1. 背景
文章题目:《Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation》
文章下载地址:2112.05351.pdf (arxiv.org)![]() https://arxiv.org/pdf/2112.05351.pdf文献引用格式:Sung-Hoon Yoon, Hyeokjun Kweon, Jaeseok Jeong, Hyeonseong Kim, Shinjeong Kim, Kuk-Jin Yoon。 “Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation”。arXiv preprint, arXiv: 2112.05351, 2021.
https://arxiv.org/pdf/2112.05351.pdf文献引用格式:Sung-Hoon Yoon, Hyeokjun Kweon, Jaeseok Jeong, Hyeonseong Kim, Shinjeong Kim, Kuk-Jin Yoon。 “Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation”。arXiv preprint, arXiv: 2112.05351, 2021.
项目地址:无
二、文章指南
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects。However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness)。To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision。In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet。The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks。Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs。The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet。Based on the dissimilarity between the multiscale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions。The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset。For reproducibility, code will be available publicly soon.
现有的弱监督语义分割(WSSS)都是用的类别激活图CAM来定位类别目标。然而,由于分类损失是难以准确定位目标区域的,CAM更偏向于判别模式,是不提供准确的目标边界信息的。为了解决这个局限性,作者提出了一个新的框架(由一个主网络MainNet和支持网络SuppotNet组成。),该框架可从给定图像级的监督中驱动像素级的自监督。在该框架中,使用提出的局部对比模块RCM和对尺度注意力模块MAM,主网络可以从支持网络中以自监督的方式训练。
局部对比模块可以从支持网络中提取两种形式的自监督(1)从多尺度注意力模块生成的类别区域掩膜(2)根据类别区域掩膜,从特征中获得逐类别的原型。然后,每个主网络中的逐像素特征都通过原型以一种对比方式进行训练,使生成的CAM更见尖锐。多尺度注意力模块MAM使用从支持网络的多个尺度推断出的CAM作为自监督来指导主网络。基于主网络和支持网络的多尺度CAM的不相似度,可训练主网络的CAM来扩展少判别的区域。提出的方法在PASCAL VOC 2012数据集上表现出了最好的效果。代码将很快公开。
三、文章介绍
尽管随着深度学习的发展在语义分割方面取得了许多成就,但这些方法非常依赖于数据的标签。语义分割的一大挑战是难以获得数据的像素级标签来训练网络。
为了解决这个问题,弱监督语义分割(WSSS)使用了包含有限信息的标签,比如使用图像级的标签,草图,bounding box。目前只使用图像级的标签是WSSS的一个热点,因为相较于其他形式的标签它更容易获得。因此本文作者主要提出了只用图像级标签的弱监督分类。
WSSS的目的都是生成一个伪ground truth来训练模型。当使用图像级的标签时,一般通过CAM来定位目标。尽管使用图像级标签来定位,但它也是有局限的。相较于语义分割(可看作像素级的分类任务),图像级的分类任务是不需要像素级的监督的。如图1所示,得到的CAM,自然的倾向于突出目标的可判别区域(稀疏性),但不能匹配目标的边界(不准确性):
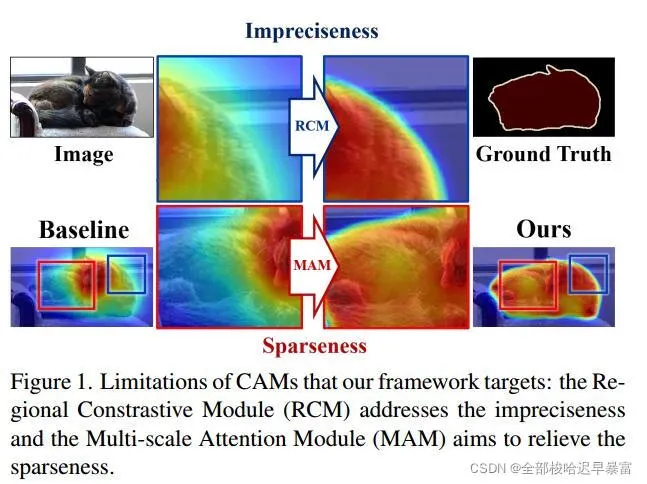
为了克服CAM存在的问题,作者提出了新的框架,能够从图像级的监督驱动像素级的自监督,以获得用于语义分割的准确的CAM。在框架中,被引导网络(主网络)通过梯度下降来优化,而引导网络(支持网络)通过指数移动平均EMA(Exponential Moving Average)来更新。为了训练主网络,作者提出了区域对比模块RCM(Regional Contrastive Module)和多尺度注意力模块MAM(Multi-scale Attentive Module),其中RCM主要解决边界不准确性而MAM主要解决判别目标时的稀疏性。
在区域对比模块RCM中,类别区域掩膜是通过对从支持网络的CAM取阈值得到的。这些掩膜都是作为像素级的自监督以声明哪一个像素属于哪一类。尽管我们可以使用这些掩膜直接作为主网络的监督信息,但我们还是使用了一种基于对比学习的间接训练方式,以防止主网络从错误的监督信息中直接学习。由于只使用图像级的监督信息,而缺乏区域信息,因此会产生不准确的结果。使用像素级的监督信息,提出的RCM使用对比学习的方式指导像素的正确分类,解决CAM的边界不准确问题。
另外,MAM主要解决的是判别目标的稀疏问题,该方法使用了多尺度推理的定位能力。作者基于主网络和支持网络中多尺度CAM的不相似性,定义了注意力矩阵。而注意力得分则被用为加权参数以生成多尺度CAM,它可用于主网络CAM中的自监督信息。
因此,本研究的主要贡献是:
• We propose the Regional Contrastive Module (RCM) that relieves impreciseness of CAMs through pixel-level self-supervision, with the generated class region mask and class-wise prototype, in a contrastive manner. 提出了区域对比模块RCM,以解决CAM的不准确性。
• We propose the Multi-scale Attentive Module (MAM) that leverages high localization capability of msinf – CAMs with the dissimilarity of CAMs at multi-scale, to expand CAMs to less-discriminative regions. 提出了多尺度注意力模块MAM,扩展CAM到低判别的区域。
• We achieve state-of-the-art WSSS performance on both the PASCAL VOC 2012 validation and test sets using only the image-level classification labels. 在PASCAL VOC 2012数据集上表现出了最好的弱监督效果。
1. 相关工作
弱监督语义分割WSSS:大部分WSSS都是使用的分类网络来提取CAM,并使用CAM生成一个像素级的伪标签,而CAM的问题在于它不能够提供准确的边界信息。为了解决这个问题,很多方法都是通过扩展或者校正CAM来匹配目标边界。比如Affinity-based方法,Adversarial Erasing (AE)方法,pre-trained saliency detection方法等。而作者并未使用显著目标检测模块也没有使用额外的数据集。
自监督学习:自监督学习不依赖大量的标签数据,近年来在图像去噪、图像分类和语义分割任务中取得了不错的成绩。也有许多研究使用对比学习来解决使用自我监督的图像级分类任务。最近有一些使用对比学习进行无监督语义分割的工作,这启发了本文。
2. 方法
(1)总体框架
整体框架如下图所示:
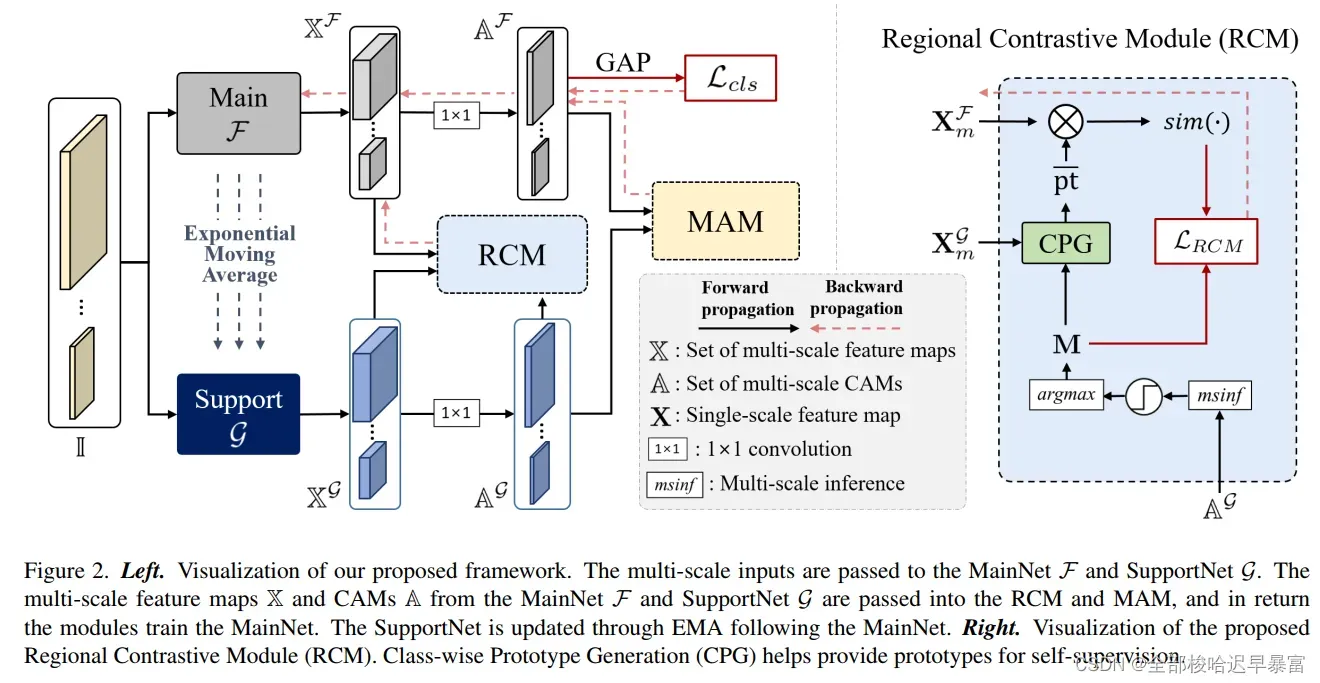
模型主要由两个网络,即主网络和支持网络。由支持网络生成的自监督,用于训练主网络。只优化主网络,通过后向传播可以获得梯度,而支持网络的更新则是使用指数移动平均EMA来获得。由于该方法使用到了多尺度图像,因此这里的尺度因子选择0.5,1,2,小尺度和大尺度的图像都是通过双线性内插得到的,而等尺度就是原图。
当给网络输入图像时,在分类层的前一层就可以得到特征图X。然后对特征图X使用1×1卷积,就可以得到CAM。在对CAM做全局平均池化GAP,和sigmoid非线性激活,就可以得到类别预测。
(2)区域对比模块RCM
RCM的结构如上图中的右边蓝色区域,RCM可以生成两种形式的自监督。首先,从支持网络的CAM,RCM可以生成指示每一个像素类别的类别区域掩膜。第二,RCM通过平均在支持网络中的每个类的类别区域掩膜的特征来获得类别原型。
类别区域掩膜(Class Region Masks):CAM能够在训练阶段的早期提供每个类别的定位区域,我们可以将CAM视为被分类为某个类别的逐像素得分图(pixel-wise score map)。为了进一步修正CAM的粗定位结果,我们只考虑生成类别区域掩膜过程中,激活值大于阈值的像素。
如果把前面获得CAM用A表示,掩膜用M表示,那么第k个掩膜的获得就可以表达为:

在这里,作者没有让网络通过额外的通道直接预测背景,而是使用前景分数较低的像素作为背景。
很多工作都使用了区域掩膜来做伪标签,然而本方法则在自监督的质量和稳定性上都具有优势。与其他模型不同,本模型没有使用如显著性模块或者预训练的分类器来修正区域信息得分,而是直接从支持网络的CAM中获得区域掩膜。由于模型对目标的定位使用了EMA算法,它能够使得训练过程更加稳定,
类别原型生成(Class-wise Prototypes Generation,CPG):在RCM中,类别区域掩膜不仅用于自监督,还用于类别原型生成,以获得每一个类别的原型。另外,还需要处理一些由于不完美的自监督所产生的脱轨现象,作者使用了特征级的对比学习。作者定义第k个类别的原型为:
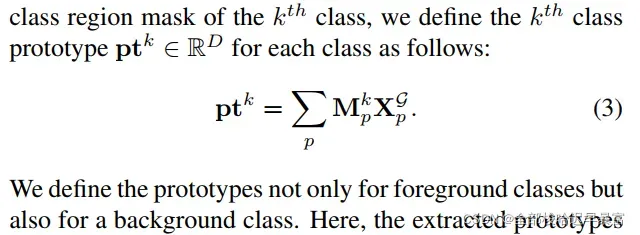
对多个图像的原型做平均,我们可以得到第k个类别原型的均值,用于表示第k个类别。
局部区域对比学习(Regional Contrastive Learning):主网络获得的像素级特征是通过对比学习的形式获得的。首先使用L2范数映射特征和原型到D维空间内,然后利用点积和指数函数定义他们之间的相似度:
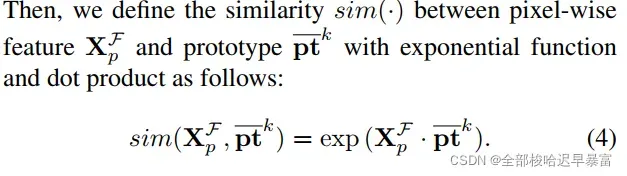
RCM的目标就是使得每一个类别的像素级特征都能够接近于这一类别的原型而远离其他类别的原型。而损失函数则是基于最大互信息的:

(3)多尺度注意力模块MAM
多尺度技术在语义分割中是一个常用的技术。对于高分辨率图像,网络一般容易捕捉细节信息,而对于低分辨率图像,网络则容易捕捉全局信息。因此使用多尺度能够让网络同时兼顾这些信息。MAM的动机也是来源于此,其整个结构如下图所示:
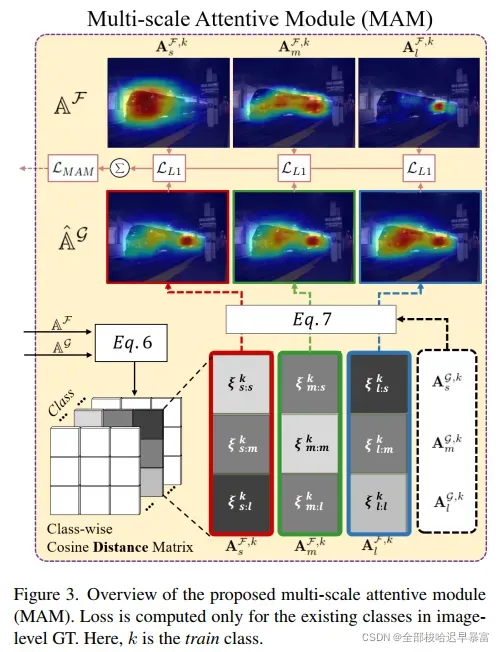
图3展示了主网络的多尺度CAM和支持网络多尺度CAM的余弦距离,用公式表示则如下:

因此,上述步骤可以表示为:
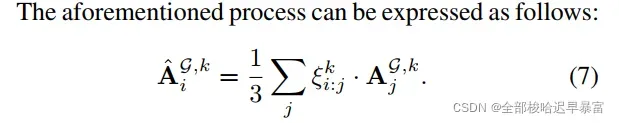
MAM的loss函数就可以被定义为:

(4)loss函数
整个模型的loss函数分成了3个部分:
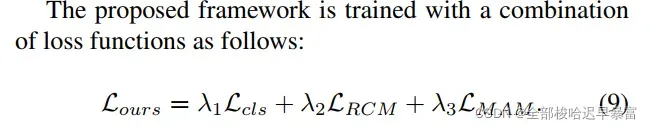
3. 实验
(1)数据集和评价标准
数据集使用PASCAL VOC 2012 dataset,评价标准使用mIoU。
(2)操作细节
语义分割的backbone选用的是ResNet38,图像大小192*192,RCM的特征图数量256,动量设置为0.997,初始学习率为0.01.
(3)消融实验
表1展示了在不同设置下的CAM的mIoU:
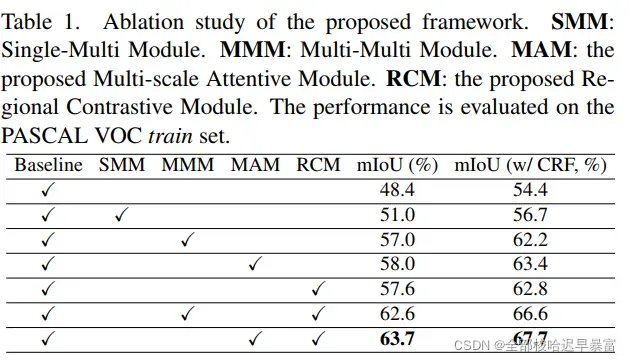
图4是CAM的定性比较:

另外又对CAM的精度和召回率做了统计:
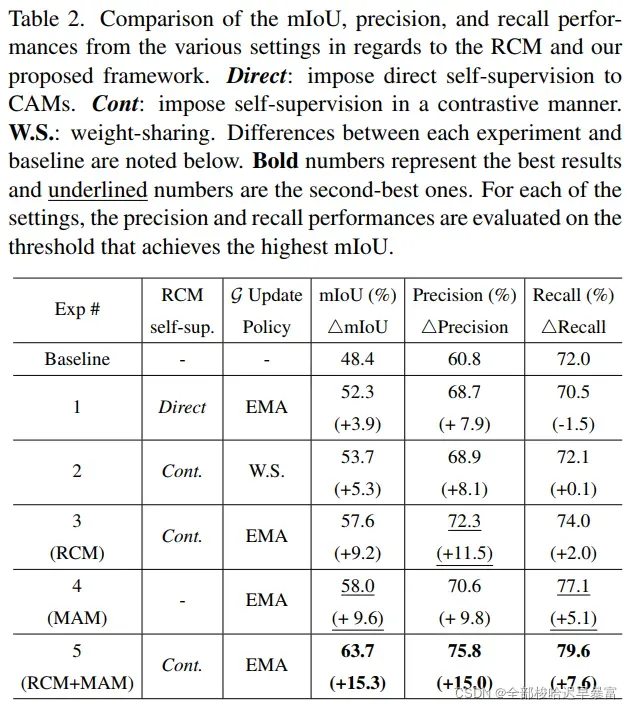
(4)模型比较
与其他模型的对比结果如下表所示:
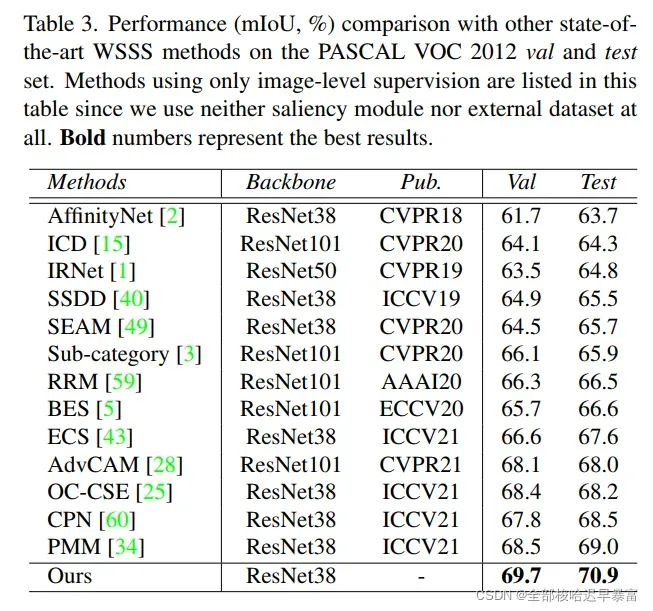
如果只使用图像级标签来做类别的IoU结果如下:

具体定性比较的可视化结果如下图所示:

(5)局限性
与其他使用CAM做伪标签的模型一样,该模型也有一个局限就是,伪标签生成的质量依赖于分类器的表现。如果一张图中出现了两个易混淆的物体,比如牛和绵羊,那么CAM也就容易混淆。如果分类器比较好,那就可以产生更具有表征性的原型,也就能更好的做自监督,效果也就会更好一些。
4.总结
版权声明:本文为博主全部梭哈迟早暴富原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/z704630835/article/details/123012695