内容
什么是逻辑回归?
Sigmoid 函数
似然函数
梯度下降
决策边界
损失函数
逻辑回归的优点
逻辑回归的缺点
代码
Logistic Regression参数详解
正则化选择参数:penalty
优化算法选择参数:solver
其他参数
代码案例
结果表明
每个文本一个字
👇👇🧐🧐✨✨🎉🎉
欢迎点击专栏其他文章(欢迎订阅,持续更新~)
机器学习之Python开源教程——专栏介绍及理论知识概述
机器学习框架和评估指标详解
Python监督学习之分类算法的概述
数据清洗、数据集成、数据归约、数据转换和数据预处理的离散化
特征工程之One-Hot编码、label-encoding、自定义编码
卡方分箱、KS分箱、最优IV分箱、树结构分箱、自定义分箱
用于特征选择、基于模型的选择、迭代选择的单变量统计
朴素贝叶斯机器学习分类算法
【万字详解·附代码】机器学习分类算法之K近邻(KNN)
《全网最强》详解机器学习分类算法决策树(附可视化和代码)
机器学习分类算法的支持向量机
机器学习分类算法的随机森林(综合学习算法)
继续更新~
关于作者
博客名:王小王-123
简介:CSDN博客专家、CSDN签约作者、华为云享专家,腾讯云、阿里云、简书、InfoQ创作者。公众号:书剧可诗画,2020年度CSDN优秀创作者。左手诗情画意,右手代码人生,欢迎一起探讨技术的诗情画意!
什么是逻辑回归?
逻辑回归算法用于解决分类问题。回归和分类的区别在于回归预测的目标变量的值是连续的(比如房子的价格);而分类预测的目标变量的值是离散的(如判断肿瘤大小是否为恶性)。
如图所示,X为数据点-肿瘤的大小,Y为观测值-是否为恶性肿瘤(0良性肿瘤,1恶性肿瘤)。通过构建线性回归模型,即可根据肿瘤大小,预测是否为恶性肿瘤,hθ(x)≥.05为恶性,hθ(x)<0.5为良性。
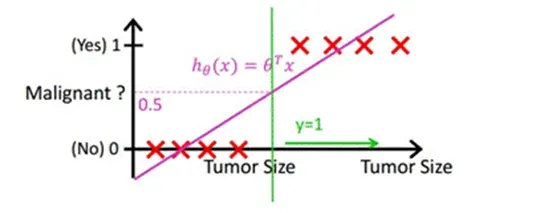
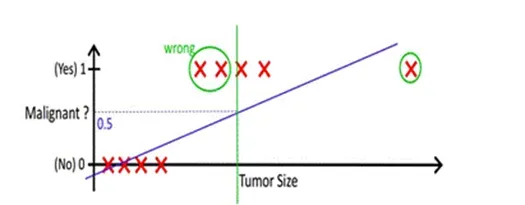
那有的人就会提出疑问,逻辑回归可以做分类,那么线性回归可不可以做分类呢?答案是可以,但是线性回归的鲁棒性(稳定和可靠)很差,如下图所示,因最右边噪点的存在,使回归模型在训练上表现很差,这主要是由于线性回归在整个实数域内敏感度一致,而分类范围,需要在[0,1]。
逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,此时引入了一个sigmoid函数,这个函数的性质,非常好的满足了,函数的定义域x的输入是全体实数,而值域输出y总是[0,1],以一种概率的形式表示。并且当x=0的时,y=0.5, 这是决策边界。
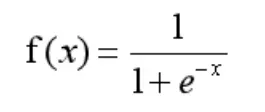
Sigmoid 函数
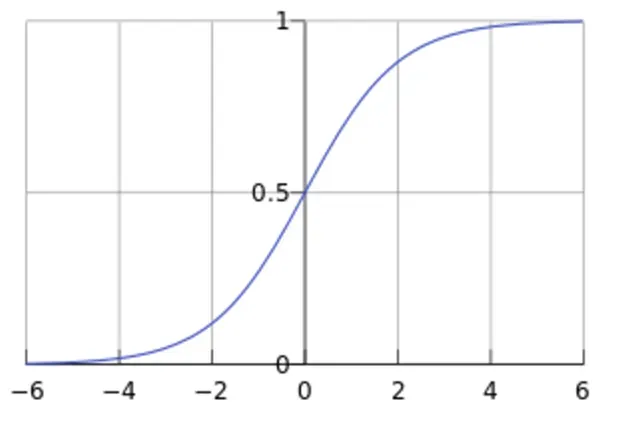
Sigmoid 函数在有个很漂亮的“S”形,如下图所示:
对于线性回归的情况,方程如下:
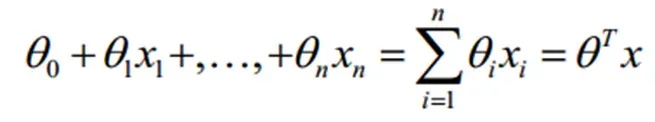
构造预测函数为:取值在[0,1]
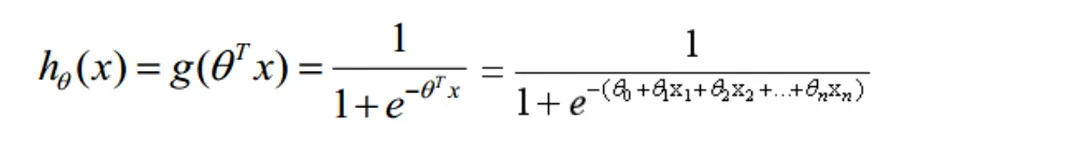
LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
(1) 导入模型。调用逻辑回归LogisticRegression()函数。
(2) fit()训练。调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
(3) predict()预测。利用训练得到的模型对数据集进行预测,返回预测结果。
似然函数
最大似然估计是通过已知结果推断出导致该结果的概率最大的参数。最大似然估计是概率论在统计学中的应用。它提供了在给定观测数据的情况下评估模型参数的方法,即“模型已确定,参数未知”,并通过多次实验观察结果。利用实验结果得到一定的参数值,可以使样本出现的概率最大化,称为最大似然估计。逻辑回归是一种监督学习。它有训练标签,即有已知结果。从这个已知结果出发,我们可以推导出能够获得最大概率的结果参数。只要我们得到这个参数,那么我们的模型自然就可以非常准确地预测未知数据。
梯度下降
当我们确定目标时,我们需要一个算法来解决问题,而最常用也更容易使用的就是梯度下降。
我们先来看看官网是如何介绍梯度下降的:梯度的本义是一个向量(vector),意思是一个函数在这一点的方向导数沿着这个方向取最大值,即函数在这一点上沿最大值的方向。这个方向(这个梯度的方向)变化最快,变化率最大(也就是这个梯度的模量)。
白话理解:就是你现在被蒙在山顶上,你正在下山。你必须一步一步地向山的一侧移动。山的一侧是一个坡度。每次你向下移动一点,你就在下降。当你到达山脚下,你就成功了。
稍微专业点的:我们对一个多元函数求偏导,会得到多个偏导函数.这些导函数组成的向量,就是梯度.我们用梯度下降是用来求解一个损失函数的最小值,所谓下降实际上是这个损失函数的值在下降。
在梯度下降算法中,还有两个比较重要的点,分别是学习率和步数。
学习率是指你在下山的过程中每走的一步大小,你要是厉害能一步跨到山底也算是你厉害,当然你也有可能跨到对面山上,所以学习率我们在设置的时候就要设置的稍微小点,当然也别太小了,这样学习的会很慢。学习率是自己设定的,比如0.01。
迭代次数是指下山时要走多少步。如果它很小,您可能无法到达山脚。人多的话,可以在山脚下来回走一走。
学习率和迭代次数是定制的,需要通过经验和实际操作来验证和设置。最好在运行代码的时候打印出来,就会看到收敛的情况。当长时间收敛效果不明显的时候,基本就结束了。
梯度下降的三种方法:
批量梯度下降BGD(Batch Gradient Descent):优点:会获得全局最优解,易于并行实现。缺点:更新每个参数时需要遍历所有的数据,计算量会很大并且有很多的冗余计算,导致当数据量大的时候每个参数的更新都会很慢。
随机梯度下降SGD:优点:训练速度快;缺点:准确率下降,并不是全局最优,不易于并行实现。它的具体思路是更新没一个参数时都是用一个样本来更新。(以高方差频繁更新,优点是使得sgd会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加的复杂)
small batch梯度下降:结合了上述两点的优点,每次更新参数时仅使用一部分样本,减少了参数更新的次数,可以达到更加稳定的结果,一般在深度学习中采用这种方法。
决策边界
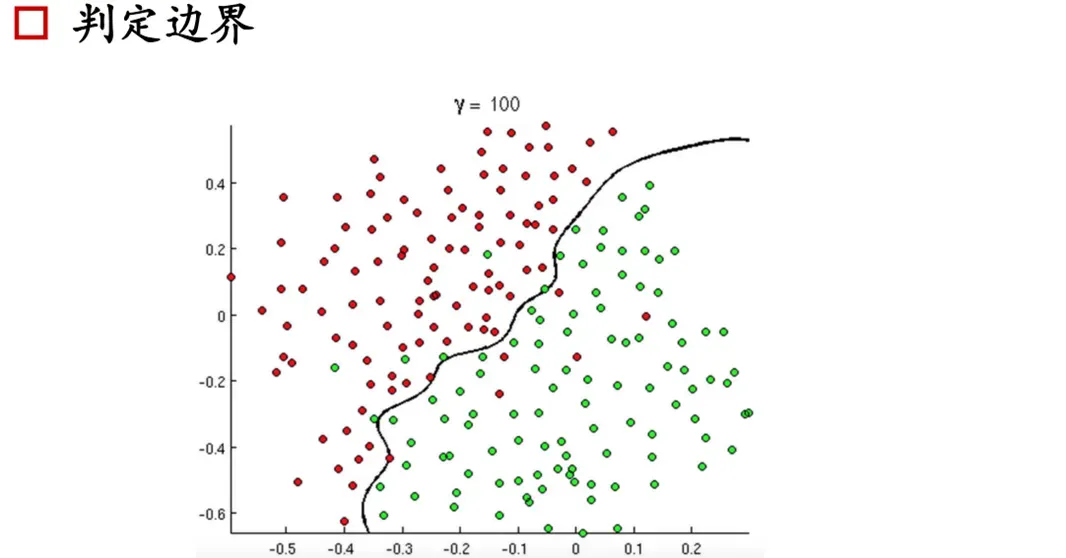
通过上面的界限,你应该也能理解逻辑回归的原理了。很容易想到我们的支持向量机使用的超平面,而逻辑回归是线性可分的,所以肯定有损失函数。
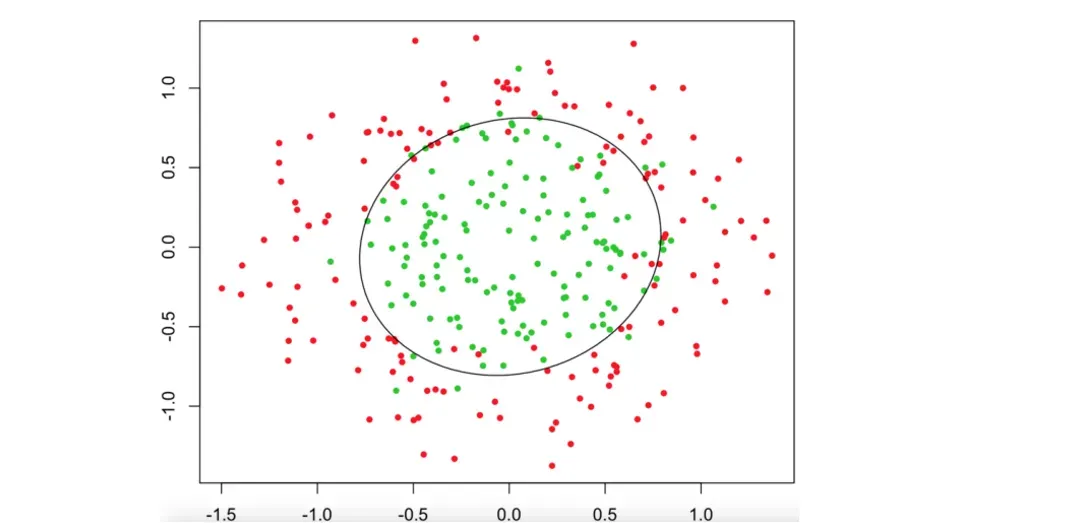
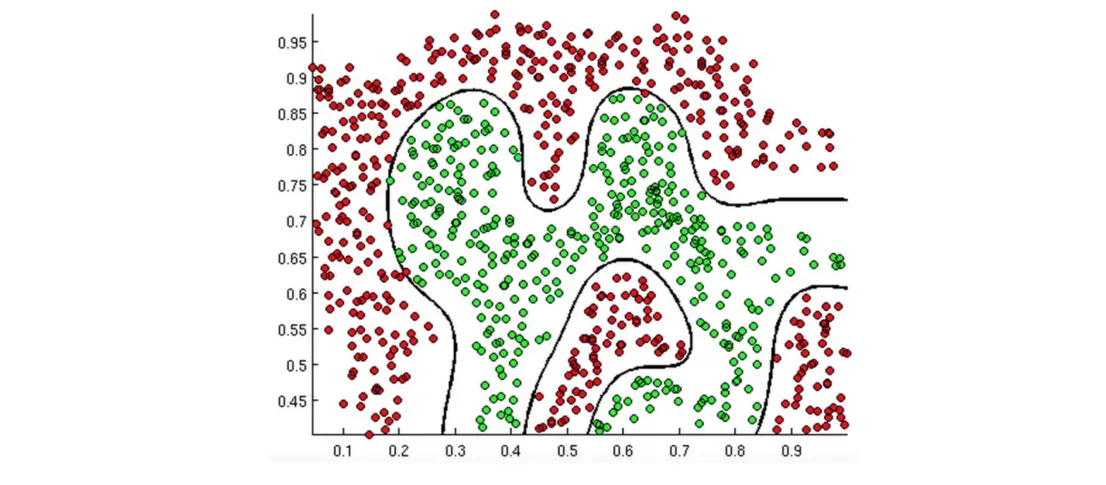

损失函数
损失函数用于评估模型的预测值与实际值的差异程度。损失函数越好,模型的性能就越好。不同模型使用的损失函数一般是不同的。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数是指预测结果与实际结果之间的差异,结构风险损失函数是指经验风险损失函数加上正则项。
通俗的讲,损失函数=代价函数=目标函数,三者的意思是一样的。
但它们之间有细微的差别。
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
目标函数:目标函数跟它俩有联系,但不是一个意思。目标函数是一个最优化函数,它是由经验风险+结构风险(也就是Cost Function + 正则化项)构成。
比如说:我们需要优化模型,我们得有个目标把,比如说我们误差不能大于0.1 ,那这个0.1就是我们的目标函数,但是技术不行,最后只能把误差维持在0.2,那么0.1就是目标函数,0.2就是损失函数,当技术好的情况下,将误差降低在0.1 那么损失=目标。
下面介绍逻辑回归中常用的损失函数。逻辑回归主要是一个分类模型,所以也用到了分类损失函数:
1)交叉熵损失:上面基本也都介绍了就不多说了。
2)Hinge Loss/多分类 SVM 损失:简言之,在一定的安全间隔内(通常是 1),正确类别的分数应高于所有错误类别的分数之和。因此 hinge loss 常用于最大间隔分类(maximum-margin classification),最常用的是支持向量机。
虽然不可微,但它是一个凸函数,因此使用机器学习领域常用的凸优化器是微不足道的。
逻辑回归的优点
首先,逻辑回归的算法比较成熟,预测比较准确;
二是模型求出的系数易于理解,便于解释,尤其在银行业,80%的预测是使用逻辑回归;
三是结果是一个概率值;
第四,训练速度快。

逻辑回归的缺点
分类较多的y都不是很适用;(多分类不适用)
对自变量的多重共线性敏感,需要进行因子分析或聚类分析来选择具有代表性的自变量; (需要做特征筛选)
另外预测结果呈现S型,两端概率变化小,中间概率变化大比较敏感,导致很多区间的变量的变化对目标概率的影响没有区分度,无法确定阈值。
综上所述:回归假设数据服从伯努利分布,通过最大似然函数的方法,利用梯度下降法求解参数,最终达到数据二分类的目的。
代码
Logistic Regression参数详解
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)其中,参数 penalty 表示惩罚项( L1 、 L2 值可选
L1 向量中各元素绝对值的和,作用是产生少量的特征,而其他特征都是0,常用于特征选择;
L2向量中各个元素平方之和再开根号,作用是选择较多的特征,使他们都趋近于0。);
C值的目标函数约束条件:s.t.||w||1
正则化选择参数:penalty
在调参时如果我们主要的目的只是为了解决过拟合,一般penalty选择L2正则化就够了。但是如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化。另外,如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。
penalty参数的选择会影响我们损失函数优化算法的选择。即参数solver的选择,如果是L2正则化,那么4种可选的算法{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}都可以选择。
但是如果penalty是L1正则化的话,就只能选择‘liblinear’了。这是因为L1正则化的损失函数不是连续可导的,而{‘newton-cg’, ‘lbfgs’,‘sag’}这三种优化算法时都需要损失函数的一阶或者二阶连续导数。而‘liblinear’并没有这个依赖。
优化算法选择参数:solver
solver参数决定了我们对逻辑回归损失函数的优化方法,有4种算法可以选择,分别是:
a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候,SAG是一种线性收敛算法,这个速度远比SGD快。关于SAG的理解,参考博文线性收敛的随机优化算法之 SAG、SVRG(随机梯度下降)
从上面的描述可以看出,newton-cg, lbfgs和sag这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear通吃L1正则化和L2正则化。
同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
newton-cg, lbfgs和sag这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear通吃L1正则化和L2正则化。
其他参数
这里的参数只做介绍,一般不需要调试
sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。
但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
对于多分类问题,只有 ‘newton-cg’、’sag’、’saga’ 和 ‘lbfgs’ 能够处理多项损失,
而 ‘liblinear’ 面对多分类问题,得先把一种类别作为一个类别,剩余的所有类别作为另外一个类别。依次类推,遍历所有类别,进行分类。max_iter: int, default: 100 ——最大迭代次数。当选择newton – cg, sag and lbfgs这三种算法时才能用。
multi_class: str, {‘ovr’, ‘multinomial’}, default: ‘ovr’ ——指定对于多分类问题的策略,可以为如下的值。
‘ovr’ :采用one – vs – rest策略。OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。
具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,
然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。T-1
‘multinomial’:many-vs-many(MvM) 直接采用多分类逻辑回归策略。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,
不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
从上面的描述可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。
‘auto’ 顾名思义根据实际情况,自动选择,它主要依据 solver 参数来决定,逻辑为如果 solver 为 liblinear,multi_class 为 ovr,如果分类类别大于 2,multi_class 为 multinomial,否则为 ovr
warm_start: bool, default: False ——如果为True,那么使用前一次训练结果继续训练,否则从头开始训练。n_jobs: int, default: 1 ——指定任务并行时的CPU数量。如果为 – 1则使用所有了用的CPU。
一般来说,我们知道这些参数所使用的的场景,那么就会少走一些坑,比如我们知道L1,L2正则项的意义是什么,L2主要解决过拟合,L1特征选取,也可以解决过拟合,默认是L2
代码案例
具体的代码步骤,我这里就不一一的做详细的解释了,因为我喜欢在jupyter notebook中机器学习,每一步都可以知道如何优化,下面的案例我首先通过逻辑回归进行调参,并使用相关系数进行特征选取,然后得出的效果分数可以达到91%,这比不做特征选取要好很多,随后我又使用逻辑回归自带的特征评估权重做了一次选取,最后效果有所提升。
feature_weight = model.coef_.tolist()[0]
feature_name = X_name
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
print(feature_sort.index)
plt.figure(figsize=(10,8))
sns.barplot(feature_sort.values,feature_sort.index, orient='h')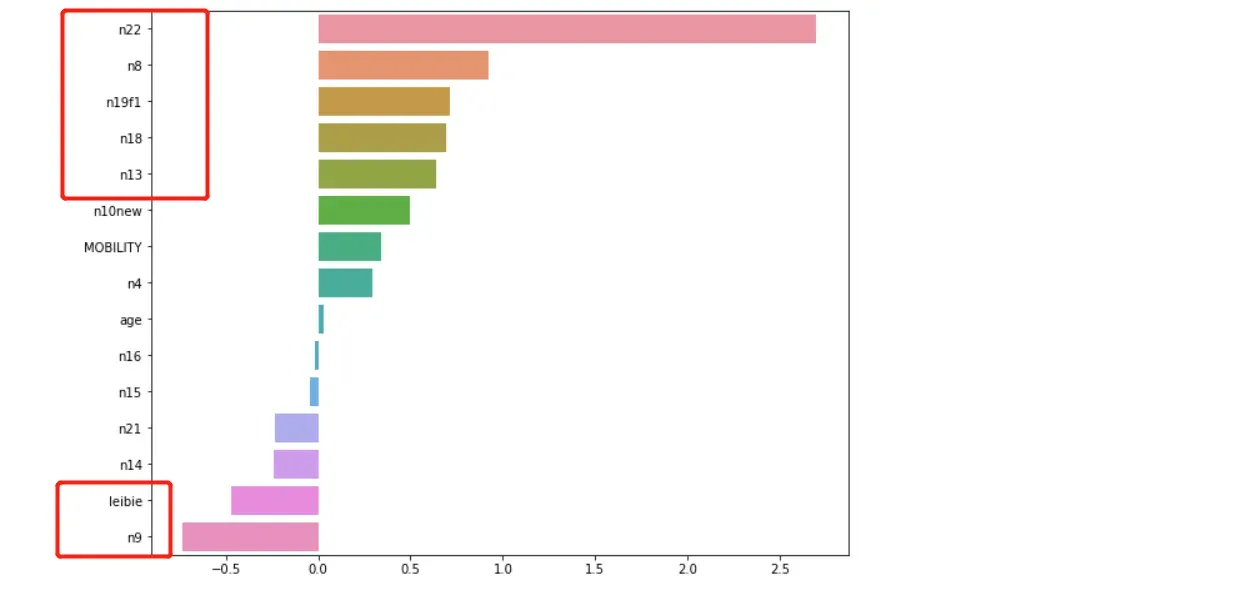
选取了8个重要的特征
完整代码如下。由于数据集为科研数据,此处不做导入说明。
# 导入数据 分割数据
df=**************不做展示***********************
# # 特征筛选(经过一番测试,不需要进行特征筛选)
# X_name=df.corr()[["n23"]].sort_values(by="n23",ascending=False).iloc[1:9].index.values.astype("U")
# X_name=feature_sort.index[:1]
# 测试出来的最佳特征!!!!!!!!
X_name=['n22', 'n8', 'n19f1', 'n18', 'n13', 'n10new','n9','leibie']
print(X_name)
X=df.loc[:,X_name]
# X=df.iloc[:,:-1]
y=df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
# X_train
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = LogisticRegression(C=i,penalty="l2").fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C=C_range[score.index(max(score))]
#设置标题
plt. title(f' LogisticRegression {max(score)}')
#设置x轴标签
plt. xlabel(' C')
#设置y轴标签
plt. ylabel(' Score')
#添加图例
# plt. legend()
plt.plot(C_range, score)
plt.show()
solvers = ["newton-cg", "lbfgs", "liblinear","sag"]
for solver in solvers:
clf = LogisticRegression(solver=solver,
C=best_C
).fit(X_train, y_train)
print("The accuracy under solver %s is %f" % (solver, clf.score(X_test, y_test)))
best_sover='liblinear'
model=LogisticRegression(C=11.02673469387755,penalty='l2',solver=best_sover)
# 训练模型
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\n',
classification_report(y_test,y_pred))
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 预测正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,返回两列,第一列代表类别0,第二列代表类别1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真阳性标签,就是说是分类里面的好的标签,这个要看你的特征目标标签是0,1,还是1,2
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()结果表明
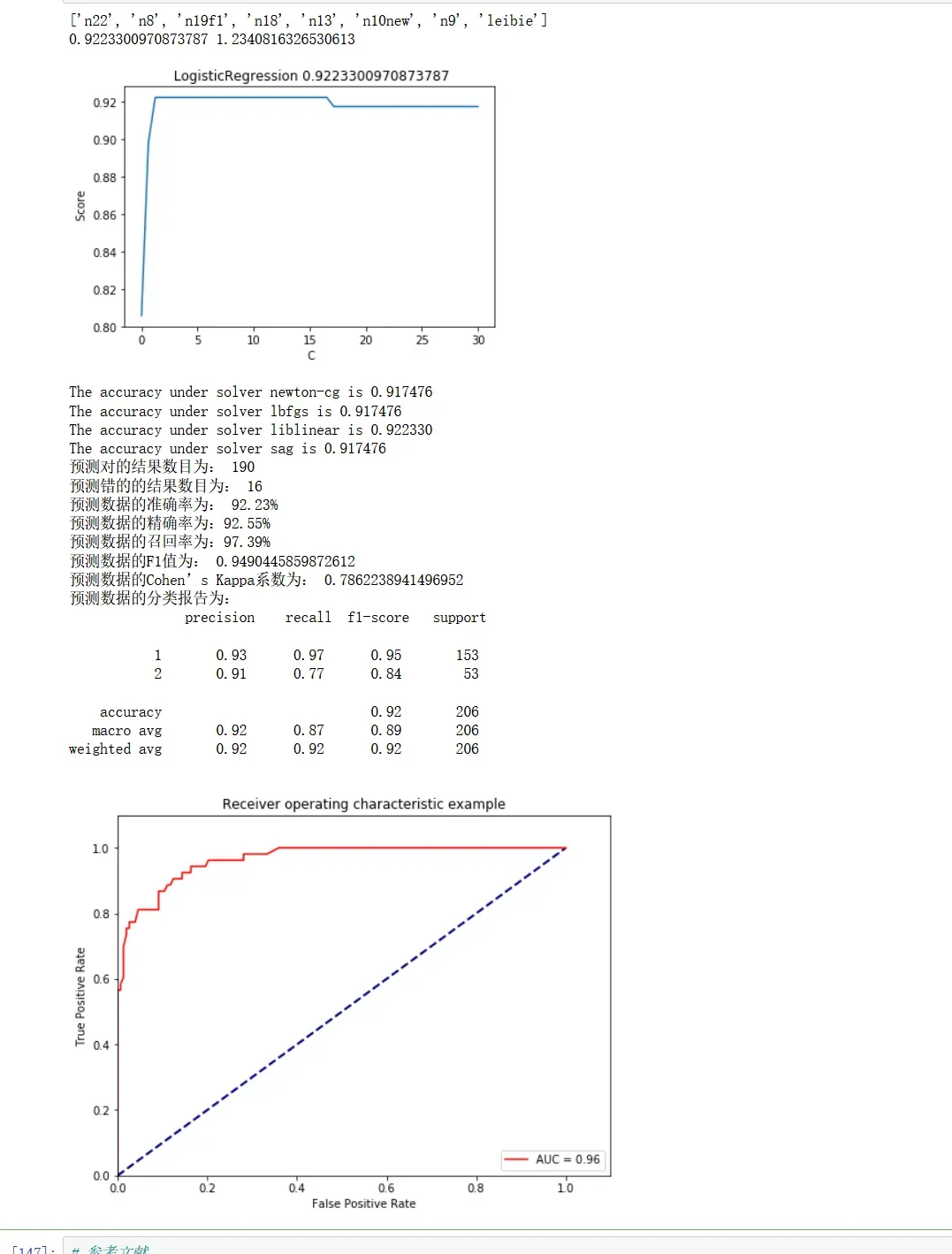
效果还是有提升的。经过反复调试,我们的逻辑回归就完成了!
每个文本一个字
幸福是你付出的,而不是你得到的!
版权声明:本文为博主王小王-123原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_47723732/article/details/122814429