因为本项目对点云分割网络进行了一些改进,引入了注意力机制,因此今天将注意力机制模块进行一个简单的介绍
注意力机制
在计算机视觉中能够能够把注意力聚集在图像重要区域而丢弃掉不相关的方法被称作是注意力机制(Attention Mechanisms)。在人类视觉大脑皮层中,使用注意力机制能够更快捷和高效地分析复杂场景信息。这种机制后来被研究人员引入到计算机视觉中来提高性能。
注意力机制可以看作是对图像输入重要信息的动态选择过程,这个过程是由对于特征自适应权重实现的。注意力机制极大提升了很多计算机视觉任务性能水平,比如在分类,目标检测,语义分割,人脸识别,动作识别,小样本检测,医疗影像处理,图像生成,姿态估计,超分辨率,3D视觉以及多模态中等任务中发挥着重要作用。
一般来说,注意力机制通常分为:
通道注意力 Channel Attention,告诉网络 : what to pay attention to
空间注意力机制 Spatial Attention,告诉网络 where to pay attention to
时间注意力机制 Temporal Attention,告诉网络 when to pay attention to
分支注意力机制 Branch Attention,告诉网络 which to pay attention to
最后还有两种混合注意力机制:
通道&空间注意力机制 和 空间&时间注意力机制。
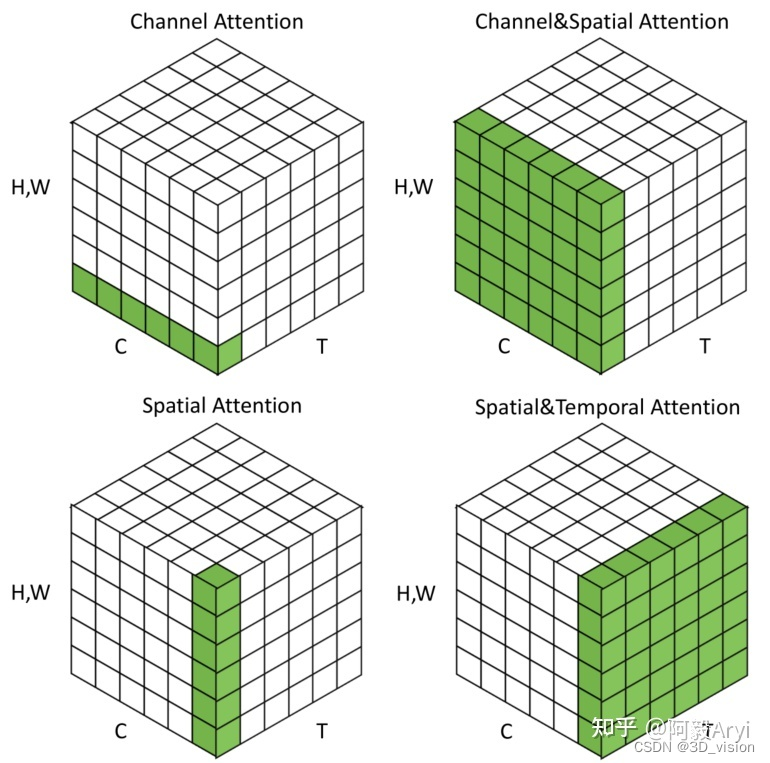
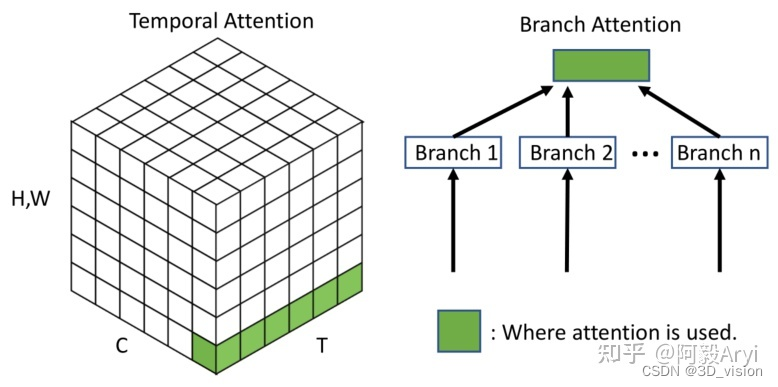 上图是不同注意力机制的作用域。
上图是不同注意力机制的作用域。
注意力机制优点
注意力机制的显著优点就是关注相关的信息而忽略不 相关的信息,不通过循环而直接建立输入与输出之间的 依赖关系,并行化程度增强,运行速度有了很大提高
CBAM注意力机制
CBAM(Convolutional Block Attention Module) 是一种用于前馈卷积神经网络的简单而有效的注意力模块。它是一种结合了通道(channel)和空间(spatial)的注意力机制模块。相比于SE-Net只关注通道注意力机制可以取得更好的结果。
CBAM网络结构
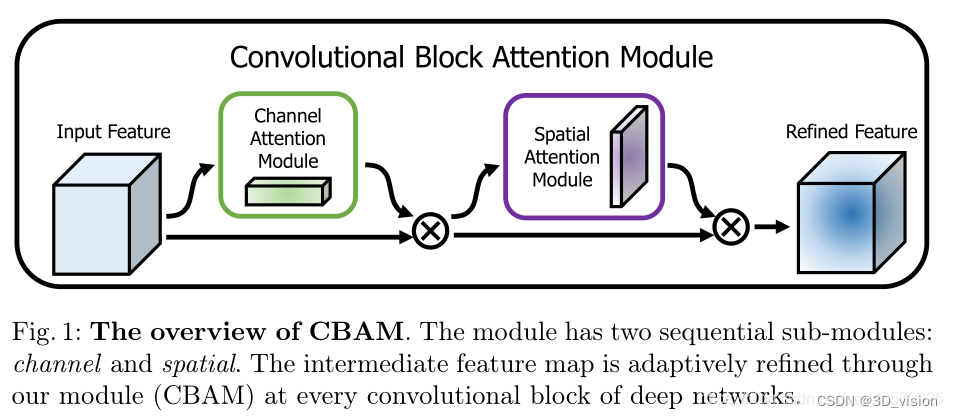
 CBAM的结构如上,可以看到,卷积层输出的结果,会先通过一个通道注意力机制,得到加权结果之后,会再经过一个空间注意力模块,最终进行加权得到结果。
CBAM的结构如上,可以看到,卷积层输出的结果,会先通过一个通道注意力机制,得到加权结果之后,会再经过一个空间注意力模块,最终进行加权得到结果。
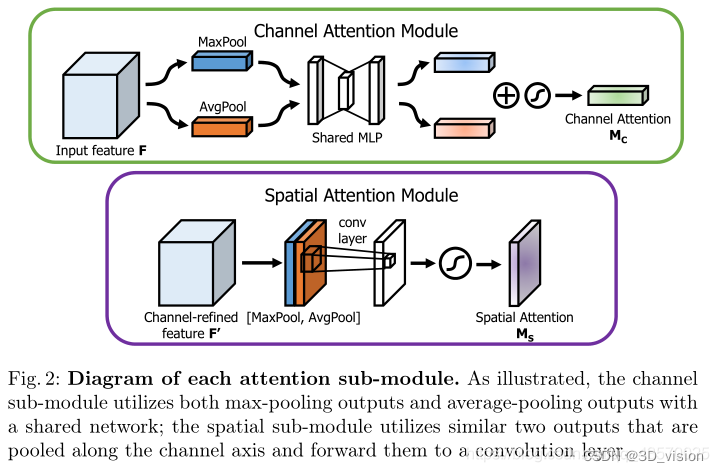
通道注意力模块(SAM)如上图所示.将输入的特征图,分别经过基于width和height的global max pooling和global average pooling,然后分别经过MLP。将MLP输出的特征进行基于element-wise(element-wise 是神经网络编程中非常常见的张量操作,他在 相应张量内的对应的元素进行操作。)的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature map。将该channel attention feature map和input feature map做element-wise乘法操作,生成Spatial attention模块需要的输入特征。
换一个角度考虑,通道注意力机制(Channel Attention Module)是将特征图在空间维度上进行压缩,得到一个一维矢量后再进行操作。在空间维度上进行压缩时,不仅考虑到了平均值池化(Average Pooling)还考虑了最大值池化(Max Pooling)。平均池化和最大池化可用来聚合特征映射的空间信息,送到一个共享网络,压缩输入特征图的空间维数,逐元素求和合并,以产生通道注意力图。单就一张图来说,通道注意力,关注的是这张图上哪些内容是有重要作用的。平均值池化对特征图上的每一个像素点都有反馈,而最大值池化在进行梯度反向传播计算时,只有特征图中响应最大的地方有梯度的反馈。通道注意力机制可以表达为:
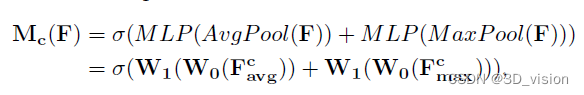
空间注意力模块(spatial attention module)也如上图所示。将Channel attention模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
同样,空间注意力机制(Spatial Attention Module)是对通道进行压缩,在通道维度分别进行了平均值池化和最大值池化。MaxPool的操作就是在通道上提取最大值,提取的次数是高乘以宽;AvgPool的操作就是在通道上提取平均值,提取的次数也是是高乘以宽;接着将前面所提取到的特征图(通道数都为1)合并得到一个2通道的特征图。
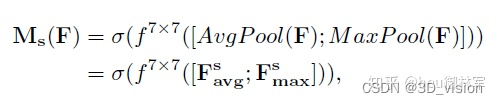
对于输入的特征图,CBAM模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将将注意力图与输入的特征图相乘以进行自适应特征优化。
优势:
由于CBAM是轻量级的通用模块,因此可以忽略该模块的开销,且无缝集成到任何CNN架构中,并可以与基础CNN一起进行端到段的训练。
代码实现
"""
Author: yida
Time is: 2021/11/21 11:40
this Code: 实现CBAM模块
"""
import os
import torch
import torch.nn as nn
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
class CBAM(nn.Module):
def __init__(self, in_channel):
super(CBAM, self).__init__()
self.Cam = ChannelAttentionModul(in_channel=in_channel) # 通道注意力模块
self.Sam = SpatialAttentionModul(in_channel=in_channel) # 空间注意力模块
def forward(self, x):
x = self.Cam(x)
x = self.Sam(x)
return x
class ChannelAttentionModul(nn.Module): # 通道注意力模块
def __init__(self, in_channel, r=0.5): # channel为输入的维度, r为全连接层缩放比例->控制中间层个数
super(ChannelAttentionModul, self).__init__()
# 全局最大池化
self.MaxPool = nn.AdaptiveMaxPool2d(1)
self.fc_MaxPool = nn.Sequential(
nn.Linear(in_channel, int(in_channel * r)), # int(channel * r)取整数, 中间层神经元数至少为1, 如有必要可设为向上取整
nn.ReLU(),
nn.Linear(int(in_channel * r), in_channel),
nn.Sigmoid(),
)
# 全局均值池化
self.AvgPool = nn.AdaptiveAvgPool2d(1)
self.fc_AvgPool = nn.Sequential(
nn.Linear(in_channel, int(in_channel * r)), # int(channel * r)取整数, 中间层神经元数至少为1, 如有必要可设为向上取整
nn.ReLU(),
nn.Linear(int(in_channel * r), in_channel),
nn.Sigmoid(),
)
# 激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 1.最大池化分支
max_branch = self.MaxPool(x)
# 送入MLP全连接神经网络, 得到权重
max_in = max_branch.view(max_branch.size(0), -1)
max_weight = self.fc_MaxPool(max_in)
# 2.全局池化分支
avg_branch = self.AvgPool(x)
# 送入MLP全连接神经网络, 得到权重
avg_in = avg_branch.view(avg_branch.size(0), -1)
avg_weight = self.fc_AvgPool(avg_in)
# MaxPool + AvgPool 激活后得到权重weight
weight = max_weight + avg_weight
weight = self.sigmoid(weight)
# 将维度为b, c的weight, reshape成b, c, 1, 1 与 输入x 相乘
h, w = weight.shape
# 通道注意力Mc
Mc = torch.reshape(weight, (h, w, 1, 1))
# 乘积获得结果
x = Mc * x
return x
class SpatialAttentionModul(nn.Module): # 空间注意力模块
def __init__(self, in_channel):
super(SpatialAttentionModul, self).__init__()
self.conv = nn.Conv2d(2, 1, 7, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x维度为 [N, C, H, W] 沿着维度C进行操作, 所以dim=1, 结果为[N, H, W]
MaxPool = torch.max(x, dim=1).values # torch.max 返回的是索引和value, 要用.values去访问值才行!
AvgPool = torch.mean(x, dim=1)
# 增加维度, 变成 [N, 1, H, W]
MaxPool = torch.unsqueeze(MaxPool, dim=1)
AvgPool = torch.unsqueeze(AvgPool, dim=1)
# 维度拼接 [N, 2, H, W]
x_cat = torch.cat((MaxPool, AvgPool), dim=1) # 获得特征图
# 卷积操作得到空间注意力结果
x_out = self.conv(x_cat)
Ms = self.sigmoid(x_out)
# 与原图通道进行乘积
x = Ms * x
return x
if __name__ == '__main__':
inputs = torch.randn(10, 100, 224, 224)
model = CBAM(in_channel=100) # CBAM模块, 可以插入CNN及任意网络中, 输入特征图in_channel的维度
print(model)
outputs = model(inputs)
print("输入维度:", inputs.shape)
print("输出维度:", outputs.shape)
文章出处登录后可见!