目标检测 YOLOv5 – Sample Assignment
flyfish
target是通过标注数据构建的 例如包括 目标的类别,目标的位置这些已知内容。
BBox就是bounding box,边框。
target里面的边框就是Ground Truth BBox,简称 GT BBox或者GT Box,就是人告诉计算机的,已知的正确答案。
通过模型输出的边框就是 Predicated BBox,
我们期望Predicated BBox结果就是GT BBox。两者交流不方便的时候就增加了一个中介,这两种边框存在一个中介,这个中介就是Anchor BBox,有时简称anchor。
当发现prior box,prior bbox,先验框这样的词汇的时候,不用疑惑,它就是anchor,是人为通过程序生成的一些边框。程序生成的边框坐标是固定的,即anchor的坐标是固定,这不是正确答案。anchor的坐标就想和GT BBox这个正确答案匹配
那么它是如何匹配的呢?
一个anchor对应一个GT BBox的情况
一种是GT BBox找到与其IoU最大的那个anchor匹配,每个GT BBox都有个anchor匹配
如果没有anchor的时候,需要直接回归GT BBox的坐标,有anchor的时候,回归的时候就可以回归两者的偏移量,两个边框上下左右各差多少,即人为生成的anchor的与标准答案GT BBox之间的差别。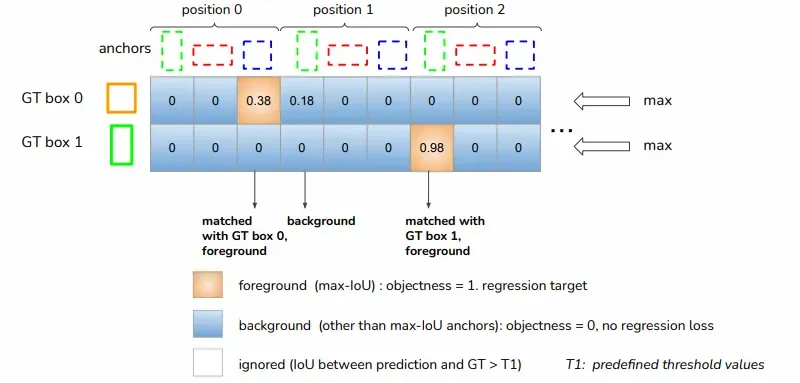
多个anchor对应一个GT BBox的情况
YOLOv5 是这样来比较人为生成的anchor的与标准答案 gt box之间的差别
通过两个量来变:一个是中心点的偏移,anchor的中心点如何变gt box的中心点
另一个是 宽度和高度的缩放系数, 相对于GT BBox的宽度和高度,anchor的宽度和高度各自变大了,还是变小了。
通过两个量的偏移变化,anchor就变GT BBox了,
这就是一个被确定为正样本的anchor 如何变GT BBox的过程
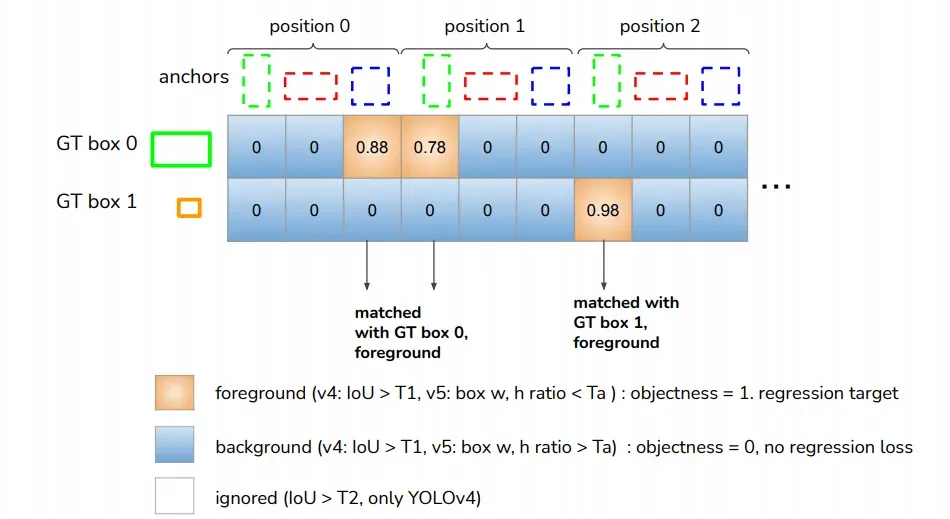
这种宽度和高度的缩放系数在文件hyp.scratch.yaml里面存着。
anchor_t: 4.0 # anchor-multiple threshold
YOLO各个版本的Sample Assignment
YOLOv3的时候是 一个target center对应一个target grid cell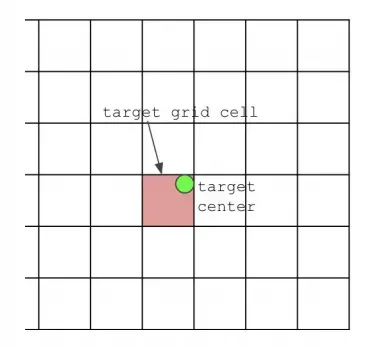
YOLOv5的时候一个target grid cell是不够的,一个target center对应三个target grid cell。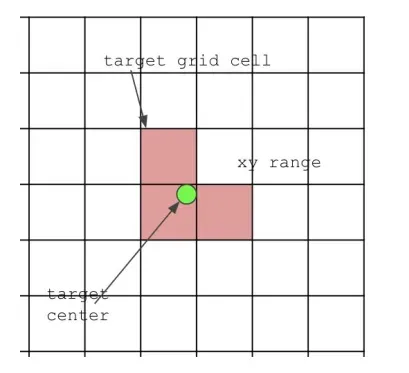
除了本身的target grid cell,还要从它的上下左右4个grid cell再选择两个。也就是前景foreground与背景background的区分。
原来他们只是叫做grid cell,被选中之后就成了target grid cell。
代码中是这样描述的(utils/loss.py)
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
gxy % 1 是浮点求模
选择之后的结果(utils/loss.py)
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
tensor([[ 0.00000, 0.00000],
[ 0.50000, 0.00000],
[ 0.00000, 0.50000],
[-0.50000, 0.00000],
[ 0.00000, -0.50000]], device=‘cuda:0’)
原点不动,向右,向下,向左,向上
往右、往下、往左、往上,分别用字母 j k l m 表示
编写一下代码将gij可视化的结果是
特征图有三种,所以有3种情况
模型的输出,其中80,40,20就是特征图大小
torch.Size([16, 3, 80, 80, 85])
torch.Size([16, 3, 40, 40, 85])
torch.Size([16, 3, 20, 20, 85])
都是三个target grid cell做为一个小组
anchor通过配置文件或者自动计算
YOLOv5是几乘以几的grid,即有多少个grid cell?
这样问是因为YOLOv1和YOLOv2的思路,YOLOv3的时候思路稍微变化。
答:YOLOv5是stride 8、16和32使用3个多尺度输出。YOLOv3和YOLOv5是一个思路。已经不是一个grid,而是三个grid。
每个grid有不同数目的grid cell。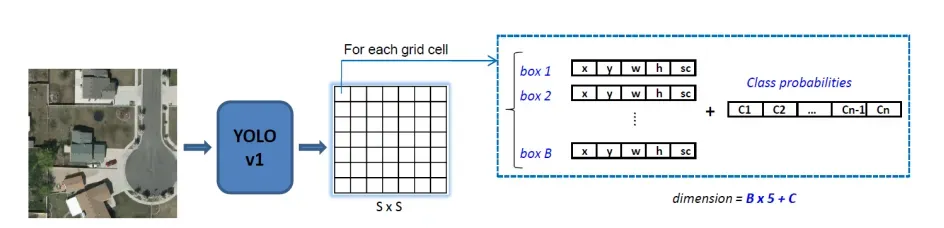
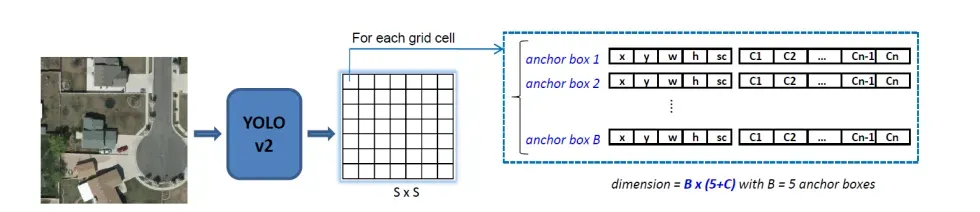
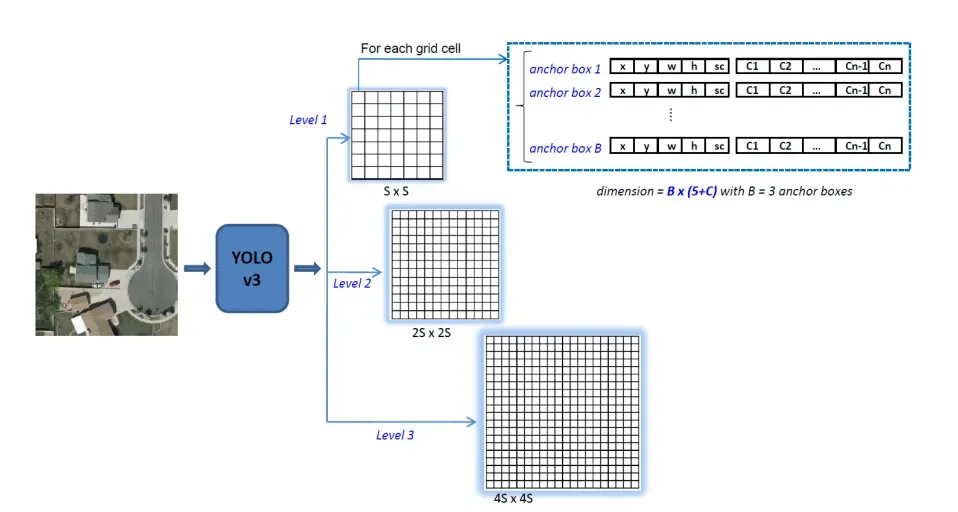
YOLOv5的grid有三层 ,如果按照640 * 640大小的图片,按照strider来划分,那么grid cell的大小分别是80 * 80,40 * 40,20 * 20
YOLOv1的输出
YOLOv1输出tensor的维度是 (S, S, B × 5 + C)
(S,S)就是网格的大小
B是每个单元格的预测框的数量
C是类别的数量
这里通常是S = 7,B = 2,C = 20(PASCAL VOC dataset)
输出图像通常是448 × 448像素
输出tensor的大小是 7 × 7 × 30
30 = 2 × 5 + 20
YOLOv2的输出
YOLOv2输出tensor的维度已经发生了变化是(S, S, B × (5 + C))
B是每个单元格的预测框的数量
C是类别的数量
原来是B × 5 + C 变成了B × (5 + C)
这里通常是S = 13,B = 5,C = 20(PASCAL VOC dataset)
输出图像通常是416 × 416像素
输出tensor的大小是
13 × 13 × 125
125 = 5 × (5 + 20)
YOLOv3的输出
YOLOv3的输出已经发生了大的变化,YOLOv5的思路与YOLOv3是相同的
一个检测层的输出变成三个检测层的输出
(S, S, B × (5 + C))
(2S, 2S, B × (5 + C))
(4S, 4S, B × (5 + C))
S,S是网格的大小
B是每个单元格的预测框的数量
C是类别的数量
这里通常是S=13,B=3,C=80(COCO dataset)
输出图像通常是416×416像素
输出是三个张量,其大小为
13 × 13 × 255
26 × 26 × 255
52 × 52 × 255
255 = 3 × (5 + 80)
YOLOv5的输出
YOLOv5的输出,与YOLOv3一样,是三个检测层的输出
按照stride来划分,以640 × 640像素图像为例
stride分别是8,16,32
640 / 8 = 80,这层网格大小是80 × 80
640 / 16 = 40,这层网格大小是40 × 40
640 / 32 = 20,这层网格大小是20 × 20
最终输出是
(80, 80, B × (5 + C))
(40, 40, B × (5 + C))
(20, 20, B × (5 + C))
B是每个单元格的预测框的数量
C是类别的数量
这里通常是B=3,C=80(COCO dataset)
输出是三个张量,其大小为
80 × 80 × 255
40 × 40 × 255
20 × 20 × 255
255 = 3 × (5 + 80)
也就是程序的输出
torch.Size([16, 3, 80, 80, 85])
torch.Size([16, 3, 40, 40, 85])
torch.Size([16, 3, 20, 20, 85])
这里的16是batch-size的大小,输出数据batch-size张图像。
每个grid cell预测框的数量是3个,这里用字母B表示
例如 P3层预测框的配置是
[ 10., 13.]
[ 16., 30.]
[ 33., 23.]
其中[10., 13]就表示一个预测框的scale,每一个grid cell有3个不同的预测框,通过scale就知道预测框的样子。
也就是上表
scale:3
num anchors per scale:3
不同层的grid cell对应的预测框大小是不同的,详细表示如下
tensor([[[[[[ 10., 13.]]], #P3层
[[[ 16., 30.]]],
[[[ 33., 23.]]]]],
[[[[[ 30., 61.]]],#P4层
[[[ 62., 45.]]],
[[[ 59., 119.]]]]],
[[[[[116., 90.]]],#P5层
[[[156., 198.]]],
[[[373., 326.]]]]]])
网格大小与anchor scale的关系
版权声明:本文为博主TheOldManAndTheSea原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/flyfish1986/article/details/119332396