一. Batch
- batch_size的选取对模型精度和模型泛化能力的影响:
- .
模型没有BN层: - batch_size过大,模型收敛速度变慢。而且模型容易陷入局部最小值,模型精度低。
- batch_size适中,模型没有BN层,模型收敛速度很快,模型不容易陷入局部最小值(较小的batch相当于人为给训练加入了噪声),而且模型精度很高。
- batch_size过小,比如说小于数据集中的类别个数,模型会出现不收敛的情况。
- 模型有BN层:
- batch_size过小,BN层所计算的统计信息的可靠性越来越差,这样就容易导致错误率的上升;而在batch size较大时则没有明显的差别
- GPU:
- 在GPU性能(GPU利用率,不是显存)没有被完全利用的情况下,batch_size越大,模型训练的速度越快;但是收敛到同一个最优点时间越长
- 如何确定batch_size
- 1.
根据数据集的大小确定batch_size。 - 样本类别数目较少,而且模型没有BN层,batch_size就设置得较小一点。
- 样本类别数目较多,而且模型没有BN层,batch_size就设置得较大一点。尽量保证一个batch里面各个类别都能取到样本。
- 数据集很小,可以采取Full Batch Learning。每次用所有的训练集进行训练。
- 2.
GPU本身的特性 - GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优;gpu 上最好都是 32 倍数,和 wrap 一致(warp是SM的基本执行单元。一个warp包含32个并行thread)
- 3.
有BN层的模型 - 数据集很大,类别也较多时,batch_size尽量越大越好。
- 4.
不同的学习率策略 - 一阶优化算法:SGD(随机梯度下降)及其改良的如Adagrad、Adam
- 二阶优化算法如共轭梯度法、L-BFGS,如果估计不好一阶导数,那么对二阶导数的估计会有更大的误差,往往要采用大batch,batch设置成几千甚至一两万才能发挥出最佳性能(做信息抽取中的关系分类分类时,batch设置的2048配合L-BFGS取得了比SGD好得多的效果,无论是收敛速度还是最终的准确率)
- batch调参技巧
- 先搜几组learning rate/batch size的比值,然后就保持这个值搜个尽可能偏小的batch size
- 当模型训练到尾声,想更精细化地提高成绩(比如论文实验/比赛到最后),有一个有用的trick,就是设置batch size为1,即做纯SGD,慢慢把error磨低。
- 有BN层时,尽量保证每个batch包含所有类别,可以通过copypaste、cutout等数据增强的手段达到
- 参考链接:
- 训练神经网络时如何确定batch的大小?
- 深度机器学习中的batch的大小对学习效果有何影响?
- 知乎:怎么选取训练神经网络时的Batch size?
(评论更有趣)
2.学习率
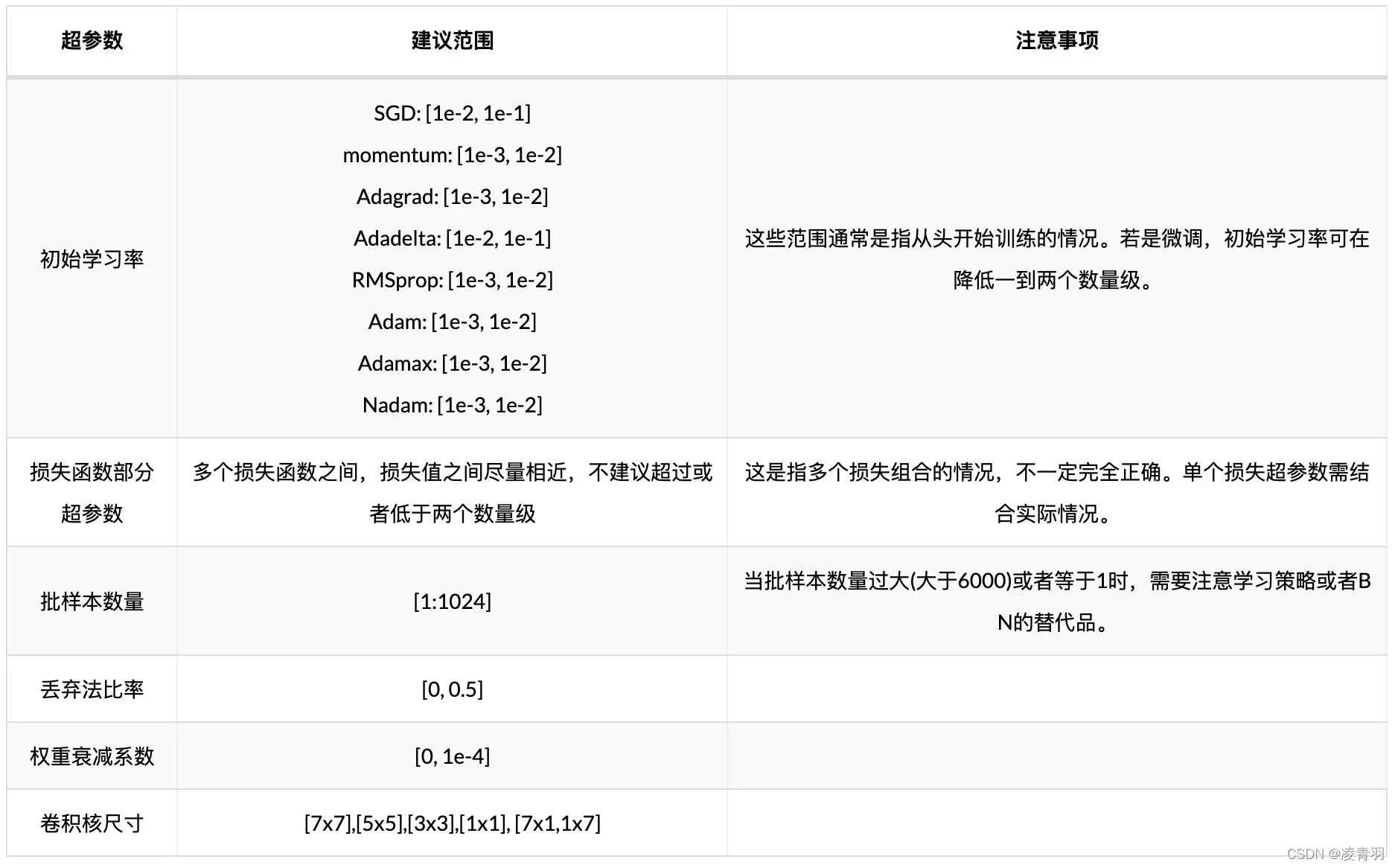
- 参考链接:
- 深度学习超参数调优
版权声明:本文为博主凌青羽原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_35759272/article/details/123026879