


作者:大松鼠
注:本文相关练习用jupyter notebook完成,源文件可到公众号”大拨鼠Code”回复“机器学习”领取,题目及数据、文章的pdf版本都已打包在一起,如果对您有帮助,希望点个关注哦,万分感谢!
专栏不断更新,欢迎订阅~
Linux
数据结构和算法
机器学习
Logistic回归
逻辑函数
我们将逻辑函数(sigmoid函数)定义为:

因为


逻辑函数的图像如下:
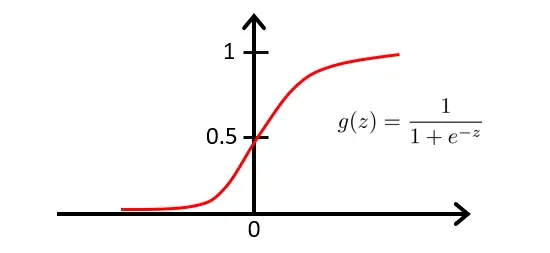

当我们有了函数
由于逻辑函数处于




决策边界
我们现在来看看,逻辑函数什么时候会将
这时我们可以设定一个界限,例如我们设为0.5,则

同时,逻辑函数的图像显示:

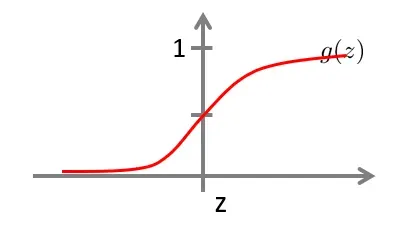

现在假设我们有如下所示的训练集和假设函数
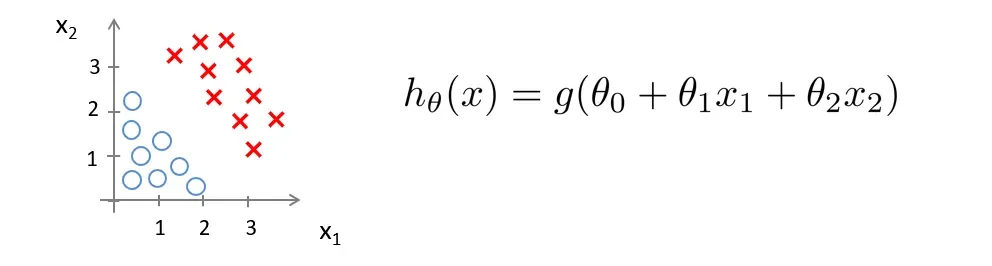

现在让

如果是

我们知道,图上
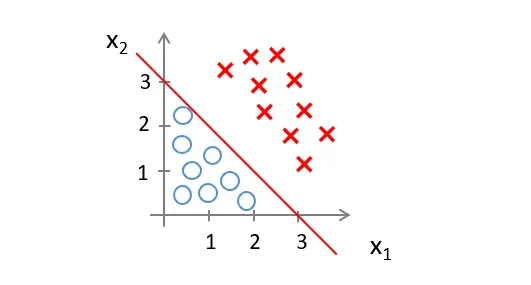

然后当数据落在直线的右边时,预测
我们称这条线为决策边界,当
让我们看另一个例子
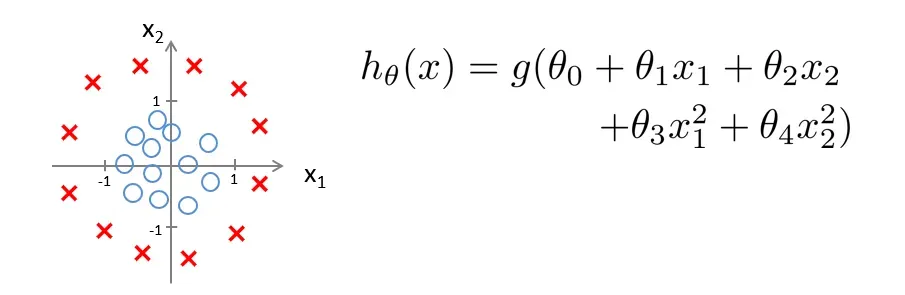

现在让

如果是

此时的决策边界就是一个以0为原点,以1为半径的圆,但数据落在圆外,则预测
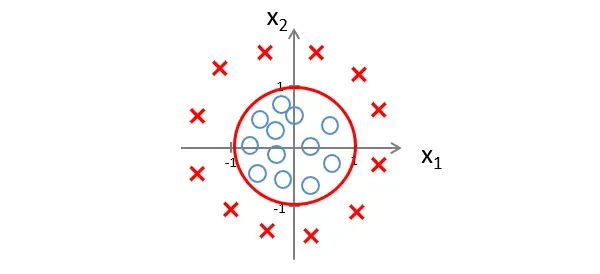

这里需要强调的是,我们不是使用训练集来定义决策边界,而是拟合参数
成本函数
假设我们现在有n个特征值和m个训练样本的训练集
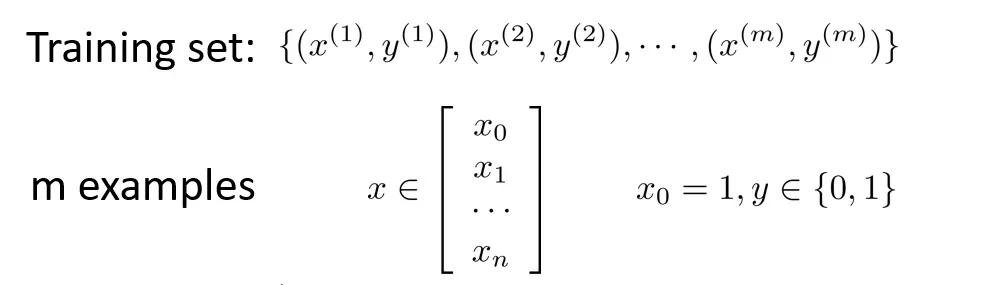

和之前的线性回归一样,我们让
我们假设函数:
现在我们要讨论的是在给定训练集时如何拟合函数
在线性回归中,我们使用成本函数

订单

原来的公式变成

因为逻辑函数
那么它的代价函数就是一个非凸函数。左图如下。有许多局部最优解。那么我们不能保证通过梯度下降法可以找到全局最优解,所以我们更喜欢右图的代价函数。
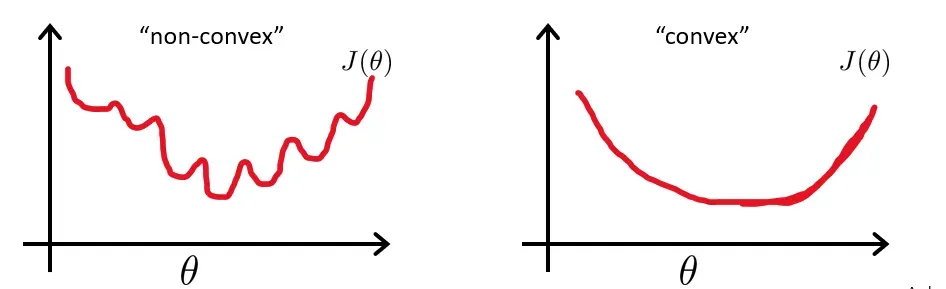

为了解决上述问题,我们定义

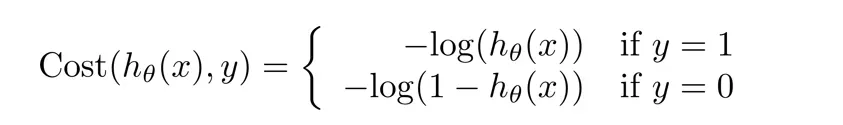

我们先讨论
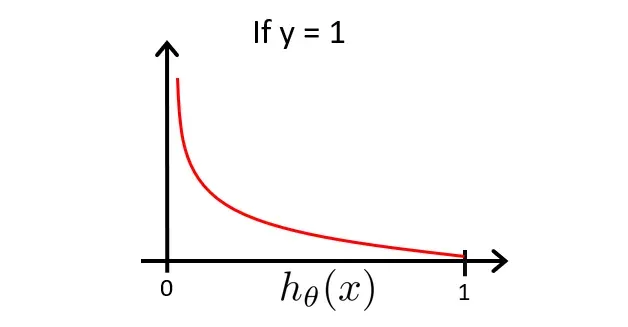

由于该图像是在
由此我们知道,若


现在讨论
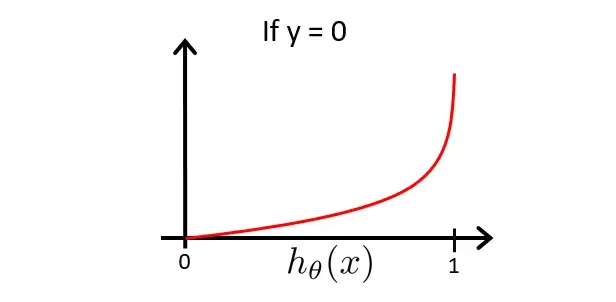

由于该图像是在

由此我们知道,若

梯度下降求解器
如下是我们的逻辑函数,在分类问题中,
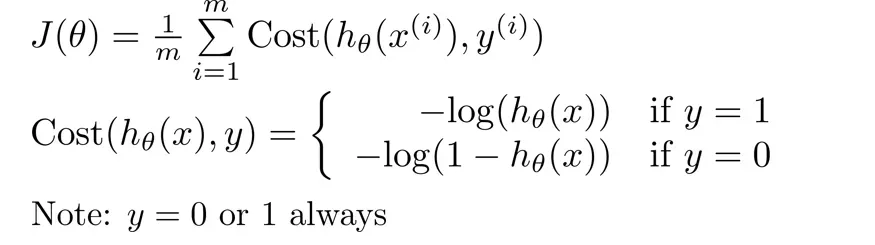

既然
因为当

因为当

所以我们可以结合

这样我们就得到了Logistic 回归的代价函数如下
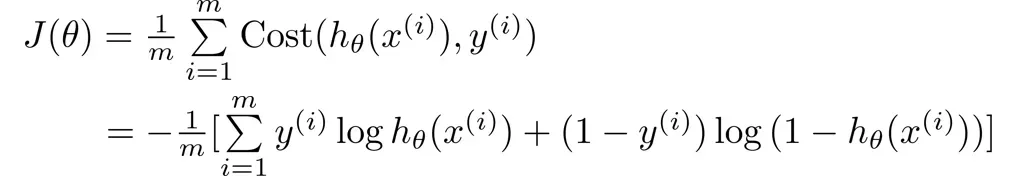

现在我们要做的就是找到最小化成本函数的参数
与线性回归类似,我们使用梯度下降,直到找到最小值
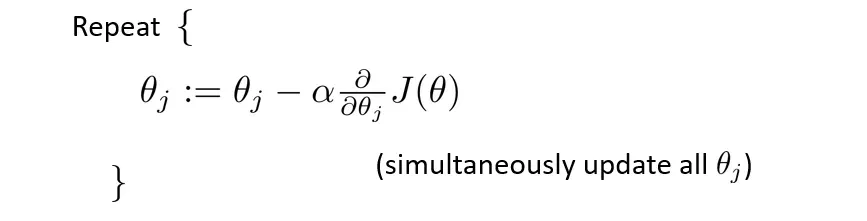

计算导数项


多变量分类(一对多)
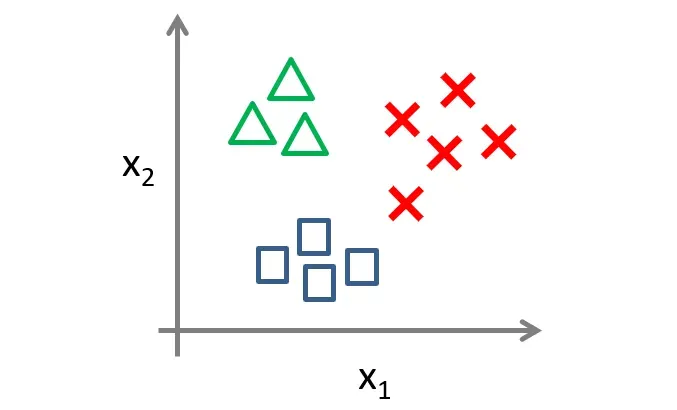

对于上图中的三个类别的样本,我们应该如何分类呢?
我们可以将这种多元分类问题转化为三个独立的二元分类问题。
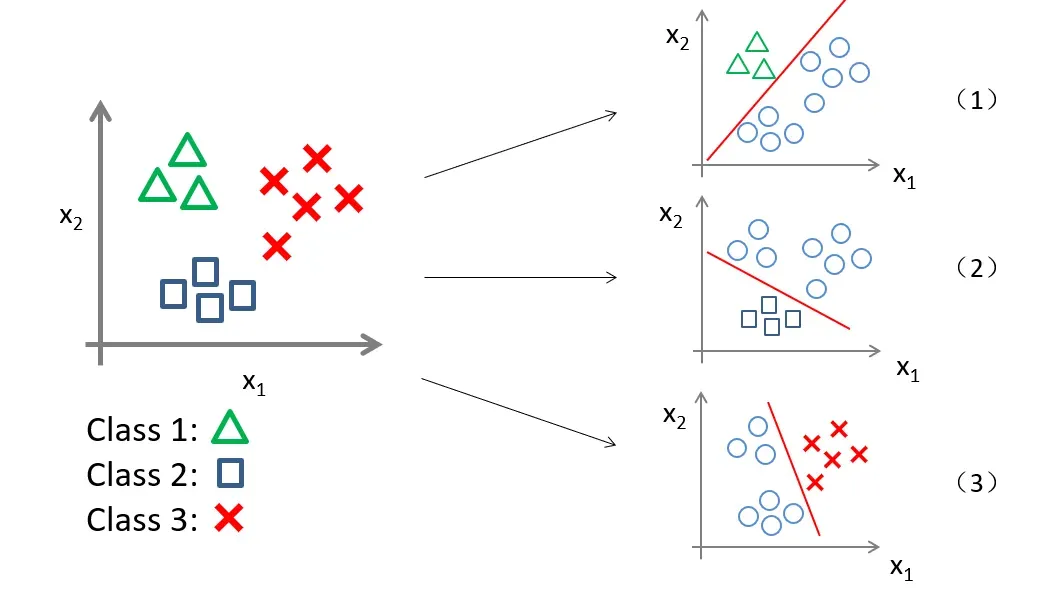

首先,假设三个类别为

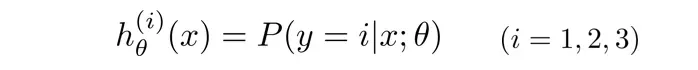

如图(1)我们先把正方形和红叉看成一类,从而转化为二元分类,那么第一个分类器就可以预测出

也就是说,在分析三元问题时,我们转换为三个二元分类器,每个分类器都针对其中一种情况进行训练。
过拟合和求解
一个假设可以在训练数据上获得比其他假设更好的拟合,但不能很好地将数据拟合到训练数据以外的数据集上。此时,该假设被认为是过拟合的。造成这种现象的主要原因是训练数据中存在噪声或训练数据太少。
在单变量线性回归问题中,我们可以选择观察数据在图上的分布特征来选择合适的拟合函数,但在多元回归分析中,很难画图并观察数据分布特征。
解决方案:
- 部分特征向量被手动或通过选择算法模型丢弃。
- 正则化:保留所有特征,但减少拟合参数
现在让我们修改成本函数以减少参数
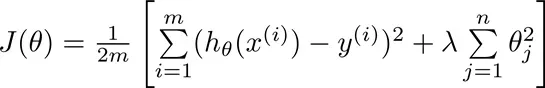

第一个目标是使拟合参数更好地拟合我们的数据
第二个目标是保持拟合参数尽可能小
线性回归的正则化
一般来说,我们只需要对参数

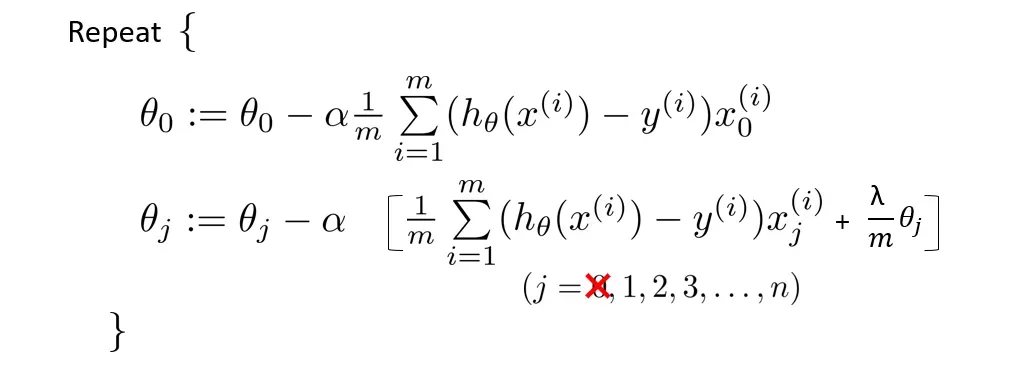

将更新
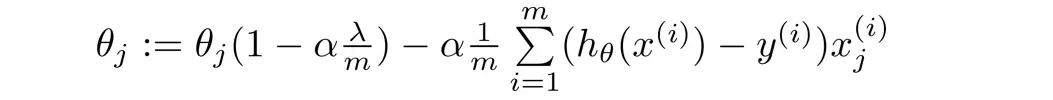

如果使用正规方程,则变为
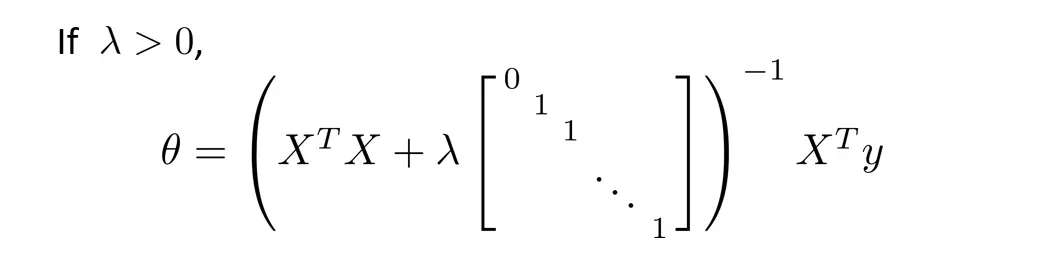

Logistic回归的正规化
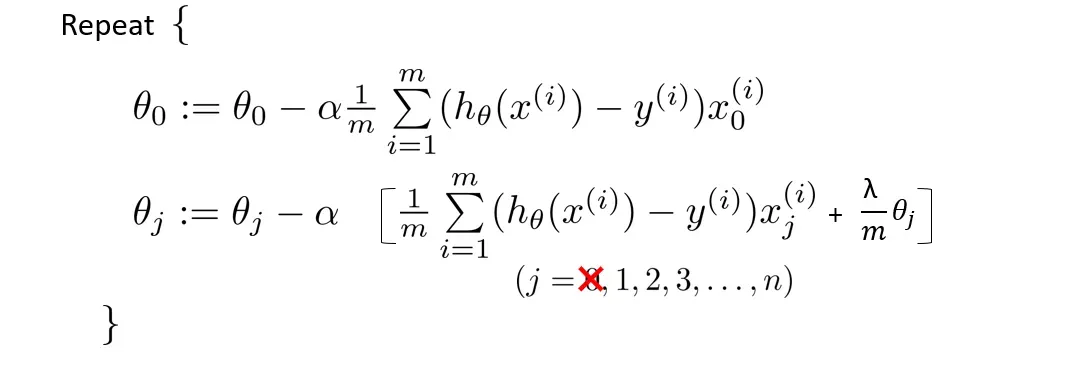

示例源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report #生成报告
线性分类问题
#数据处理
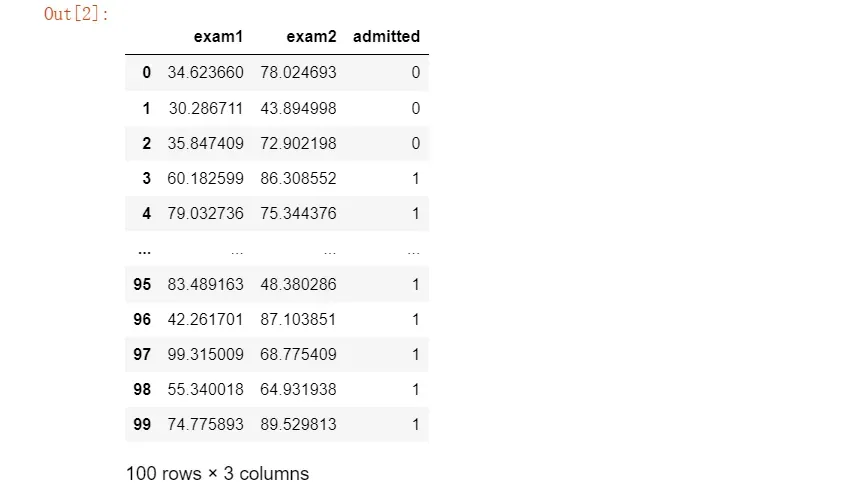
data=pd.read_csv('E:\\happy\\data\\Logistic_data\\ex2data1.txt',names=['exam1','exam2','admitted'])
data

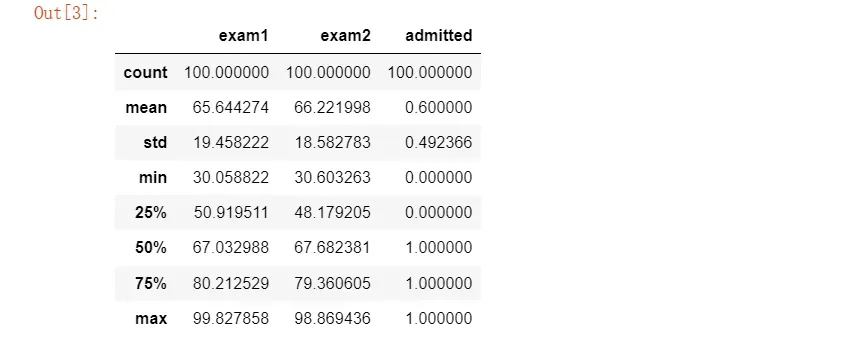
#先看看数据各个统计值
data.describe()

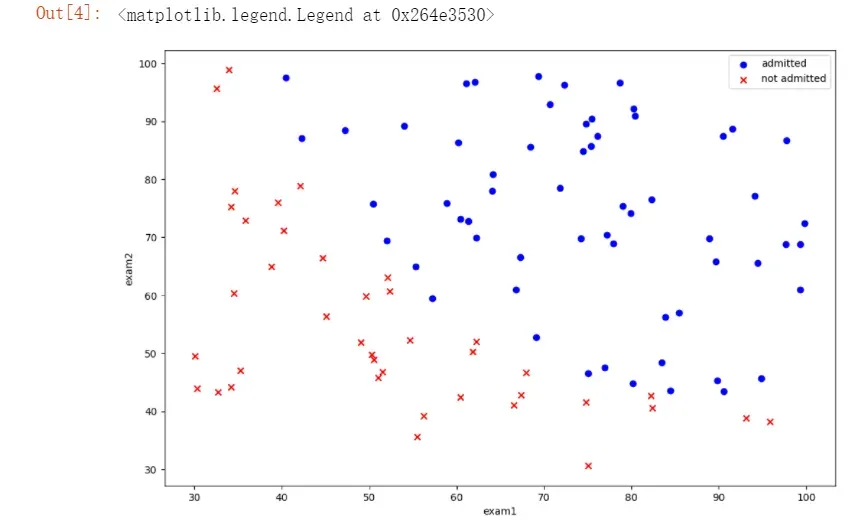
#绘制散点
positive = data[data['admitted'].isin([1])]
negative = data[data['admitted'].isin([0])]
fig = plt.figure(figsize=(12,8), dpi=100)
plt.scatter(positive.exam1,positive.exam2,c='b',marker='o',label='admitted')
plt.scatter(negative.exam1,negative.exam2,c='r',marker='x',label='not admitted')
plt.xlabel("exam1")
plt.ylabel("exam2")
plt.legend()

#sigmoid函数
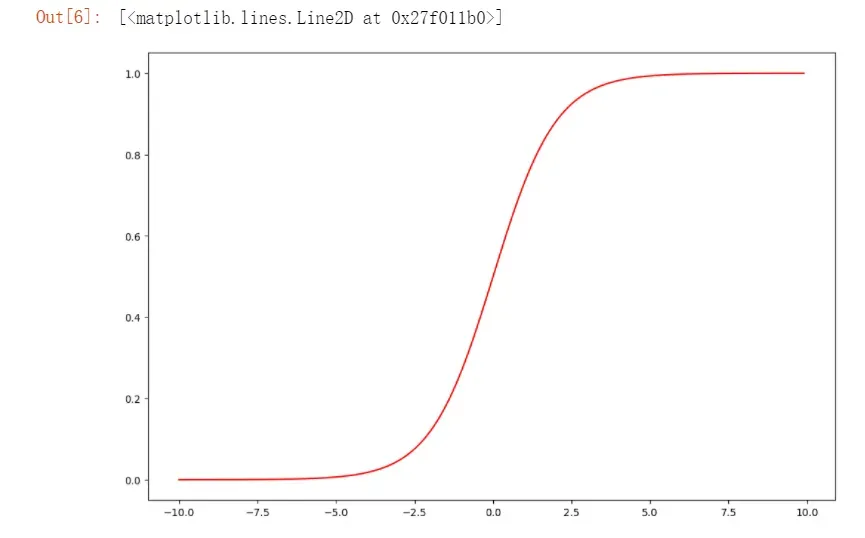
def sigmoid(z):
return 1/(1 + np.exp(-z))
#绘图检查一下sigmoid函数定义是否正确
nums = np.arange(-10,10,step=0.1)
fig = plt.figure(figsize=(12,8), dpi=100)
plt.plot(nums, sigmoid(nums),'r')


#添加一列1
data.insert(0,'Ones',1)
#读取特征值和目标函数
cols = data.shape[1] #得到矩阵列数
x_data = np.array(data.iloc[:, 0:cols-1]) #取不包含最后一列的所有数据,并转化为数组,不然不能进行下面的运算
y_data = np.array(data.iloc[:,cols-1:cols]) #取最后一列数据
theta = np.zeros(3)
def cost(theta,X,y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
return np.mean(np.multiply(-y, np.log(sigmoid(X * theta.T))) - np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T))))
偏导数
转换为矢量


#求代价函数偏导
def gradient(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
return X.T * (sigmoid(X * theta.T) - y) / len(X)
#看看能否运行
gradient(theta ,x_data ,y_data)


现在用SciPy’s truncated newton(TNC)实现寻找最优参数。
import scipy.optimize as opt
res = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(x_data, y_data))
res
![]()

cost(res[0], x_data, y_data)
![]()

构建分类器
当

def predict(theta , X):
theta = np.matrix(theta)
X = np.matrix(X)
prob = sigmoid(X * theta.T)
return (prob >= 0.5).astype(int)
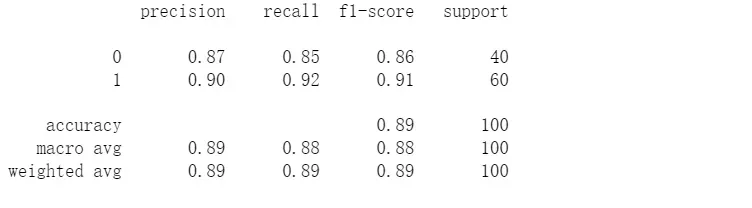
#预测一下,看看精确率
final_theta = res[0];
y_pred = predict(final_theta , x_data)
#生成报告
print(classification_report(y_data,y_pred))

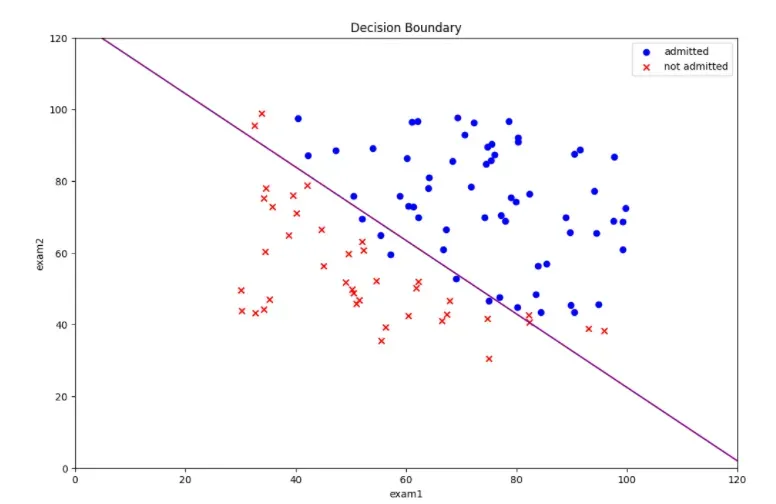
决策边界
coef = -(res[0] / res[0][2]) #决策边界方程系数
x = np.arange(130 ,step=0.1)
y = coef[1] * x + coef[0]
#画出决策边界
fig = plt.figure(figsize=(12,8), dpi=100)
plt.plot(x, y,'purple')
plt.scatter(positive.exam1,positive.exam2,c='b',marker='o',label='admitted')
plt.scatter(negative.exam1,negative.exam2,c='r',marker='x',label='not admitted')
plt.xlim(0,120)
plt.ylim(0,120)
plt.xlabel("exam1")
plt.ylabel("exam2")
plt.legend()
plt.title('Decision Boundary')

非线性分类问题
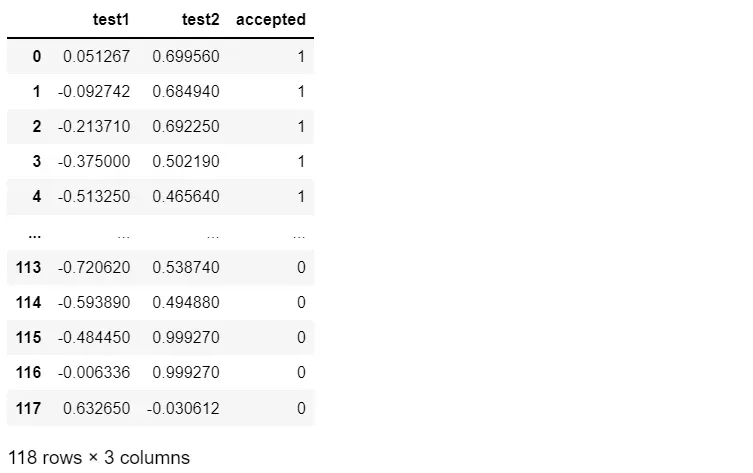
data2 = pd.read_csv('E:\\happy\\data\\Logistic_data\\ex2data2.txt',names=['test1', 'test2','accepted'])
data2

#绘制散点图
positive2 = data2[data2['accepted'].isin([1])]
negative2 = data2[data2['accepted'].isin([0])]
fig = plt.figure(figsize=(12,8), dpi=100)
plt.scatter(positive2['test1'], positive2['test2'], c='b',marker='o',label='accepted')
plt.scatter(negative2['test1'], negative2['test2'], c='r',marker='x',label='rejected')
plt.legend()
plt.xlabel('test1')
plt.ylabel('test2')
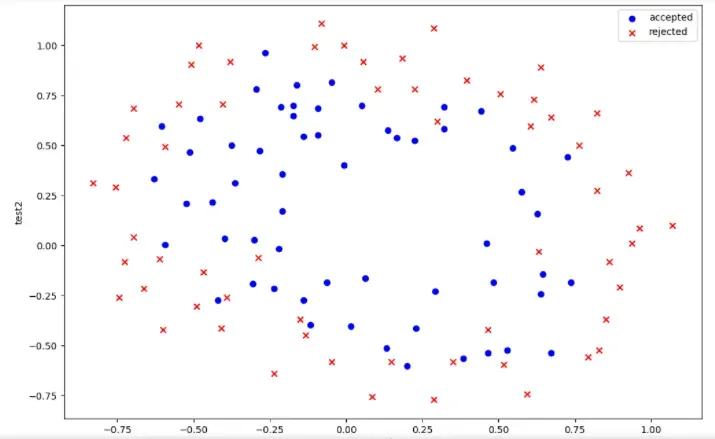

这些数据散点看起来是非线性的,不能简单的区分正负类,所以我们需要创建更多的项来让决策边界更好的对数据进行分类,这就需要使用特征图,但是这样容易出现过拟合的问题,所以我们还需要正则化成本函数。
特征图
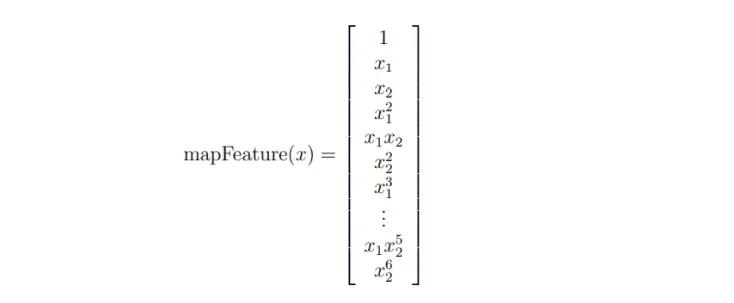

def feature_mapping(x, y, power, as_ndarray=False):
data = {"f{}{}".format(i - p, p): np.power(x, i - p) * np.power(y, p)
for i in np.arange(power + 1)
for p in np.arange(i + 1)
}
if as_ndarray:
return pd.DataFrame(data).values
else:
return pd.DataFrame(data)
x1 = np.array(data2.test1)
x2 = np.array(data2.test2)
归一化成本函数

X = feature_mapping(x1, x2, power=6, as_ndarray=True)
cols = data2.shape[1]
y = np.array(data2.iloc[:,cols-1:cols])
theta = np.zeros(28)
def regularized_cost(theta, X, y, lamb = 1):
'''正规项不包含theta_0'''
theta_except_0 = theta[1:]
reg = (lamb / (2 * len(X))) * np.sum(np.power(theta_except_0, 2))
return cost(theta,X,y) + reg
正则化梯度


def regularized_gradient(theta, X, y, lam=1):
theta_except_0 = theta[1:]
reg_theta = (lam / len(X)) * theta_except_0
#将theta_0和theta_j(j≠0)两种情况拼接到一个数组中
reg_term = np.concatenate([np.array([0]), reg_theta])
reg_term = np.matrix(reg_term)
return gradient(theta, X, y) + reg_term.T
regularized_gradient(theta, X, y, lam=1)
现在用SciPy’s truncated newton(TNC)实现寻找最优参数。
res2 = opt.fmin_tnc(func=regularized_cost, x0=theta, fprime=regularized_gradient, args=(X, y))
res2


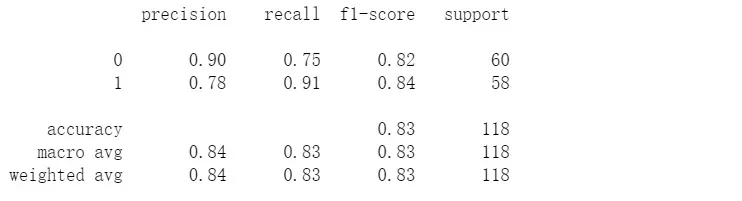
#看看精确度
final_theta = res2[0]
y_pred = predict(final_theta, X)
print(classification_report(y, y_pred))

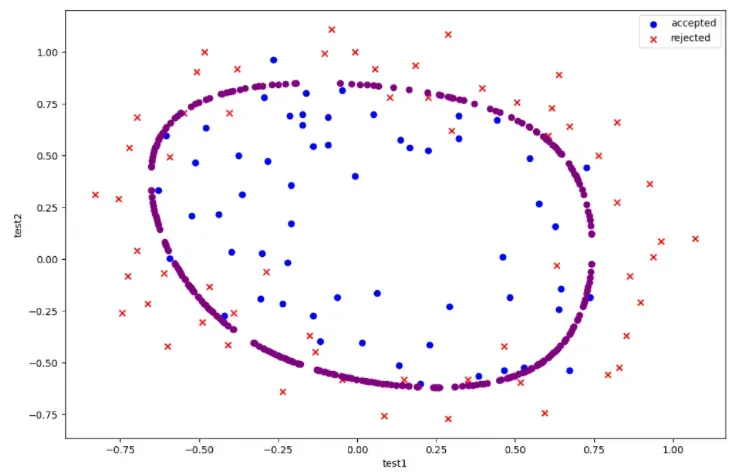
决策边界
#寻找决策边界
def find_decision_boundary(power, theta):
t1 = np.linspace(-1, 1.5, 1000)
t2 = np.linspace(-1, 1.5, 1000)
cordinates = [(x, y) for x in t1 for y in t2]
x_cord, y_cord = zip(*cordinates)
mapped_cord = feature_mapping(x_cord, y_cord, power)
inner_product = mapped_cord @ theta
decision = mapped_cord[np.abs(inner_product) < 0.001] #保留接近0的数据用于绘图
return decision.f10, decision.f01
#画出据决策边界
power = 6
x, y = find_decision_boundary(power,final_theta)
fig = plt.figure(figsize=(12,8), dpi=100)
plt.scatter(positive2['test1'], positive2['test2'], c='b',marker='o',label='accepted')
plt.scatter(negative2['test1'], negative2['test2'], c='r',marker='x',label='rejected')
plt.scatter(x, y, c = 'purple')
plt.legend()
plt.xlabel('test1')
plt.ylabel('test2')

参考:
吴恩达机器学习系列课程
机器学习笔记
版权声明:本文为博主大拨鼠原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/watermelon_c/article/details/122785071