本文已加入 🚀 Python AI 计划,从一个Python小白到一个AI大神,你所需要的所有知识都在我的 GitHub:https://github.com/kzbkzb/Python-AI 了。
1、 前言
今天是第十天。我们将使用LSTM预测股票的开盘价。最终的R2可以达到0.74,比传统RNN的0.72高出两个百分点。
我的环境:
- 地点:Python3六点五
- 编译:朱庇特笔记本
- 深度学习环境:tensorflow2四点一
来自专栏:[100例深度学习]
前几个时期的亮点:
- 100例深度学习卷积神经网络(lenet-5)深度学习中的“Hello word”|第22天
- 100例深度学习-卷积神经网络(CNN)实现MNIST手写数字识别|第一天
- 100例深度学习-卷积神经网络(CNN)服装图像分类|第3天
- 100例深度学习-卷积神经网络(CNN)花朵识别|第4天
- 100例深度学习-卷积神经网络(CNN)天气识别|第5天
- Vgg-100卷积神经网络识别海盗(第一天)
- 100例深度学习-卷积神经网络(resnet-50)鸟类识别|第8天
- 100例深度学习-循环神经网络(RNN)股票预测|第9天
如果你还是一点白,你可以看一下我的专栏给你:“小白介绍深学习”,帮你零基础介绍深学习。
2、 LSTM的作用是什么
神经网络程序的基本流程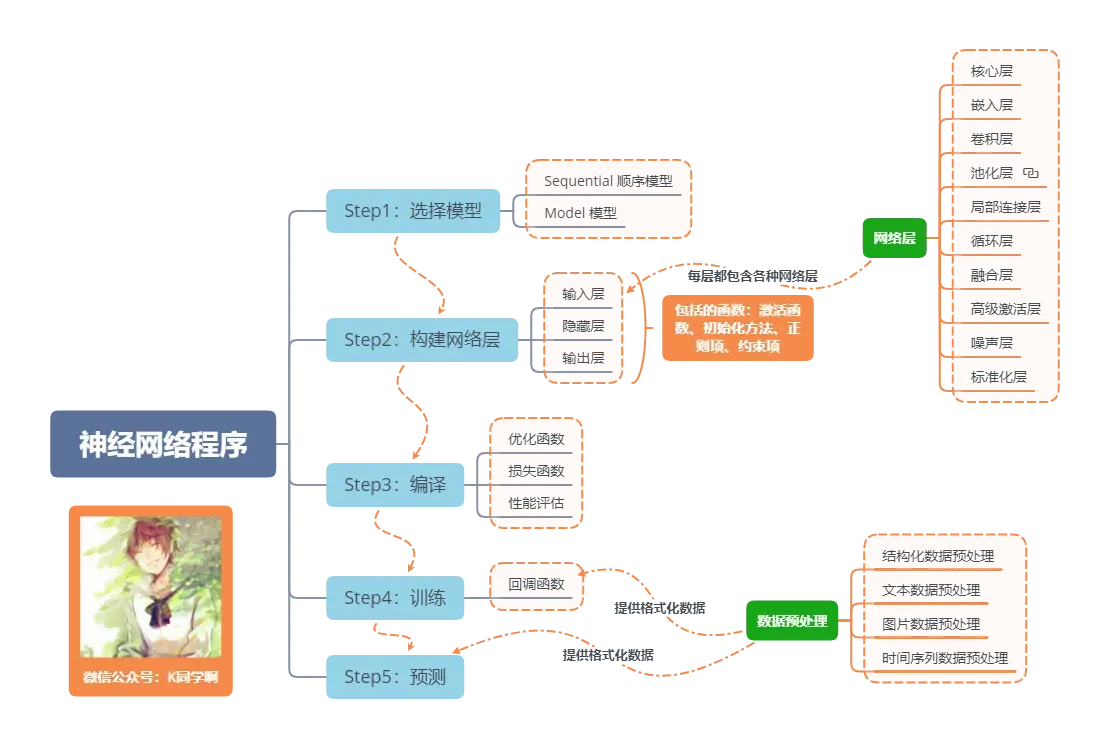
LSTM的一句话介绍是RNN的高级版本。如果RNN的最大限度是理解一个句子,那么LSTM的最大限度是理解一个段落。详情如下:
LSTM完全被称为长-短记忆网络,是一种能够学习长期依赖性的特殊RNN。LSTM由Hochreiter&schmidhuber(1997)提出。许多研究人员已经开展了一系列的工作来改进和发扬它。LSTM可以很好地解决许多问题,现在已被广泛使用。
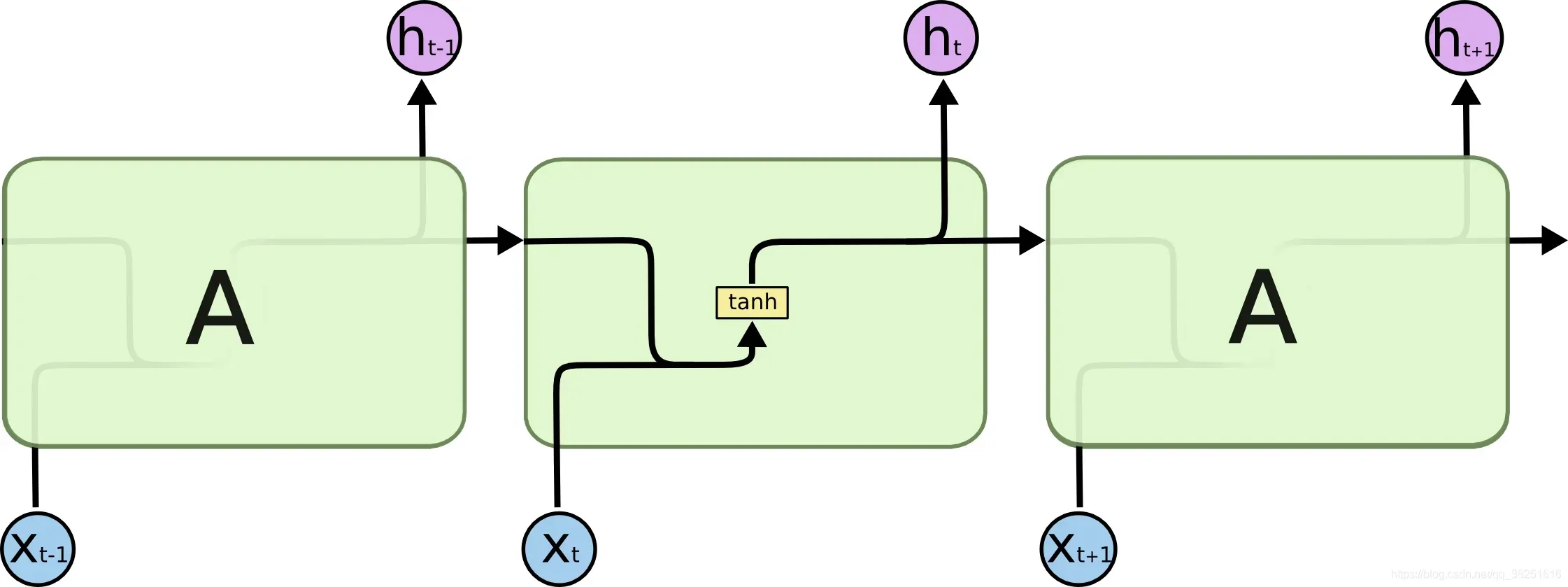
所有的递归神经网络都具有形成链的重复神经网络模块的形式。在普通RNN中,重复模块的结构非常简单,其结构如下:
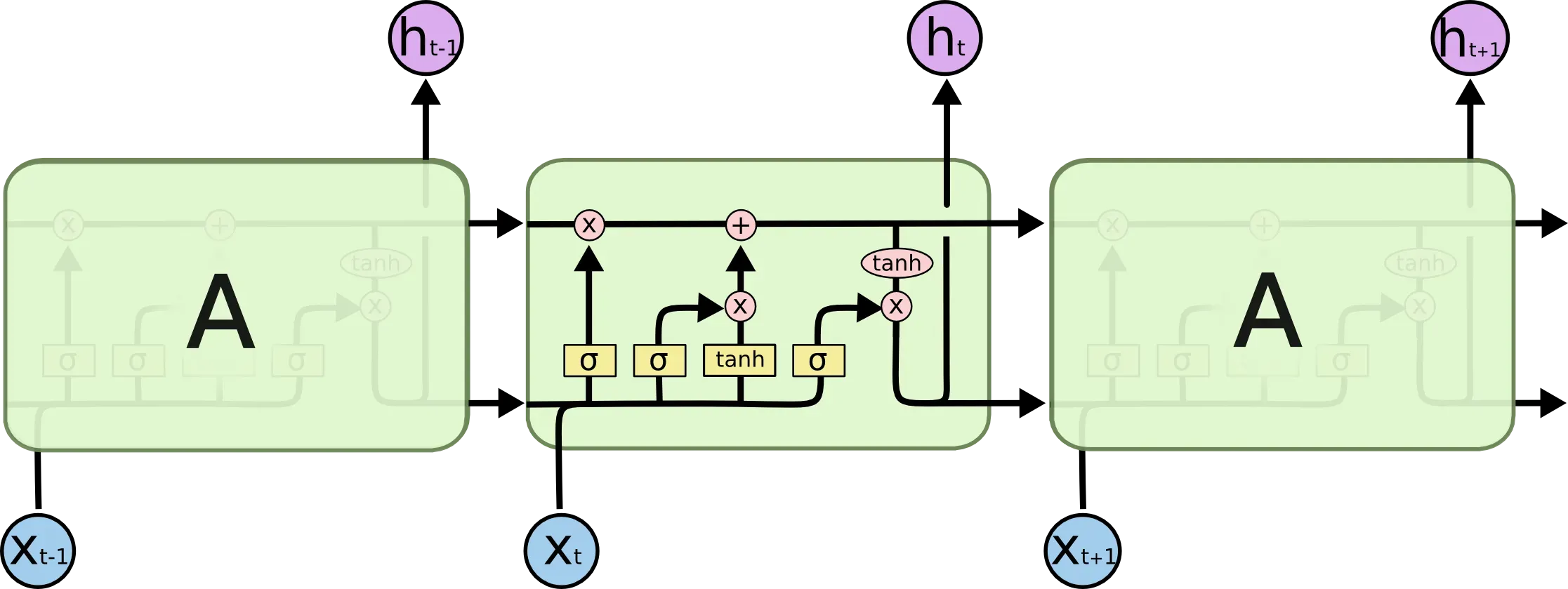
LSTM避免了长期依赖的问题。能记住长期的信息!LSTM具有相对复杂的结构。它可以通过选通状态选择和调整传输的信息,记住需要记住很长时间的信息,忘记不重要的信息。其结构如下:
3、 准备工作
1.设置GPU
如果使用了CPU,可以注释掉这部分代码。
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
2.设置相关参数
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
from numpy import array
from sklearn import metrics
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense,LSTM,Bidirectional
# 确保结果尽可能重现
from numpy.random import seed
seed(1)
tf.random.set_seed(1)
# 设置相关参数
n_timestamp = 40 # 时间戳
n_epochs = 20 # 训练轮数
# ====================================
# 选择模型:
# 1: 单层 LSTM
# 2: 多层 LSTM
# 3: 双向 LSTM
# ====================================
model_type = 1
3.加载数据
data = pd.read_csv('./datasets/SH600519.csv') # 读取股票文件
data
2426行×8列
"""
前(2426-300=2126)天的开盘价作为训练集,后300天的开盘价作为测试集
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
4、 数据预处理
1.规范化
#将数据归一化,范围是0到1
sc = MinMaxScaler(feature_range=(0, 1))
training_set_scaled = sc.fit_transform(training_set)
testing_set_scaled = sc.transform(test_set)
2.时间戳功能
# 取前 n_timestamp 天的数据为 X;n_timestamp+1天数据为 Y。
def data_split(sequence, n_timestamp):
X = []
y = []
for i in range(len(sequence)):
end_ix = i + n_timestamp
if end_ix > len(sequence)-1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return array(X), array(y)
X_train, y_train = data_split(training_set_scaled, n_timestamp)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test, y_test = data_split(testing_set_scaled, n_timestamp)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
5、 构建模型
# 建构 LSTM模型
if model_type == 1:
# 单层 LSTM
model = Sequential()
model.add(LSTM(units=50, activation='relu',
input_shape=(X_train.shape[1], 1)))
model.add(Dense(units=1))
if model_type == 2:
# 多层 LSTM
model = Sequential()
model.add(LSTM(units=50, activation='relu', return_sequences=True,
input_shape=(X_train.shape[1], 1)))
model.add(LSTM(units=50, activation='relu'))
model.add(Dense(1))
if model_type == 3:
# 双向 LSTM
model = Sequential()
model.add(Bidirectional(LSTM(50, activation='relu'),
input_shape=(X_train.shape[1], 1)))
model.add(Dense(1))
model.summary() # 输出模型结构
WARNING:tensorflow:Layer lstm will not use cuDNN kernel since it doesn't meet the cuDNN kernel criteria. It will use generic GPU kernel as fallback when running on GPU
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50) 10400
_________________________________________________________________
dense (Dense) (None, 1) 51
=================================================================
Total params: 10,451
Trainable params: 10,451
Non-trainable params: 0
_________________________________________________________________
6、 激活模型
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
7、 培训模式
history = model.fit(X_train, y_train,
batch_size=64,
epochs=n_epochs,
validation_data=(X_test, y_test),
validation_freq=1) #测试的epoch间隔数
model.summary()
Epoch 1/20
33/33 [==============================] - 5s 107ms/step - loss: 0.1049 - val_loss: 0.0569
Epoch 2/20
33/33 [==============================] - 3s 86ms/step - loss: 0.0074 - val_loss: 1.1616
Epoch 3/20
33/33 [==============================] - 3s 83ms/step - loss: 0.0012 - val_loss: 0.1408
Epoch 4/20
33/33 [==============================] - 3s 78ms/step - loss: 5.8758e-04 - val_loss: 0.0421
Epoch 5/20
33/33 [==============================] - 3s 84ms/step - loss: 5.3411e-04 - val_loss: 0.0159
Epoch 6/20
33/33 [==============================] - 3s 81ms/step - loss: 3.9690e-04 - val_loss: 0.0034
Epoch 7/20
33/33 [==============================] - 3s 84ms/step - loss: 4.3521e-04 - val_loss: 0.0032
Epoch 8/20
33/33 [==============================] - 3s 85ms/step - loss: 3.8233e-04 - val_loss: 0.0059
Epoch 9/20
33/33 [==============================] - 3s 81ms/step - loss: 3.6539e-04 - val_loss: 0.0082
Epoch 10/20
33/33 [==============================] - 3s 81ms/step - loss: 3.1790e-04 - val_loss: 0.0141
Epoch 11/20
33/33 [==============================] - 3s 82ms/step - loss: 3.5332e-04 - val_loss: 0.0166
Epoch 12/20
33/33 [==============================] - 3s 86ms/step - loss: 3.2684e-04 - val_loss: 0.0155
Epoch 13/20
33/33 [==============================] - 3s 80ms/step - loss: 2.6495e-04 - val_loss: 0.0149
Epoch 14/20
33/33 [==============================] - 3s 84ms/step - loss: 3.1398e-04 - val_loss: 0.0172
Epoch 15/20
33/33 [==============================] - 3s 80ms/step - loss: 3.4533e-04 - val_loss: 0.0077
Epoch 16/20
33/33 [==============================] - 3s 81ms/step - loss: 2.9621e-04 - val_loss: 0.0082
Epoch 17/20
33/33 [==============================] - 3s 83ms/step - loss: 2.2228e-04 - val_loss: 0.0092
Epoch 18/20
33/33 [==============================] - 3s 86ms/step - loss: 2.4517e-04 - val_loss: 0.0093
Epoch 19/20
33/33 [==============================] - 3s 86ms/step - loss: 2.7179e-04 - val_loss: 0.0053
Epoch 20/20
33/33 [==============================] - 3s 82ms/step - loss: 2.5923e-04 - val_loss: 0.0054
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50) 10400
_________________________________________________________________
dense (Dense) (None, 1) 51
=================================================================
Total params: 10,451
Trainable params: 10,451
Non-trainable params: 0
_________________________________________________________________
8、 结果可视化
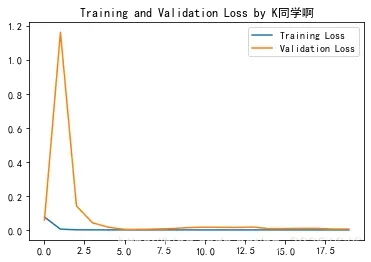
1.绘制损耗图
plt.plot(history.history['loss'] , label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss by K同学啊')
plt.legend()
plt.show()
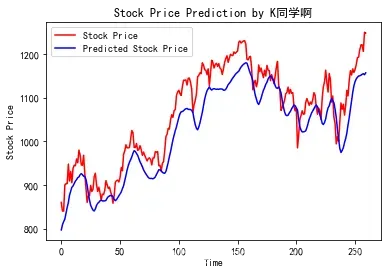
2.预测
predicted_stock_price = model.predict(X_test) # 测试集输入模型进行预测
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(y_test)# 对真实数据还原---从(0,1)反归一化到原始范围
# 画出真实数据和预测数据的对比曲线
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction by K同学啊')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
3.评估
"""
MSE :均方误差 -----> 预测值减真实值求平方后求均值
RMSE :均方根误差 -----> 对均方误差开方
MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方误差: %.5f' % MSE)
print('均方根误差: %.5f' % RMSE)
print('平均绝对误差: %.5f' % MAE)
print('R2: %.5f' % R2)
均方误差: 2688.75170
均方根误差: 51.85317
平均绝对误差: 44.97829
R2: 0.74036
除了改变模型外,还可以通过调整参数来提高拟合度。这主要是关于LSTM,因此没有详细介绍调整参数。
前几个时期的亮点:
- 100例深度学习-卷积神经网络(CNN)实现MNIST手写数字识别|第一天
- 100例深度学习-卷积神经网络(CNN)服装图像分类|第3天
- 100例深度学习-卷积神经网络(CNN)花朵识别|第4天
- 100例深度学习-卷积神经网络(CNN)天气识别|第5天
- Vgg-100卷积神经网络识别海盗(第一天)
- 100例深度学习-卷积神经网络(resnet-50)鸟类识别|第8天
- 100例深度学习-循环神经网络(RNN)股票预测|第9天
专栏:100例深度学习案例
如果你认为这篇文章对你有帮助,记得要注意、表扬并添加收藏
最后,我将给您另一份副本,以帮助您获得bat和其他一线制造商的数据结构。这是谷歌和阿里巴巴的老板们写的。这对算法薄弱或需要改进的学生非常有用(提取代码:9go2):
谷歌和阿里巴巴的Leetcode笔记
除了我整理的7K+开源电子书,总有一本可以帮助你💖 (提取代码:4eg0)
7K+开源电子书
版权声明:本文为博主K同学啊原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_38251616/article/details/117907074