联邦学习 ——新型的分布式机器学习技术。
一、联邦学习开源框架
1、联邦学习框架(按架构分类)
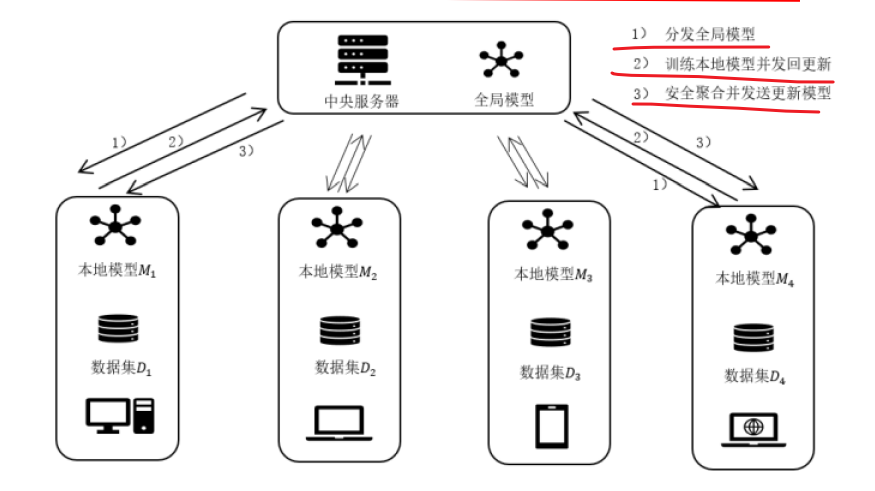
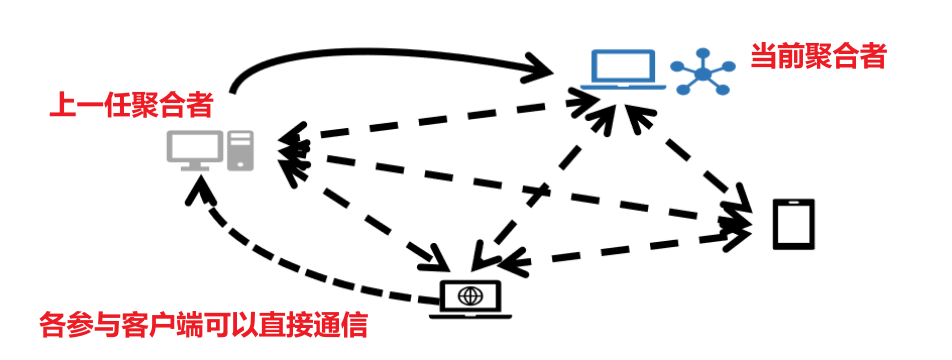
联邦学习常用的框架分为2种:中心化框架、去中心化框架,以中心化框架为主。
2、联邦学习的分类(按照参与方数据和特征分类)
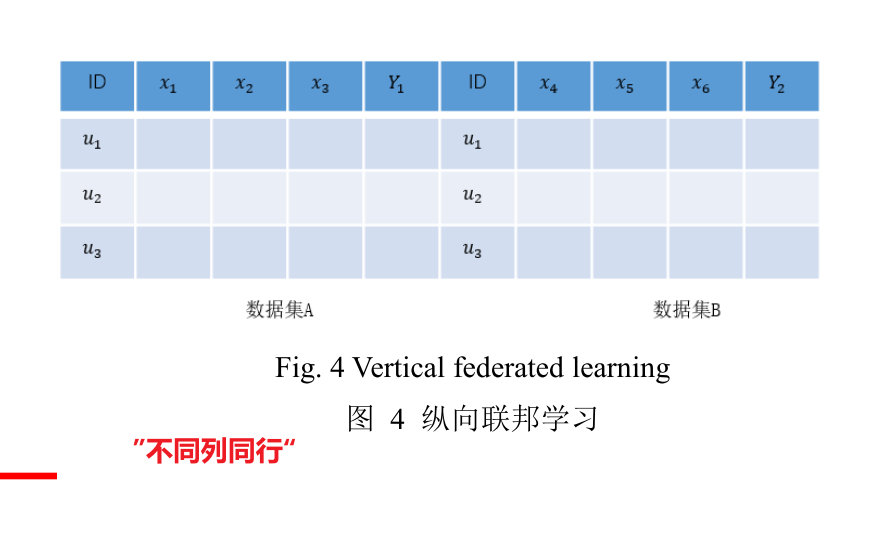
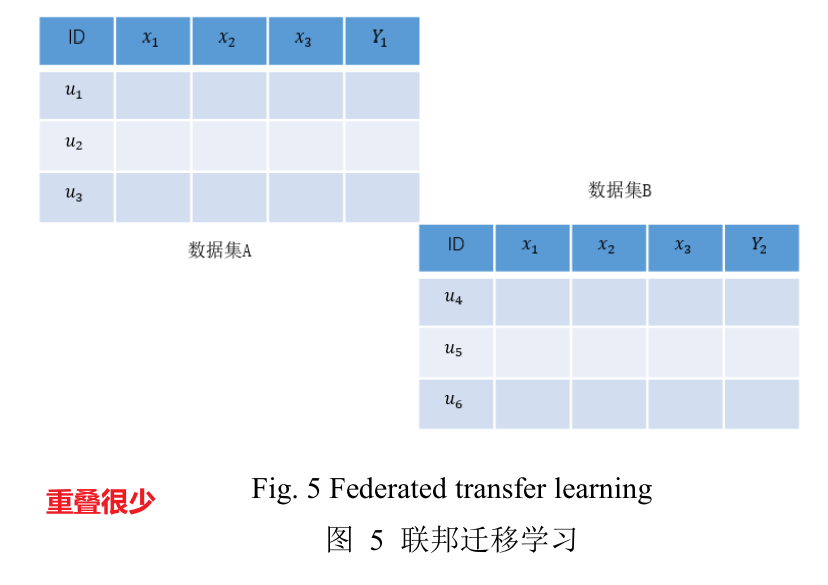
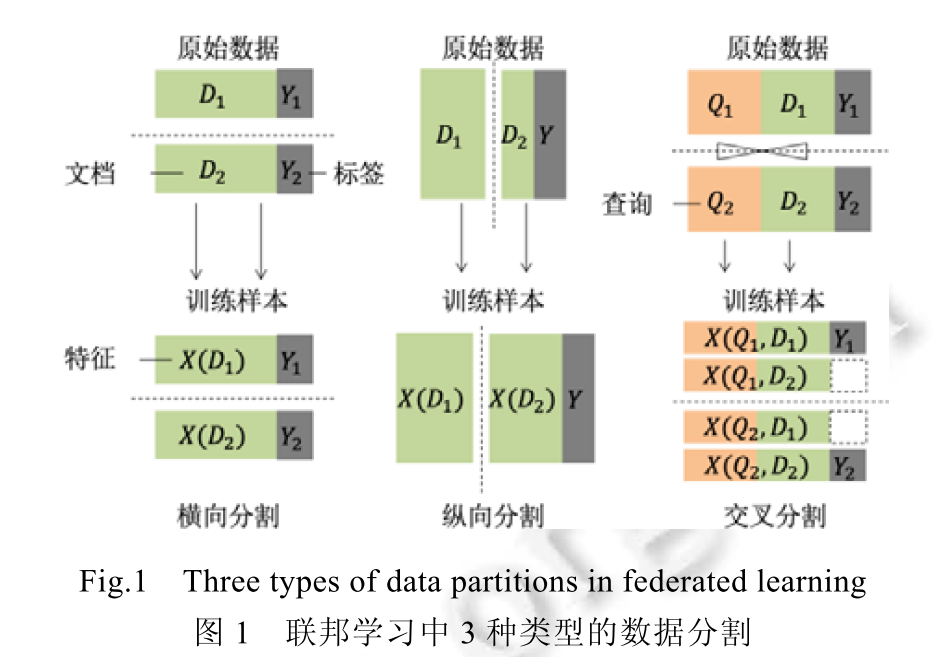
根据用户及数据集的特点,分为横向联邦学习、纵向联邦学习和迁移联邦学习。
横向联邦学习,用户重叠少、特征重叠多。如谷歌的分布式系统。(FedAvg)
纵向联邦学习,用户重叠多,特征重叠少。如学校的教务处和财务处(FATE,PaddleFL,FedML)
迁移联邦学习,用户和特征重叠都少。如不同区域的公司(FATE)

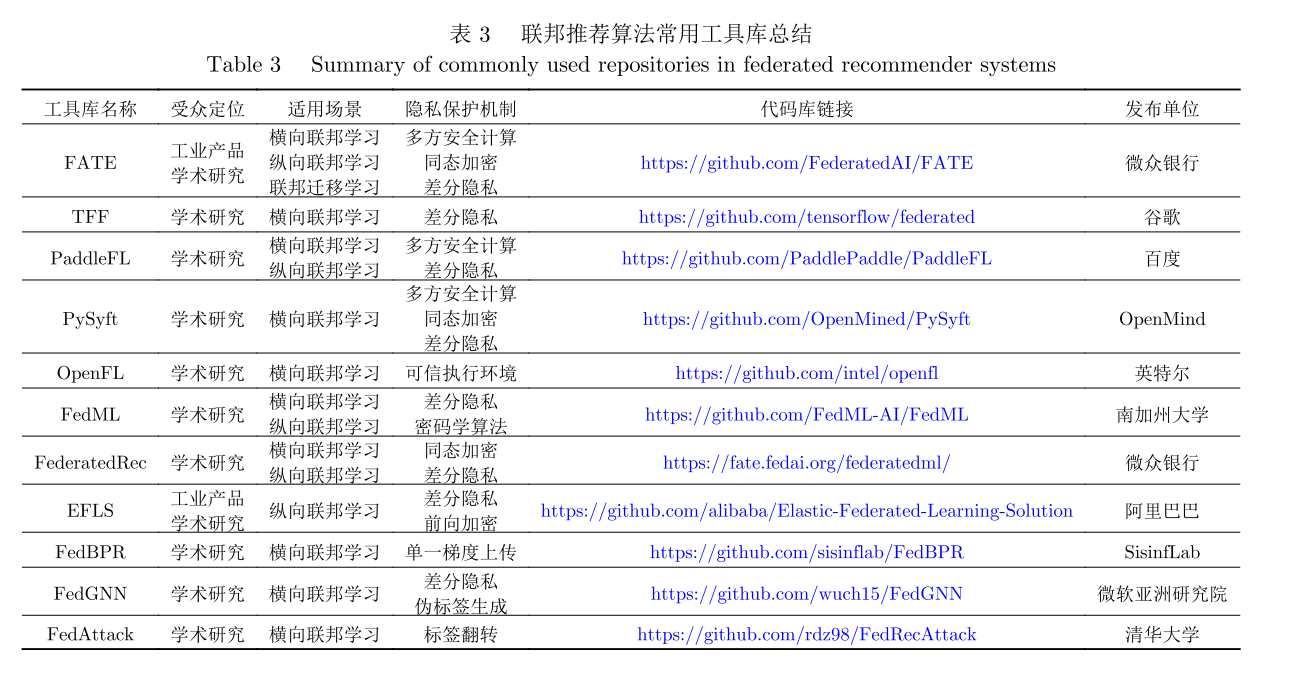
1)FATE项目
FATE项目使用了多方安全计算(MPC)以及同态加密(HE)技术构建底层安全计算协议,以此支持不同种类机器学习的安全计算,包括逻辑回归、基于树的算法、深度学习和迁移学习等。目前,FATE支持3种类型的联邦学习算法:横向联邦学习、纵向联邦学习和迁移联邦学习。
2)OpenMinded
OpenMinded开源的Pysyft 框架,较好地支持横向联邦学习。该框架同时支持TensorFlow,Keras,Py-torch。Pysyft提供了安全加密算子,数值运算算子及联邦学习,用户也可以高效搭建自己的联邦学习算法。相比较FATE,OpenMinded尚未提供高效的部署方案及serving端解决方案,相比于工业应用,更适合作为高效的学术研究、原型开发的工具。
3)TensorFlow Federated
开源的TensorFlow Federated框架,截止2019年12月已发布至0.11版本,较好地支持横向联邦学习。其中,可以通过Federated Learning (FL) API,与Tensor-Flowl Keras交互,完成分类、回归等任务。目前Ten-sorFlow Federated在安全加密算子上缺少开放实现,同时缺少对线上生产的完善支持。
3、联邦学习开源框架
1)PySyft
PySyft是用于安全和隐私深度学习的Python库,它在主流深度学习框架(例如PyTorch和TensorFlow)中使用联邦学习,主要借助差分隐私和加密计算等技术,对联邦学习过程中的数据和模型进行分离。
《A generic framework for privacy preserving deep learning》
我们的主要贡献如下:
- 首先,建立了一个用于worker间通信的标准化协议,以使联邦学习成为可能。
- 然后,开发了一个基于张量的链抽象模型,以有效覆盖运算(或编码新运算),例如在worker间发送/共享张量。
- 最后,提供了用这个新框架实现最近提出的差分隐私和多方计算协议的元素。
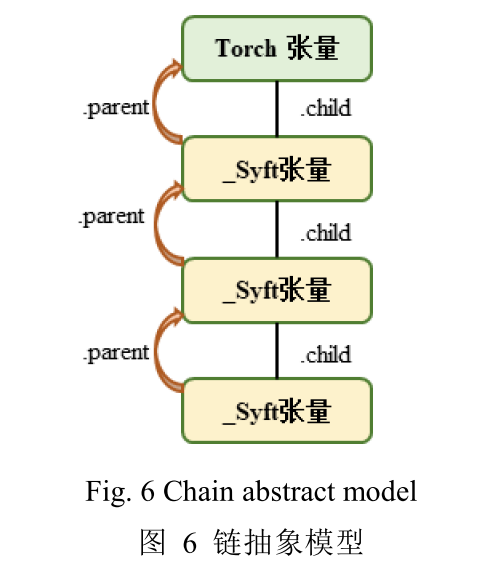
更加深入 https://blog.csdn.net/Yohuna/article/details/123789715
2)FATE
安全方面FATE采用密钥共享、散列 以及同态加密技术,以此支持多方安全模式下不同种类的机器学习、深度学习和迁移学习.
技术方面,FATE同时覆盖了横向、纵向、迁移联邦学习和同步、异步模型融合,不仅实现了许多常见联邦机器学习算法,还提供了一站式联邦模型服务解决方案,包括联邦特征工程、模型评估、在线推理、样本安全匹配等
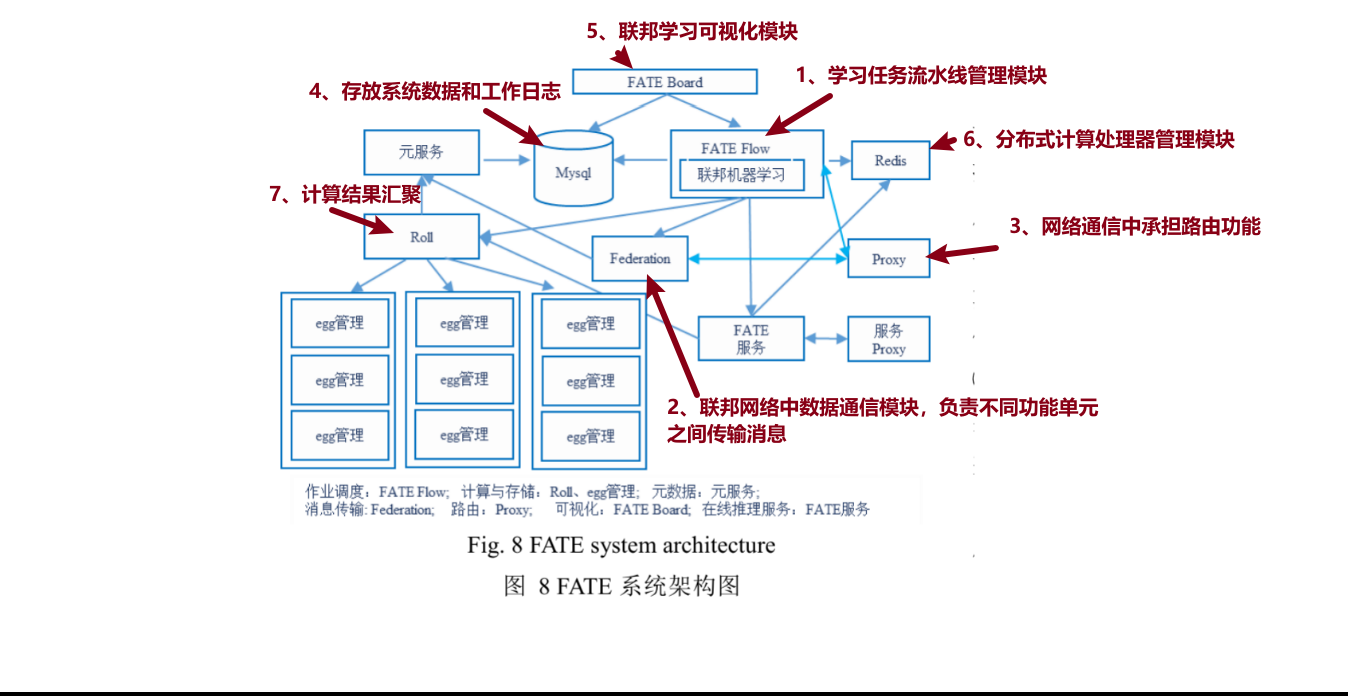
FATE的优势在于其具有丰富的算法组件,具有简单、开箱即用、易用性强的特点。作为目前唯一的一个可以同时支持横向联邦学习、纵向联邦学习以及联邦迁移学习的开源框架,FATE得到了业界广泛的关注与应用.同时,FATE还提供了一站式联邦模型解决方案,可以有效降低开发成本,相比于其他开源框架,在工业领域优势突出.
3)TFF
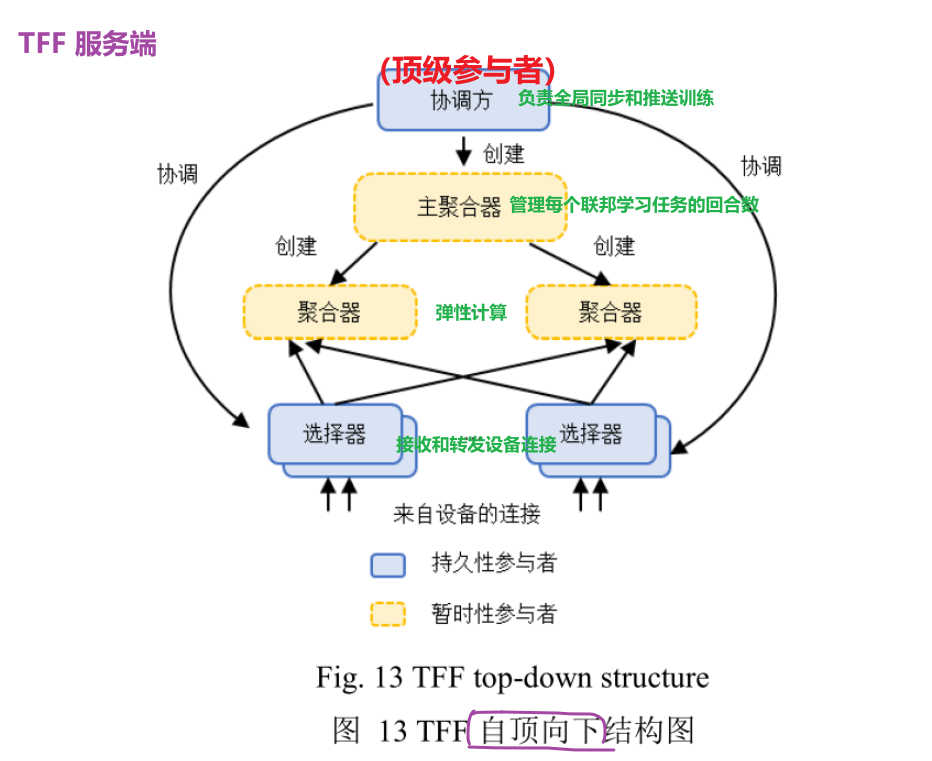
2019年,谷歌发布了基于TensorFlow构建的全球首个大规模移动设备端联邦学习系统,该系统用于在移动智能设备执行机器学习和其他分布式计算,旨在促进联邦学习的开放性研究和实验。
TFF的训练流程包括以下几步:
- (筛选设备)服务器从所有设备端筛选出参与该轮联邦学习任务的设备,为了不影响用户体验,筛选标准包括是否充电、是否为计费网络等因素.
- (服务端发送数据)服务器向训练设备发送数据,包括计算图以及执行计算图的方法.而在每轮训练开始时,服务器向设备端发送当前模型的超参数以及必要状态数据.设备端根据全局参数、状态数据以及本地数据集进行训练,并将更新后的本地模型发送到服务端.
- (服务端聚合更新模型)服务端聚合所有设备的本地模型,更新全局模型并开始下一轮训练.
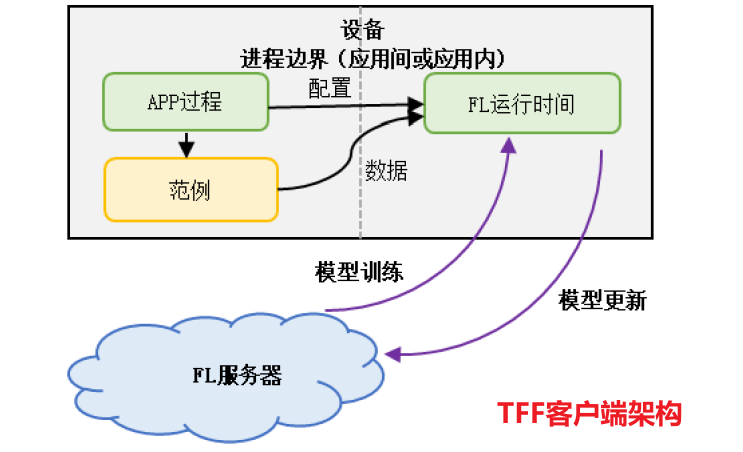
设备端的功能主要包括连接服务器,获取模型和参数状态数据,模型训练,模型更新
TFF构建了FL API和 FC API2个级别的接口来实现联邦学习模型训练的实验环境和计算框架。
- 联邦学习类型方面,TFF目前只支持横向联邦学习,尚未提供纵向联邦及迁移学习的方案;
- 模型方面,提供了FedAvg,Fed-SGD 等算法,同时也支持神经网络和线性模型;在计算范式方面,TFF支持单机模拟和移动设备训练,不支持基于拓扑结构的分布式训练;
- 在隐私保护机制方面,TFF采用差分隐私以保证数据安全.
- TFF的主要受众目标是研究人员和从业者,他们可以采用灵活可扩展的语言来表达分布式数据流算法,定义自己的运算符,以实现联邦学习算法和研究联邦学习机制.
4)Paddle FL
2019年,百度基于安全多方计算、差分隐私等领域的实践,开源了联邦学习框架 PaddleFL,旨在为业界提供完整的安全机器学习开发生态,PaddleFL提供多种联邦学习策略,因此该框架在不同领域都受到了广泛关注。
Paddle FL可以支持横向联邦和纵向联邦⒉种策略
- 对于横向联邦学习,其主要支持FedAvg, DPSGD,SECAGG等策略;
- 对于纵向联邦学习,其主要支持LR with PrivC和NN with MPC的神经网络.
借助于飞桨丰富的模型库和预训练模型,研究人员可以快速上手针对一些具体的垂直场景应用进行研究。
5) FedML
FedML是由美国南加州大学联合MIT.Stanford、MSU、UW-Madison、UIUC、腾讯、微众银行等众多高校与公司联合发布的一个联邦学习开源框架.FedML不但支持3种计算范例(单机模拟、基于拓扑结构的分布式训练和移动设备训练),还通过灵活且通用的 API设计和参考基准实现促进了各种算法研究,并针对非独立同分布( non-independentidentically distributed, Non-IID)数据设置了精选且全面的基准数据集用于公平比较
FedML旨在为在任何规模的任何地方运行的构建简单而通用的api
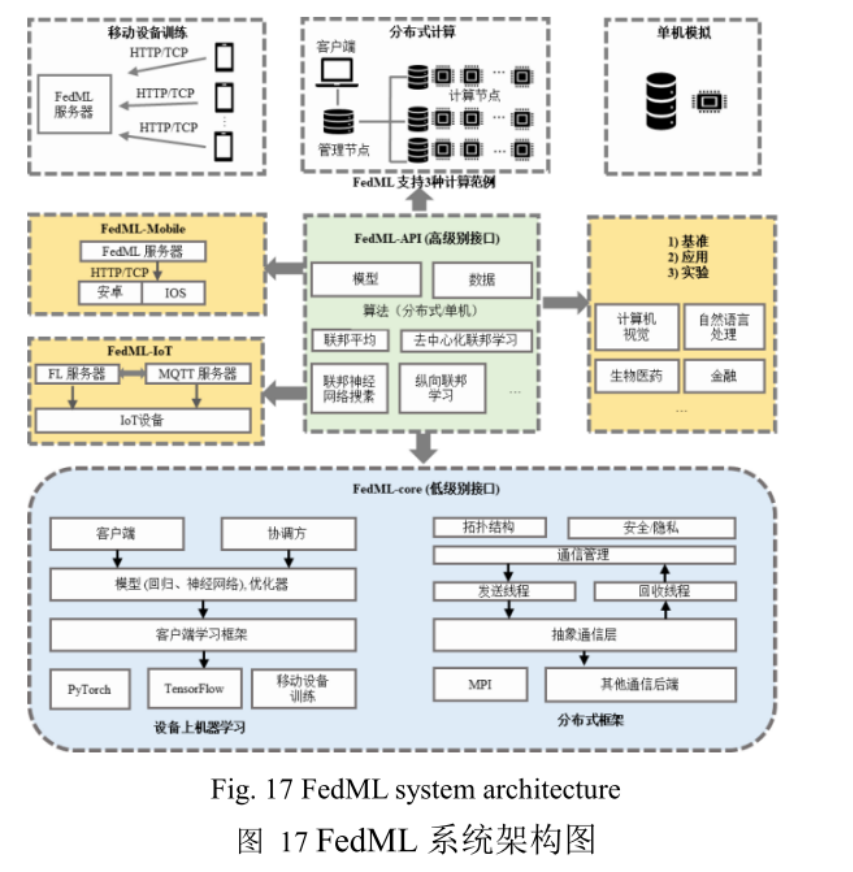
默认采用MPI通信,具体通信过程:
- 服务器启动,发送初始化信息给客户端;
- 客户端收到服务器端发送的消息,触发handler 函数;
- 训练方进行本地模型的训练;
- 每轮训练结束后,将训练好的参数放入发送队列;
- 发送线程将队列中的数据传回服务器;
- 服务器收到客户端端发送的消息,触发handler函数;
- 进行全局模型参数的更新;
- 将更新后的全局参数传入发送队列进行下发,开始下一轮迭代训练.
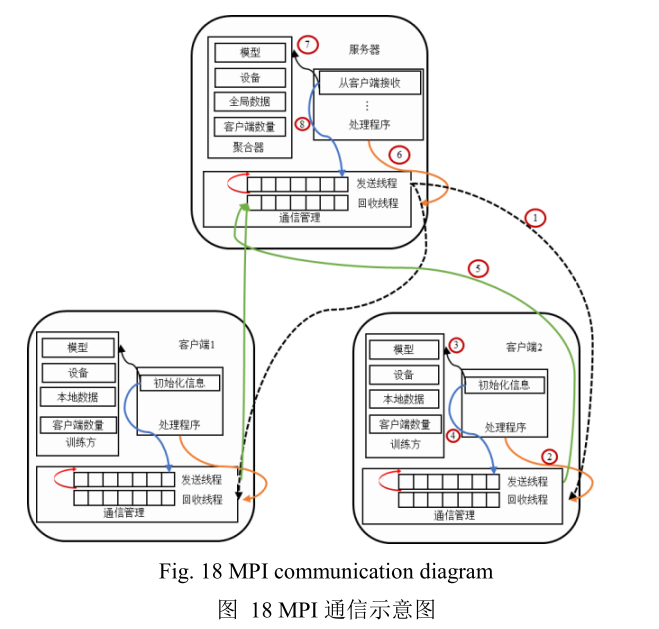
此外,FedML还支持用户自定义通信协议.如果需要使用不同的通信协议,用户只需替换底层的通信管理即可.
6) Flower
Flower是由英国牛津大学在2020年发布的一款联邦学习框架,其优点在于Flower 可以模拟真实场景下的大规模联邦训练.且基于其跨平台的兼容性、跨设计语言的易用性、对已有机器学习框架的支持以及抽象的框架封装,用户可以快速高效搭建所需的联邦学习训练流程.Flower综合计算资源、内存空间和通信资源等因素,高效实现了移动和无线客户端下异构资源的使用.
Flower包含Flower客户端、Flower服务端、联邦策略、Flower协议、Flower数据集、Flower基准、Flower工具7部分
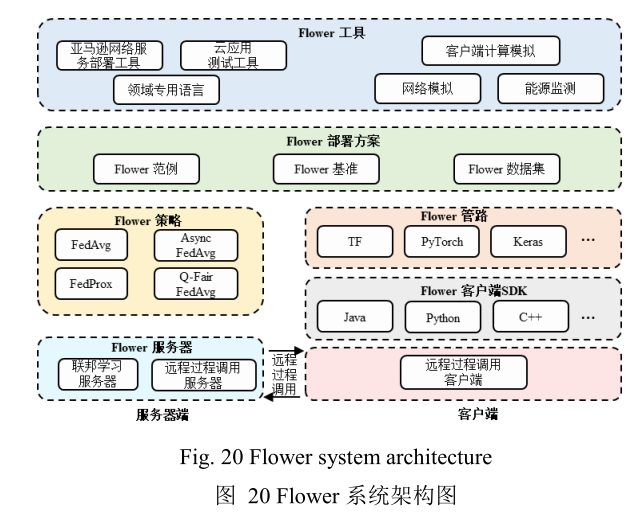
Flower主要提供可复现实验,机器学习算法,网络扰动,跨平台接入,大规模接入5个功能模块
-
可复现实验
一个完整的联邦学习框架需要多个组件来实现,Flower中提供了一套可靠、成熟的组件来实现这些部分,研究人员可以在一套组件下快速进行实验验证.此外,已有算法库可以让研究人员快速的与现有方案进行对比.
-
机器学习算法
联邦计算的方式弥补了传统单机模式下的不足,但是仍旧有许多的ML算法尚未迁移过来.Flower通过对现有ML框架的链接,允许用户在现有ML代码库的基础之上将ML算法快速应用于联邦模型的训练中.
-
网络扰动
通信网络贯穿联邦学习的整个始末,在现实场景中,网络通信状态直接会影响到模型训练的效率和结果.Flower中提供了对网络带宽约束的功能,方便量化网络波动对整个联邦学习过程的影响.
-
跨平台接入
Flower中提供了对不同架构的支持,因此可以测试异构环境下不同算法的表现.此外,在设计上抽象类的设计,使得 Flower对于特定编程语言的依赖降到最低.
-
大规模接入
在真实场景下的联邦学习训练需要大量的设备进行参与.然而,在实验场景中往往不会以真实的参与规模进行设计,对于大规模设备参与的可扩展性有待考察.Flower在设计之初就考虑到了大量并发连接客户机的场景,具有很好的可扩展性.
4、其他联邦学习框架
除了目前业内较常用的几款开源框架外,其他的公司也根据自己的业务场景设计、开源了其框架.其中开源框架包括Fedlearner,FedNLP, FederatedScope;闭源框架有ClaraFL和蜂巢
1)Fedlearner
字节跳动在 2020年初开源了联邦学习框架Fedlearner,该框架可以支持各类联邦学习模式,包括模型管理、训练任务管理等模块.与微众银行等开源框架不同,Fedlearner 实行产品化工作,将模块部署于平台侧和广告主侧,注重于在推荐行业开展联邦学习.
2)FedNLP
南加大Lin等人开源了首个以研究为导向的自然语言处理联邦学习框架( federated learning natural language processing,FedNLP) .主要由应用程序层、算法层和基础架构层3层组成.
3)FederatedScope
FederatedScope是由阿里巴巴达摩院研发、开源的框架.该框架采用事件驱动的编程范式,用于支持现实场景中联邦学习应用的异步训练.并借鉴分布式机器学习的相关研究成果,集成了异步训练策略来提升训练效率.具体而言,FederatedScope 将联邦学习看成是参与方之间收发消息的过程,通过定义消息类型以及处理消息的行为来描述联邦学习过程.
4)闭源ClaraFL
英伟达推出了一款主要应用目标为医院和医疗机构的联邦学习框架ClaraFL .该框架的特点是客户端可以部署于面向边缘的英伟达服务器上,在本地进行模型训练,并通过联邦学习的方式实现数据交流,从而与多参与方共同训练出更精准的全局模型.ClaraFL可以将患者数据保存在医院内部,实现隐私保护的同时,帮助医生进行高速而准确的诊断.由于单个医疗机构的数据量有限,基于ClaraFL进行联邦学习可以有效汇总海量医疗数据,打破数据壁垒,提高医疗救治水平.
5)闭源蜂巢
平安科技推出了一款主要应用于物流行业的联邦智能框架“蜂巢”,该框架的特点是为支持国密级加密的企业框架,采用了国密SM2、国密SM4以及差分隐私和同态加密等不同的加密方式,以满足不同场景所需的不同保密级别.
5、不同联邦学习框架的对比

学习计算范例
单机模拟、拓扑、移动设备端训练
联邦学习关于隐私保护
联邦学习数据安全隐患会遇到 中央服务器、单方数据污染、传输问题、数据泄露
二、支持数据隐私保护的一个联邦深度神经网络模型
针对机器学习中数据隐私泄露的问题,一些隐私保护的方法被提出,主要可以分为以安全多方计算、同态加密为代表的基于加密的隐私保护方法和以差分隐私为代表的基于扰动的隐私保护方法.
安全多方计算:两个或者多个持有私有数据的参与者通过联合计算得到输出,并且满足正确性、隐私性、公平性等特性
三、支持数据隐私保护的一个联邦深度神经网络模型
《A survey on security and privacy of federated learning》
1、联邦学习领域中的安全威胁有哪些
-
投毒攻击(Poisoning):在联邦学习中,由于每个客户端都能够接触到模型参数以及训练数据,因此一些恶意的客户端很可能会将被篡改的数据或权重发送给服务器,从而影响全局模型。投毒攻击分为三类,分别是数据投毒(Data Poisoning),模型投毒(Model Poisoning),数据修改(Data Modification)
-
推理攻击(Inference)
-
后门攻击(Backdoor attacks)
-
基于生成对抗网络的攻击(GANs)
-
系统停机(System disruption IT downtime):停机时间可能是一种精心策划的攻击,目的是从FL环境中窃取信息
-
恶意的服务器(Malicious server)
-
通信瓶颈(Communication bottlenecks)
-
搭便车攻击(Free-riding attacks):简单来说就是有些客户端想要做伸手党
-
不可用性(Unavailability):客户端在训练过程中可能会掉线
-
窃听(Eavesdropping):攻击者可能会从不可靠的信道中窃取到数据
-
违反数据保护法(Interplay with data protection laws)
2、联邦学习领域中隐私威胁有哪些
成员推断攻击(Membership inference attacks):推理攻击是一种推断训练数据细节的方法,这种攻击通过检查训练数据集上是否存在特定的数据来获取信息。
无意的数据泄露与通过推理重构(Unintentional data leakage & reconstruction through inference):数据泄露的危害以及恶意的客户端通过全局模型来重构其他客户端的训练数据
基于生成对抗模型的推断攻击(GANs-based inference attacks)
3、有哪些方法来缓解这些威胁以及如何提高联邦学习的隐私保护能力?
差分隐私(Differential Privacy):具体方法是对样本进行添加噪音,并尽量使总体样本的统计性质(均值,方差等)保持不变
安全多方计算(Secure Multi-party Computation):多方联合计算一个函数,且各方都不泄露各自的数据。
混合(Hybrid):多技术结合
验证网络(VerifyNet):验证服务器端是否是可靠的
对抗训练(Adversarial training):从训练阶段开始就尝试攻击的所有排列,使FL全局模型对已知的对抗性攻击具有鲁棒性

四、基于隐私保护的联邦推荐算法
《基于隐私保护的联邦推荐算法》
问题:如何在保证用户隐私与数据安全的前提下分析用户行为模式进而推荐用户可能感兴趣的物品
传统的隐私保护推荐算法主要采用差分隐私等机制添加数据扰动[20]或者利用加密的方式(比如同态加密与安全多方计算)实现对于个人敏感信息的隐私保护. 然而添加扰动的方法需要严格的数学假设并且不可避免的对原始数据引入偏差, 而加密的方式虽然能够实现对于原始数据的无损保护, 但加密操作往往需要更大的计算量最终使得模型的实时性大打折扣. 值得一提的是, 上述传统隐私保护推荐算法需要将个人数据收集到中心服务端进行存储与训练, 因此在原始数据传输等过程中仍然存在隐私泄露与安全威胁的问题. 另外, 由于上述隐私与安全问题的担忧造成了多参与方不能安全高效的进行数据共享, 最终导致数据孤岛现象进而影响整体模型的预测性能.
1.1 传统推荐方法
传统协同过滤算法:通过将用户的历史行为信息转化为用户—项目行为矩阵的方式进行存储训练,并且传统协同过滤方法能够擅长挖掘用户对物品直接近邻的属性特征.
根据其运用学习范式的不同可分为基于领域的推荐方法和基于模型的推荐方法两大类.
基于领域的方法侧重于寻找当前用户(物品)的最近邻,然后基于近邻做出物品推荐.
基于模型的方法利用机器学习技术将整个用户—项目评分信息或者部分数据作为训练集来产生预测模型,然后使用训练好的模型为用户提供个性化推荐
1.2 基于深度学习的推荐算法
根据深度学习模型自身特性以及融合到推荐场景中附加信息的不同,主要分为基于自编码器的推荐算法、基于多层感知机的推荐算法、基于卷积神经网络的推荐算法、基于循环神经网络的推荐算法以及基于图神经网络的推荐算法.除了上述介绍的单一深度网络模型应用于推荐任务外,集成多种深度模型的长处可以得到性能表现更加优良的集成模型.
尽管上述提及的深度学习推荐模型能够在预测性能方面得到显著提升,但有相关的文献表明推荐模型在多种不同的攻击类型中存在一定的脆弱性,最终给用户的敏感隐私信息带来严重的安全威胁.
1.3 基于隐私保护的推荐算法
根据所使用防御机制的不同大致分为基于匿名化的隐私保护方法、基于数据扰动的隐私保护方法、基于密码学的隐私保护方法、基于对抗学习的隐私保护方法与基于联邦学习的方法等
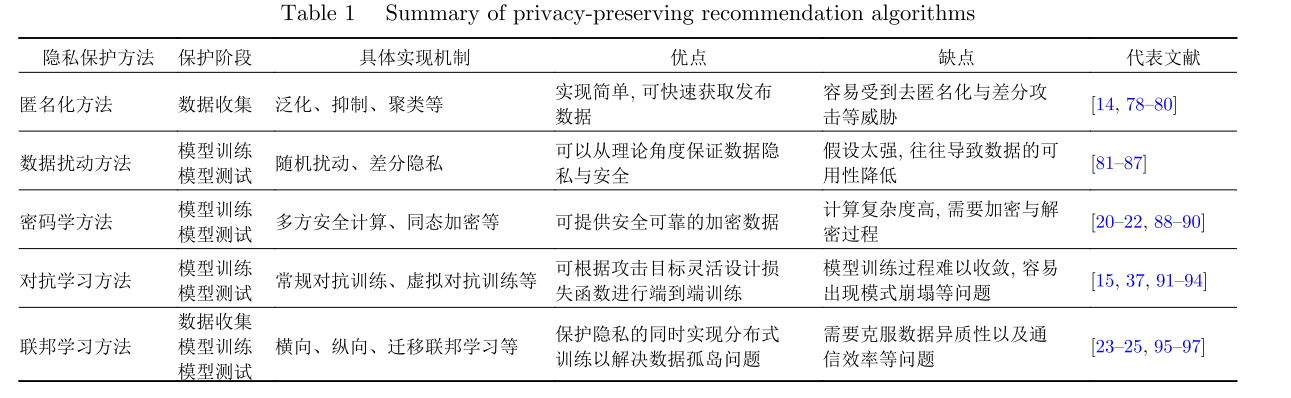
2、基于联邦学习的推荐系统
当前主流推荐模型的训练框架首先收集所有用户的个人信息到集中存储的中心服务端,然后在中心服务端统一训练推荐模型(其中大致经历召回、粗排、精排以及重排序阶段),最后生成对于每个用户的个性化推荐结果.然而,用户上传的行为数据往往包含大量的个人敏感信息,因此集中式训练的模式会存在潜在的隐私泄露风险与安全隐患。另外,由于用户对于个人隐私的担忧,大多数人们不乐意将自己的原始数据进行上传,因此导致集中式的训练模式缺乏足够的训练数据而使得模型预测性能下降.基于以上两种原因,推荐系统亟需一种能够保护用户个人原始数据同时能够确保推荐算法预测性能的新颖学习框架.
联邦学习作为一种保护隐私的分布式机器学习框架,其通过将用户个人原始数据保留在本地,利用服务端与客户端的中间参数进行协同优化,最终在保护用户个人隐私的同时保障了机器学习模型的预测性能.推荐算法为了实现保护用户隐私的需求,自然的想法是将集中式学习框架迁移到联邦学习范式的场景中,于是基于隐私保护的联邦推荐系统得到了关注。
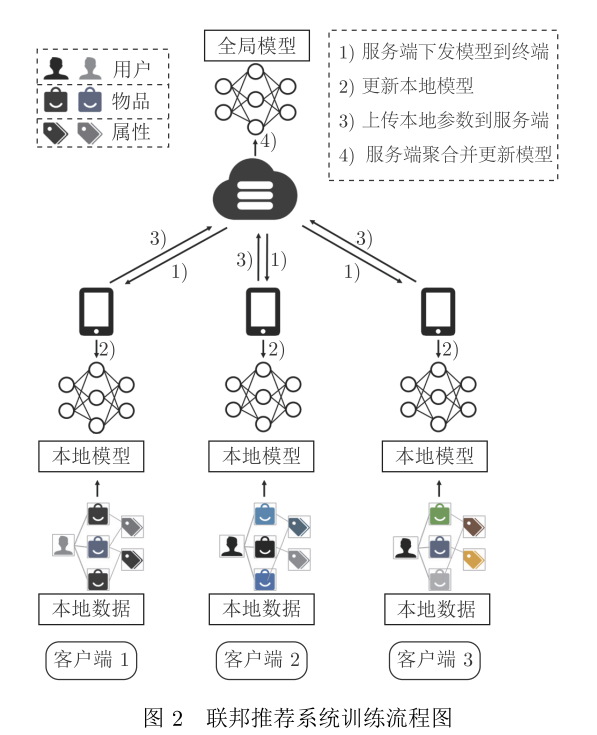
- 如何有效挖掘符合实际场景的异质数据
- 如何挑选有代表性的本地模型参与训练
- 如何在服务端进行更加有效的参数聚合
- 如何减少通信成本并保证模型收敛
- 如何实现参数传输过程中的隐私保护问题
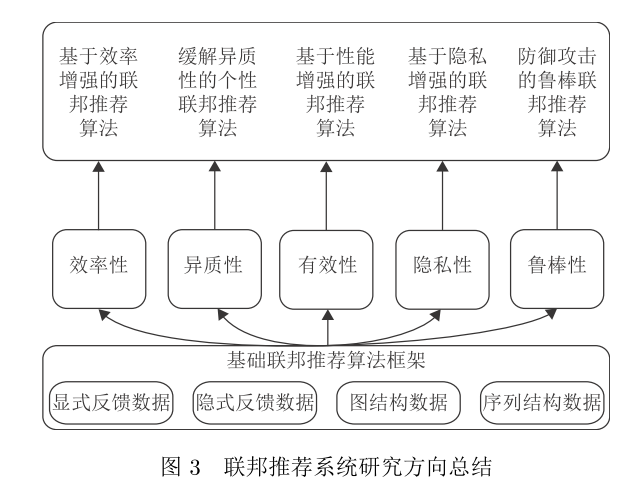

2.1 基于隐私增强的联邦推荐算法
由于联邦学习框架可以保留用户的个人行为数据在本地而通过模型中间参数进行协同优化,因此通过将集中式训练的推荐模型迁移到联邦学习的框架上可以从根源上保护用户行为信息的隐私问题.然而,最新的研究文献表明传输模型的梯度信息仍然可能遭受逆向攻击进而泄露用户隐私以及模型的结构信息.不同于传统的机器学习任务,由于在推荐系统场景中存在大量的用户个人敏感行为信息以及受保护的用户属性信息,因此在联邦学习框架基础上增强隐私保护能力是当前推荐系统领域研究的重要课题.
与常规联邦学习模型增强隐私保护能力的研究路线类似,实现隐私增强的联邦推荐算法的主要途径是在基础框架下引入数据扰动以及密码学等技术,以保证数据安全运行的同时实现精准推荐的目标.
显式评分数据在参数优化过程中容易被服务端识别进而造成用户信息泄露的问题, Lin等提出基于数据扰动的隐私保护联邦推荐算法FedRec,该方法提出了两种简单且有效的数据扰动机制,即用户平均方法和混合填充方法,来生成伪交互物品集合以及对应的评分集合R,通过在参数更新过程中上传用户真实的交互集合I以及伪交互集合T以此提高梯度信息在传输过程中的隐私保护能力.
基于隐式反馈数据的联邦推荐系统隐私泄露问题,Minto等提出利用差分隐私机制等数据扰动技术来保护用户数据安全性的算法(LDP-FedRec),通过利用匿名化以及扰动机制可以实现不被服务端轻易识别进而保护用户隐私的目标.
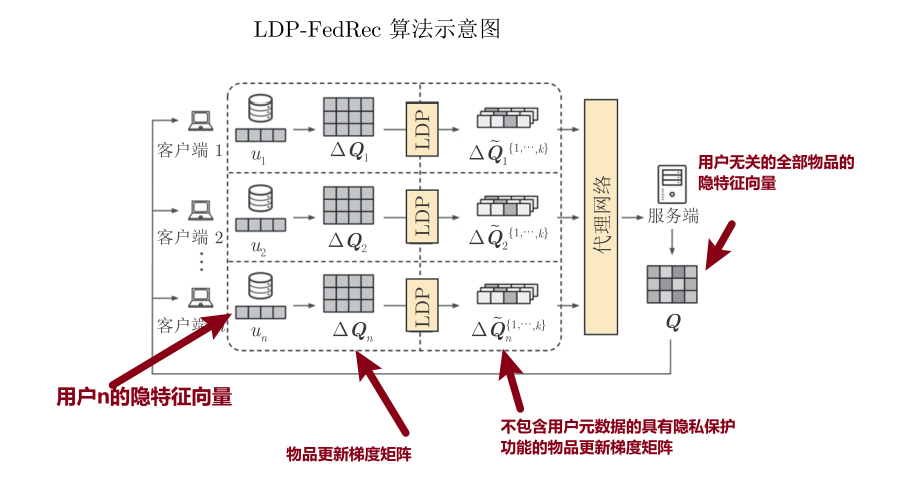
除了利用差分隐私等扰动机制来保护参数外,利用密码学等技术可以实现严格的数据隐私保护能力.一种利用同态加密技术来保护梯度信息不被泄露的方法.具体地,首先生成公开秘钥与私有秘钥.公开密钥可以被任何参与者共享,而私有秘钥只在用户间进行识别;然后进行模型参数的初始化工作,即在服务端初始化物品矩阵以及在每个用户端进行用户特征向量的初始化工作;最后执行在同态加密环境下的矩阵分解操作,以此实现保护模型的中间参数不被恶意第三方攻击的目标
为增强联邦学习推荐系统的隐私保护能力,当前的方法主要采用同态加密以及差分隐私机制对中间的计算结果进行保护.然而,前者带来了额外的通信和计算成本,后者由于严格的数学假设不可避免的对模型的准确性有所影响.因此以上方法不能同时满足推荐系统的实时反馈和准确的个性化需求.为此Yang 等12提出了一种新颖的联邦推荐框架.该方法可以在不牺牲效率和有效性的前提下保护联邦推荐系统中的数据隐私问题.具体地,该算法利用秘密共享技术来结合联邦矩阵分解的安全聚合过程.此外,该算法还引入了个性化掩码的新思想,并将其应用于所提出的联邦掩码矩阵分解框架中.个性化掩码机制可以进一步提高模型的训练效率以及模型的预测精度.通过实验结果展示了所设计的模型在不同的真实数据集上的优越性.此外,Lin等利用虚假标记以及秘密共享技术来修改客户端上传到服务器的参数数据,通过该机制实现了在不损失模型准确性的前提下保护用户隐私的目标.该算法是一种通用的跨客户端设备的联邦学习框架,可以方便地迁移到评分预测、物品排序以及序列化推荐场景.
五、面向企业数据孤岛的联邦排序学习
随着数据隐私保护日渐受到人们重视,从多个数据拥有者(如企业)手中收集数据训练排序学习模型的方式变得不可行.各企业之间数据被迫独立存储,形成了数据孤岛
面向企业数据孤岛联邦学习的目标是:在保护各企业数据隐私的情况下,训练一个有效的全局模型。
半监督学习用于只有部分数据带标签
联邦场景下的排序学习问题:给定有n个企业的联邦和一个特征提取函数,让各企业协同训练一个全局的排序模型。每个企业拥有一个同其他企业合作产生的无标签数据集和自身持有的带标签数据集。
- 首次定义了企业数据孤岛场景下的联邦排序学习问题,并提出相应的解决框架,进一步指明了其两大研究挑战,即交叉特征生成与缺失标签处理.目前,尚未有任何面向企业数据孤岛的联邦排序学习相应研究成果;
- 为了应对交叉特征生成的挑战,本文提出了基于略图(sketch)数据结构的交叉特征生成算法,并在理论上证明了算法具有的隐私性与结果精度的保证;
- 为了应对缺失标签处理的挑战,本文提出了一种半监督联合训练算法,通过交互的标签生成器,来高效与准确地推断交叉样本对应的缺失标签;
总结大量现有工作Kairouz P,MeMahan HB, Avent B, et al. Advances and open problems in federated learning.CoRR,2019, abs/1912.04977.
据孤岛场景下的联邦排序学习问题,并提出相应的解决框架,进一步指明了其两大研究挑战,即交叉特征生成与缺失标签处理.目前,尚未有任何面向企业数据孤岛的联邦排序学习相应研究成果;
- 为了应对交叉特征生成的挑战,本文提出了基于略图(sketch)数据结构的交叉特征生成算法,并在理论上证明了算法具有的隐私性与结果精度的保证;
- 为了应对缺失标签处理的挑战,本文提出了一种半监督联合训练算法,通过交互的标签生成器,来高效与准确地推断交叉样本对应的缺失标签;
总结大量现有工作Kairouz P,MeMahan HB, Avent B, et al. Advances and open problems in federated learning.CoRR,2019, abs/1912.04977.
文章出处登录后可见!