Datawhale干货
作者:Ben,中山大学,Datawhale成员
最近ChatGPT火出圈了,它和前阵子的Stable Diffusion(AIGC)一样成为社交媒体上人们津津乐道的话题。“ChatGPT要取代谷歌搜索了?”“ChatGPT要让程序员失业了吗?”……类似的标题又一次刺激了我们的神经。作为一名码农,我对后一个标题其实是嗤之以鼻的。无论ChatGPT是用了什么样的“魔法”,仅从目前展现的能力来看,它学会的顶多就是熟练使用编程语言的API,去实现某个函数完成人类给定的特定小任务。在真实的项目场景下,程序员通常要接过一个含糊不清的需求,梳理其中的每个细节直至形成逻辑闭环,再将其抽象成一个个特定任务并实现功能,现有AI至多能帮上最后一个小阶段;更别提真正让程序员头大的往往是并发、事务一致性等问题,这些都是现有AI无法解决的。
但是作为一名深度学习爱好者,我对ChatGPT表现出来的能力是惊叹的。无论是OpenAI提供的示例还是社交媒体上的各路花活,都让我更新了以往对AI语言模型特有的“人工智障”的认识。因此我其实十分好奇,ChatGPT的“魔法”原理是什么?遗憾的是,我在中文互联网上并没有找到对这个工作很好的解读文字,而直接看论文既费事又不是特别能理解。在一些网上优质解读视频的帮助下,我逐渐理解了所谓的“魔法”究竟是什么,并尝试梳理成如下的文字。
ChatGPT的“魔法”原理
由于ChatGPT并没有放出论文,我们没法直接了解ChatGPT的设计细节。但它的blog中提到一个相似的工作InstructGPT,两者的区别是ChatGPT在后者的基础上针对多轮对话的训练任务做了优化,因此我们可以参考后者的论文去理解ChatGPT。
然而,InstructGPT的论文由25页正文和43页附录组成,所以本文并不试图去讲清包括训练策略在内的每个细节。为了保证梳理的完整性,本文将分为上下两个部分:第一部分参考了Youtube上的 李宏毅 和 陈蕴侬 老师,旨在讲清InstructGPT的改进思路;第二部分参考了B站UP主弗兰克甜,试图转述他对ChatGPT的深刻理解。
InstructGPT的改进思路
对任何一篇工作的理解,都要回归到两个问题:一是它相比以往的工作有哪些改进,二是这些改进基于什么设计思路或者说有什么用。对InstructGPT的简单理解,可以是基于人类反馈的强化学习(RLHF)手段微调的GPT。那么我们去搞懂RLHF,其实就可以大概了解InstructGPT了。
根据下边的论文图片,我们可以知道InstructGPT的训练可以分为三个阶段:
利用人类的标注数据(demonstration data)去对GPT进行有监督训练,不妨把微调好的GPT叫做SFT;
收集多个不同(如4个)的SFT输出,这些输出基于同一个输入,然后由人类对这些输出进行排序并用来训练奖赏模型(RM);
由RM提供reward,利用强化学习的手段(PPO)来训练之前微调过的SFT。
一个需要补充的细节是,RM是会保持更新的,因此阶段2与阶段3其实是递交进行的。
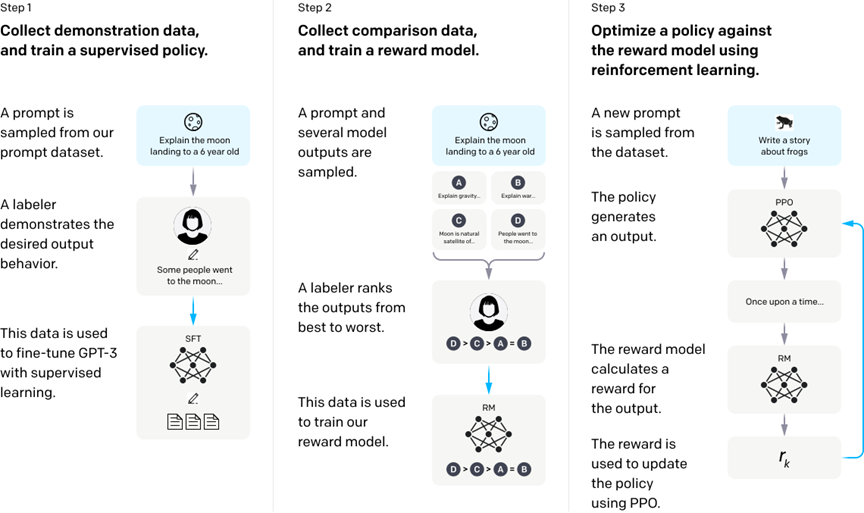
由于我此前并不是特别了解强化学习,因此一开始读论文时尚能理解阶段1和3,但完全搞不懂阶段2在说什么。相信不少读者也有类似的疑问:
InstructGPT为什么要做这样的改进,或者说它的novelty是什么?
为什么要训练一个RM,这个奇奇怪怪的RM为什么能用来充当奖赏函数?
人类对模型的多个输出做个排序,为什么就能够提供监督信号,或者说在训练RM时如何怎么做到loss的梯度回传?
可能部分人还有其它疑问,但我相信回答了这三个问题,应该也能帮助理解。
第一个问题其实在ChatGPT的blog中也有回答。这两个模型的改进思路,都是尽可能地对齐(Alignment)GPT的输出与对用户友好的语言逻辑,即微调出一个用户友好型GPT。以往的GPT训练,都是基于大量无标注的语料,这些语料通常收集自互联网。我们都知道,大量“行话”“黑话”存在于互联网中,这样训练出来的语言模型,它可能会有虚假的、恶意的或者有负面情绪等问题的输出。因此,一个直接的思路就是,通过人工干预微调GPT,使其输出对用户友好。
为了回答第二个问题,其实要稍微拓展下强化学习相关的一些研究。我们都知道,经典的强化学习模型可以总结为下图的形式:
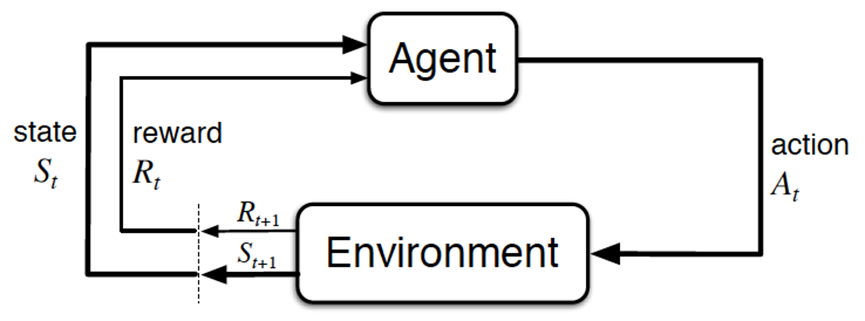
具体来说,智能体(Agent)就是我们要训练的模型,而环境是提供reward的某个对象,它可以是AlphaGo中的人类棋手,也可以是自动驾驶中的人类驾驶员,甚至可以是某些游戏AI里的游戏规则。强化学习理论上可以不需要大量标注数据,然而实际上它所需求的reward存在一些缺陷,这导致强化学习策略很难推广:
reward的制定非常困难。比如说游戏AI中,可能要制定成百上千条游戏规则,这并不比标注大量数据来得容易;
部分场景下reward的效果不好。比如说自动驾驶的多步决策(sequential decision)场景中,学习器很难频繁地获得reward,容易累计误差导致一些严重的事故。
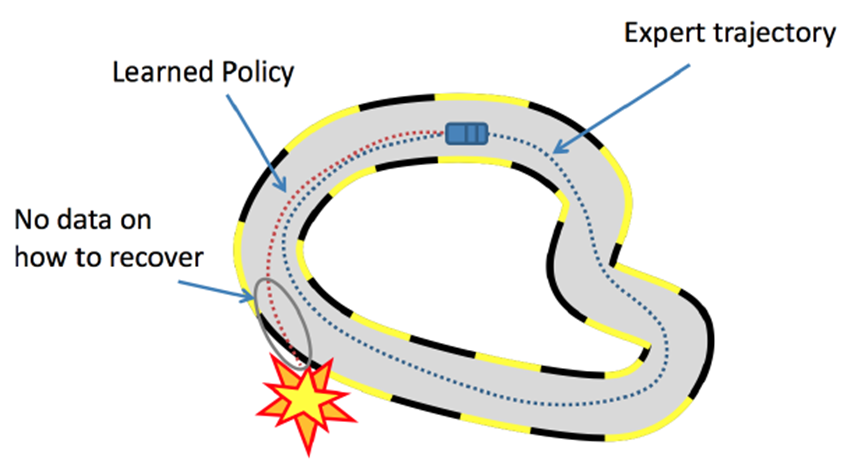
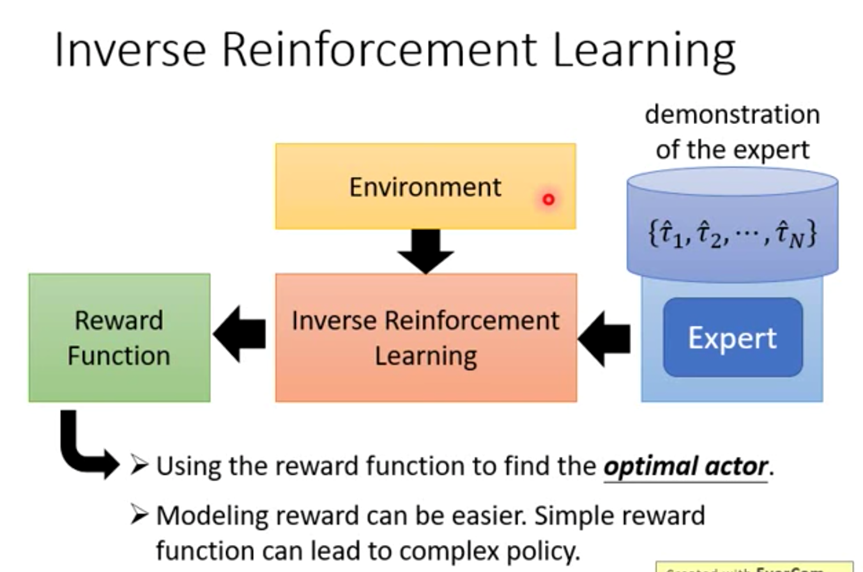
想把上面的多步决策问题讲清是一件困难的事,而且我本人也不是十分理解。总之,为了解决这些问题,模仿学习(Imitation Learning)应运而生。模仿学习的思路是不让模型在人类制定的规则下自己学习,而是让模型模仿人类的行为。有的人可能会疑惑,这与监督学习有什么异同吗?我认为相同点在于都要收集人类的标注数据,不同点在于模仿学习最终是以强化学习的形式进行的;简单来说,模仿学习将强化学习的Environment替换成一个Reward Model,而这个RM是通过人类标注数据去训练得到的。其中,逆强化学习就是模仿学习的一种形式,如下图。(PS:由于我实在是不了解强化学习领域,所以这里的理解可能不准确)
在回答了第二个“为什么要训练RM”的问题后,就要接着回答“如何训练RM”。如下图,训练RM的核心是由人类对SFT生成的多个输出(基于同一个输入)进行排序,再用来训练RM。按照模仿学习的定义,直观上的理解可以是,RM在模仿人类对语句的排序思路,或者按照OpenAI团队论文《Learning from Human Preferences》的说法是,模仿人类的偏好(Preference)。那么到底是如何模仿的呢,或者说如何实现梯度回传?
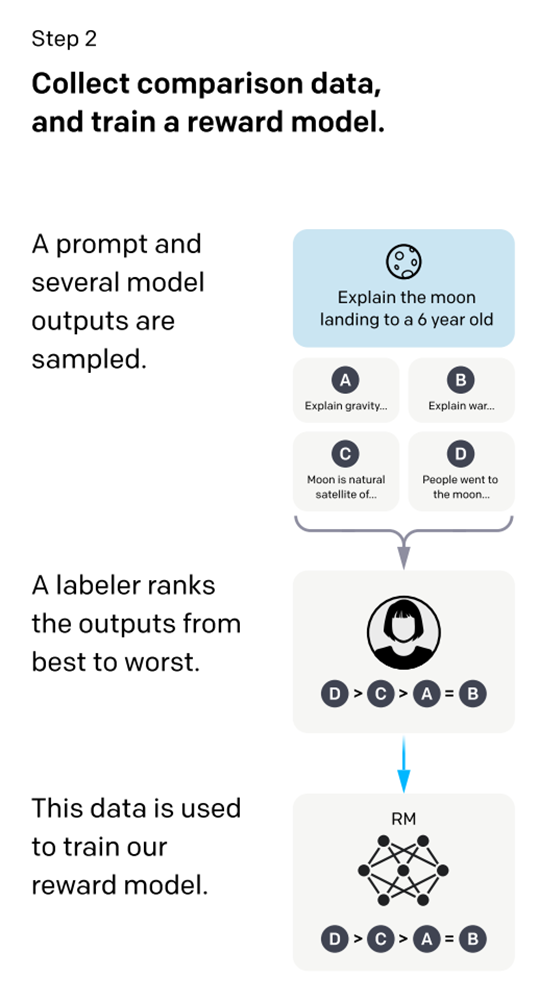
这里我们代入一个场景。如上图,SFT生成了ABCD四个语句,然后人类对照着Prompt输入来做出合适的排序选择,如D>C>A=B。这里的排序实质是人类分别给四个语句打分,比如说D打了7分,C打了6分,A和B打了4分。为了让RM学到人类偏好(即排序),可以四个语句两两组合分别计算loss再相加取均值,即分别计算个loss。具体的loss形式如下图。

文章出处登录后可见!