论文:
《Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers》
官方链接:
(32 封私信) 自动驾驶BEV感知有哪些让人眼前一亮的新方法? – 知乎 (zhihu.com)
较好的代码分析:
万字长文理解纯视觉感知算法 —— BEVFormer – 知乎
这个对工程文件的解读真的绝了,能帮助新手快速上手 代码的整体框架
主要工作:
一句话总结:
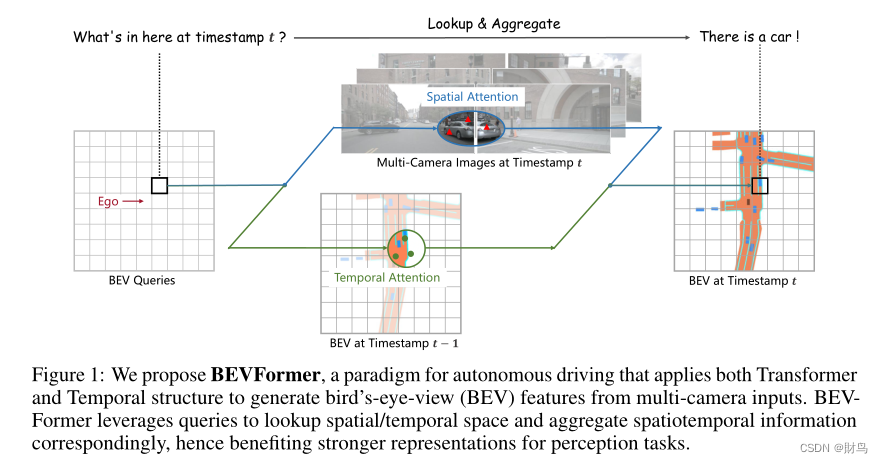
- 利用了transformer的查询机制来聚合时序信息和空间信息实现多视角输入到BEV视图的转换
总之,结合了注意力机制和时序信息。
关键设计:
- 网格状的空间查询,通过注意力机制灵活的融合空间特征和时间特征。
- 空间交叉注意力模块,聚合多相机图像的空间信息。
- 时间自注意力模块,从历史BEV特征中提取时序信息,有利于运动目标的的运动估计,和应对严重遮挡的目标检测。
BEVFormer
Overall Architecture
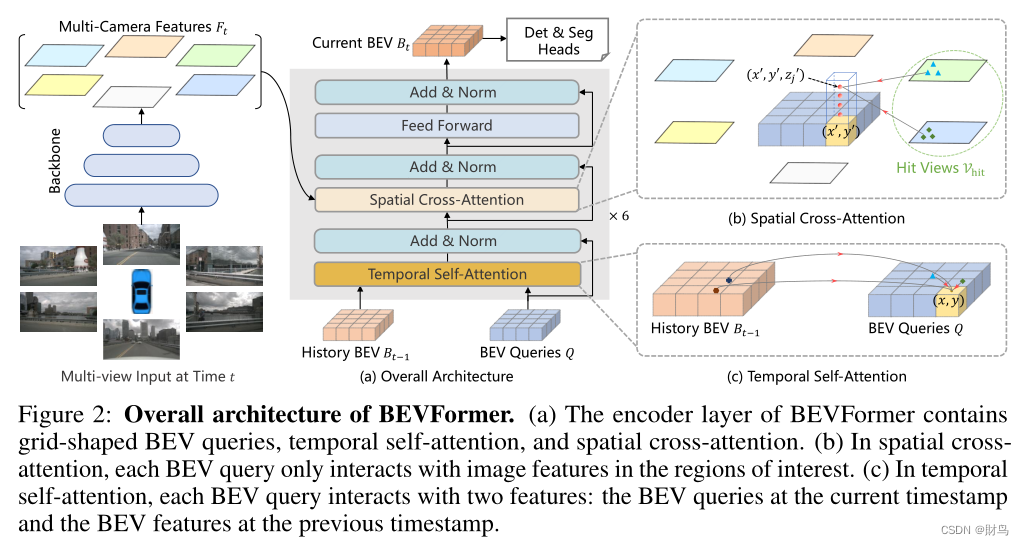
BEV queries的定义
定义了一组维度为H*W*C的可学习参数作为BEV queries, 用来捕获BEV特征。在nuScenes数据集上,BEV queries 的空间分辨率为200*200,对应自车周围100m*100m的范围。BEV queries 每个位于(x, y)位置的query都仅负责表征其对应的小范围区域。BEV queries 通过对spatial space 和 tempoal space 轮番查询从而能够将时空信息聚合在BEV query特征中。最终我们将BEV queries 提取的到的特征视为BEV 特征,该BEV特征能够支持包括3D 目标检测和地图语义分割在内的多种自动驾驶感知任务。
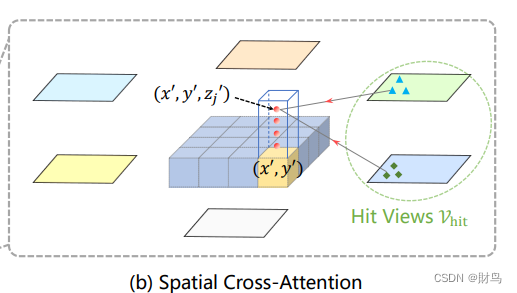
Spatial Cross-Attention
设计了一中空间交叉注意力机制,使BEV queries 从多相机特征中通过注意力机制提取所需的空间特征。由于本方法使用多尺度的图像特征和高分辨率的BEV特征,直接使用最朴素的global attention 会带来无法负担的计算代价。因此我们使用了一种基于deformable attention 的稀疏注意力机制时每个BEV query之和部分图像区域进行交互。具体而言,对于每一个位于(x, y)位置的BEV特征,我们可以计算其对应现实世界的坐标x',y'。 然后我们将BEV query进行lift 操作,获取在z轴上的多个3D points。 有了3D points, 就能够通过相机内外参获取3D points 在view 平面上的投影点。受到相机参数的限制,每个BEV query 一般只会在1-2个view上有有效的投影点。基于Deformable Attention, 我们以这些投影点作为参考点,在周围进行特征采样,BEV query使用加权的采样特征进行更新,从而完成了spatial 空间的特征聚合。
Temporal Self-Attention
从经典的RNN网络获得启发,我们将BEV 特征视为类似能够传递序列信息的memory。 每一时刻生成的BEV特征都从上一时刻的BEV特征获取了所需的时序信息,这样保证能够动态获取所需的时序特征,而非像堆叠不同时刻BEV特征那样只能获取定长的时序信息。具体而言,给定上一时刻的BEV 特征,我们首先根据ego motion 来将上一时刻的BEV特征和当前时刻进行对齐,来确保同一位置的特征均对应于现实世界的同一位置。对于当前时刻位于(x, y)出的BEV query, 它表征的物体可能静态或者动态,但是我们知道它表征的物体在上一时刻会出现在(x, y)周围一定范围内,因此我们再次利用deformable attention 来以(x, y)作为参考点进行特征采样。我们并没有显式地设计遗忘门,而是通过attention 机制中的attention wights来平衡历史时序特征和当前BEV特征的融合过程。每个BEV query 既通过spatial cross-attention 在spatial space下聚合空间特征,还能够通过temporal self-attention 聚合时序特征,这个过程会重复多次确保时空特征能够相互促进,进行更精准的特征融合
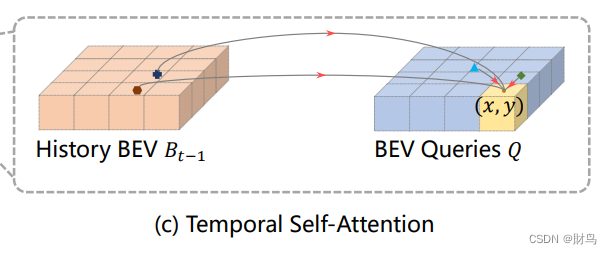
思考:这里基于时序的注意力模块我看了很久都不太明白,目前的理解是encoder模块不是有6个吗,在第一个模块里,BEV queries是随机初始化的,而通过历史的BEV特征可以一定程度上帮助queries进行初始化。我之前的一个疑问是为什么是自注意力机制,以为query在历史BEV里加权搜集信息就好了,后面才反应过来那样理解的话6个模块级联有啥意义啊,所以除了第一个encoder里query是纯纯的在搜集历史信息外,后面的query都融合了历史特征和当前时刻空间特征,所以在后面的5个encoder里,历史BEV(t-1)和当前BEV(T)分别进行自注意力操作,输出在进行加权求和就好了。不要被那个BEV queries搞混了,作为一个encoder的输入其实际上就是上一个encoder的BEV特征输出,放到最后一个encoder其实就是最后输出的BEV特征图,和 history BEV本质上是一样的东西。
文章出处登录后可见!