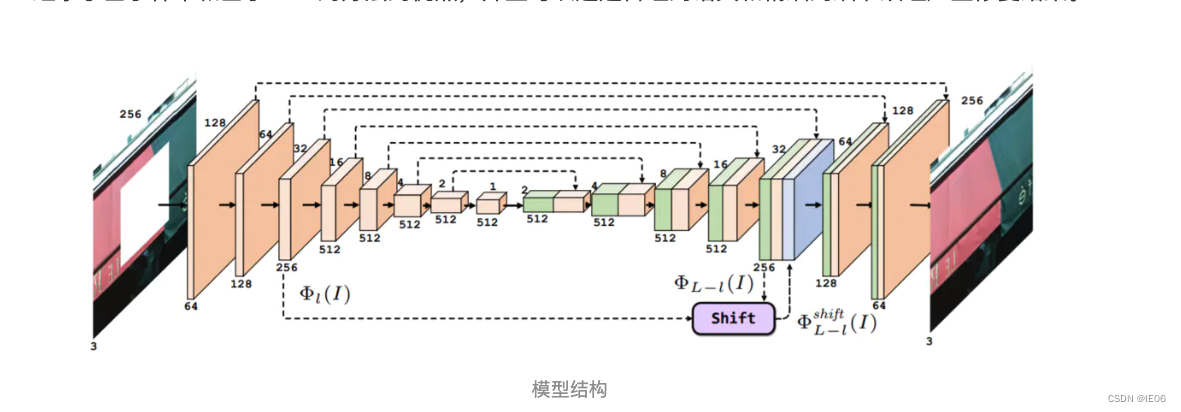
添加引导损失:所有连接的两个层之间编码特征和解码特征的L2损失之和。
添加shift连接:通过移位操作,网络可以有效借用缺失部分外最近的邻居给出的信息,来完善生成部分的全局语义结构和局部纹理细节。简单来说,它就是提供合适的参照物来完善估计。
1.6 DeepFill:生成器添加注意力
作者提出了一个二阶段的由粗到细的修复网络:
第一阶段粗修复网络:使用空洞卷积+重建损失先补出一个模糊粗糙的结果;
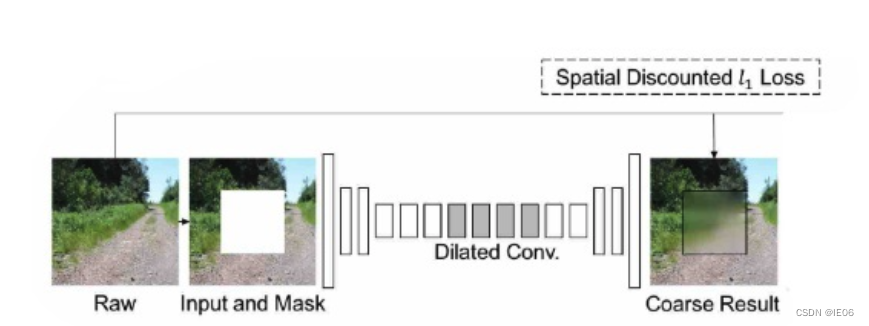
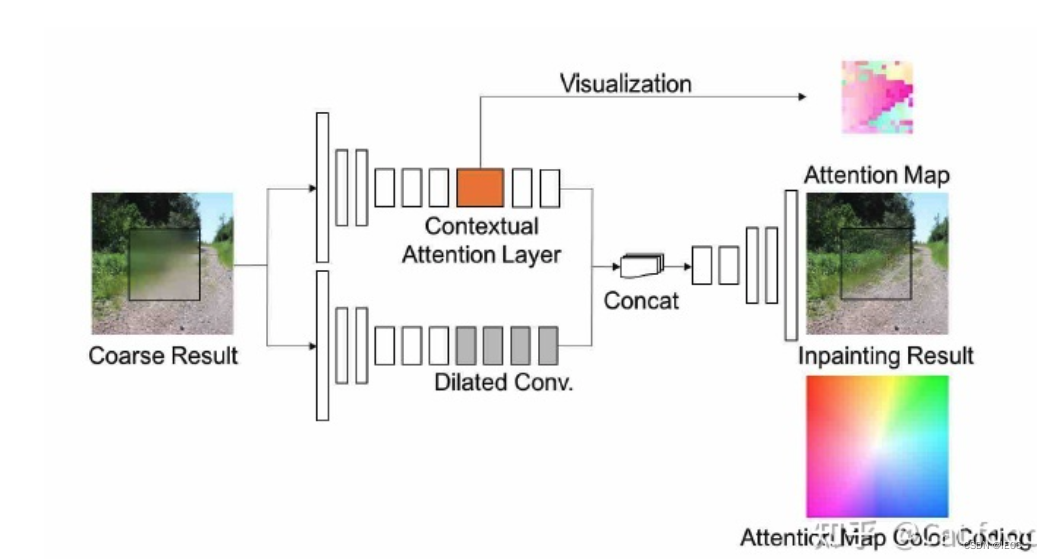
第二阶段精修复网络:使用带语境注意力模块空洞卷积+重建损失+全局、局部GAN-GP对抗损失来进一步细化结果。
encode部分上路分支是包含语义注意力层(contextual attention layer)的encoder;下路是常规的encoder。两路encoder输出的特征图最后拼接在一起合成一个特征图,最后通过decoder生成修复结果。
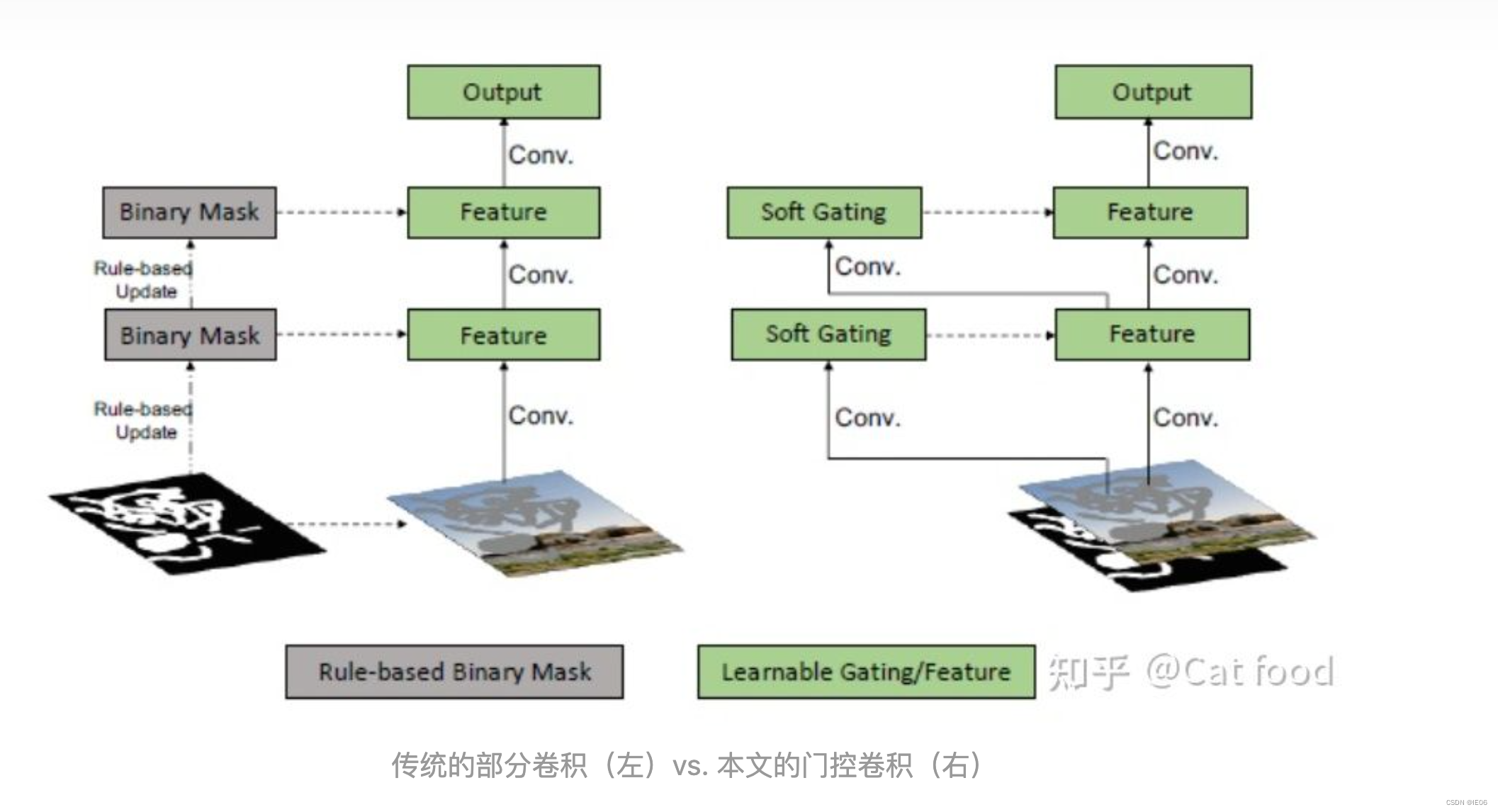
1.7 DeepFill v2: mask由门控卷积生成
gated conv是本文的核心创新点,他就像一个软筛子一样,对输入有选择机制。(软性选择,就是乘以一个0-1之间的数,与之相对的是硬筛子,要么全通过,要么全拦下),它可以自动根据更新规则从数据里面学到soft mask的参数(就像过滤系数一样),如下式:
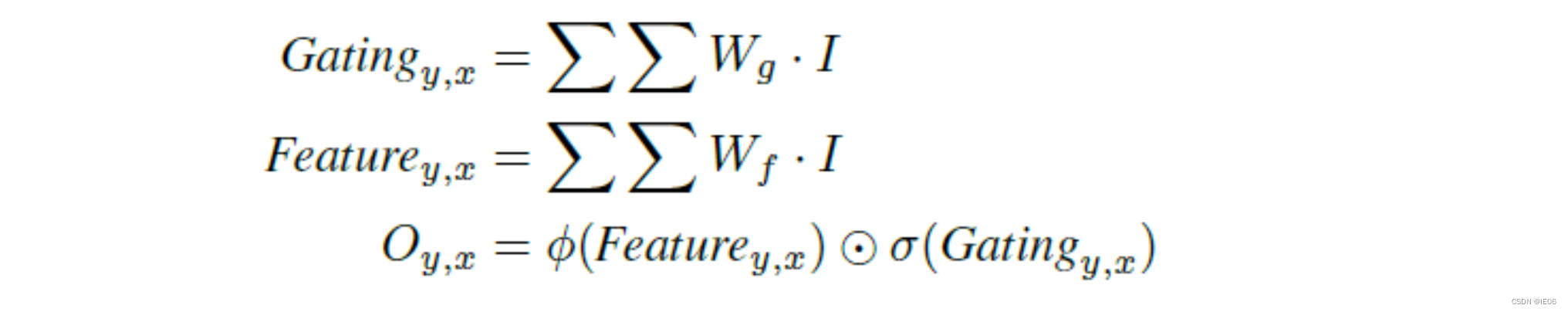
此外为了应对free-form的mask,使用了Markovian discriminiator,对尺寸小于原图的矩阵打分。对抗损失使用了Hinge loss。
1.8 PatialConv:处理freeMask
其核心思想是,如果感受野内不存在有效像素(即都被mask了),则不进行卷积操作;其他情况下,也只对有效像素做卷积。
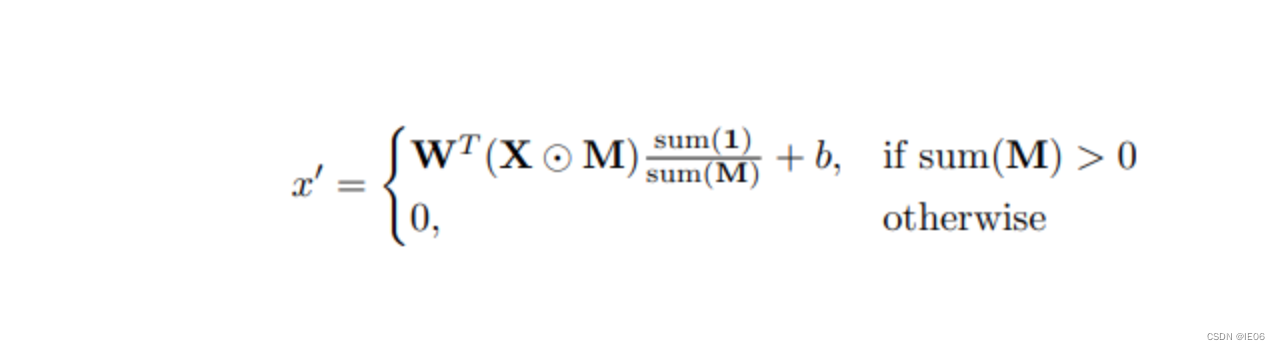
此外,mask也不断更新:

1.9 CTSDG:鉴别器添加边缘检测
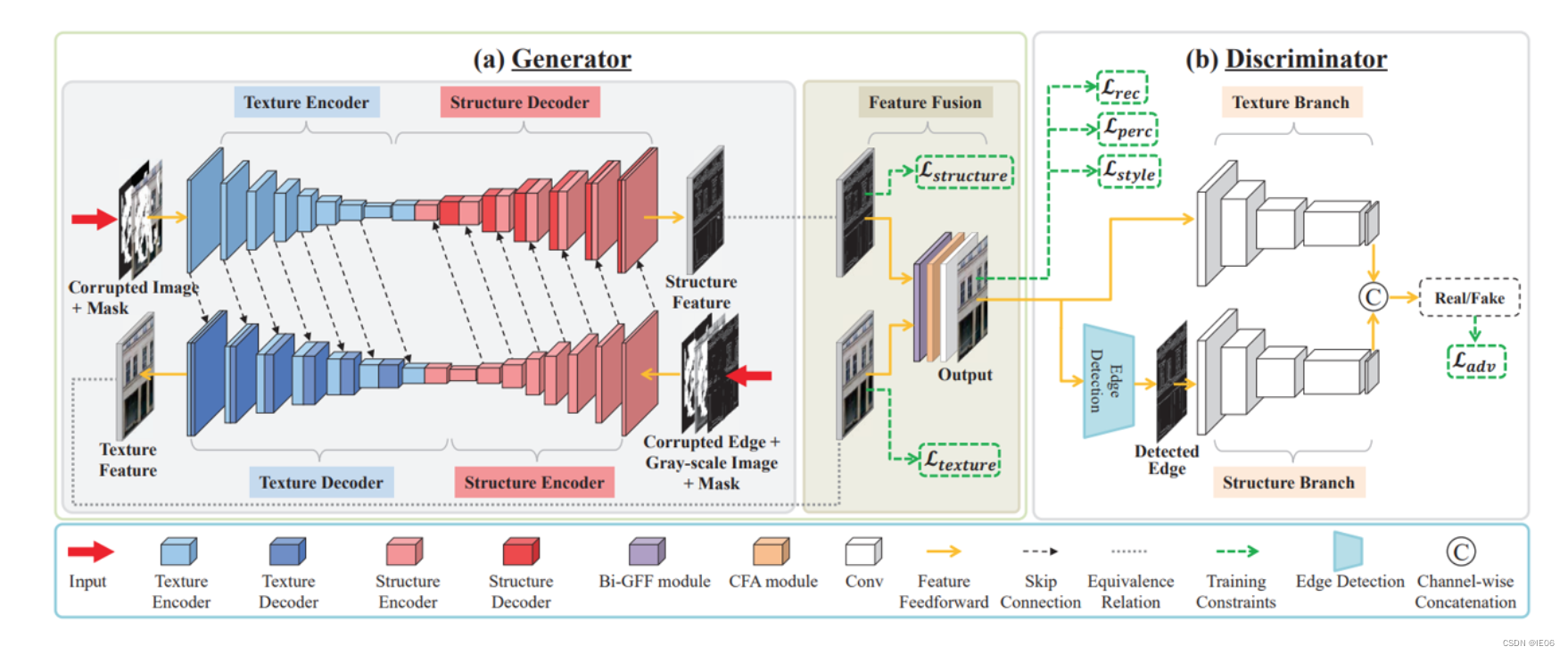
比较像MSNPS,生成器这边从图像、边缘分别生成,鉴别器这边也是从图像、边缘分两支进行判定。
1.10 EdgeConnect:添加边缘生成器和边缘判别器
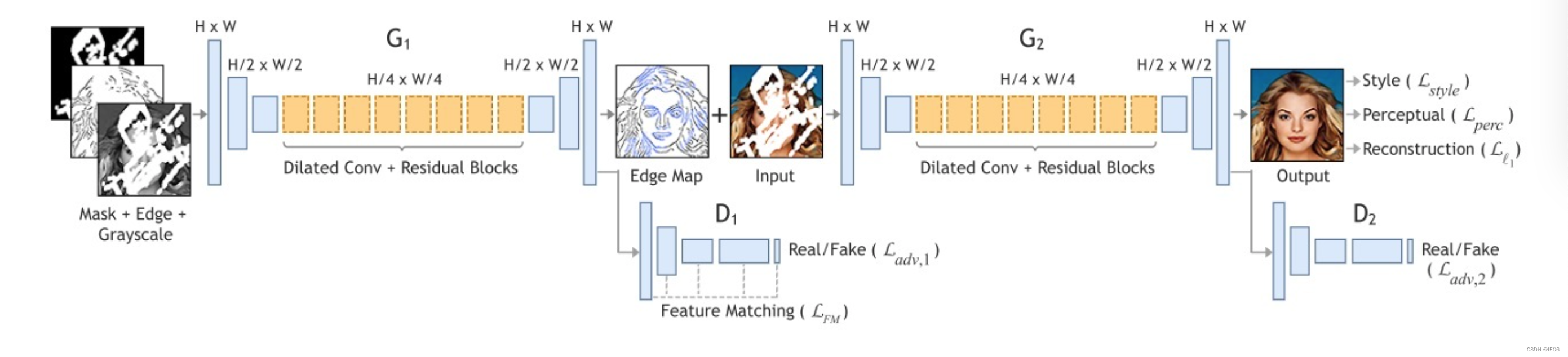
这个项目的功能和deepfill v2比较像,使用轮廓作为先验来指导图像生成。
如上图,左半部分的G1和D1用来学习轮廓,右边半部分的G2和D2则用来生成最终的图像。
G1和G2都使用了空洞卷积+残差模块;D1和D2都使用PatchGAN,也就是将判别图片分成70×70进行判别,对判别结果取平均。
原先的图片修补任务需要对RGB值图片的缺失区域进行修补,如果采用范数距离计算重构损失的话,总得到模糊的图片(对可能的修补模式求平均的结果);如果采用特征距离计算对抗损失
的话,总得到人造痕迹太明显的图片(伪像)(从训练记忆里面找一个相似的结果并贴上去)。上下文编码器 Context Encoder 采用参数加权的方式结合使用两者,只是平衡了这两个缺点。
既然如此,把图片修补任务的难度降低,不修复三通道的RGB图,转而修复只有轮廓的二值图。修复得到了轮廓图片后,将其转变为风格迁移任务(将轮廓图转化为彩色图片)。这个过程,把恢复高频信息与低频信息的过程解耦合,从而解决图片修补任务。
文章出处登录后可见!