一个深度学习入门的菜鸟,希望通过做笔记的方式记录下自己学到的东西,希望对同样入门的人有所帮助。希望大佬们帮忙指正错误~侵权立即删除。
如何评估模型对解决问题的“有用”程度需要测量和评估模型。每个模型都有自己的特点,随着因素的变化表现出不同的表现,因此需要选择合适的评价指标进行评价。
内容
1. 混淆矩阵
二、准确率(正确率)—— Accuracy
三、精确率(查准率)—— Precision
四、召回率(查全率)—— Recall
1、公式
2、意义
3、精确率和召回率的关系
五、PR曲线 & AP & mAP & BEP & F1-score
1、含义解析
2、AP —— 针对某一类别
3、mAP —— 目标检测算法中最重要的一个指标。
4、BEP
5、F1-score
六、ROC & AUC
1、灵敏度/真正率/召回率(TPR),特异度和假正率(FPR)
2、ROC(接受者操作特征曲线)
3、AUC(曲线下的面积)
七、IOU
八、如何选择评价指标
1. 混淆矩阵
下表就是著名的混淆矩阵(真·混淆bushi)
| actual positive | actual negative | |
| predicted positive | TP | FP |
| predicted negative | FN | TN |
🎈 让我们从一个字母开始:
T 表示本次预测结果正确;F 表示本次预测结果错误
P表示判为正例;N 表示判为负例
🎈让我们匹配字母
TP:本次预测为正例(P),而且这次预测是对的(T)
FP:本次预测为正例(P),而且这次预测是错的(F)
TN:本次预测为负例(N),而且这次预测是对的(T)
FP:本次预测为负例(N),而且这次预测是错的(F)
🎈举个栗子吧,比如说正例代表核酸检测阳性(P);负例代表核酸检测阴性(N)
那么TP代表的就是检测出来是阳性并且这一次判断是正确的,FP代表的就是检测出来是阳性并且这一次判断是错误的,TN代表的就是检测出来是阴性并且这一次判断是正确的,FP代表的就是检测出来是阴性并且这一次判断是错误的。
🎈很显然:TP+FP+TN+FN=样本总数
二、准确率(正确率)—— Accuracy
🌳 公式来源于上面的混淆矩阵
🌳的意思是:所有预测的正确百分比
🌳准确率虽然可以判断总的正确率,但在样本不平衡的情况下不能作为衡量结果的良好指标。
比如说P占了总样本量的99.9%,N占0.01%,如果我们毫无逻辑地全部判定为P,那么准确率将高达99.9%,但是实际上我们的模型只是无脑地全部判定为P,所以准确率在样本类别占比不平衡时衡量结果的效果并不好。
三、精确率(查准率)—— Precision
🌳 公式来源于上面的混淆矩阵
🌳表示的意义是:在所有判定为P的样本中判定正确的百分比(代表对正样本结果中的预测准确程度)
四、召回率(查全率)—— Recall
1、公式
公式来源于上面的混淆矩阵
2、意义
表示的意义是:实际为正(P)的样本中被预测为正(P)样本的概率
召回率越高,实际为正(P)被预测出来的概率越高,类似于“宁可错杀一千,绝不放过一个”。
3、精确率和召回率的关系
🌳 它们是一对矛盾的指标。一般来说,准确率高时,召回率会低;而召回率高时,准确率会低。
🌳 通常只有在一些简单的任务中才有可能有高精度和召回率。
怎么理解呢?举个栗子:(P为好果子,N为烂果子)
如果想要把好果子(P)的尽可能多地选出来,那么我们可以通过增加判断为好果子的数量(增加判定为P的数量)来实现。
极端情况:如果我们将所有果子都选上了(全部都判定为好果子),那么所有好果子(P)也会被选上,但这样精确率就会变低(公式中的FP变大导致),但此时FN为0,所以召回率为1(实现了要把好果子(P)的尽可能多地选出来);
如果希望选出的果子(判定为P)中好果子的比例尽可能高(即精确率尽可能高),那就只选最有把握的好果子(减少判定为P的数量,降低它的分母),但这样难免会漏掉不少好果子(FN变大),导致召回率较低(分母大了)。
五、PR曲线 & AP & mAP & BEP & F1-score
1、含义解析
🌳P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。
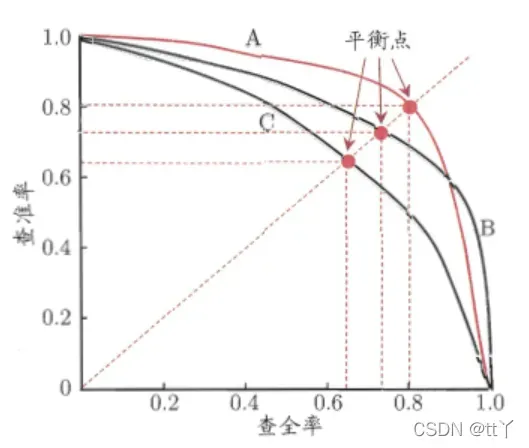
🌳在进行比较时,若一个模型的PR曲线被另一个模型的曲线完全包住,则说明后者的性能优于前者,比如上图中A优于C。
🌳A Vs B:因为AB两条曲线交叉了,所以难以比较,这时比较合理的判据就是比较PR曲线下的面积,该指标在一定程度上表征了该模型在精确率和召回率上取得相对“双高”的比例。
2、AP——针对某一类别
PR曲线下面的面积,通常来说一个越好的模型,AP值越高
3、mAP —— 目标检测算法中最重要的一个指标。
mAP是多个类别AP的平均值(即从类别的维度对 AP 进行平均):对每个类的AP再求平均,得到的就是mAP的值
取值:[0,1]
相同的值,越大越好
4、BEP
因为算这个曲线的面积(AP)不容易,所以人们引入了平衡点”(BEP)来度量
BEP:表示精确率=召回率时的取值,值越大表明该模型性能越好(所以A比B好)
但是BEP还是过于简单,所以更常用的是F1度量(F1-score)
5、F1-score
公式如下:
F1越大性能越好。
六、ROC & AUC
1、灵敏度/真正率/召回率(TPR),特异度和假正率(FPR)
公式如下
特异性:
因为我们所关心的是正样本(P),所以需要查看有多少负样本(N)被错误预测为正样本(P),因此我们更常用的是假正率(即1 – 特异度)
误报率:
TPR表示模型预测响应的覆盖程度,而FPR表示模型虚报的响应程度。
您可以从公式中看到它们所代表的含义
他们都是以实际是正还是负的角度看概率的(实际是P还是N),因此无论样本种类比例分布平不平衡,都不会有影响
2、ROC(接受者操作特征曲线)
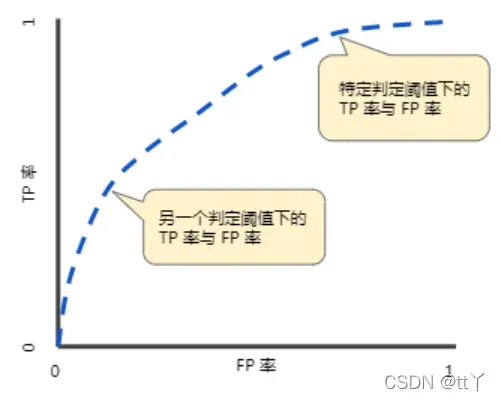
🌳其中横坐标为假正率(FPR),纵坐标为真正率(TPR)
🌳那ROC曲线该怎么画呢?
吃个栗子
| 样本序号 | 实际类别 | 判断是P的概率 |
| 1 | P | 0.3 |
| 2 | N | 0.5 |
| 3 | P | 0.6 |
| 4 | P | 0.4 |
我们依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。然后以此来计算对应的TPR和FPR,然后绘图即可。
🌳TPR 越高,同时 FPR 越低(即 ROC 曲线越陡),那么模型的性能就越好
3、AUC(曲线下的面积)
AUC是ROC曲线下的面积,介于0.1和1之间。
作为一个数值,它可以用来直观地评价模型的好坏。值越大越好。
七、IOU
🌳IOU是交并比,在这里是指预测的物体框框和真实的物体框框的交集的面积与并集的面积之比。
🌳IOU_Loss是根据IOU的损失函数:IOU_Loss = 1 – IOU
但它有一些缺点:
(1)如果你的预测框和真实框完全不重合,那么你的IOU为0,没有办法呈现出你的预测框距离真实框有多远,损失函数不可导,导致无法进行优化。
(2)可能出现两个IOU一样,对应的2个框框的面积也一样,但是相交情况完全不一样,那么IOU_Loss将无法区分他们相交的不同。
八、如何选择评价指标
根据实际情况进行选择,关注问题的趋势
例如,预测火灾的发生
我们要预测每一次火灾,即召回率高,可以通过尽可能牺牲准确率来实现。也就是说,每次实际发生火灾时,最好尽可能预测误报。
欢迎大家在评论区批评指正,谢谢~
版权声明:本文为博主tt丫原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_55073640/article/details/123003206