首先,本博客以【PyTorch】深度学习实践之 加载数据集Dataset and Dataloader、【PytorchLearning】构建自己的数据集、深度学习之MiniBatch、PyTorch深度学习实践 第八讲—Mini-batch数据集、【零基础】神经网络优化之mini-batch、批量梯度下降法(BGD)、随机梯度下降法(SGD)和小批量梯度下降法(MBGD)、Dataset的简单构建、系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)、Pytorch之Dataloader参数collate_fn研究几篇博客作为参考,受益颇大。
目录
1、Dataset与DataLoader(加载数据的两个工具类)
在Pytroch中创建数据集主要使用两个类:Dataset和DataLoader。
(1)Dataset既是一个集成数据集的库(例如MNIST、CIFAR都集成在Datasets中),又是一个用来表示数据集的抽象类(不能直接实例化,只能继承)。继承Dataset的类需要重新init()、getittem()和len(),分别是为了加载数据集、获取数据索引和获取数据总量。【构造数据集,数据集应该支持索引,能够用下标操作快速把数据拿出来】
(2)DataLoader本质上就是一个 iterable(内部定义了 __ iter __ 方法),通过读取Datasets中的数据,组装成一个batch后返回一个tensor。DataLoader可实例化对象。【主要目标:用来拿出一个mini-batch来供训练时加速使用】
总而言之,Dataset是构建Dataloader的重要实例参数之一。
2、Mini-batch优点
Mini-batch是一个一次训练数据集的一小部分,并不是整个训练集的技术。
优点:(1)使得内存较小、不能同时训练整个训练集的电脑也可以训练模型
(2)从运算角度来说是低效的,因为不能在所有样本中计算loss,但是这点代价比起不能运算模型要好的。Mini-batch跟随机梯度下降(SGD)结合在一起作用蛮大。方法:在每一代训练前,对数据进行随机混洗,然后创建mini-batches,对每一个mini-batch用梯度下降训练网络权重。因为这些batches是随机的,你其实是在对每个batch做随机梯度下降(SGD)。
3、梯度下降几种选择:
- 梯度下降(Batch Gradient Descent,BGD(批量梯度下降)):一次将所有图片输入到网络中学习
- 随机梯度下降(Stochastic Gradient Descent,SGD):与梯度下降对应的另一种极端方法,每次只输入一张图片进行学习
- Min-Batch梯度下降(Mini-Batch Gradient Descent,MBGD(小批量梯度下降)):对批BGD和SGD的一个折中办法。思想:每次迭代使用batch_size个样本(随机选择的一部分)对参数进行更新。常用在深度学习中进行模型的训练
批量梯度下降,BGD 优点:
- 一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
- 由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在地方向。当目标函数是凸函数时,BGD一定能够得到全局最优。
缺点:
- 当样本数目m很大时,每迭代一步都需要对所有样本计算,训练过程很慢。从迭代的次数上来看,BGD迭代的次数相对较少。
随机梯度下降,SGD 优点:
- 由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
- 准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
- 可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
- 不易于并行实现。
小批量梯度下降,MBGD 优点:
- 通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
- 每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代3000次,远小于SGD的30W次)
- 可实现并行化
缺点:
- batch_size的不当选择可能会带来一些问题。具体见这篇博客:批量梯度下降法(BGD)、随机梯度下降法(SGD)和小批量梯度下降法(MBGD)
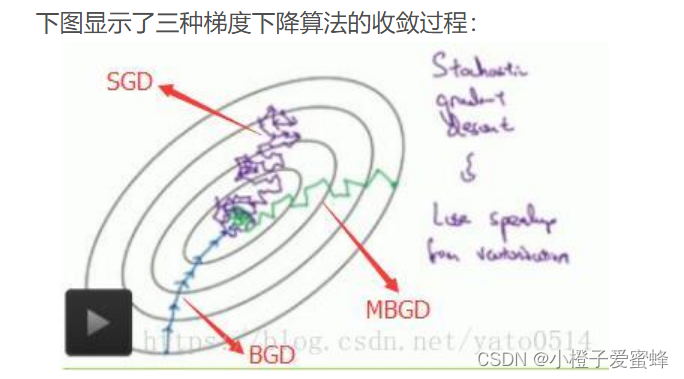
注:为什么SGD收敛速度比BGD快???(从迭代次数来看,SGD迭代地次数较多,在解空间地搜素过程也挺盲目。)

4、Epoch、Batch-Size,Iteration
Epoch【时期】:对所有样本进行一次前向传播和后向传播(通俗点,一个Epoch就是将所有训练样本训练一次的过程)
Batch-size:进行一次前向传播和反向传播所用的样本数量
Iteration【一次迭代】:数据集中有多少个batch,例如1000个样本batch-size为100,那么iteration为10(这个概念跟程序语言中的迭代器相似)
Batch【批/一批样本】:当一个Epoch的所有训练样本数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练
Epoch
使用训练集的全部数据对模型进行一次完整训练【一代训练】
【(1)使用有限数据集,且使用一个迭代过程即梯度下降来优化学习过程,所以仅仅更新一次epoch是不够的。(2)epoch数量增加=>神经网络中的权重的更新次数增加=>曲线从欠拟合变得过拟合。 】
Batch
使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新【一批数据】
Iteration
使用一个Batch数据对模型进行一次参数更新的过程【一次训练】
例子如下:
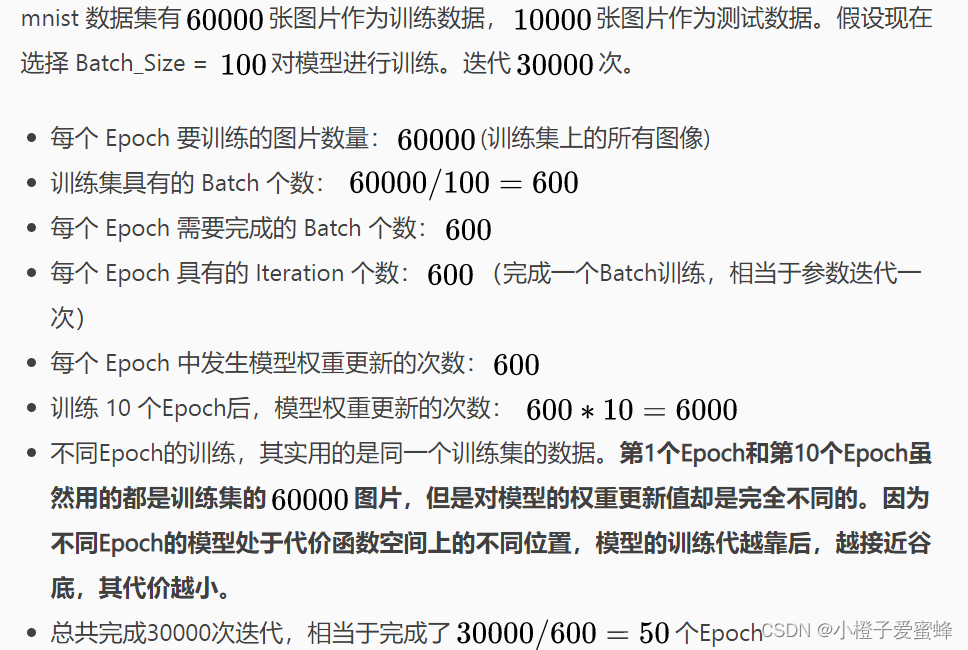
5、定义Dataset
Dataset类是Pytorch中所有数据集加载类中应该继承的父类,其中父类中的两个私有成员函数必须被重载,否则将会触发错误提示。
(1)init()是初始化函数,之后我们可以提供数据集路径进行数据的加载
(2)getitem()帮助我们通过索引找到某个样本
(3)len()帮助我们返回数据集大小
import torch
import numpy as np
from torch.utils.data import Dataset # Dataset是抽象类,不能被实例化,只能继承
from torch.utils.data import DataLoader #帮助我们加载数据
class ImageDataset(Dataset): # 【ImageDataset继承Dataset】
# 【初始化函数,之后可以提供数据集路径进行数据的加载】
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
# 【帮助返回数据集大小】(将返回的值除以batch_size的结果就是每一轮epoch中需要迭代的次数)
def __len__(self):
return len(self.dataset)
# 【使得读取的数据由索引,通过索引找到某个样本】
def __getitem__(self, index):
img_path, pid, camid = self.dataset[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
return img, pid, camid, img_path
注: 重点是 getitem函数,getitem接收一个index,然后返回图片数据和标签,这个index通常指的是一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息。
6、DataLoader的使用,对数据进行分组
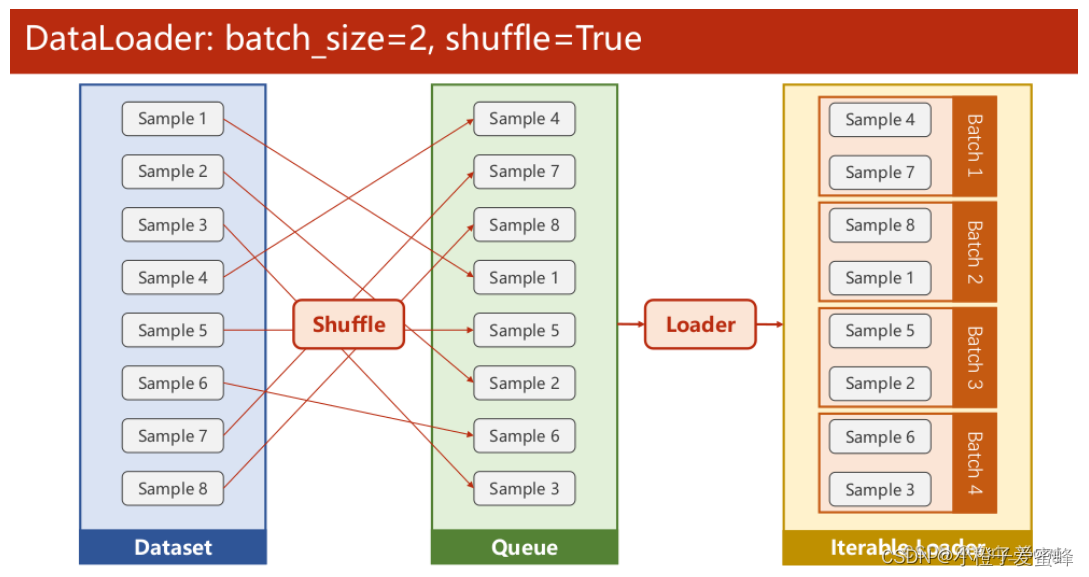
torch.utils.data.DataLoader(): 构建可迭代的数据装载器, 我们在训练的时候,每一个for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据的。它的参数有很多,dataset、batch_size、shuffle、sampler、batch_sampler、num_workers、collate_fn、pin_memory、drop_last(当样本数不能被batch_size整除时,是否舍弃最后一批数据)、timeout、worker_init_fn、multiprocessing_context。
# 【用自定义的类把它实例化一个数据对象】
train_set = ImageDataset(dataset.train, train_transforms)
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0)
train_loader = DataLoader(
train_set,
# 【一个组中有多少个样本】
batch_size=cfg.SOLVER.IMS_PER_BATCH,
sampler=RandomIdentitySampler(dataset.train, cfg.SOLVER.IMS_PER_BATCH, cfg.DATALOADER.NUM_INSTANCE),
# 【要不要对样本进行随机排列】
shuffle = True,
# 【用多少进程并行运算,并行可以提高读取效率】
num_workers=num_workers,
collate_fn=train_collate_fn
)
7、DataLoader中的collate_fn()函数
是否需要进行自定义collate_fn ,主要看我们输入的数据是否为tensor格式, 如果内部元素是tensor格式,那么就不需要自己重新实现collate_fn, 如果内部元素不是tensor格式,就需要自己重新实现该函数。【拼接维度不同的数据】
代码如下:
"""
@author: liaoxingyu
@contact: sherlockliao01@gmail.com
"""
import torch
def train_collate_fn(batch):
# 【将多个列表(或元组)的对应元素拼在一起】
imgs, pids, _, _, = zip(*batch)
# 【将列表变成Tensor张量形式,stack默认在维度0拼接,维度大小等于batch_size大小】
pids = torch.tensor(pids, dtype=torch.int64)
return torch.stack(imgs, dim=0), pids 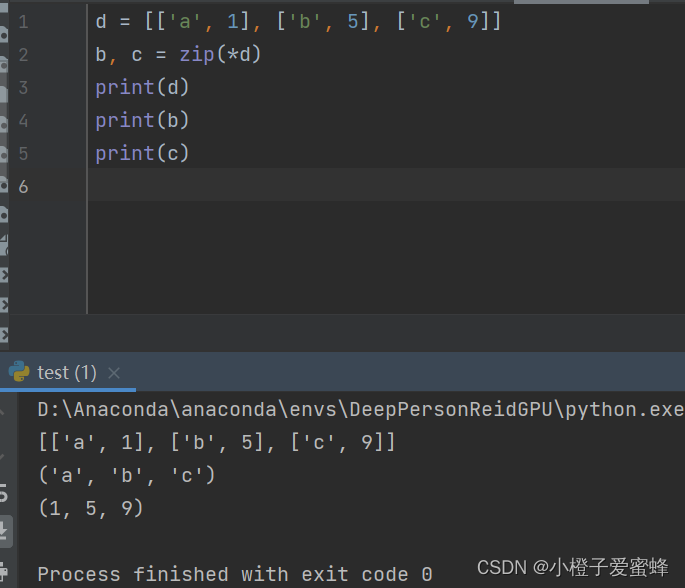
stack函数意义:保留两个信息:[1. 序列] 和 [2. 张量矩阵] 信息,属于【扩张再拼接】的函数。
官方解释:沿着一个新维度对输入张量序列进行连接。 序列中所有的张量都应该为相同形状。
浅显说法:把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…以此类推,也就是在增加新的维度进行堆叠。【扩维拼接】
outputs = torch.stack(inputs, dim=?) → Tensor
参数:
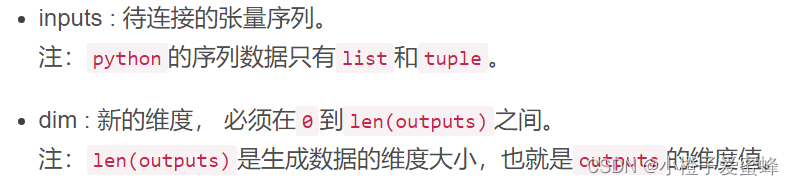
以上是我学习的笔记,如有不足,请多多指教!!!
文章出处登录后可见!