在最新的视觉顶会CVPR2022会议中,涌现出了大量基于生成对抗网络GAN的论文,广泛应用于各类视觉任务;
下述论文已分类打包好!后台回复 CVPR2022 (长按红字、选中复制)获取分类、按文件夹汇总好的论文集,gan起来吧!!!
梳理不易,麻烦各位看官,转发、分享、在看三连,多多鼓励小编!!!
一、3D
1、FLAG: Flow-based 3D Avatar Generation from Sparse Observations
为了生成逼真合理的虚拟形象姿势,从头戴式设备 (HMD) 应用于此任务的信号流通常仅限于头部姿势和手部姿势估计得来。
虽然这些信号很有价值,但它们是人体的不完整表示,因此很难生成合理的虚拟全身。通过从稀疏观察中开发基于流的 3D 人体生成模型来应对这一挑战,其中不仅学习 3D 人体姿势的条件分布,还学习从观察到潜在空间的概率映射,从中生成一个合理的姿势以及关节的不确定性估计。
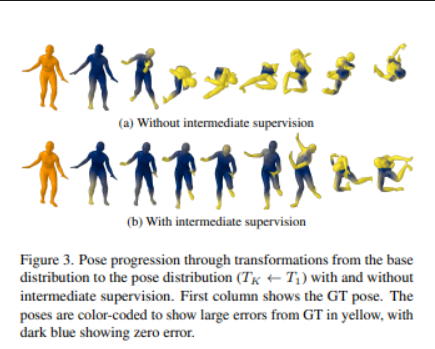
2、3D Shape Variational Autoencoder Latent Disentanglement via Mini-Batch Feature Swapping for Bodies and Faces
在人脸和身体的 3D 生成模型中学习解耦的、可解释的和结构化的潜在表征仍是一个悬而未决的问题。当需要对身份特征进行控制时,这个问题尤其严重。
本文提出一种直观而有效的自监督方法来训练 3D 形状变分自动编码器 (VAE),方法可以分离身份特征的潜在表示。通过在不同形状之间交换任意特征来管理小批量生成,可以定义一个损失函数,利用潜在表示中的已知差异和相似性。实验结果表明,最先进的潜在解耦方法无法解开面部和身体的身份特征,提出的方法则正确地解耦了这些特征的生成,同时保持了良好的表示和重建能力。
代码和预训练模型可在github.com/simofoti/3DVAE-SwapDisentangled
二、GAN改进
3、Polarity Sampling: Quality and Diversity Control of Pre-Trained Generative Networks via Singular Values
提出Polarity采样,一种即插即用方法,用于控制预训练的深度生成网络(pre-trained deep generative networks,DGNs)的生成质量和多样性。本文展示了一些最先进的 DGN 的整体生成质量(例如,就 Frechet Inception 距离而言)改进的定量和定性结果,包括 StyleGAN3、BigGAN-deep、NVAE、用于不同的有条件和无条件图像生成任务。特别是,Polarity采样将 FFHQ 数据集上的 StyleGAN2 的FID 表现更新为2.57,LSUN 汽车数据集上的StyleGAN2 表现为 FID 2.27,AFHQv2 数据集上 StyleGAN3 的 FID 3.95。

4、Feature Statistics Mixing Regularization for Generative Adversarial Networks
在生成对抗网络中,改进判别器是生成性能的关键之一。本文研究判别器的偏差,以及通过去偏是否会提高生成性能。经验证据表明判别器对图像的风格(例如纹理和颜色)很敏感。作为一种补救措施,提出特征统计混合正则化(feature statistics mixing regularization,FSMR),它鼓励判别器的预测对输入图像的风格保持不变。具体来说,在判别器的特征空间中生成原始图像和参考图像的混合特征,并应用正则化,使混合特征的预测与原始图像的预测一致。
广泛的实验证明这种正则化降低对风格的敏感性,并提高各种 GAN 架构的性能。此外,将 FSMR 添加到最近提出的基于增强的 GAN 方法中进一步提高了图像质量。
https://github.com/naver-ai/FSMR
三、发型编辑
5、HairCLIP: Design Your Hair by Text and Reference Image
发型编辑是计算机视觉和图形学中一个有趣且具有挑战性的问题。许多现有方法需要精心绘制的草图或掩膜作为编辑的条件输入,但是这些交互既不简单也不高效。为了将用户从繁琐的交互过程中解放出来,本文提出了一种新的交互发型编辑模式,可以根据用户提供的文本或参考图像单独或联合操作头发属性。
为此,在共享嵌入空间中对图像和文本条件进行编码,并通过利用对比语言-图像预训练 (CLIP) 模型强大的图像文本表示能力提出统一的头发编辑框架。通过精心设计的网络结构和损失函数,框架可以以一种解耦的方式执行高质量的编辑。大量实验证明了方法在操作准确性、编辑结果的视觉真实性和无关属性保留方面的优越性。
https://github.com/wty-ustc/HairCLIP
四、风格迁移
6、Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization
任意风格迁移 (Arbitrary style transfer,AST) 和域泛化 (domain generalization,DG) 是重要但具有挑战性的视觉学习任务,可以作为特征分布匹配问题。在高斯特征分布的假设下,传统的特征分布匹配方法通常匹配特征的均值和标准差。然而,现实世界数据的特征分布通常比高斯分布要复杂得多,仅使用一阶和二阶统计量无法准确匹配,而使用高阶统计量进行分布匹配在计算上是令人望而却步的。
这项工作首次提出通过精确匹配图像特征的经验累积分布函数 (empirical Cumulative Distribution Functions,eCDF) 来执行精确分布匹配 (Exact Histogram Matching,EFDM),提出的方法有效在各种 AST 和 DG 任务上得到验证。
https://github.com/YBZh/EFDM

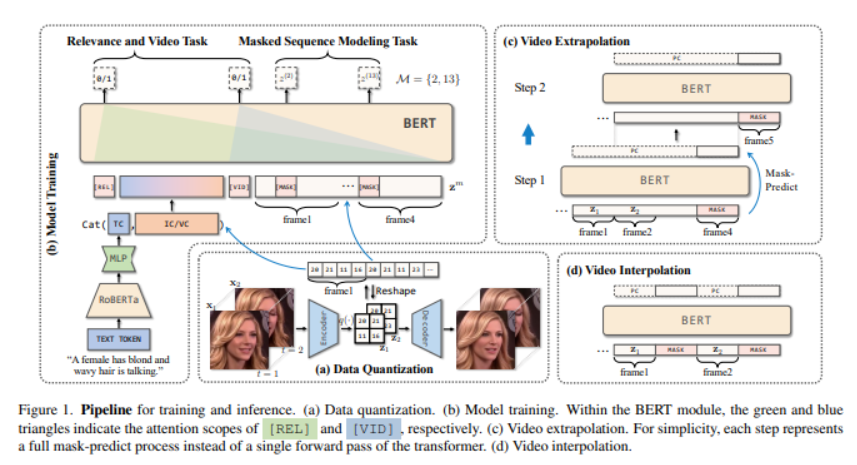
7、Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
大多数条件视频合成方法使用单一模态作为条件,这有很大的局限性。例如,以图像为条件的模型生成用户期望的特定运动轨迹是有问题的,因为没有提供运动信息的手段。相反,语言信息可以描述所需的动作,但不能精确地定义视频的内容。
基于联合或单独提供的文本和图像,这项工作提出一个多模式视频生成框架。利用视频量化表示的最新进展,并应用具有多种模态的双向transformer作为输入来预测离散的视频表示。为了提高视频质量和一致性,提出一种经过自学习训练的新视频token和一种用于采样视频token的改进掩码预测算法。引入文本增强以提高文本表示的鲁棒性和生成视频的多样性。框架可以包含各种视觉模式,例如分割掩膜、绘图和部分遮挡的图像。它可以生成比用于训练的序列长得多的序列。
此外,模型可以提取文本提示所建议的视觉信息,例如“图像中的一个物体正在向东北移动”,并生成相应的视频。对三个公共数据集和一个新收集的标有面部属性的数据集进行评估,实现了最好的生成结果。
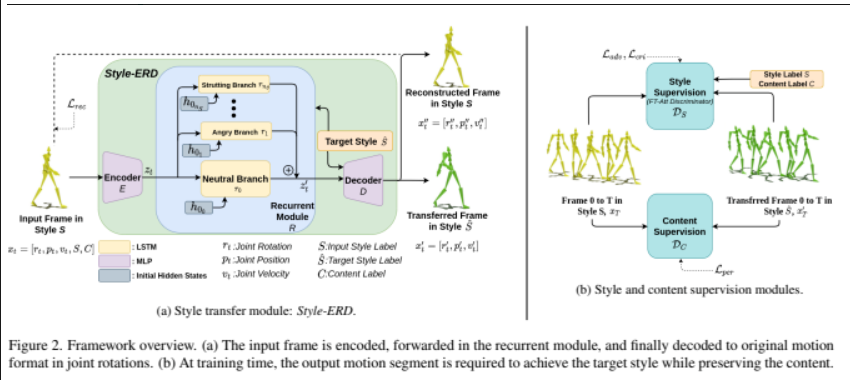
8、Style-ERD: Responsive and Coherent Online Motion Style Transfer
动作风格迁移是丰富角色动画的常用方法,通常在离线设置下分段处理运动。但对于在线动画应用程序,例如来自动作捕捉的实时头像动画,需要将动作作为具有最小延迟的流进行处理。
这项工作实现一种灵活、高质量的运动风格迁移方法Style-ERD,以在线方式使用Encoder-Recurrent-Decoder结构对运动进行风格化,以及结合特征注意和时间注意力的判别器。方法使用统一的模型将运动风格化为多种目标风格。虽然方法针对在线设置,但它在运动真实感和风格表现力方面优于以前的离线方法,并提高运行时效率。
文章出处登录后可见!