目录
一、深度学习简介
二、对抗攻击与防御算法介绍
三、对抗样本应用以及工具箱简介
四、对抗攻击算法的衡量标准
一、深度学习简介
深度学习(DL,Deep Learning)是机器学习(ML,Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI,Artificial Intelligence) 深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术,本此介绍主要以图像识别方面为主。
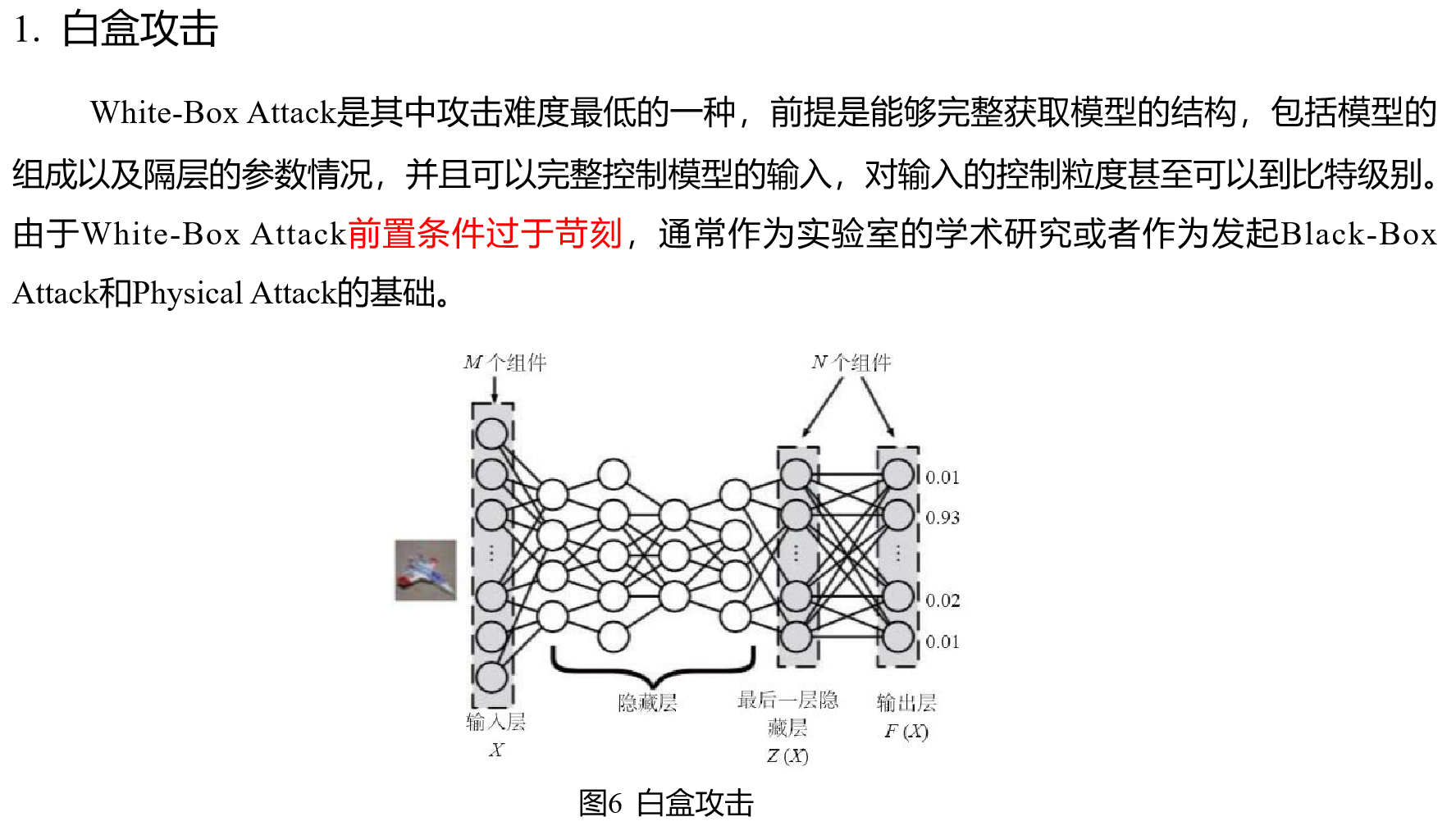
1.1 深度学习的脆弱性(易攻击性)
深度学习作为一个非常复杂的软件系统,同样会面对各种黑客攻击。黑客通过攻击深度学习系统,也可以威胁到财产安全、个人隐私、交通安全和公共安全。针对深度学习系统的攻击,通常包括以下几种。

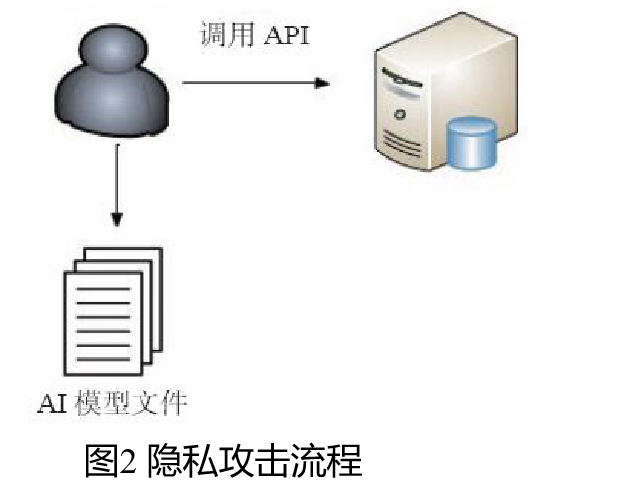
1.1.1 偷取算法(隐私攻击)
深度学习模型对外提供服务的形式也主要分为云模式的API(Application Programming interface 应用程序接口),或者私有部署到用户的移动设备或数据中心的服务器上。针对云模式的API,黑客通过一定的遍历算法,在调用云模式的API后,可以在本地还原出一个与原始模型功能相同或者类似的模型;针对私有部署到用户的移动设备或数据中心的服务器上,黑客通过逆向等传统安全技术,可以把模型文件直接还原出来供其使用。
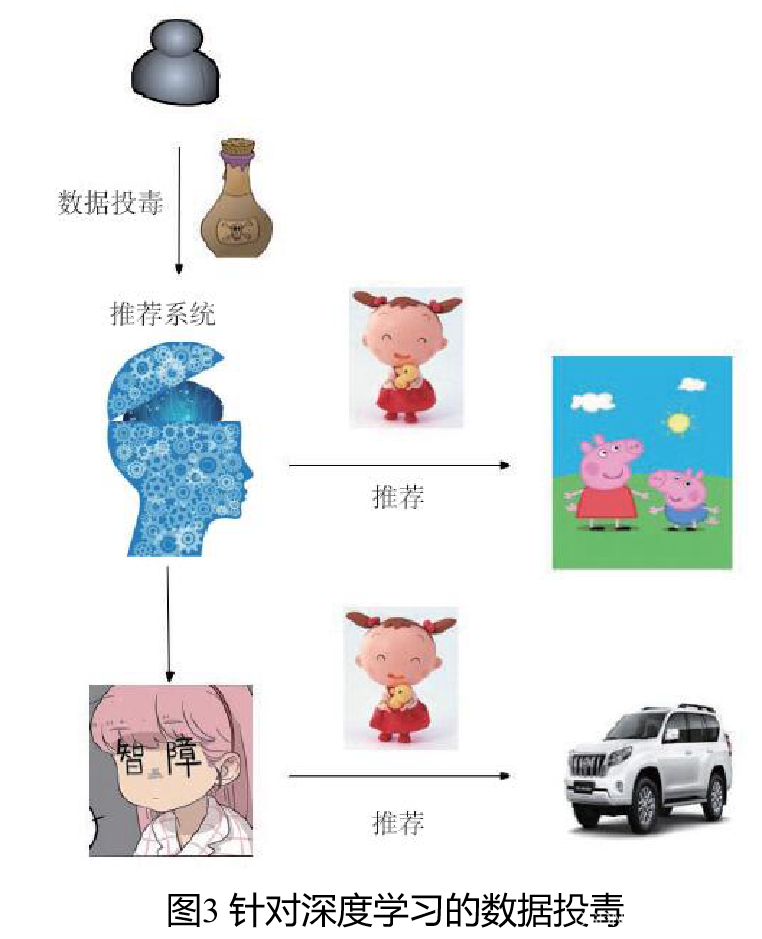
1.1.2 数据投毒(针对训练数据的攻击)
针对深度学习的数据投毒主要是指向深度学习的训练样本中加入异常数据,导致模型在遇到某些条件时会产生分类错误。如图3所示,早期的数据投毒都存在于实验室环境,假设可以通过在离线训练数据中添加精心构造的异常数据进行攻击。这一攻击方式需要接触到模型的训练数据,而在实际环境中,绝大多数情况都是公司内部在离线数据中训练好模型再打包对外发布服务,攻击者难以接触到训练数据,攻击难以发生。于是攻击者把重点放到了在线学习的场景,即模型是利用在线的数据,几乎是实时学习的,比较典型的场景就是推荐系统。推荐系统会结合用户的历史数据以及实时的访问数据,共同进行学习和判断,最终得到推荐结果。黑客正是利用这一可以接触到训练数据的机会,通过定的算法策略,发起访问行为,最终导致推荐系统产生错误。
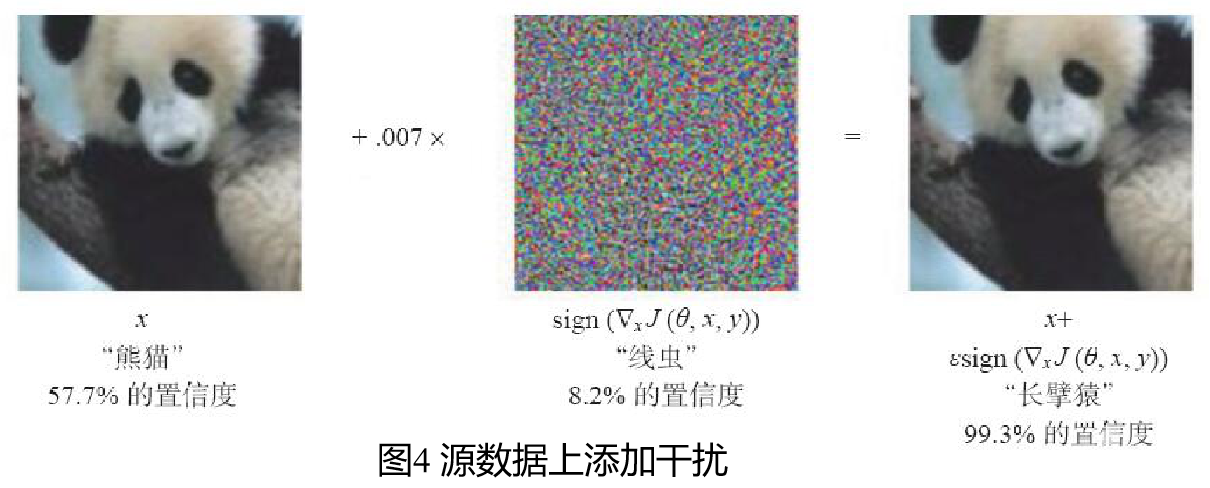
1.1.3 对抗样本
由Christian Szegedy等人提出,是指在数据集中通过故意添加细微的干扰所形成的输入样本,导致模型以高置信度给出一个错误的输出。这样我们可以理解大致的原理是攻击者通过在源数据上增加人类难以通过感官辨识到的细微改变,但是却可以让深度学习模型接受并做出错误的分类决定。比如下面这个奇妙的现象,在原有数据上叠加精心设计的变化量,在肉眼都难以识别的情况下,影响我们模型判断。

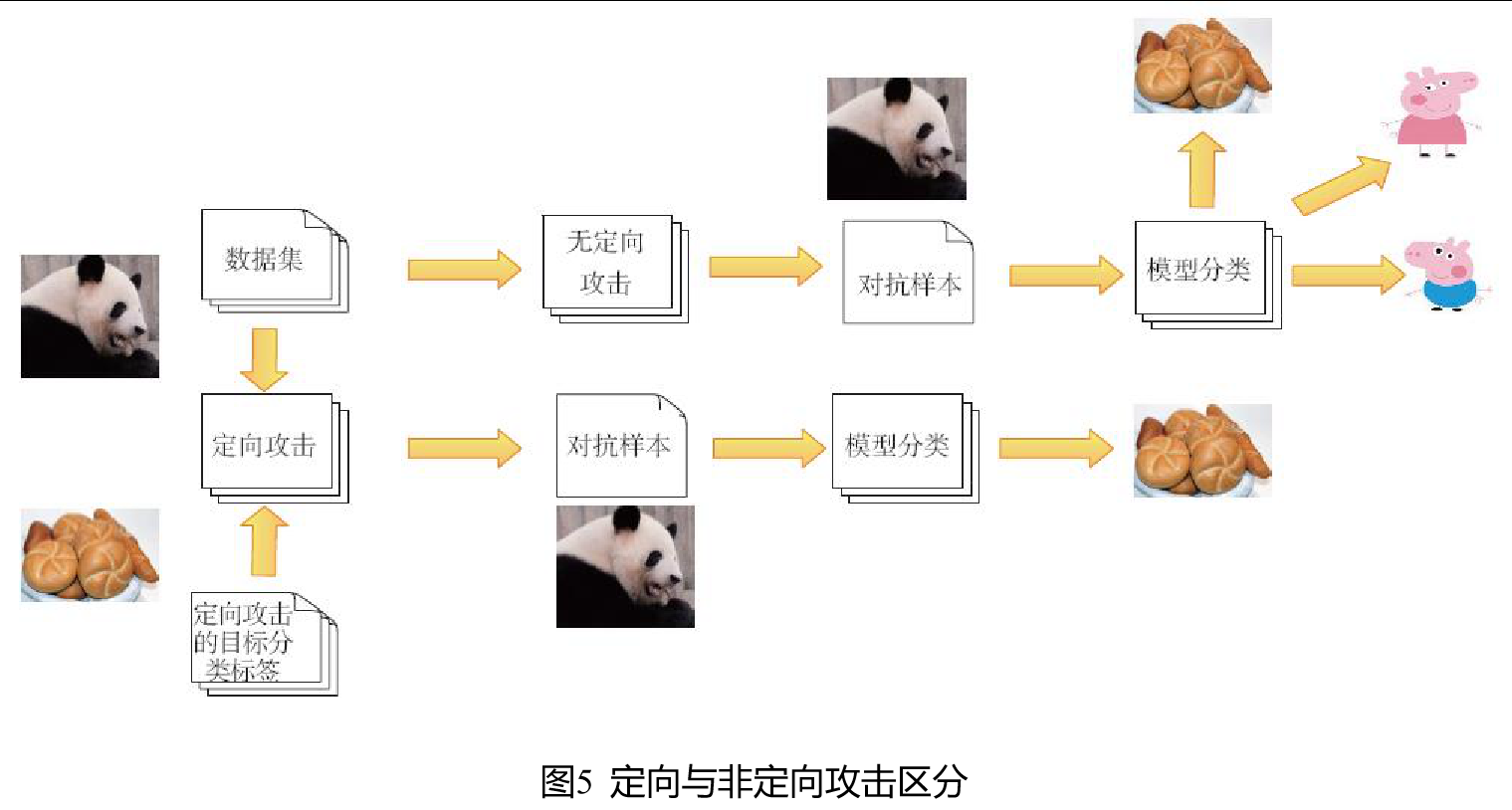
2. 黑盒攻击
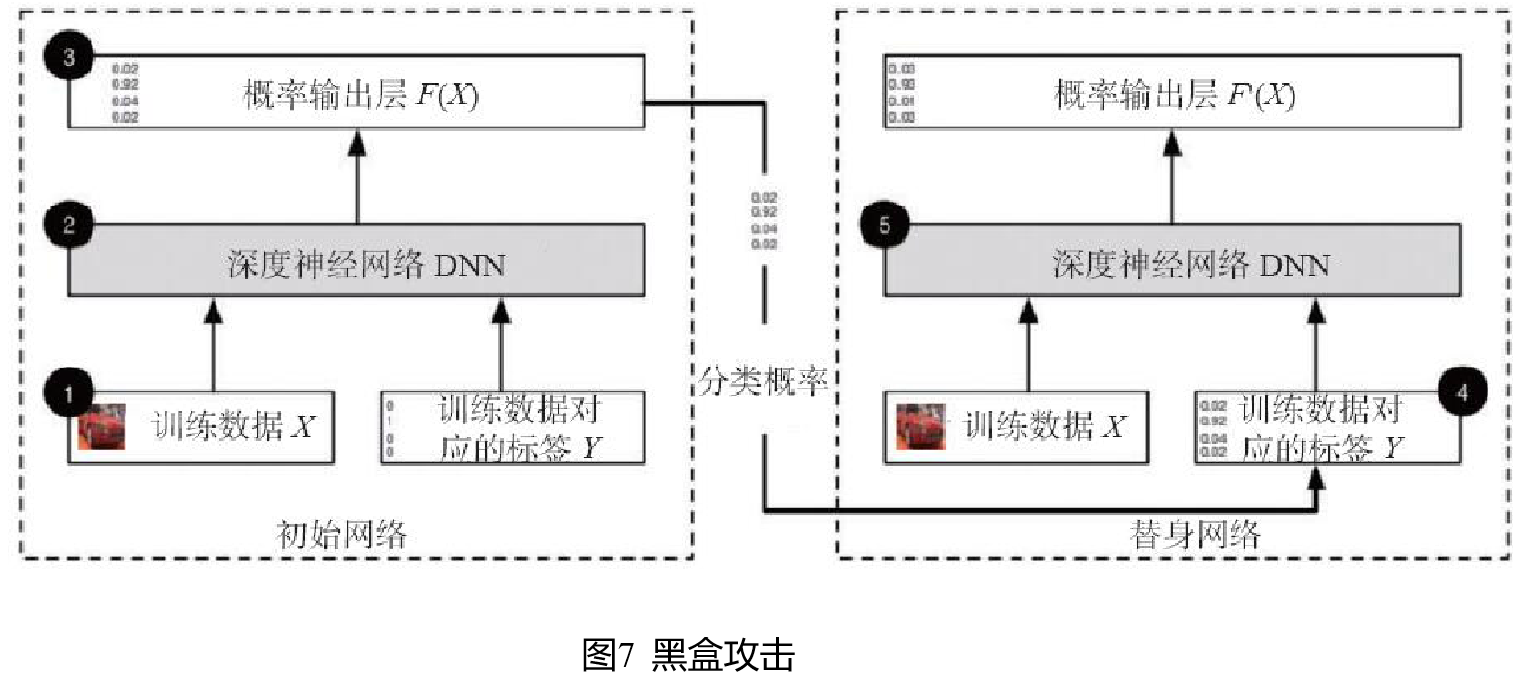
Black-Box Attack相对White-Box Attack攻击难度具有很大提高Black-Box Attack完全把被攻击模型当成一个黑盒,对模型的结构没有了解,只能控制输入,通过比对输入和输出的反馈来进行下一步攻击。
3. 物理攻击
Physical Attack是这三种攻击中难度最大的,除了不了解模型的结构,甚至对于输入的控制也很弱。以攻击图像分类模型为例,生成的攻击样本要通过相机或者摄像头采集,然后经过一系列未知的预处理后再输入模型进行预测。攻击中对抗样本会发生缩放、扭转、光照变化、旋转等。

二、对抗攻击与防御算法介绍
2.1 对抗攻击
深度学习模型以高置信度的方式给出错误的输出,通过生成对抗样本以达成逃避基于深度学习的检测服务的攻击方式被称为对抗攻击。
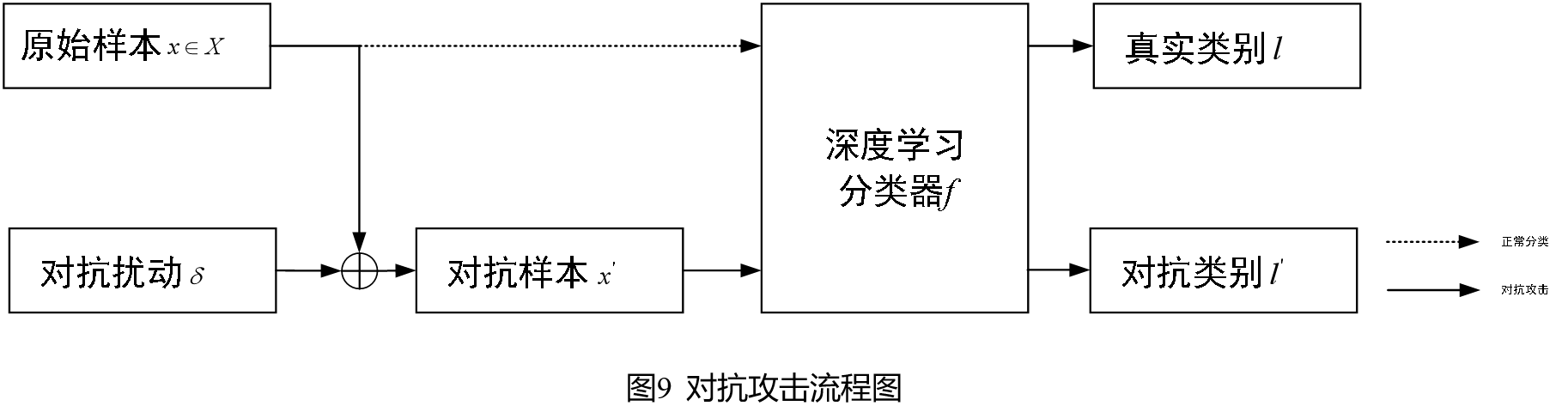
在图像分类任务中,用户输入一张图像至已训练好的深度学习分类器中,分类器会给出相应类别的预测结果。当遭受对抗攻击后,原始样本被加入人眼难以察觉的扰动,形成的对抗样本能够误导分类器给出其他类别的预测结果。对抗攻击的形式化表达如下所示。

 2.1.1 样本距离度量(扰动大小)
2.1.1 样本距离度量(扰动大小)
对抗攻击是指通过加入人眼难以察觉的扰动,生成能够成功欺骗深度学习分类器以达到逃逸攻击的目的。为了使对抗样本更具欺骗性,对抗攻击中目标函数的定义显得尤为重要。目标函数的定义涉及到对原始样本与对抗样本的距离度量,以量化样本之间的相似性,在许多经典的对抗攻击算法中,L_p被广泛用于度量样本间的 p 范式距离,其定义如公式所示。
 2.1.2 数据集
2.1.2 数据集
对抗攻击通常需要对相同数据集进行仿真实验,以评估和对比攻击方法的性能。在图像分类领域,ImageNet、MNIST 和 CIFAR-10 是3个应用非常广泛的开源数据集。ImageNet是根据WordNet层次结构组织的图像数据集,该数据集数量庞大、类别丰富,是迄今为止最优秀的图像数据集,著名的ILSVRC挑战赛基于此数据集展开对抗攻击和防御。MNIST数据集来自美国国家标准与技术研究所,是一个手写体数字(0-9)数据库,该数据集包含60000个训练样本和10000个测试样本,数字已标准化于大小为28 x 28 的图像中。CIFAR-10 是由Geoffrey Hinton的学生Alex Krizhevsky 和Vinod Nair等人整理搭建的小型数据集,用于普通物体识别,该数据集包含60000张大小为32 x 32 x 3的图像,其中训练样本50000张、测试样本10000张。CIFAR-10数据集总共分为10个类别,分别是飞机、汽车、鸟、猫、鹿、狗、蛙、马、船和卡车。MNIST和CIFAR-10内容简洁、尺寸小,易于对抗攻击的实施,因此经常被作为评价对抗攻击性能的图像数据集。
2.1.3 常见的深度学习脆弱性检测(对抗攻击算法)
1. 白盒攻击算法
ILCM(最相似迭代算法)
FGSM(快速梯度算法)
BIM(基础迭代算法)
JSMA(显著图攻击算法)
DeepFool(DeepFool攻击算法)
C/W(C/W攻击算法)
2. 黑盒攻击算法
Single Pixel Attack(单像素攻击)
Local Search Attack(本地搜索攻击)
2.1.4 常见的深度学习脆弱性加固(对抗防御算法)
1. Feature squeezing(特征凝结)
2.Spatial smoothing(空间平滑)
3.Label smoothing(标签平滑)
4.Adversarial training(对抗训练)
5.Virtual adversarial training(虚拟对抗训练)
6.Gaussian data augmentation(高斯数据增强)
2.2 对抗攻击算法介绍
1. L-BFGS攻击
在探索深度学习可解释性的研究中,Szegedy等人证明了深度学习对加入特定扰动的输入样本表现出极强的脆弱性,并由此发现了对抗样本的存在,提出了第一个针对深度学习的对抗攻击方案L-BFGS,L-BFGS攻击的定义如公式所示。






5. JSMS显著图攻击算法
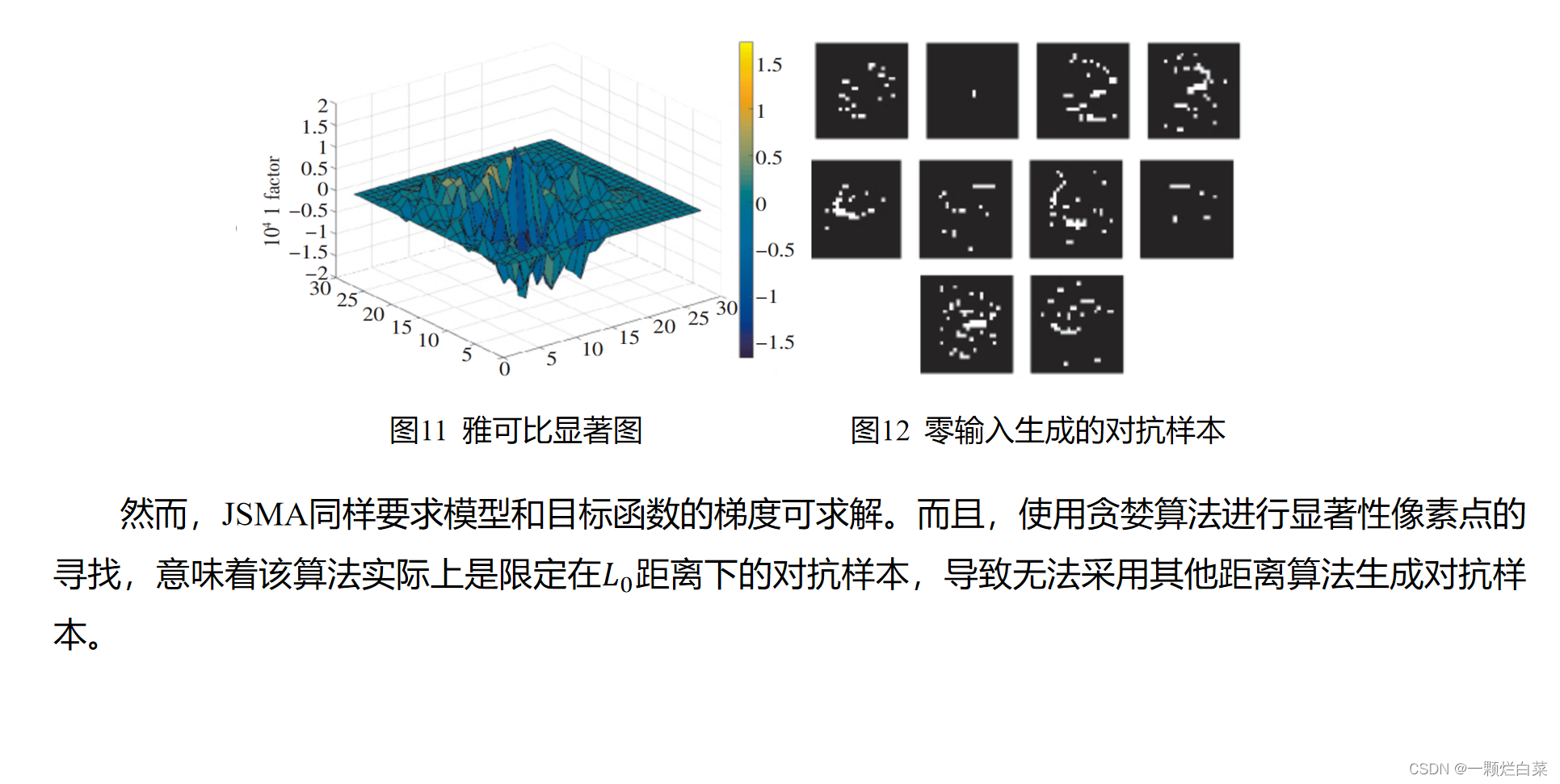
Papernot等人提出了使用雅可比显著图来生成对抗样本的方法。显著性矩阵是基于梯度的,神经网络的梯度给出了产生对抗样本所需的信息。 简单来说,想要使得样本被模型错误分类为目标标签t,必须增加模型输出的目标标签t的概率,同时减少其他标签的概率,直到目标标签的概率大于其他标签。这可以通过使用显著性矩阵(图11),有选择地改变图像的某些像素来实现。在求解出显著性矩阵后,通过算法选择显著性最大的像素,并对其进行修改,以增加分类为目标标签t的概率。重复这一过程,直到目标标签的概率大于其他标签,或达到了最大次数。通过给对抗样本生成算法提供零输入(全黑图像),产生的对抗样本如图4所示。每个样本的类别对应从0~9。可以看出,部分对抗样本可以由人眼识别出其对应的目标类别。


8. 单像素攻击算法
单像素攻击(Single Pixel Attack)是典型的黑盒攻击算法。Nina Narodytska和Shiva Prasad Kasiviswanathan在论文《Simple Black-Box Adversarial Perturbations for Deep Networks》中介绍了该算法。在白盒攻击中,我们根据一定的算法,在原始数据上叠加了精心构造的扰动,从而导致模型产生分类错误,而单像素攻击的基本思想是,可以通过修改原始数据上的一个像素的值,让模型产生分类错误。


针对一个像素点的修改可以对分类结果产生较大影响。但是当图像较大时,一个像素点的改变很难影响到分类结果。并且随着图像文件的增大,搜索空间也迅速增大,单像素攻击的效率也会快速下降。针对这一情况,有的单像素攻击在实现上允许同时修改一个以上的像素点,比如同时修改50个像素点,但是攻击效果并不明显。
本地搜索攻击算法(Local Search Attack)改进了单像素攻击算法,论文《Simple Black-Box Adversarial Per-turbations for Deep Networks》重点介绍了该算法。单像素攻击算法没有很好地利用模型的反馈信息去优化扰动,很大程度上依赖随机选择像素和选代调整像素点的值。本地搜索攻击算法的主要改进点就是根据模型的反馈信息去选择扰动的点,并随机选择对分类结果影响大的点周围的点,进步进行选择。
2.3 对抗防御算法介绍
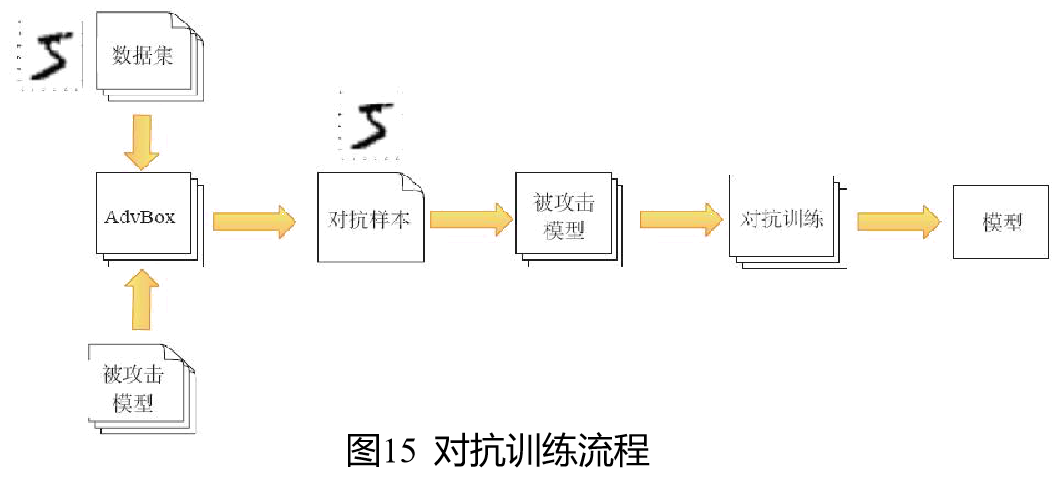
1. 对抗训练
Adversarial training如图所示,其基本思路是,常见的对抗样本生成算法是已知的,训练数据集也是已知的,那么可以通过常见的一些对抗样本工具箱,比如AdvBox或者FoolBox,在训练数据的基础上生成对应的对抗样本,然后让深度学习模型重新学习,让它认识这些常见的对抗样本,这样新生成的深度学习模型就具有了一定的识别对抗样本的能力。
2. 高斯数据增强
高斯数据增强(Gaussian data augmentation)最早由Zantedeschi等人在论文《Efficient Defenses Against Ad-versarial Attacks》中提出。高斯数据增强的原理非常简单,虽然对抗训练落地非常方便,但是问题也显而易见,就是难以穷尽所有的对抗样本,始终还是处于被动挨打的地位。那么是否有种方法可以尽量多地穷尽对抗样本呢?高斯数据增强算法认为,绝大多数的对抗样本相当于在原始图像上叠加了噪声,理想情况下可以用高斯噪声模拟这种噪声。
高斯数据增强的流程如图16所示,在模型的训练环节中,在原始数据的基础上叠加高斯噪声,然后进行监督学习,这样训练出来的模型就是加固后的模型。

三、对抗应用以及工具箱简介
3.1 对抗样本应用
对抗样本的发生通常依赖于深度学习网络的多维输入,机器视觉领域经常需要处理图像、视频等具有极高维度的数据,因此机器视觉领域天然就是对抗样本的舞台。
3.1.1 交通标志识别
识别交通标志是智能驾驶最基础的功能之一,也是对抗样本最早应用到物理攻击的一个场景。通常智能驾驶会根据高精地图、交通标志识别以及雷达传感器的数据进行综合判断,但是由于城市建设地图未及时更新、临时交通管制等因素,交通标志识别的结果的优先级通常会高于其他传感器,因此识别交通标志的功能一旦出现问题,造成的影响不容小觑。有安全研究者通过实验证明,可以在一个STOP的路牌上增加不明显的贴纸,最终让智能驾驶系统识别为60公里限速,如图7-8所示。

3.1.2 人脸识别
真人戴上一副特制的眼镜,就被人脸识别系统错误识别为另一个人。如果这些对抗攻击方法被用来干扰自动驾驶、人脸识别等应用系统,后果将不堪设想。 人物戴上特制眼镜被识别成其他人:

3.2 常见对抗样本工具箱简介
3.2.1 AdvBox
AdvBox是一款由百度安全实验室研发,在百度大范围使用的AI模型安全工具箱,目前原生支持PaddlePaddle、PyTorch、Caffe2、MXNet、Keras以及TensorFlow平台,方便广大开发者和安全工程师使用自己熟悉的框架。AdvBox同时支持GraphPipe,屏蔽了底层使用的深度学习平台,用户可以零编码,仅通过几个命令就可以对PaddlePaddle、PyTorch、Caffe2、MXNet、CNTK、ScikitLearn以及TensorFlow平台生成的模型文件进行黑盒攻击。
3.2.2 ART
ART(Adversarial Robustness Toolbox)是IBM研究团队开源的用于检测模型及对抗攻击的工具箱,帮助开发人员加强AI模型的防御性,让AI系统变得更加安全。
3.2.3 FoolBox
FoolBox由Bethge Lab[1]的三名德国科学家开发,能够帮助用户在解析“黑匣子”时更轻松地构建起攻击模型,并且在名人面部识别与高知名度Logo识别方面成功骗过美国热门的图片识别工具。
四、对抗攻击算法衡量指标
1. 图像相似度
通过对抗攻击算法生成的对抗样本与原始图像对比,如果相似度很高,则具有很好的隐蔽性。
2. 生成时间
从开始到攻击样本生成完毕所需的时间进行分析,相对大多数情况来说,生成的越快,则攻击算法越好,前提需要综合考虑。
3. 成功率
攻击深度学习模型,使得攻击后的学习模型出错的概率越大,则成功率越高。
4. 人工验证样本
通过调取社会人员对生成的目标对抗样本图像与原始图像进行比较,能够欺骗人的眼睛,如果看不出来任何破绽,则生成的对抗样本可行。
文章出处登录后可见!