网络连接结构
个人理解,如有偏差,欢迎指出。
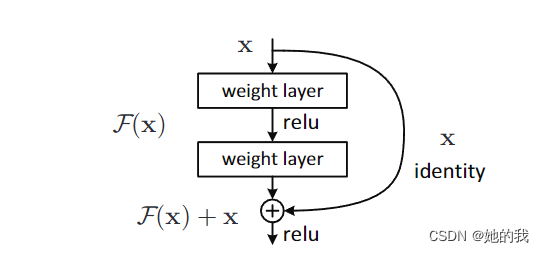
ResNet
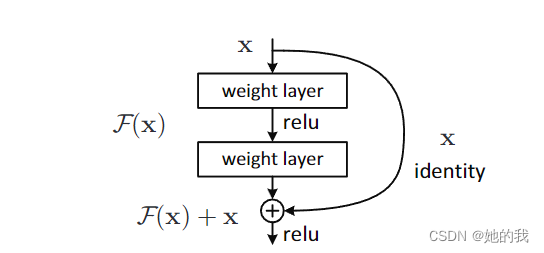
- ResNet 为了解决模型退化问题,创新性的使用了恒等映射,将上一层可能不需要改变的信息,通过跨层链接以逐个相加的方式,叠加到下一层的输出上,增加了信息流动的方式,从而一定程度上缓解了梯度消失的问题。
RIR
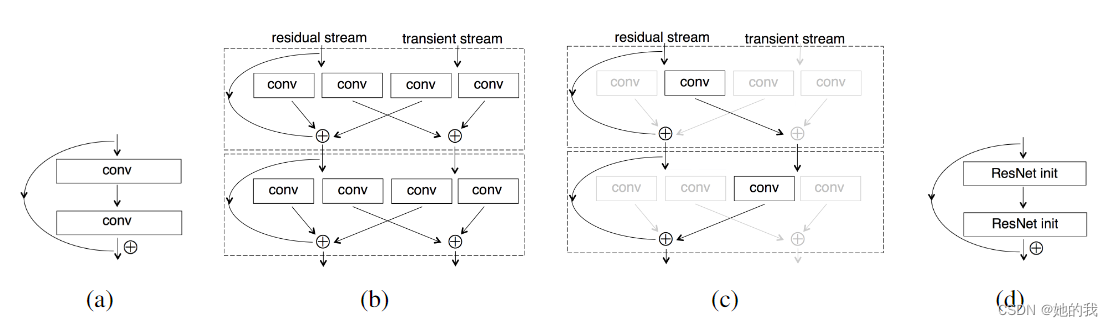
- Resnet in Resnet (RiR) 基于ResNet 改进,扩展了信息流动的方式,研究证明在深度网络中,浅层网络学习的内容可能对后面深层的网络没有任何作用,也即是说,ResNet 可能将浅层冗余的信息(需要抛弃的信息)也不可避免的通过恒等映射传递下去了,因为,认为通过恒等映射相加这种方式去学习丢弃特征的过程是很困难的。
- RIR增加了并联的普通卷积的方式,增加了以非线性方式处理来自任何一个流的信息的能力(可以学习丢弃特征的能力),没有捷径连接。
DenseNet

- DenseNet 创新性的提出了更加密集的网络模型,随机深度(stochastic depth)通过在训练期间随机丢弃层来改进深度残差网络的训练。这表明并非所有层都可能需要,并强调深度(残差)网络中存在大量冗余。基于此,DenseNet认为信息流在网络层传递的过程中,k可能改变了本来需要保留的信息,而ResNet采用相加的恒等连接,只是保留信息的一种相对合理的方式。
- 因此,DenseNet在跨层结构使用concatenate这种更加一般的方式,整合信息流。DenseNets 不是从极深或极宽的架构中汲取表征能力,而是通过特征重用来利用网络的潜力
Unet
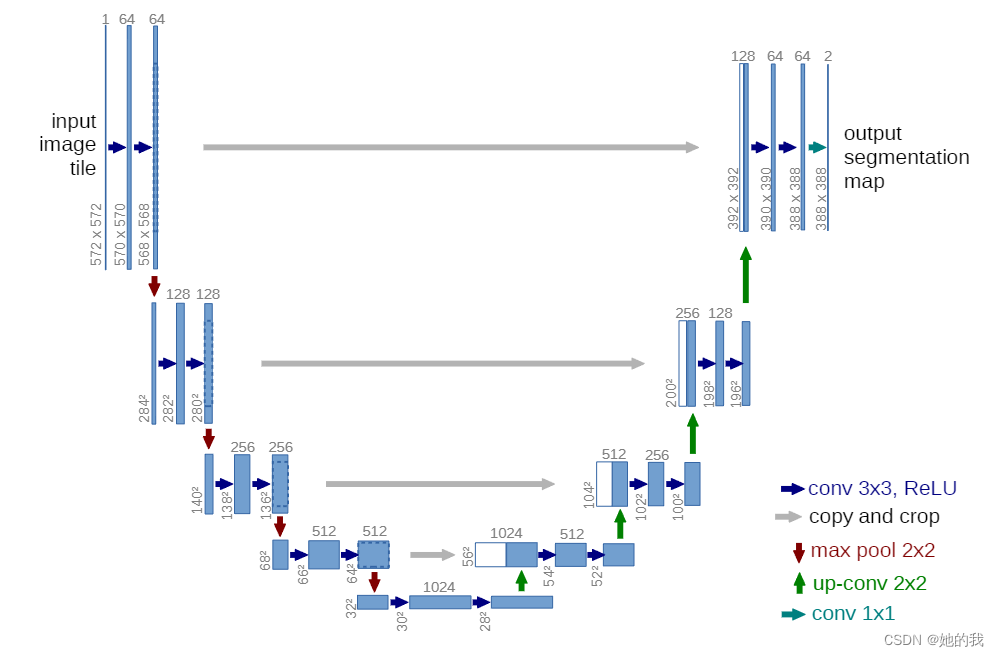
- 采用编码解码结构,通过编码下采样增大感受野,得到各级特征,但是有边缘信息损失,再通过解码器回复图像分辨率,创新型使用跳跃连接将带有边缘信息的底层特征融合(concatenate)进行上采样,更好的恢复图像细节。
Unet++
- 降采样它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。升采样的最大的作用其实就是把抽象的特征再还原解码到原图的尺寸,最终得到分割结果。对于特征提取阶段,浅层结构可以抓取图像的一些简单的特征,比如边界,颜色,而深层结构因为感受野大了,而且经过的卷积操作多了,能抓取到图像的一些说不清道不明的抽象特征,浅有浅的侧重,深有深的优势。
- 不同层次特征的重要性对于不同的数据集是不一样的,并不是说设计一个4层的UNet,就像原论文给出的那个结构,就一定对所有数据集的分割问题都最优。其次,U-Net中的长连接是有必要的,它联系了输入图像的很多信息,有助于还原降采样所带来的信息损失,在一定程度上,它和残差的操作非常类似,也就是residual操作。如果没有长连接就是这样,缺少了恒等映射???:
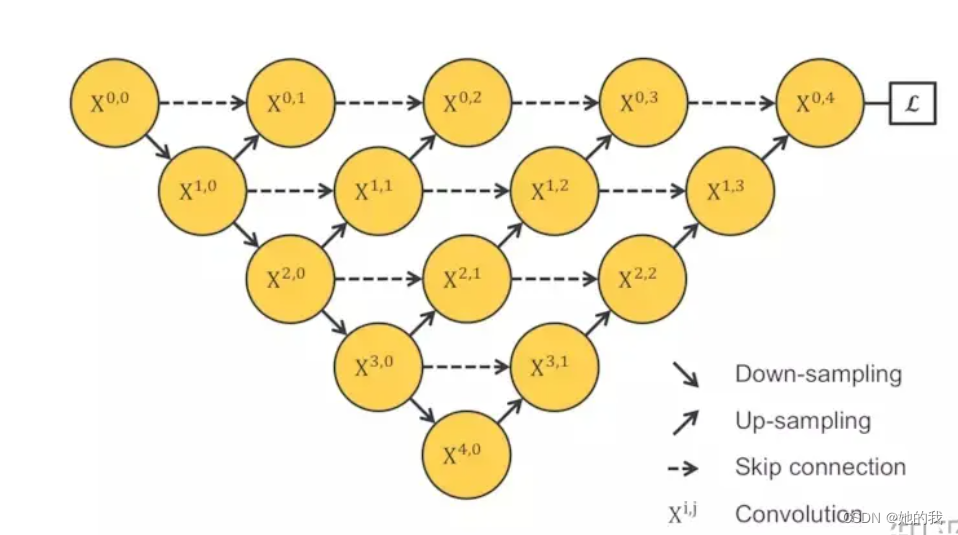
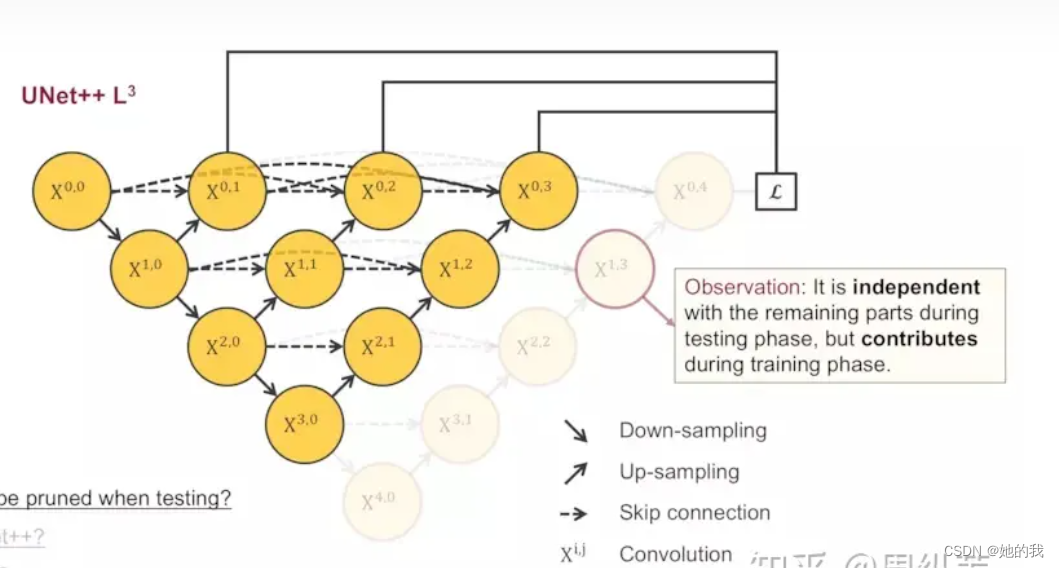
- Unet++实现了长连接,单从一层看就是DenseNet的一个block!!,是否可以看作一个并联的DenseNet呢,Unet++采用了深层监督的方法,具体的实现操作就是在图中 ,X01, X02, X03, X04后面加一个1×1的卷积核,相当于去监督每个level,或者每个分支的U-Net的输出。
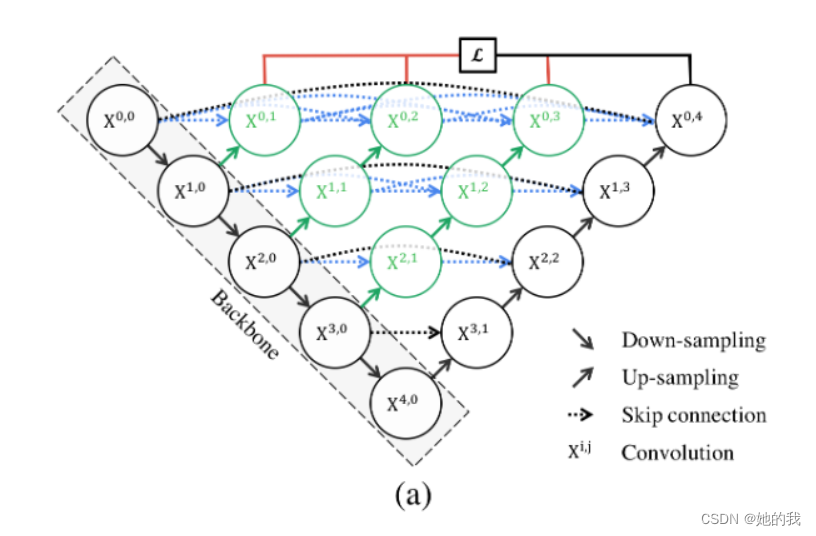
- 此外,在测试的阶段,由于输入的图像只会前向传播,扔掉这部分对前面的输出完全没有影响的,而在训练阶段,因为既有前向,又有反向传播,被剪掉的部分是会帮助其他部分做权重更新的。因为在深监督的过程中,每个子网络的输出都其实已经是图像的分割结果了,所以如果小的子网络的输出结果已经足够好了,我们可以随意的剪掉那些多余的部分了。
特征融合方式
深度学习特征融合的方式
参考:特征融合
相加
-
线性相加:像ResNet或RIR中上下层采用的特征融合方式就是逐像素相加。 相加不改变梯度的变化。操作也比较简单快速。限制:首先,两个输入x1和x2, 应该是有相同含义或者相似含义的,或者说输入和输出之间是对应的。在ResNet中,就假设其中一个输入可能为0,而输入可能就是其中一个输出。直接相加也意味着两个输入需要有同样的范围,而且重要性是相等的。y = f(x1, x2) = x1 + x2
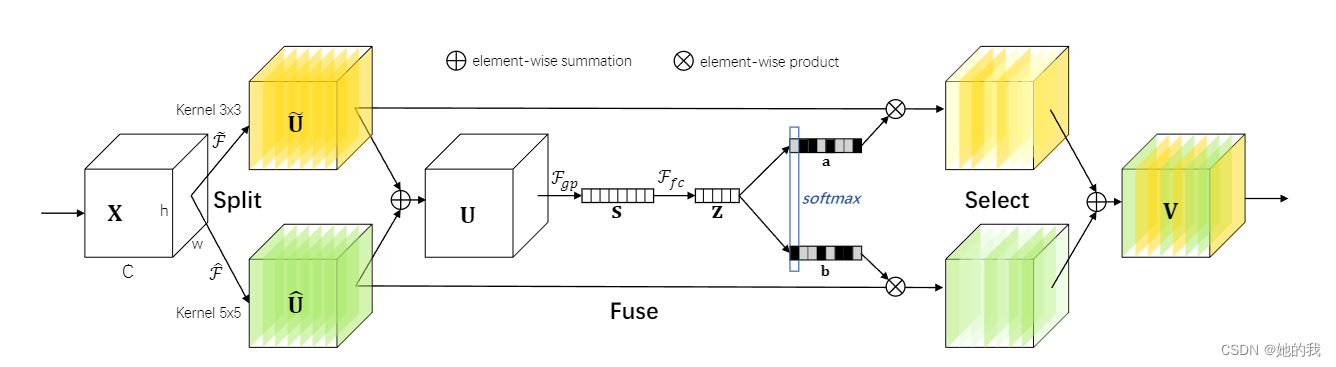
-
非线性相加:可以用注意力学习到相加的两者具有不同的重要性,如下图,两个不同感受野的特征图,通过学习得到不同的权重,最后实现权重非线性相加的结果。
相乘
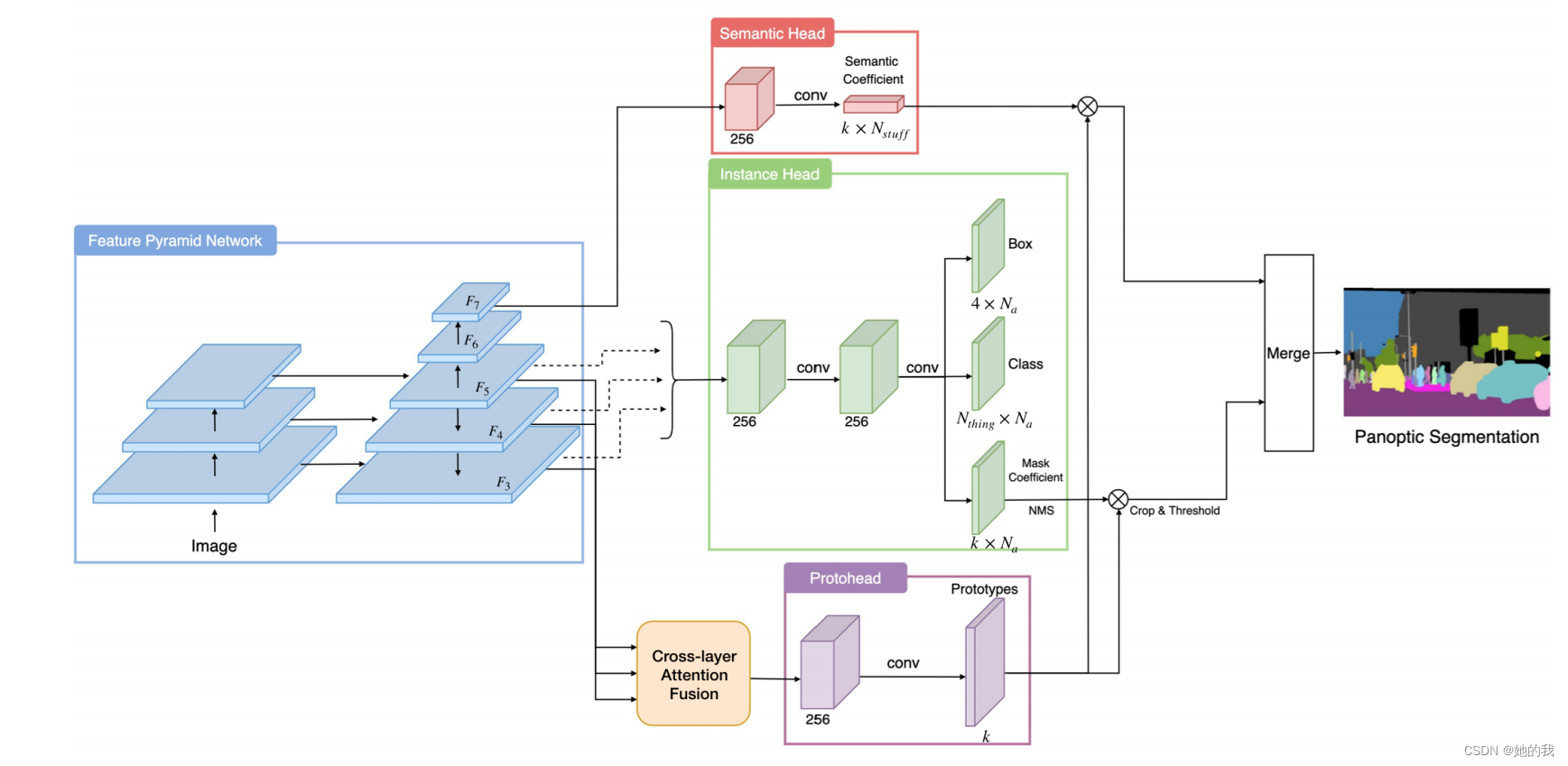
- 一般是采用block得到特征图的权重,再与特征图相乘,得到加权的效果。下面的全景分割的网络就是采用此种方式,分别求出实例分割和语义分割的权重,再将其与使用注意力得到的原特征图进行加权相乘,突出自己从语义分割和实例分割学到的强调部分。
拼接
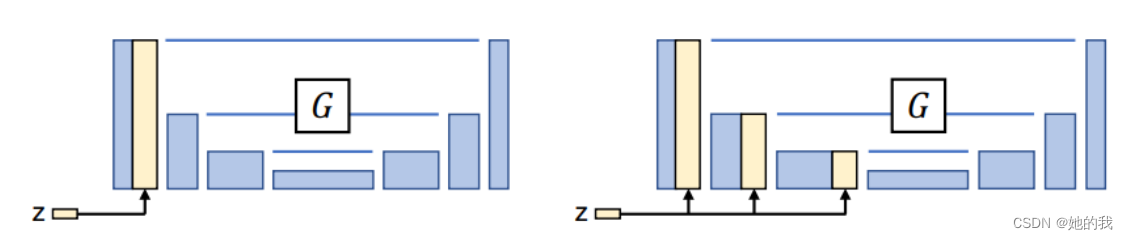
- 使用concatenate,只是将得到的特征图堆叠起来,之后会进行其他的卷积操作,相对更宽泛一些,DenseNet使用此种方法作为对ResNet的一种扩展,显然的,这个方法要求有更多的内存。但是我们可以结合不同维度的东西,这里的作用是将不同位置的特征结合起来生成新的特征,主要是想保存好前面的低维特征,不至于损失太多。
统计数据融合
- 新颖的自适应实例归一化(AdaIN)层,它将内容特征的均值和方差与样式特征的均值和方差对齐。可以实现不同含义的数据进行融合。这里均值和方差表示图像的风格,输入特征图表示图像的内容。这种方法利用统计指标进行了融合,可以改变一个输入的统计指标,通常我们用统计指标来表示一些条件来作用在特征图上。
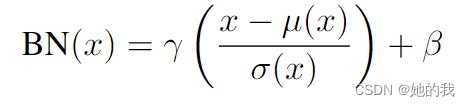
文章出处登录后可见!
已经登录?立即刷新