本文会做经常性的更改,如有错误或者其他补充的,请各位大佬不吝指点。
如图所示为我们的示例输出的网络结构。
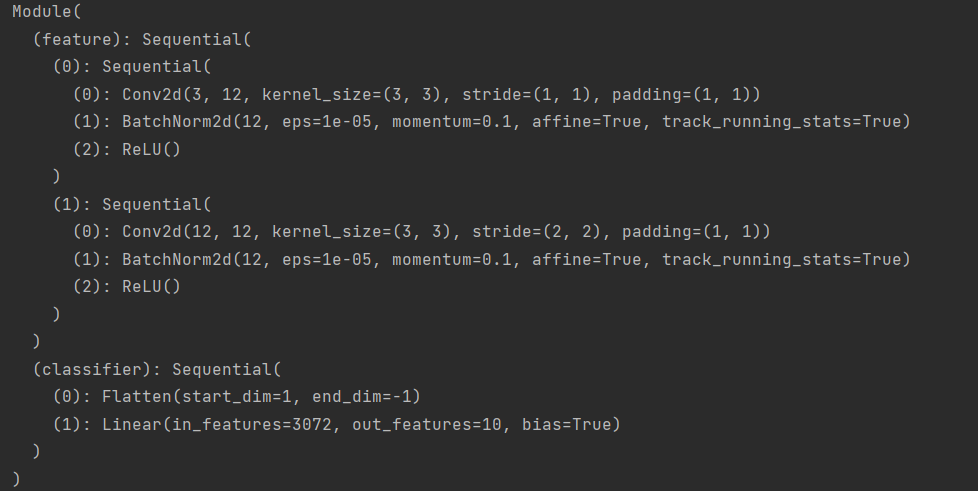
引入创建的模型:
import torch
import simple_module
mod = simple_module.Module()一、模型的保存与读取
1.整个模型的保存与读取
# 保存整个模型
torch.save(mod, '../parameters/mod.pth')
# 读取整个模型
mod_load = torch.load('../parameters/mod.pth')2.模型参数的保存与读取(以字典方式保存和读取)
# # 保存模型的参数(以字典的方式保存)
torch.save(mod.state_dict(), '../parameters/mod_parameter.pth')
# 查看保存了哪些参数
print(mod.state_dict().keys())
print(mod.state_dict()['feature.0.0.bias'])
# 读取模型的参数(以字典的方式读取)
mod.load_state_dict(torch.load('../parameters/mod_parameter.pth'))odict_keys(['feature.0.0.weight', 'feature.0.0.bias', 'feature.0.1.weight',
'feature.0.1.bias', 'feature.0.1.running_mean', 'feature.0.1.running_var',
'feature.0.1.num_batches_tracked', 'feature.1.0.weight', 'feature.1.0.bias',
'feature.1.1.weight', 'feature.1.1.bias', 'feature.1.1.running_mean',
'feature.1.1.running_var', 'feature.1.1.num_batches_tracked', 'classifier.1.weight',
'classifier.1.bias'])
tensor([-0.1721, -0.1222, 0.1023, -0.1484, -0.0547, -0.1922, -0.0796, -0.1784,
-0.0233, -0.0271, -0.1018, 0.1875])二、模型更改某一层
# 模型修改某一层
mod.classifier[1] = torch.nn.Linear(in_features=3072, out_features=20, bias=True)三、模型删除某些层
# 删除某一层,可以将该层设置为空序列
mod.classifier[1] = torch.nn.Sequential()
# 可以采用切片的方式删除,这样删除更加彻底
mod.classifier = torch.nn.Sequential(*list(mod.classifier.children())[:-1])
# 或者直接删除
mod.classifier.__delattr__('1')四、模型添加层(貌似只能在某一个块的末尾添加,后续再查找资料,有大佬可以指点一下)
# 模型添加层
mod.classifier.add_module(name='liner', module=torch.nn.Linear(in_features=3072, out_features=100, bias=True))五、冻结某些层,使得训练时不进行参数更行
1.冻结某一层
# 冻结某一层
mod.feature[0][0].weight.requires_grad = False2.冻结所有的参数
# 冻结所有的参数
for param in mod.parameters():
param.requires_grad = False3.冻结前面某部分的参数,可先将参数名称罗列出来,然后选择一部分的参数名称,利用参数的名称进行冻结。这种方式可以任意地冻结自己想要冻结的层。
no_grad = []
for name, value in mod.named_parameters():
# print(name)
no_grad.append(name)
no_grad = no_grad[:-4]
for name, value in mod.named_parameters():
if name in no_grad:
value.requires_grad = False
else:
value.requires_grad = True4.还有一种方式,就是只冻结前面几层
i = 0
for name, value in mod.named_parameters():
value.requires_grad = False
i = i + 1
if i == 4:
break;或者
model_parameters = model.named_parameters()
for i in range(freeze):
name, value = next(model_parameters)
value.requires_grad = False这是我目前想到的一个方法,还有其他方法的请大佬不吝指点。
无论哪种方式,都是将对应层的weight的requires_grad设置为False。
5.最后还需要给优化器设置过滤器
# 定义一个fliter,只传入requires_grad=True的模型参数
optimizer = optim.SGD(filter(lambda p : p.requires_grad, mod.parameters()), lr=1e-2)
文章出处登录后可见!
已经登录?立即刷新