



内容
走进LightGBM
什么是LightGBM?
XGBoost的缺点
LightGBM的优化
LightGBM的基本原理
Histogram 算法
直方图加速
LightGBM并行优化
代码实践
详细参数说明
代码实践
最优模型及参数(数据集1000)
模型调整
每个文本一个字
👇👇🧐🧐✨✨🎉🎉
欢迎点击专栏其他文章(欢迎订阅,持续更新~)
机器学习之Python开源教程——专栏介绍及理论知识概述
机器学习框架和评估指标详解
Python监督学习之分类算法的概述
数据清洗、数据集成、数据归约、数据转换和数据预处理的离散化
特征工程之One-Hot编码、label-encoding、自定义编码
卡方分箱、KS分箱、最优IV分箱、树结构分箱、自定义分箱
用于特征选择、基于模型的选择、迭代选择的单变量统计
朴素贝叶斯机器学习分类算法
【万字详解·附代码】机器学习分类算法之K近邻(KNN)
《全网最强》详解机器学习分类算法决策树(附可视化和代码)
机器学习分类算法的支持向量机
机器学习分类算法之Logistic 回归(逻辑回归)
机器学习分类算法的随机森林(综合学习算法)
机器学习分类算法之XGBoost(集成学习算法)
继续更新~
关于作者
👦博客名:王小王-123
👀简介:CSDN博客专家、CSDN签约作者、华为云享专家,腾讯云、阿里云、简书、InfoQ创作者。公众号:书剧可诗画,2020年度CSDN优秀创作者。左手诗情画意,右手代码人生,欢迎一起探讨技术
走进LightGBM
什么是LightGBM?
在上一篇的文章里,我介绍了XGBoost算法,它是是很多的比赛的大杀器,但是在使用过程中,其训练耗时很长,内存占用比较大。
在2017年年1月微软在GitHub的上开源了LightGBM。该算法在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升算法。可用于排序,分类,回归以及很多其他的机器学习任务中。
GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT不仅在工业界应用广泛,通常被用于多分类、点击率预测、搜索排序等任务;在各种数据挖掘竞赛中也是致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。
而LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。
LightGBM是一个梯度提升框架,使用基于树的学习算法。
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。而GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好更快地用于工业实践。
XGBoost的缺点
在LightGBM提出之前,最有名的GBDT工具就是XGBoost了,它是基于预排序方法的决策树算法。这种构建决策树的算法基本思想是:首先,对所有特征都按照特征的数值进行预排序。其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。最后,在找到一个特征的最好分割点后,将数据分裂成左右子节点。
这样的预排序算法的优点是能精确地找到分割点。但是缺点也很明显:首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
LightGBM的优化
为了避免XGBoost的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,lightGBM在传统的GBDT算法上进行了如下优化:
- 基于Histogram的决策树算法。
- 单边梯度采样 Gradient-based One-Side Sampling(GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征值节省了不少时间和空间上的开销。
- 互斥特征捆绑 Exclusive Feature Bundling(EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
- 带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长 (level-wise) 的决策树生长策略,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销。实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM使用了带有深度限制的按叶子生长 (leaf-wise) 算法。
- 直接支持类别特征(Categorical Feature)
- 支持高效并行
- Cache命中率优化
LightGBM的基本原理
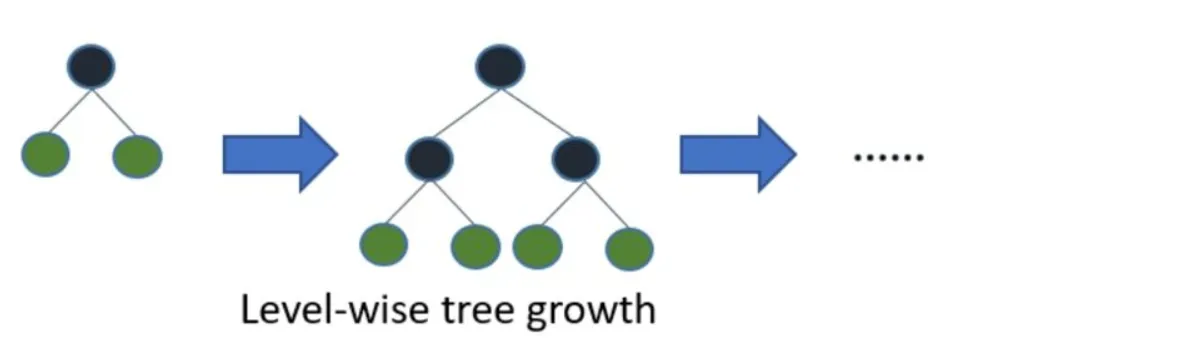
LightGBM树的生长方式是垂直方向的,其他的算法都是水平方向的,也就是说Light GBM生长的是树的叶子,其他的算法生长的是树的层次。
LightGBM选择具有最大误差的树叶进行生长,当生长同样的树叶,生长叶子的算法可以比基于层的算法减少更多的loss。
下面的图解释了LightGBM和其他的提升算法的实现
在 Histogram 算法之上,LightGBM 进行进一步的优化。首先它抛弃了大多数 GBDT 工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。Level-wise 过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上 Level-wise 是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
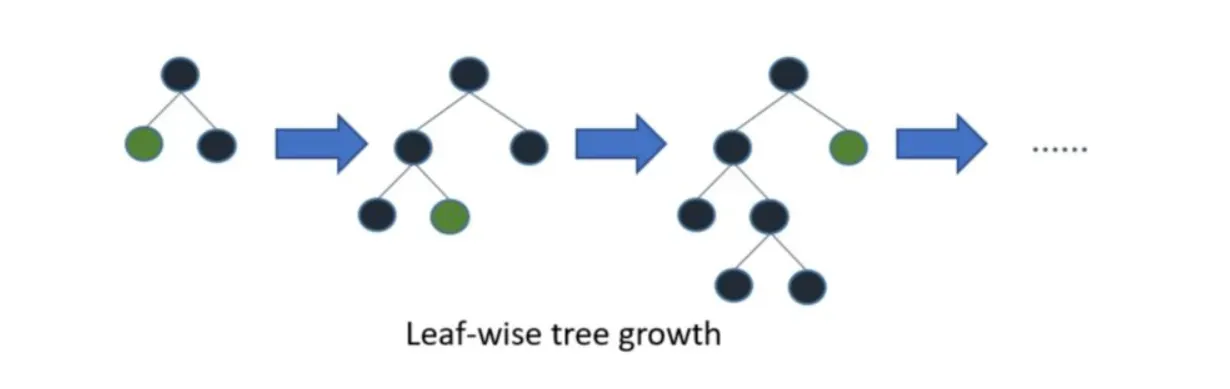
Leaf-wise 则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同 Level-wise 相比,在分裂次数相同的情况下,Leaf-wise 可以降低更多的误差,得到更好的精度。Leaf-wise 的缺点是可能会长出比较深的决策树,产生过拟合。因此 LightGBM 在 Leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。

既然能提高速度,那能不能用在小数据集上呢?
不可以!不建议在小数据集上使用LightGBM。LightGBM对过拟合很敏感,对于小数据集非常容易过拟合。对于多小属于小数据集,并没有什么阈值,但是从我的经验,我建议对于10000+以上的数据的时候,再使用LightGBM。这也很明显,因为小的数据集使用XGBoost就可以了呀。
实现LightGBM非常简单,复杂的是参数的调试。LightGBM有超过100个参数,但是不用担心,你不需要所有的都学。
Histogram 算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
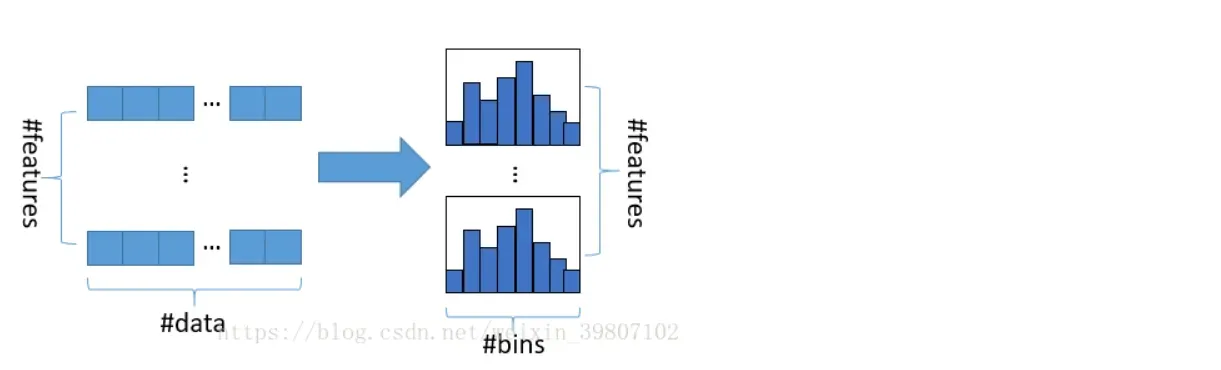

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用 8 位整型存储就足够了,内存消耗可以降低为原来的1/8。 (内存消耗低)


然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data*#feature)优化到O(k*#features)。
当然,Histogram 算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。
直方图加速
LightGBM 另一个优化是 Histogram(直方图)做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM 可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。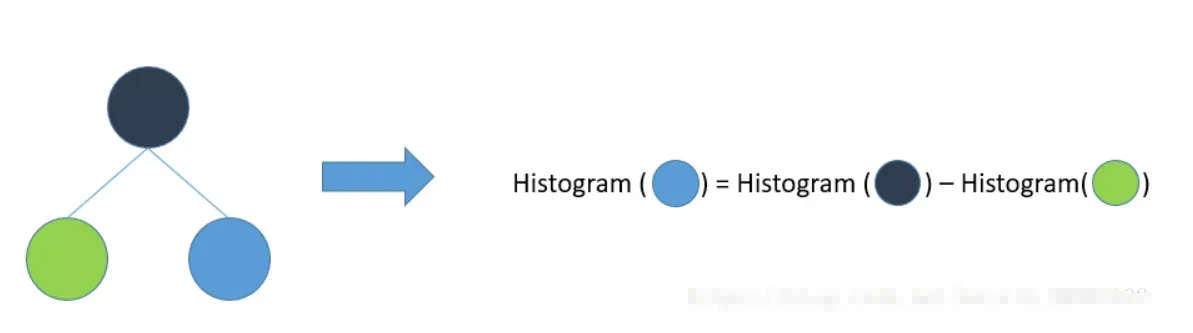

实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1 特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM 优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1 展开。并在决策树算法上增加了类别特征的决策规则。在 Expo 数据集上的实验,相比0/1 展开的方法,训练速度可以加速 8 倍,并且精度一致。据我们所知,LightGBM 是第一个直接支持类别特征的 GBDT 工具。
LightGBM 的单机版本还有很多其他细节上的优化,比如 cache 访问优化,多线程优化,稀疏特征优化等等。优化汇总如下:
LightGBM并行优化
LightGBM 还具有支持高效并行的优点。LightGBM 原生支持并行学习,目前支持特征并行和数据并行的两种。
特征并行的主要思想是在不同机器上的不同特征集上找到最优分割点,然后在机器之间同步最优分割点。
数据并行就是让不同的机器在本地构建直方图,然后全局合并,最后在合并后的直方图上找到最优分割点。
LightGBM 针对这两种并行方法都做了优化:
在特征并行算法中,通过将所有数据保存在本地来避免数据分割结果的通信;
在数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。基于投票的数据并行则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。
注意:
- 当生长相同的叶子时,Leaf-wise 比 level-wise 减少更多的损失。
- 高速,高效处理大数据,运行时需要更低的内存,支持 GPU
- 不要在少量数据上使用,会过拟合,建议 10,000+ 行记录时使用。
代码实践
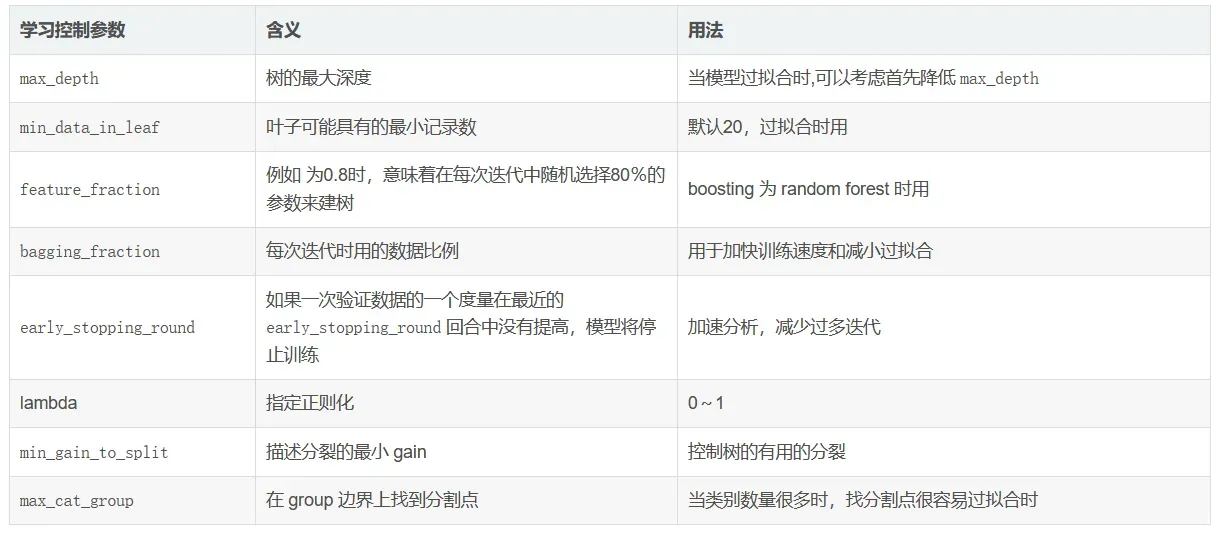
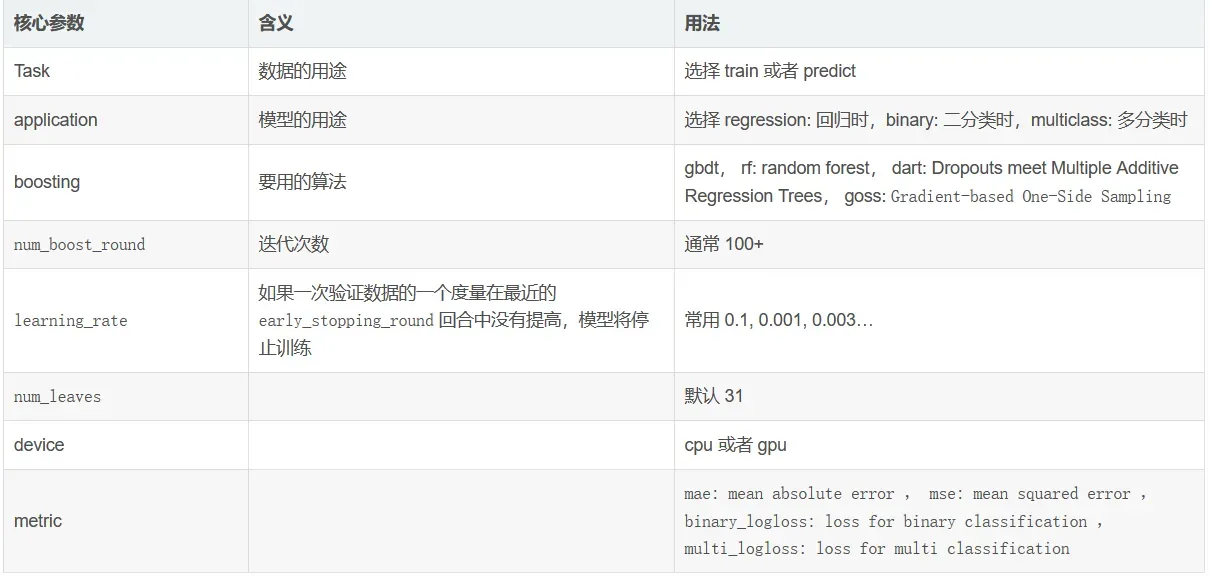
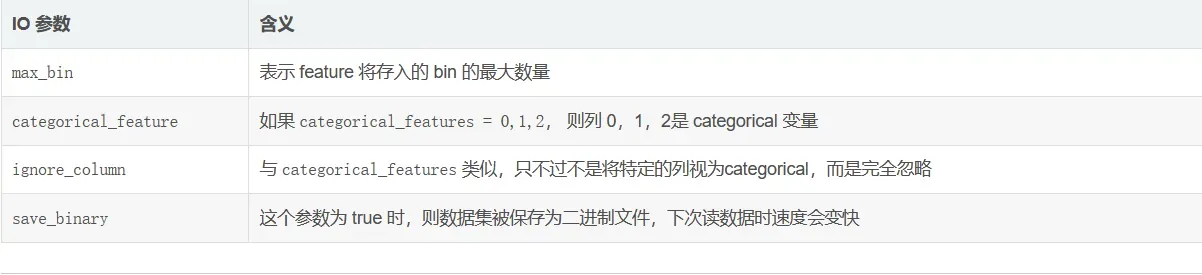
详细参数说明
以下参数可以提高准确率
learning_rate:学习率.
默认值:0.1
调参策略:最开始可以设置得大一些,如0.1。调整完其他参数之后最后再将此参数调小。
取值范围:0.01~0.3.
max_depth:树模型深度
默认值:-1
调整策略:无
取值范围:3-8(不超过10)
num_leaves:叶子节点数,数模型复杂度


减少过拟合
max_bin:工具箱数(叶子结点数+非叶子节点数?)
bin的最大数 决定 特征的最大组数(类似特征会被组合)
小的bin数量会降低训练精度(accuracy),但是可能可以提高泛化性能(genreal power)
LightGBM 将根据 max_bin 自动压缩内存。 例如, 如果 maxbin=255, 那么 LightGBM 将使用 uint8t 的特性值
min_data_in_leaf:一个叶子上数据的最小数量. 可以用来处理过拟合
默认值:20
参数调优策略:搜索,尽量不要太大。
feature_fraction:每次迭代中随机选择特征的比例。
默认值:1.0
调参策略:0.5-0.9之间调节。
可用于加速训练
可用于处理过拟合
bagging_fraction:不进行重采样的情况下随机选择部分数据
默认值:1.0
调参策略:0.5-0.9之间调节。
可用于加速训练
可用于处理过拟合
bagging_freq:bagging的次数。0表示禁用bagging,非零值表示执行k次bagging
默认值:0
调参策略:3-5
其他
lambda_l1:L1正则
lambda_l2:L2正则min_split_gain:执行切分的最小增益
默认值:0.1





#导入所需要的包
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report#评估报告
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.model_selection import GridSearchCV #网格搜索
import matplotlib.pyplot as plt#可视化
import seaborn as sns#绘图包
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler#归一化,标准化
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import precision_score
import lightgbm as lgb 最优模型及参数(数据集1000)
有的小伙伴会有疑问,咋我们的lightGBM效果没有XGBoost好呀,原因出在我们的数据上,因为这个是一个小的数据集,效果可以达到这个,完全是不断迭代优化参数的效果。
df=pd.read_csv(r"数据.csv")
X=df.iloc[:,:-1]
y=df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
model=lgb.LGBMClassifier(n_estimators=39,max_depth=8,num_leaves=12,max_bin=7,min_data_in_leaf=10,bagging_fraction=0.5,
feature_fraction=0.59,boosting_type="gbdt",application="binary",min_split_gain=0.15,
n_jobs=-1,bagging_freq=30,lambda_l1=1e-05,lambda_l2=1e-05,learning_rate=0.1,
random_state=90)
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
'''
评估指标
'''
# # 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\n',
classification_report(y_test,y_pred))
# ROC曲线、AUC
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 预测正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,返回两列,第一列代表类别0,第二列代表类别1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真阳性标签,就是说是分类里面的好的标签,这个要看你的特征目标标签是0,1,还是1,2
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()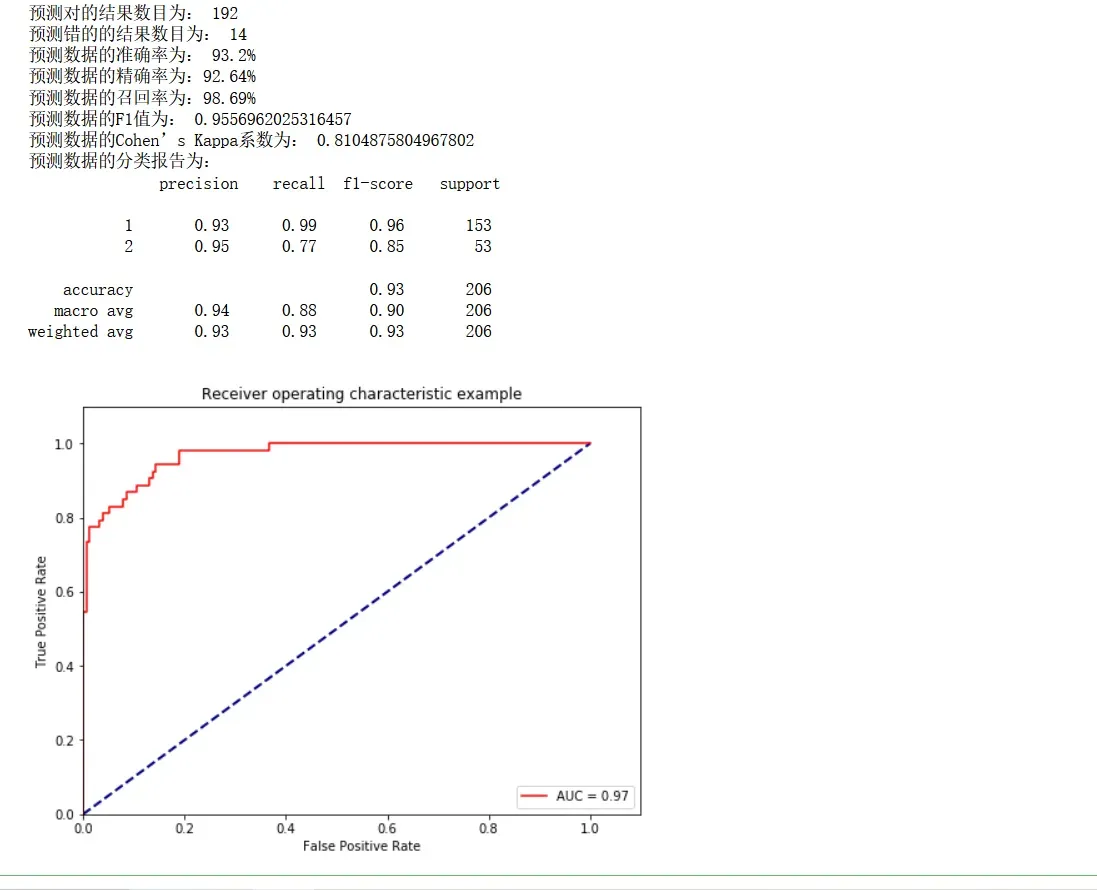

模型调整
尝试调整学习曲线
为了初始化我们的参数,我们也可以通过在训练集上进行网格搜索来确定参数的近似位置,然后使用学习曲线来迭代最佳参数
model=lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.01, n_estimators=39, max_depth=4,
num_leaves=12,max_bin=15,min_data_in_leaf=11,bagging_fraction=0.8,bagging_freq=20, feature_fraction= 0.7,
lambda_l1=1e-05,lambda_l2=1e-05,min_split_gain=0.5)例如:
params_test5={'min_split_gain':[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]}
gsearch5 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.01,
n_estimators=1000, max_depth=4, num_leaves=12,max_bin=15,min_data_in_leaf=11,
bagging_fraction=0.8,bagging_freq=20, feature_fraction= 0.7,
lambda_l1=1e-05,lambda_l2=1e-05,min_split_gain=0.5),
param_grid = params_test5, scoring='roc_auc',cv=5)
gsearch5.fit(X_train,y_train)
gsearch5.best_params_, gsearch5.best_score_学习曲线
scorel = []
for i in range(0,200,10):
model = lgb.LGBMClassifier(n_estimators=i+1,random_state=2022).fit(X_train,y_train)
score = model.score(X_test,y_test)
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1) #作图反映出准确度随着估计器数量的变化,110的附近最好
plt.figure(figsize=[20,5])
plt.plot(range(1,200,10),scorel)
plt.show()
## 根据上面的显示最优点在51附近,进一步细化学习曲线
scorel = []
for i in range(35,45):
RFC = lgb.LGBMClassifier(n_estimators=i,
n_jobs=-1,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*range(35,45)][scorel.index(max(scorel))])) #112是最优的估计器数量 #最优得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(range(35,45),scorel)
plt.show()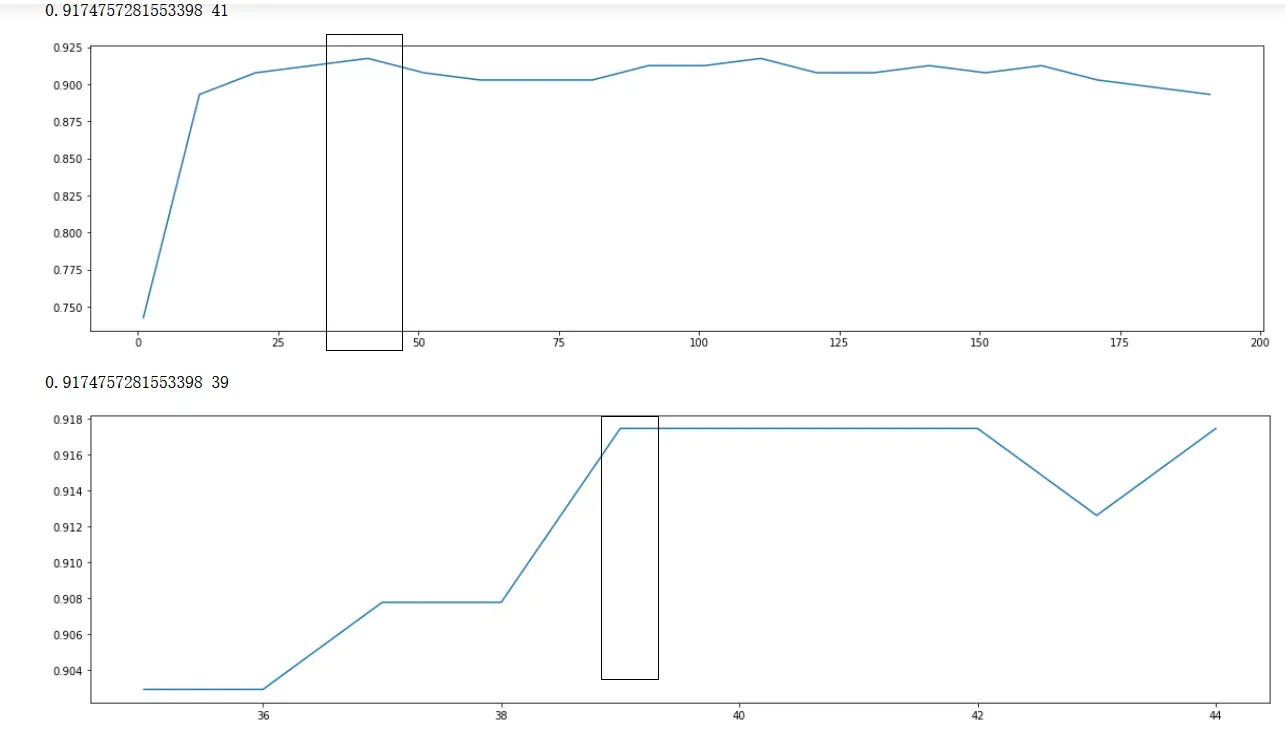

max_depth
scorel = []
for i in range(3,20):
RFC = lgb.LGBMClassifier(n_estimators=39,max_depth=i,
n_jobs=-1,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*range(3,20)][scorel.index(max(scorel))])) #112是最优的估计器数量 #最优得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(range(3,20),scorel)
plt.show()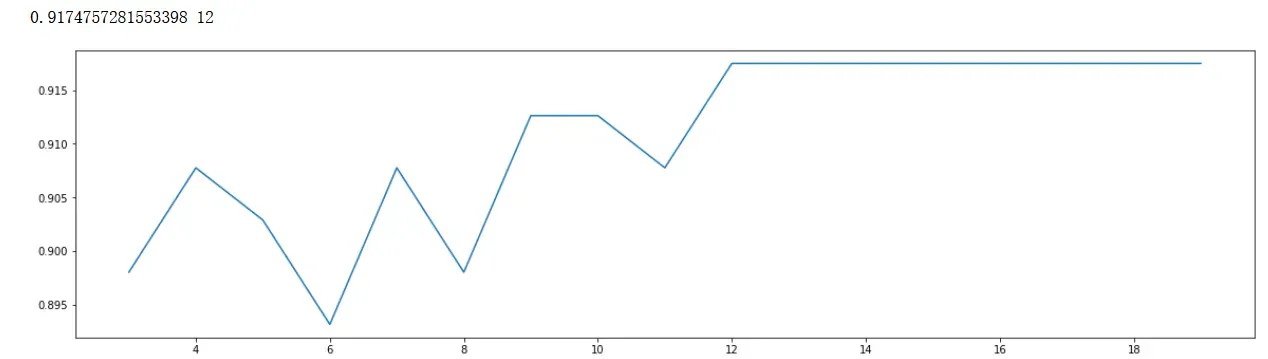

整数区间参数调优(手动修改)
scorel = []
for i in np.arange(7,45,1):
RFC = lgb.LGBMClassifier(n_estimators=39,max_depth=8,num_leaves=12,max_bin=7,min_data_in_leaf=10,bagging_fraction=0.5,feature_fraction=0.6,
n_jobs=-1,bagging_freq=30,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*np.arange(7,45,1)][scorel.index(max(scorel))])) #112是最优的估计器数量 #最优得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(np.arange(7,45,1),scorel)
plt.show()
# num_leaves=12,max_bin=15,min_data_in_leaf=11,bagging_fraction=0.8,bagging_freq=20, feature_fraction= 0.7,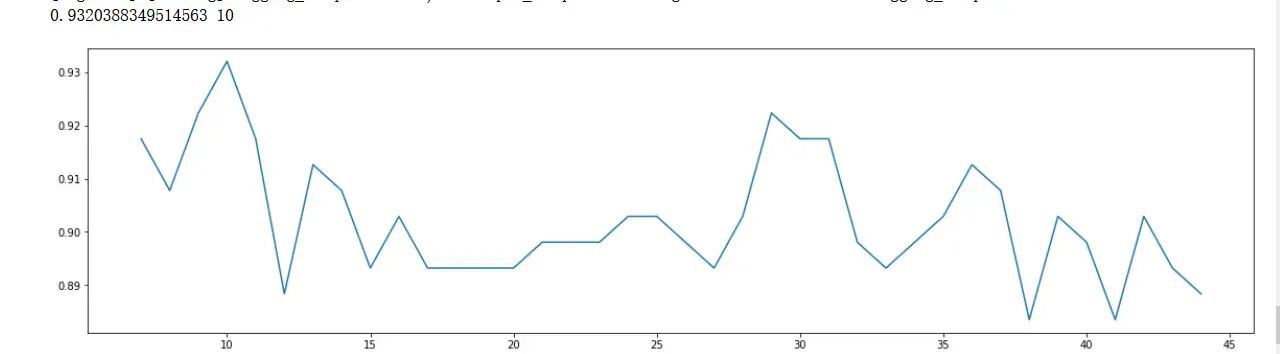

浮点参数(手动修改)
scorel = []
for i in np.arange(0.01,1,0.01):
RFC = lgb.LGBMClassifier(n_estimators=39,max_depth=8,num_leaves=12,max_bin=7,min_data_in_leaf=10,bagging_fraction=0.5,
feature_fraction=0.59,min_split_gain=i,
n_jobs=-1,bagging_freq=30,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*np.arange(0.01,1,0.01)][scorel.index(max(scorel))])) #112是最优的估计器数量 #最优得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(np.arange(0.01,1,0.01),scorel)
plt.show()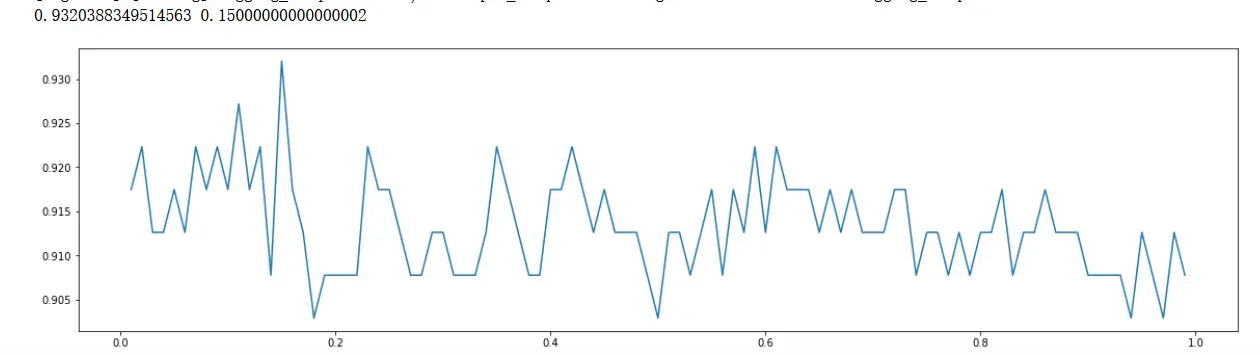

写到最后:
算法使用的场景一定要记住,在数据量很大的情况下
每个文本一个字
每天加油!
版权声明:本文为博主王小王-123原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_47723732/article/details/122933941