具体参考:
https://blog.csdn.net/qq_42363032/article/details/120070512
https://blog.csdn.net/qq_42363032/article/details/110449592
import numpy as np
from sklearn.metrics import f1_score, accuracy_score, roc_curve, precision_score, recall_score, roc_auc_score, log_loss
两大类指标汇总
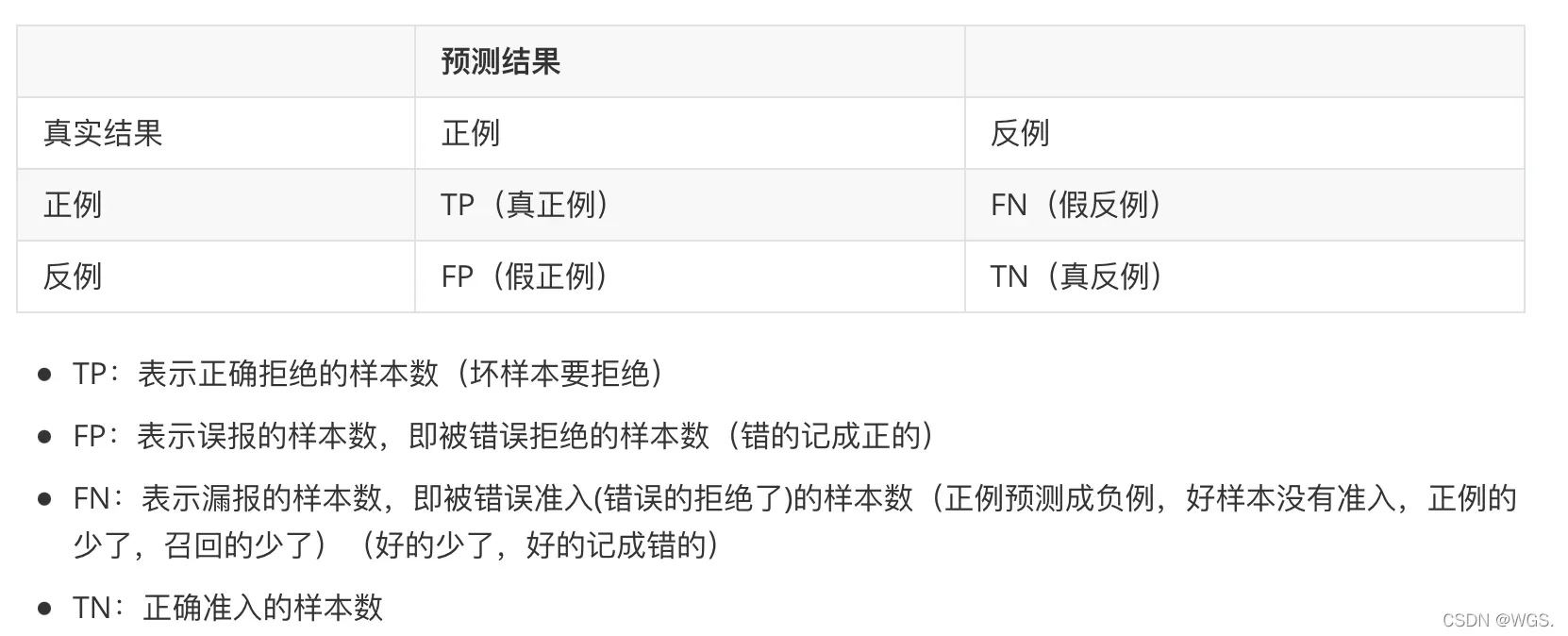
混淆矩阵
精确率、召回率、F1

'''精确率'''
def get_precision(y, y_pre):
'''
:param y: array,真实值
:param y_pre: array,预测值
:return: float
'''
return precision_score(y, y_pre)
'''召回率'''
def get_recall(y, y_pre):
'''
:param y: array,真实值
:param y_pre: array,预测值
:return: float
'''
return recall_score(y, y_pre)
'''F1'''
def get_f1(y, y_pre):
'''
:param y: array,真实值
:param y_pre: array,预测值
:return: float
'''
return f1_score(y, y_pre)
准确性

'''准确率'''
def get_accuracy(y, y_pre):
'''
:param y: array,真实值
:param y_pre: array,预测值
:return: float
'''
return accuracy_score(y, y_pre)
日志丢失
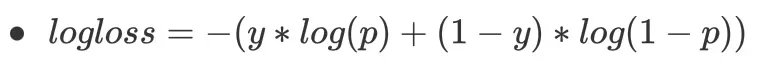
'''对数损失'''
def get_logloss(y, y_score):
'''
:param y: array,真实值
:param y_score: array,预测概率值
:return: float
'''
return log_loss(y, y_score)
def get_logloss2(y, y_score, eps=1e-15):
'''
:param y: array,真实值
:param y_score: array,预测概率值
:return: float
'''
y_score = np.clip(y_score, eps, 1 - eps)
def logloss_(true_label, predicted_prob):
if true_label == 1:
return -np.log(predicted_prob)
else:
return -np.log(1 - predicted_prob)
return sum([logloss_(y[i], y_score[i]) for i in range(len(y))]) / len(y)
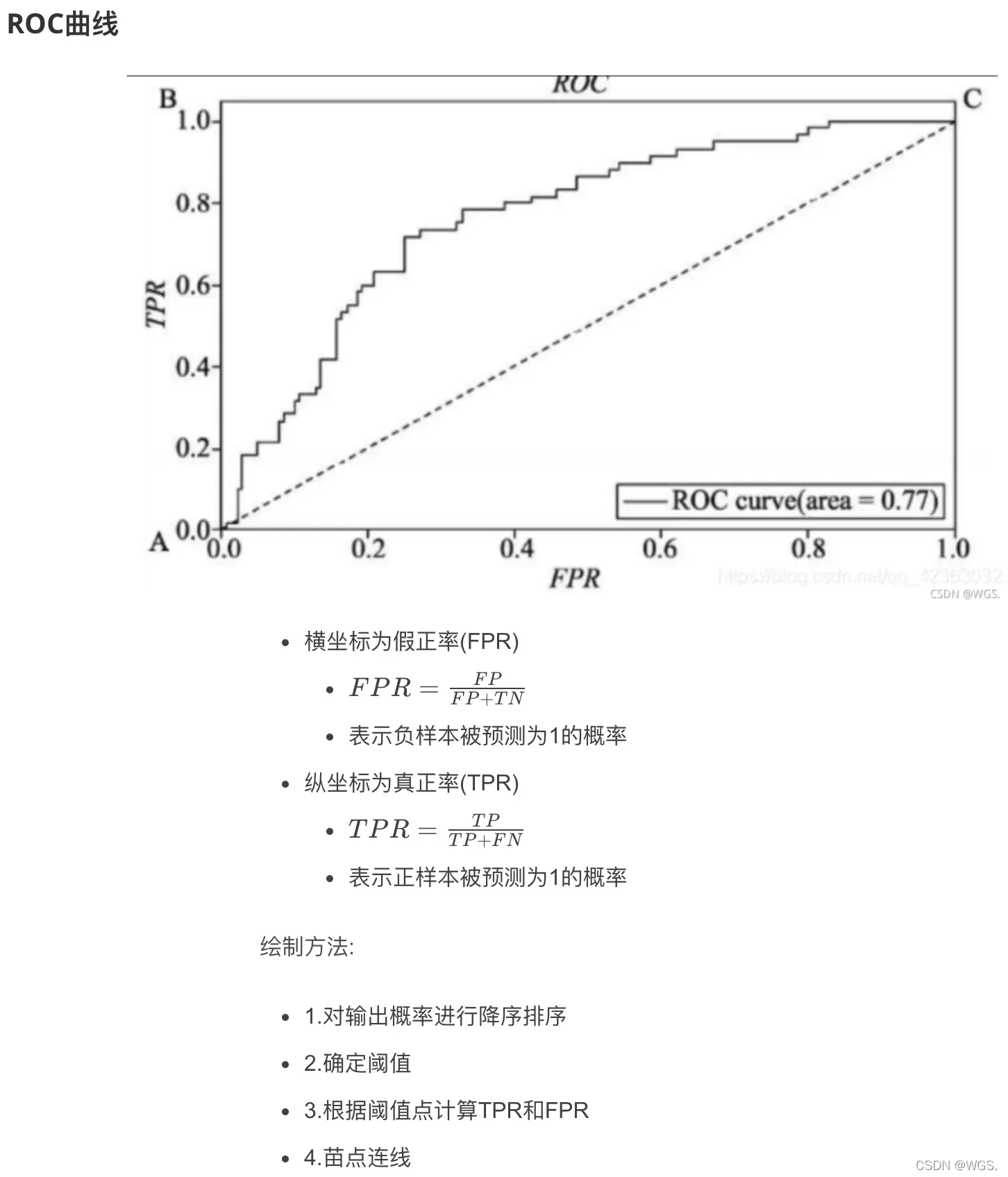
AUC


'''AUC'''
def get_auc(y, y_score):
'''
:param y: array,真实值
:param y_score: array,预测概率值
:return: float
'''
return roc_auc_score(y, y_score)
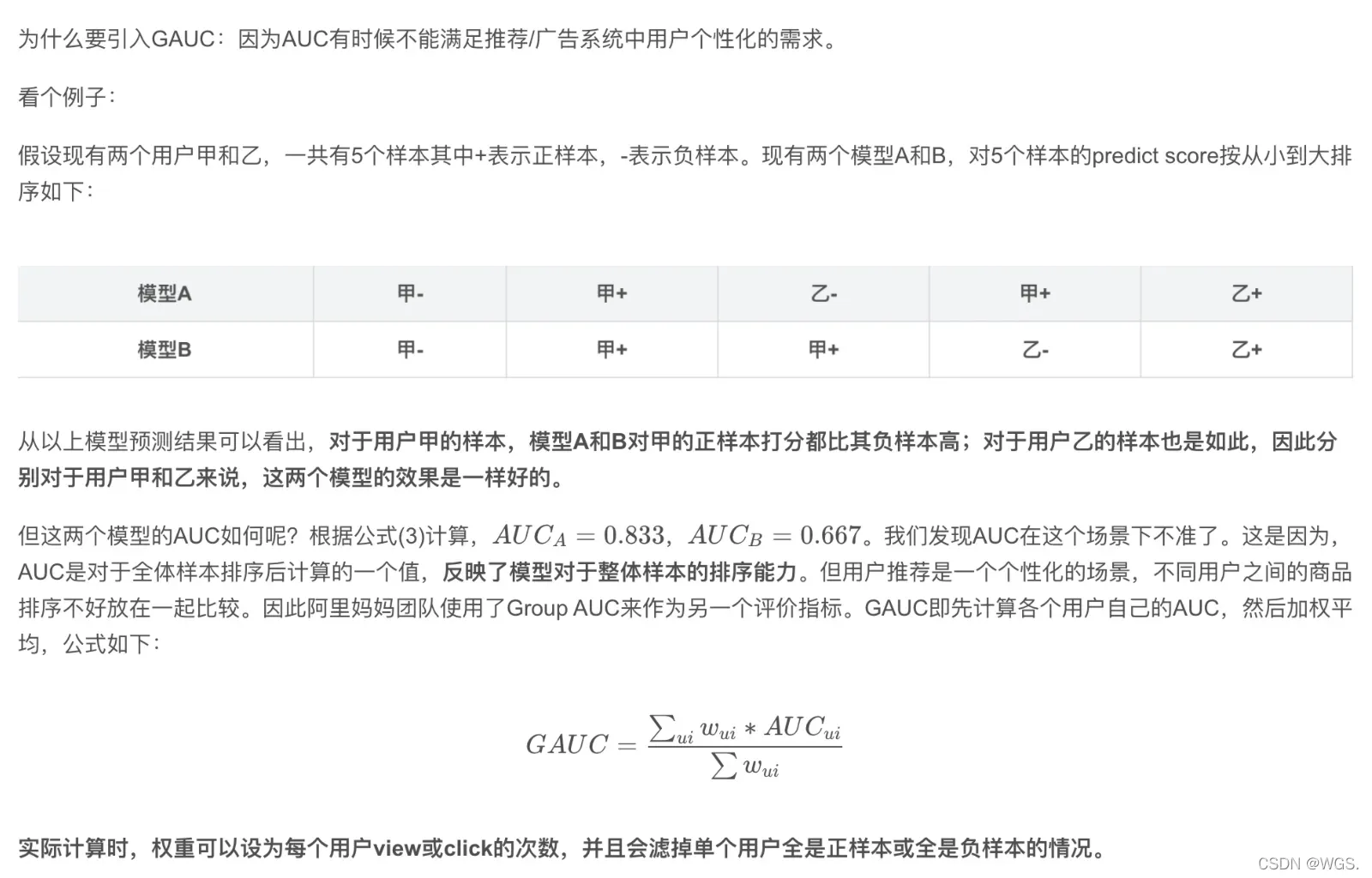
GAUC
'''GAUC'''
def get_GAUC(df, suid, label, model):
'''
:param df: dataframe
:param suid: user ID
:param label: label name
:param model: model
:return: 权重为点击数的GUAC、权重为样本数的GAUC、数据全为正样本或全为负样本的用户数
'''
# 计算测试集gauc
tmp_c = 0
tmp_wclick = 0
sumWAUCclick, sumWclick = 0, 0
sumWAUCall, sumWall = 0, 0
for suuid, data in df.groupby(suid):
# 过滤单个用户全是正样本或全是负样本的情况
if len(set(list(data[label]))) == 1:
tmp_c += 1
continue
# 计算权重为每个用户的点击数、每个用户样本数
wclick = data[label].sum()
tmp_wclick += wclick
wall = len(list(data[label]))
# 对于每个用户预测并计算其AUC
x = data.iloc[:, :-1]
y = data[label].values
# sklearn model将batchsize去掉,tf model可加batch size
y_pre_score = model.predict(x, batch_size=256)
aucUser = roc_auc_score(y.ravel(), y_pre_score.ravel())
# 分子、分母累加
sumWAUCclick = sumWAUCclick + wclick * aucUser
sumWAUCall = sumWAUCall + wall * aucUser
sumWclick += wclick
sumWall += wall
gaucclick = sumWAUCclick / sumWclick
gaucall = sumWAUCall / sumWall
print(' tmp_wclick ', tmp_wclick)
return gaucclick, gaucall, tmp_c
ks
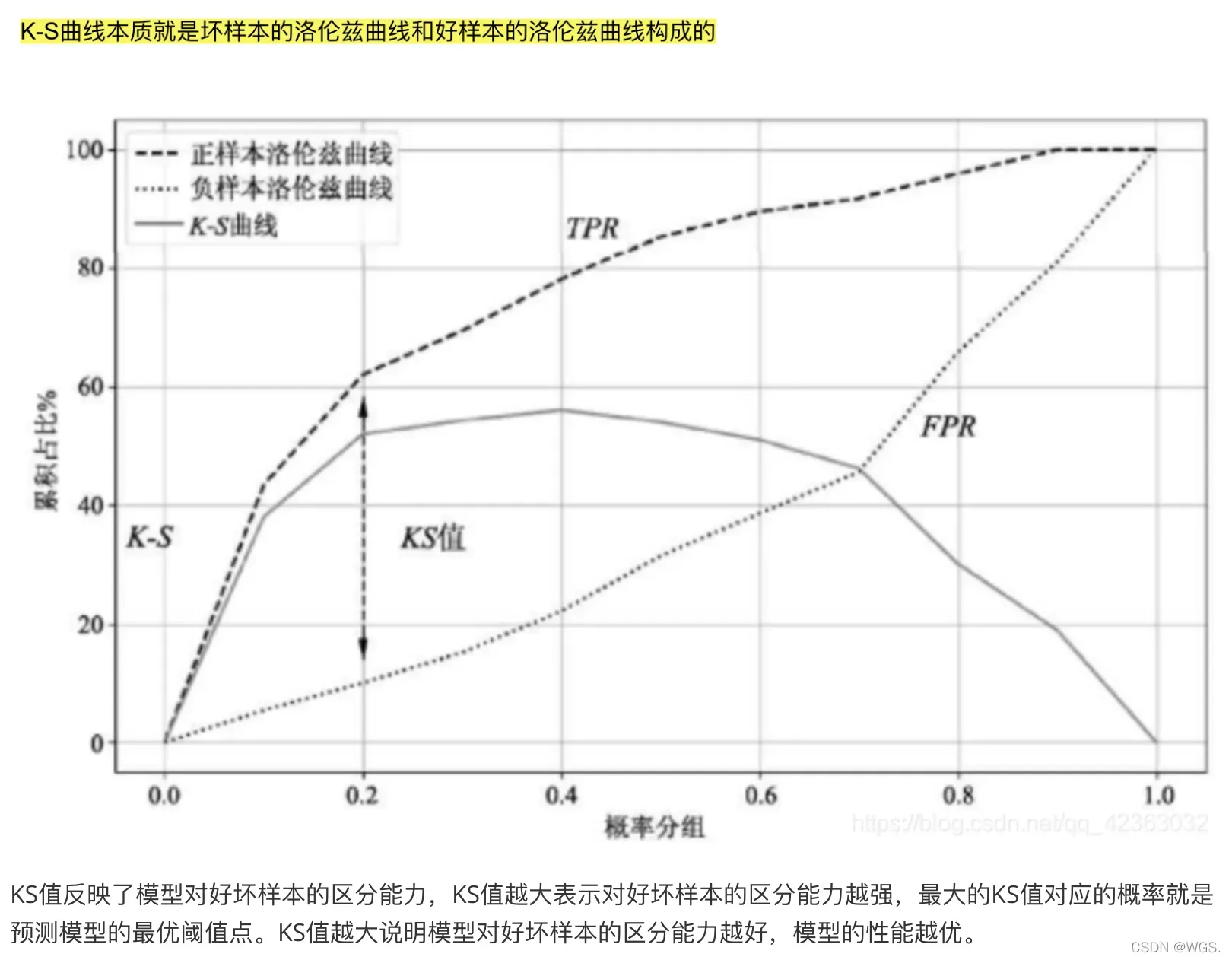
'''ks'''
def get_ks(y, y_score):
'''
:param y: array,真实值
:param y_score: array,预测概率值
:return: float
'''
fpr, tpr, thresholds = roc_curve(y, y_score)
return max(tpr - fpr)
样本不平衡时的可用指标
考虑负样本的F1

'''F1_weight'''
def weightF1ForPN(y, y_pre, F1_positive, alpha, beta, flag=False):
'''
:param y: array,真实值
:param y_pre: array,预测值
:param F1_positive: 正样本F1,即 get_f1()
:param alpha: 正样本占比
:param beta: 负样本占比
:param flag: 是否打印负样本信息
:return: F1_weight、负样本精确率、负样本召回率
'''
lenall = len(y)
# y = y.flatten()
pre = 0
rec = 0
precisoinlen = 0
recallLen = 0
for i in range(lenall):
# 精确率_负样本:所有预测为负中,真实为负的比例
if y_pre[i] == 0:
pre += 1
if y[i] == 0:
precisoinlen += 1
# 召回率_负样本:所有负例中模型为负预测的概率
if y[i] == 0:
rec += 1
if y_pre[i] == 0:
recallLen += 1
p_negative = precisoinlen / pre
r_negative = recallLen / rec
if flag:
print(' 预测为负的样本数:{},在这其中实际为负的样本数:{},负样本精确率:{}'.format(pre, precisoinlen, p_negative))
print(' 负例样本:{},负例中预测为负的数量:{},负样本召回率:{}'.format(rec, recallLen, r_negative))
F1_negative = (2 * p_negative * r_negative) / (p_negative + r_negative)
if flag:
print(' 负样本F1:{}'.format(F1_negative))
f1_weight = alpha * F1_positive + beta * F1_negative
return f1_weight, p_negative, r_negative
Specificity

G-Mean

'''G-Mean'''
def get_Gmean(recall_positive, recall_negative):
'''
:param recall_positive: 正样本召回率
:param recall_negative: 负样本召回率
:return: float
'''
return (recall_positive * recall_negative) ** 0.5
MCC

'''MCC'''
def get_MCC(y, y_pre):
'''
:param y: array,真实值
:param y_pre: array,预测值
:return: float
'''
lenall = len(y)
TP, FP, FN, TN = 0, 0, 0, 0
for i in range(lenall):
if y_pre[i] == 1:
if y[i] == 1:
TP += 1
if y[i] == 0:
FP += 1
if y_pre[i] == 0:
if y[i] == 1:
FN += 1
if y[i] == 0:
TN += 1
member = TP*TN - FP*FN
demember = ((TP+FP) * (TP+FN) * (TN+FP) * (TN+FN)) ** 0.5
mcc = member / demember
return mcc
版权声明:本文为博主WGS.原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42363032/article/details/122996356