



深度学习计算框架中的自动调优,尤其是高性能算子的自动生成是近年来非常热门的话题。本系列文章主要是对之前看到的零散信息做一个简单的总结。虽然,因为有些方向比较难,所以作者理解的很浅,文章在很多方面也只能是皮毛。这是第一篇,应该是介绍。
问题和挑战
深度神经网络(DNN)已成为了当代AI的主流方法并在众多领域取得了前所未有的成功,但它巨大的计算量也给AI产品的落地带来了巨大的挑战。另一方面,计算机体系架构的发展也随着登纳德缩放定律(Dennard scaling)和摩尔定律(Moore’s Law)的逐渐失效有了显著的变化。这些变化使得充分利用硬件资源的门槛变得比以往更高。在这样的背景下,计算框架的重要性就逐渐凸显了出来。它的主要作用就是以更易用的方式使AI算法能够充分利用计算资源,让其跑得更快,继而减少成本。
我们可以看到,神经网络计算框架这些年正在经历一些演变。早期比较常见的是基于运行时图解释器的方式,而近几年越来越多地转向基于编译器的方式。当然,一些功能全面,发展成熟的框架,如TensorFlow, PyTorch等,同时包含了两种方式。神经网络可以看作计算图(因为这个概念用得太泛了,为避免混淆,机器学习模型代表的计算图有时也称为ML Graph)。其中的操作(Operation),或称算子(Operator)对应计算图中的节点,节点间传输的数据对应计算图中的边。
- 图解释器(Graph Interpreter):一个自然的想法就是由一个运行时框架来解析并调度执行这些算子。当某个算子的前继算子计算完成,即满足数据依赖后就执行该算子。实现中可以按拓扑序执行算子,对于没有数据依赖的算子可以利用线程池等手段进行并行加速。这就是基于图解释器方式的主要思路。这种方式实现简单,不需要编译,方便计算加速库集成。相关的例子很多,如ONNXRuntime,TensorFlow Lite和一些训练框架的经典模式等。早期的网络结构比较简单且固定,也比较适用于这种方式。
- 深度学习编译器(Deep Learning Compiler):随着机器学习算法的多样化(如动态特性的引入),多平台的高性能算子需求等多方面的因素,基于编译器的方式逐渐热了起来。机器模型其实本质上其实就是一段程序,而为程序代码生成平台相关的高性能机器码正是编译器所擅长的。于是,基于编译器的神经网络计算框架,或称深度学习编译器开始崛起。相关的项目也一下子占据了我们的视野并且蓬勃发展,像XLA, Glow, nGraph, PlainML, Tiramisu, TVM, IREE, ONNC, TensorComprehensions等等。
两者的一般区别如下: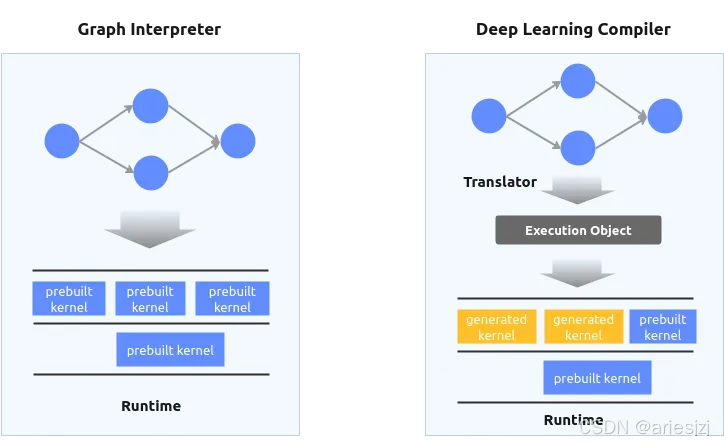
一般的深度学习编译器的工作范式是先由编译器将模型解析然后经过优化,最后编译生成可执行对象。这部分通常以AOT的方式离线执行。这个执行对象中包含加速器(如GPU)与CPU上的代码。前者主要是算子在加速器上的实现(如Nvidia GPU上可以以ptx或者cubin的形式),最后会在加速器上运行;后者主要是在CPU上的一些运行时控制逻辑,以及一些外部库调用,或者CPU的算子实现。这部分如果包含bytecode或者需要解释执行的东西,那后面还需要一个运行时虚拟机来加载执行。如果全部都编译成可直接在机器上跑的可执行程序,那运行时就可以不用了,或者说编译出的执行对象中包含了运行时。整个工作流程大体如下: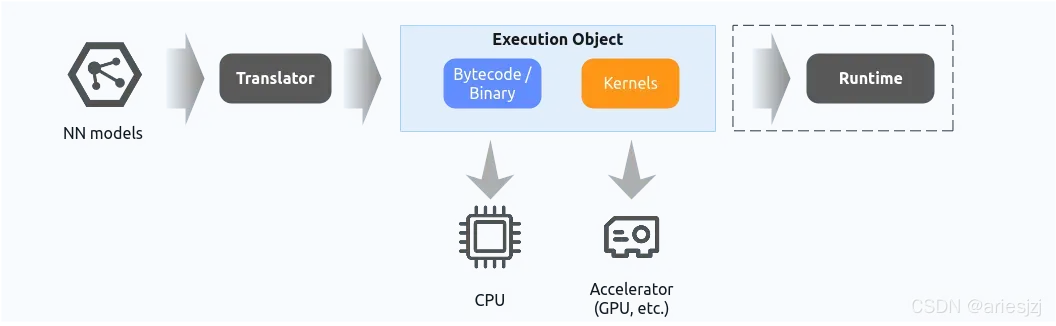

那为什么不直接用传统的通用编译器,如GCC,LLVM呢?一个原因是深度学习程序中的变量大多是张量(Tensor),而传统编译器对这种张量计算的优化并不是特别擅长。另外,通用编译器主要针对通用编程语言,缺少领域特定(Domain-specific)的语言支持,以及相关的特有优化。大体来说,深度学习编译器一般可分为两层,即图级别(Graph-level)和张量级别(Tensor-level)。一个神经网络程序经过前端解析,生成图级别的中间表示(或称High-level IR)。它一般是硬件平台无关的。在此之上会做计算图级别的优化,如算子融合(Operator fusion)。然后这层IR会lower到张量级别的中间表示(或称Low-level IR)。这层一般是硬件平台相关的,因为要考虑利用硬件特性生成高性能张量程序。这里主要讨论的是这层上的优化。最后通过编译器后端生成可执行的机器码。关于深度学习编译器更详细的介绍可以参考2020年的相关综述《The Deep Learning Compiler: A Comprehensive Survey》。
那么,核心问题就是如何将机器学习模型编译成特定硬件平台上高性能的机器码。众所周知,编译器是与硬件密切相关的。因此在讨论这个问题前有必要先来看下计算机硬件架构的变化与趋势。它也解释了为什么基于编译器的方式会在深度学习计算领域受到关注。2006年UC Berkeley一众大佬的文章《The Landscape of Parallel Computing Research: A View from Berkeley》从多个角度对并行计算进行了总结与展望,很多观点也可以在经典教材《Computer Architecture: A Quantitative Approach》第6版中找到(毕竟都出自图灵奖获得者David A. Patterson)。文中指出并行计算(主要是指大规模的并行计算,如1000核)才是未来的趋势。2006年左右,CUDA作为GPGPU方案问世,开启了它的繁荣之路,也算是这篇文章观点的印证(尤其是其中对大规模并行处理器与并行编程模型的部分)。值得注意的是,该文也提到auto-tuning技术会在并行计算的编译器中起到重要作用,因为在并行计算中,其搜索空间会更大。从面临的挑战上,文中提到计算机硬件架构的发展遇到了“三堵墙”:
- 功耗墙(Power wall)终结了Dennard Scaling,使得单核频率无法维持原来的增速(2006年就是4GHz左右了)。这也体现在了Moore’s law的放缓上。
- 内存墙(Memory wall)指由于内在访问速率无法满足处理器的请求,导致性能瓶颈在于访存(有张经典的图可参见《Computer Architecture: A Quantitative Approach》第6版Figure 2.2,这里就不粘了)。尽管由于Moore’s law放缓,单处理器速度增长放缓,但这个gap仍然很大。
- 指令级并行墙(ILP wall)指指令级并行的空间在逐步变小。从前Moore’s law与Memory wall使得架构设计往ILP方向努力。ILP(Instruction-level parallelism)指通过架构的创新和编译器的帮助,采用pipelining,superscalar processing,speculative execution,multiple way instruction issuing等手段挖掘数据并行。这些优化有个巨大的好处,就是对程序员是透明的,也就是说只要有钱升级硬件,不需要做啥就能获得性能的提升。但如今ILP的优化空间越来越小,因为这种优化一般限于一段指令内,而挖掘更粗粒度级别并行需要在更大范围内分析。而这样的范围是硬件所难以做的。因此,这种优化一般需要通过软件层面,即应用开发者或者编译器来做。
结合以上多方面的因素,计算机架构“被迫”朝着并行的方向发展。这些趋势在一张图上可以比较好地体现出来(图片来自40 Years of Microprocessor Trend Data):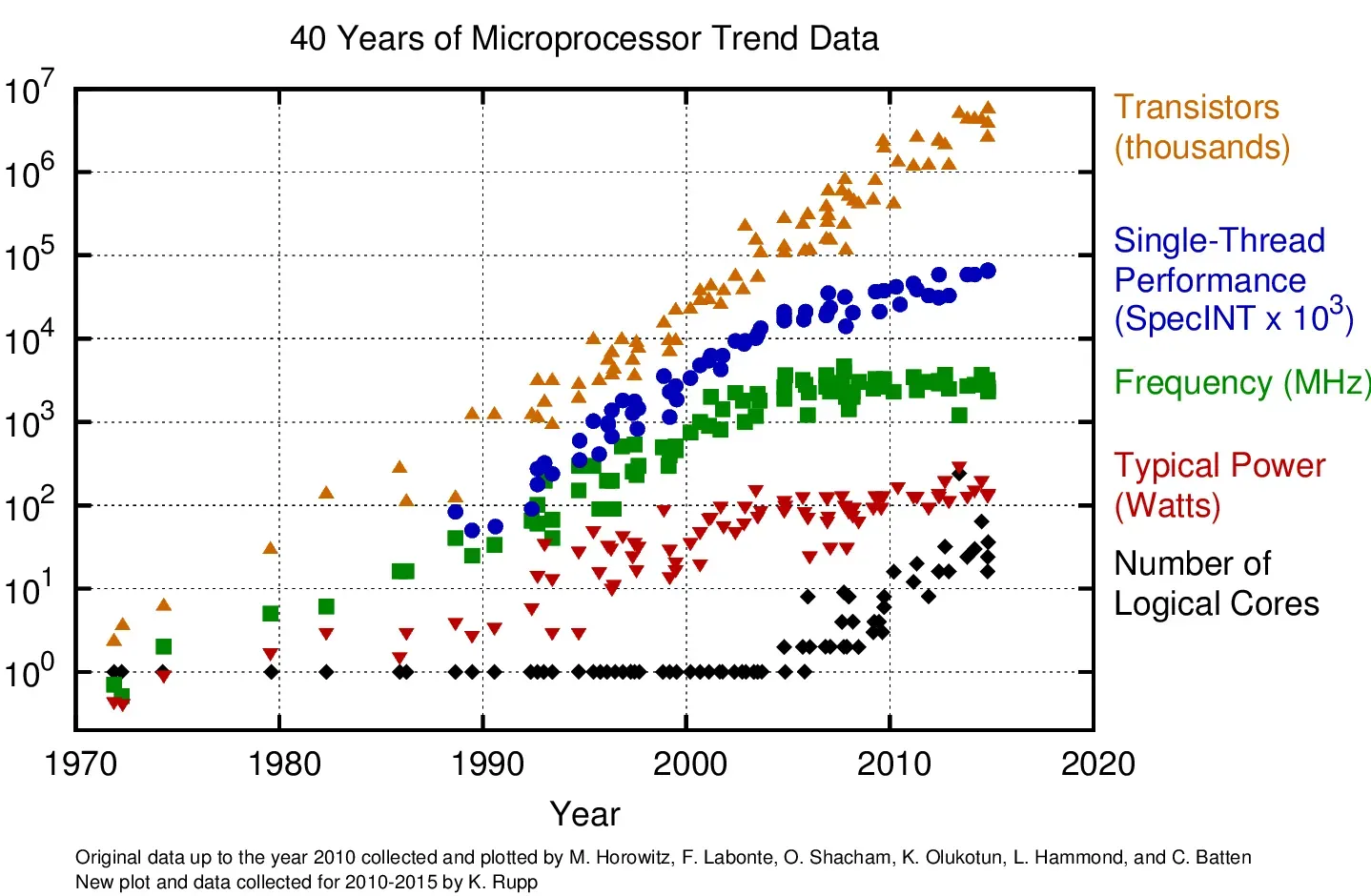

一方面CPU上的核越来越多,另一方面各种并行处理器,如GPU,NPU开始迅猛发展。并行化趋势给开发者带来的一个重大影响是性能的提升不再那么“透明”,等着硬件的升级程序自然提速的美好时代过去了。高性能的责任越来越多地交给了编译器与开发者。换句话说,要写出高性能的程序越来越难了,门槛越来越高了,码农是越来越不好当了。。。
前面提到,在并行计算时代,高写出高性能的程序越来越难。对于一个关于张量计算的操作,写它的硬件相关的实现(即kernel,或tensor program)或许不难,但要写出高性能的、尤其是结合硬件特性达到极致性能优化的kernel却非常难。处理器并行化程度的提升加剧了这种难度。大体原则上,为了在现代处理器上达到优异的性能,我们一般需要考虑几个因素:
- 并行度(Parallelism):并行化趋势下,处理器中有了更多地可以独立运行的核。程序为了利用这种硬件并行计算能力,需要利用好处理器中的多核或多个计算单元。这需要在保证依赖关系的前提下,将任务尽可能分布到这些计算资源上,并减少它们之间的同步和通信开销。由此衍生出指令级并行、数据级并行和线程级并行等技术。
- 时间与空间局部性(Temporal and spatial locality):由于前面提到的Memory wall,导致现实中很多workload其瓶颈在于访存。为了解决或者说缓解这一问题,充分利用时间与空间局部性,现代处理器基本都会设计有多级存储器层次(Memory hierarchy)结构,各级cache的访问时延可能会有数量级的差异。为了利用好cache,常常需要基于性能profiling数据的分析和细致的设计。 其中需要考虑到false sharing, thrashing, misalignment等问题。
- 专用硬件(Specialized hardware):对于一些高频计算场景,很多芯片上会提供一些专用的硬件支持,如CPU上的SIMD指令(如x86的SSE/AVX,ARM的Neon)用于向量计算。再如现代处理器很多会带矩阵计算专用硬件芯片或模块,如x86上的AMX(Advanced Matrix Extension),ARM上的Scalable Matrix Extension,Apple的Neural Engine,Nvidia GPU的Tensor Cores等。另外,如有多处理器组成异构系统,我们还需考虑将任务进行切分,然后在这些处理器上分配。
算子优化的挑战主要来自几个方面:
- 优化手段多样:虽然优化原则听起来还简单,但衍生开去有很多的优化手段,如tiling(blocking), promotion(shared memory and registers), loop unrolling, vectorization, double buffer, array packing, loop permutation, texture unit, cacheline alignment, prefetching, register cache, vectorized memory access, pinned memory, software pipelining, fastmath, WMMA intrinsics, memory coalescing, atomic operations, annotated pointer, warp-level primitives, multiple streams, cuda::pipeline等等。这些优化方法不胜枚举,而且还在不断增加中。如对Nvidia的GPU来说,CUDA的几乎每次迭代都会引入一些优化特性。让问题更复杂的是,一些优化中还有参数需要调节,如loop unrolling太大或太小都不好。register与shared memory用得太多或太少都不好。诸如此类的trade-off很常见,而且对不同的case还不一样。要在各种各样的情况下权衡这些优化及它们的参数就算对于优化专家来说也是相当耗费精力的。
- 优化的通用性与移植性:优化与硬件平台和输入参数都相关,这就意味着通用的优化非常难。不同类型的硬件架构的差异使得优化要考虑的因素也有很大不同。比如GPU(Nvidia)和CPU相比,情况可能更为复杂。 由于它们设计目的的不同(CPU低延迟,GPU高吞吐),一个比较大的差异来自存储器层次结构。CPU的为金字塔型,register, L1 cache, L2 cache和main memory各级存储容量逐级变大。而GPU的为沙漏型,一般有很大的register file。另外,CPU上的cache基本无法直接控制,而Nvidia的GPU暴露了一部分的cache(称为shared memory)让开发者可控。尽管它提供了提升局部性优化的机会,但同时也提高了优化的难度。除此之外,GPU上的内存访问还有一些特殊性要考虑,如对global memory的访问线程间最好lockstep方式进行访问,从而达到memory coalescing的目的。而对于shared memory的访问要避免不同线程用到同一个bank,以防止bank conflict(除非所有线程访问同一数据,这种情况可以broadcast)。GPU采用了面向高吞吐的高并发线程架构,意味着其性能不仅取决于单线程,还很大程度上取决于线程级并行。开发者需要显式地管理和控制计算任务的分布,比如分多少thread block(或称compute thread array,CTA ),每个thread block多少线程,每个线程干多少事,使硬件利用率尽可能高。同时还要考虑一些约束,比如每个thread block的最大线程数量,每个SM的最大shared memory,线程最大register使用量。总得来说,要得到最优的性能,需要非常小心细致地设计计算的分布与数据的搬运,同时充分利用专用硬件单元(如Tensor Cores)。更加另人头疼的是,因为cache大小,核数和一些硬件特性的差异,哪怕是同一个品牌的同一种处理器,不同的型号下也可能会导致优化策略有所差异。这意味着对于一个算子,在一个硬件上优化得可能好好的换个硬件可能又不那么灵了。最后,就算是考虑同一个算子,对于不同的参数、属性其优化可能也不同。
- 优化间相互影响:只考虑一两个优化或许还好,但我们的目标是最终的性能,它是各个优化的组合下的综合效果体现。各种优化之间可能会相互制约,相互影响。另外,这些优化的应用顺序可能对结果也会有影响(类似编译器中的phase-ordering problem)。这意味着找到最优的优化方法组合与序列就是一个困难的组合优化问题。而且对于不同的case可能影响还是不同的。这此因素让问题就变得更复杂。我们的最终性能目标是低延迟或者高吞吐。为了达到目标,我们通常需要提升更具可操作性的因素指标。但这些因素指标间是需要权衡的,它们都会对最终性能有影响,有时为了提升一个会需要牺牲另一个。实际的优化中,通常需要针对case,对这些因素进行权衡。总得来说,性能优化就是关于平衡的艺术。一个经典的例子如《Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines》中提到的stencil计算。最好的性能需要在locality, parallelism与 redundant work三者之间做trade-off,而不是在一个方向上走极端。另一个例子,Nvidia GPU上我们一般会努力提升occupancy来hide latency。但UC Berkeley的
《Better Performance at Lower Occupancy》
说明了一些情况下反而低occupancy达到更好的性能。
好了,以上罗嗦一堆,其实主要想说明对于一个算法,要实现正确的版本或许不难,但要结合硬件能力达到高性能就比较难了,要达到极致的性能更是难上加难。前面提到的种种因素使得性能优化成为了一门艺术,或者说是依赖经验的手艺活。拿Nvidia GPU来说,可以找到不少官方或非官方的性能优化指南,官方也提供了一系列的performance profiling工具,用于对给定的workload分析性能瓶颈甚至给出建议。尽管如此,它们大多也只能作为优化建议和guidelines,相当于老师傅的经验,并不是万灵药。总得来说,性能优化没有silver bullet。
对于这个问题,业界一个最为常见的方式是将预置的算子实现封装成计算库。如在深度学习领域,一些算子库其中包含一些常见算子的由专家深度优化的手工实现。这种库使用起来比较方便,能在较短时间达到比较高的性能,因此这种方式被广泛使用。硬件厂商一般也会提供这样的库,常见的如Nvidia的cuDNN与cuBLAS, Intel的MKL、oneDNN(原MKL-DNN与DNNL) ,AMD的clBLAS与ACML, ARM的ACL,IBM的ESSL等等。开源社区中也不乏像OpenBLAS, Eigen这样优秀的计算库。
手写库的方式虽然比较划算,但也有一些明显的局限性:
- 算法更新:高度优化的计算库不仅需要专家知识,还需要花大量的工程时间。而AI领域由于近几年异常火热,算法变更迭代很快。算法的研究者不断设计出新的算子或已有算子的变种。但当需要进行实验时,却发现缺乏高效的实现,导致运行很慢。在这个SOTA以周甚至更短时间被刷新的时代,一个模型训练个几个月,就算paper发出来了,也已经过时了。。。同时,一般来说,算法研究者对系统优化并不感兴趣或并不擅长。一些复杂的算子,即使是熟练的优化工程师也需要上周,甚至上月的时间才能达到理想的性能。这之间就产生了巨大的gap。这种方式需要消耗巨大精力与时间的性质使得开发者只能面向少数有限的头部算子。如科学计算中的线性代数计算,或者DNN中的matmul,convolution, pooling,softmax等高频算子,因为用得很多且容易成为性能瓶颈,值得花大力气优化。
- 组合爆炸:即使不考虑新的自定义算子,对于现有的算子,以下两个因素会导致待处理和优化的算子数量出现组合爆炸:
- 算子参数多样。算子的输入张量会有一些参数,如size, shape,memory layout(比如NCHW,NHWC亦或NC/32HW32,row-major还是column-major)等,另外算子本身也可能会有参数属性(如convolution有filter size, batch size, dilation, stride等 )。对于不同参数下的同一算子其性能最优的实现可能是不同的。因此,像一些库或推理框架中会引入算法的挑选机制,如cuDNN和TensorRT。比如对于convolution,cuDNN中实现有几个算法,对于给定的情况,cuDNN可以把它们都跑一下,然后挑出性能最好的一个。
- 算子融合。算子之间连接成计算图,现实当中我们通常会将它们融合。这样一方面可以减少global memory的访问,另一方面可以减少launch kernel的开销。但这样的组合方式太多,手写算子的方式大多只能以单算子为粒度,或者以有限的算子组合粒度来实现与优化。我们可以看到业界也有一些努力来解决这个问题,如CUTLASS通过C++模板使开发者可以自定义算子组合,cuDNN 8中引入了cudnn backend API可以吃一个子图。它们大大增加了灵活度,但也不是任意的组合,主要是一些像compute-intensive operator + element-wise operator这样的经典组合。由于要优化的情况非常多,即使硬件厂商的专家手工计算库,对于用户的各种各样的输入,仍很难在所有情况下达到最优。因此,在一些业界的工作可以看到在某些情况下性能上超越cuBLAS,cuDNN这类硬件厂商提供的计算库的情况。
- 平台移植:移植性和性能之间存在一定的矛盾,因为充分利用平台特有的特性往往是高度优化的重要手段之一。这意味着这些优化的可移植性降低了。对于很多手工实现的算子来说,他们的算法和硬件优化是混在一起的。一般而言,特定芯片的平均性能最好的库来自硬件制造商,因为理论上它最了解自己的硬件,并且可能能够使用一些内部机制对其进行优化。但是硬件厂商提供的库一般都是针对自己的硬件,这些优化不能应用到其他硬件平台上。
既然手写的方式有以上这些局限性,那么一个自然的想法便是利用自动化的方式,也就是自动kernel生成的方式。它的目标是对于给定算法自动生成目标平台上的高性能的实现。
另外,在编译器领域,我们也可以看到一些有趣的演进趋势。我们知道,编译器优化中其实有一些是组合优化问题。如一些优化中的参数选取问题,以及优化间的phase-ordering problem。对于这些问题,传统可能会使用基于heuristic的方法,或是建模成整数线性规划问题再用成熟的工业求解器求解。而逐渐受到关注的adaptive compilation使用编译、执行、分析这样的反馈循环来尝试找到最优的解,这和深度学习编译中的auto-tuning的思路是类似的。关于如何在编译器中应用机器学习方法近年来业界有非常多的尝试与丰富的成果,在这里就不展开了。近几年几篇总结性质的文章包括 2018年的《A Survey on Compiler Autotuning using Machine Learning》和《Machine Learning in Compiler Optimization》,以及2020年的《Machine Learning in Compilers: Past, Present and Future》。
综上所述,一方面机器学习的计算加速是由编译器来解决的,另一方面是编译器在尝试整合机器学习的方法。从这个角度来看,深度学习计算框架和编译器社区的演进似乎是交叉的,未来可能会出现更多有趣的化学反应。
Auto-tuning概念与萌芽
让我们回到深度学习算子的kernel自动生成这个主题上来。它大体有几个关键步骤,即解析与分析,优化与代码生成。其中最核心的问题是找到最优的schedule(来自Merriam-Webster的释义:“a procedural plan that indicates the time and sequence of each operation”),也就是算法与硬件的mapping。具体来说,就是比如如何做tiling,如何在核上分布任务,张量的访问顺序,内存如何在各级存储上分配等。它们可以用一系列的参数表示,这些参数值的特定组合形成一种配置(Configuration或Setting)。确定这个参数组合使性能最优的过程就是tuning,将之自动化就是auto-tuning。很多的现有用于图像处理或深度学习的编译器都会使用auto-tuning技术来寻找张量计算的最优实现,如Halide, TVM, XLA, TensorComprehensions等。Auto-tuning这个词在很多地方会看到,它们所表示的意思却不完全相同。为了避免混淆,先简单理一下概念。如cuDNN中有cudnnFindConvolutionForwardAlgorithm()函数会搜索convolution在给定情况下的最优实现。TensorRT也会在构建plan时对网络中layer进行算法实现的选择。这类方法更准确地说,是自动的算子kernel选择,与本文主要讨论的auto-tuning有所不同。本文提到的auto-tuning主要是指对schedule的自动调参。有了最优的schedule,就可以生成对应的高性能张量程序(或者说kernel)了。
确定算法实现中的最优schedule有两大类方法:
- Analytical model:参数通过解析模型来确定,也称model-driven方法。主要通过数学方法对系统中各种参数关系进行定量地分析和建模。这类方法在构建模型过程中通常需要较强的领域相关知识,适用于相对简单的计算模式,且可能会有较多的假设。优点是一般可解释性强,且确定参数的过程较快。
- Empirical search:基本思想是对特定的问题,迭代地产生很多代码的变体,然后通过性能评估确定对于给定硬件平台哪个变体最好。优点是相对来说通用性更强,不需要太多领域相关知识。缺点是搜索过程较长,且可解释性较差。
当然,两者也可以相互结合,如通过analytical model得到的参数作为初始值再在邻域内通过local search进行调优。
深度学习模型中有各种各样的算子,它们通过融合后又构成更复杂的计算子图。对这些各种各样的计算子图自动生成高性能的kernel是一个非常有挑战,可以说到目前还没有彻底解决的问题。让我们先从最基本,最经典的BLAS开始说起。BLAS在科学计算中有着广泛应用,在如今的机器学习模型中也有广泛的应用(像Dense/FC,Convovlution,RNN等)。业界从上世纪70年代开始涌现出一批BLAS计算库,比如EISPACK,LINPACK,LAPACK等。以BLAS中的矩阵相乘(Matmul, GEMM)为例,它是非常完美的并行计算对象。对于输出矩阵中的每个元素的计算,相互是独立的。考虑到复杂的现代计算机体系架构,我们通常不会简单地按照其原始的数学定义来计算。正如前面一节提到的,优化中有不少的参数需要tuning。因为BLAS应用广泛且计算模式相对简单,因此早期的tuning工作不少是聚焦在它的。
借用2016年论文《BLISlab: A Sandbox for Optimizing GEMM》中的一张介绍GEMM实现中做blocking利用多级cache优化的示意图。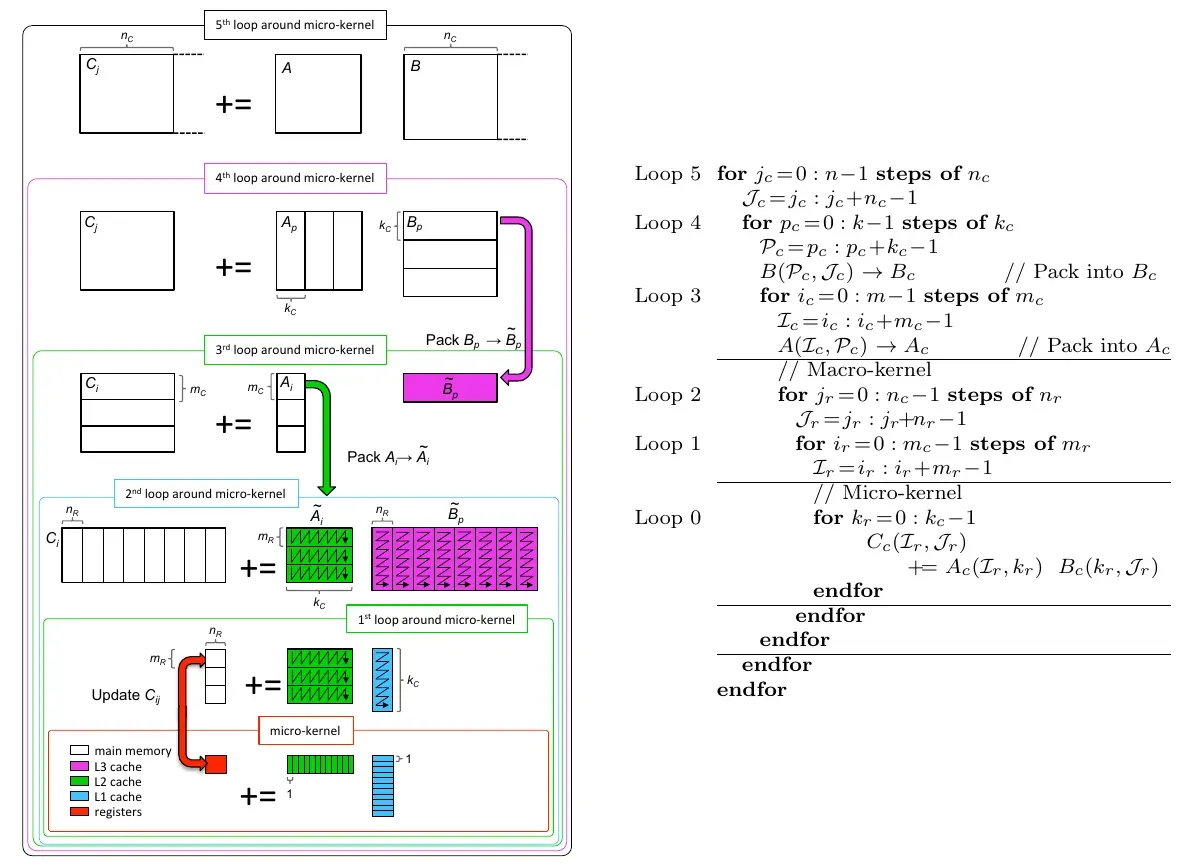
这是针对CPU的,类似的图在Nvidia的CUTLASS的介绍中也有,那是针对GPU的,因此各级存储相应地变成了global memory, shared memory和register file。它们的基本思想都是类似的,就是将矩阵层层分块,塞到各级的存储当中,让最内层真正的计算在最快的存储上进行。但问题来了,结构是这么个结构,但每级怎么切,切多大,每个线程干多少活让性能最好呢?2009年论文《A Note on Auto-tuning GEMM for GPUs》中以GEMM为例,考虑了分层blocking中的5个参数,即三个矩阵的分块大小与thread block的大小。当然,现代处理器上会考虑的参数更多。

对于像GEMM或类似的计算密集型操作中的tuning,很早开始就有相关工作,其中不乏auto-tuning的尝试。
- PHiPAC:1997年论文《Optimizing matrix multiply using PHiPAC: a portable, high-performance, ANSI C coding methodology》中的PHiPAC将AEOS(Automated Empirical Optimization of Software)范式应用到矩阵相乘。它主要用于开发基于ANSI C的可移植高性能BLAS库。PHiPAC由三个部分组成:一是抽象了编译器和处理器的机器模型,提供可移植高性能ANSI C程序的的guideline。二是参数化的code generator,可以根据那些guideline产生代码。三是搜索脚本,用于自动针对特定系统通过更改code generator的参数(如register和L1 cache blocking size)并对生成的程序进行benchmarking对代码进行tuning。搜索使用best-first方法,搜索过程中会拟合用于预测执行时间的模型。
- ATLAS:1998年的论文《Automatically Tuned Linear Algebra Software》和2001年的《Automated Empirical Optimizations of Software and the ATLAS Project》中的ATLAS(Automatically Tuned Linear Algebra Software)与PhiPAC一样,都是empirical search类的方法。它同样也是AEOS这种范式在BLAS领域的实践。所有Level 3 BLAS函数(TRMM, TRSM, SYMM, HEMM, SYRK, SYR2K, HERK, HER2K)的核心是GEMM。前面提到对于GEMM的实现可以分为外层和内层,ATLAS使用了人类专家优化的内层kernel,然后基于code generation与timer搜索参数化code generator中的一些参数,如是否拷贝转置A和B,register blocking(用于A与B的寄存器),loop unrolling等相关参数。ATLAS先通过一些general timings得到L1 cache size, pipeline depth等信息,然后尝试多种策略,并从中选择性能最好的。之后,在2005年论文《Is Search Really Necessary to Generate High-Performance BLAS?》中提到使用analytical model可以产生与empirical search性能相当的代码实现,并且将ATLAS中的global search engine替换成model-driven optimization engine从实验证实了这一观点。
- FFTW:1998年的论文《FFTW,an adaptive software architecture for the FFT》中的FFTW针对快速傅立叶变换(FFT)算法,应用black box优化技术自动tune库中核心组件的实现。它指出以往方法主要以最小化浮点操作数量为目标,但除此之外,复杂的处理器流水线与存储器层次结构对最终性能都会有影响。因此,浮点操作数数量少不代表性能更好。FFTW采用了adaptive方法来对特定硬件产生高性能的Cooley-Turkey FFT算法实现。FFTW包含executor,codlets和planner三大组件。Codelet完成部分的计算,由FFTW的codelet generator在编译时生成。在计算开始前,planner使用动态规划以最小化实际执行时间为目标找到codelet的最优组合。最后,executor执行由planner指定的codelets组件。
- SPARSITY:2001年的论文《Optimizing sparse matrix computations for register reuse in SPARSITY》中的Sparsity系统用于根据硬件自动构建sparse matrix kernel。它主要针对低计算密度的sparse matrix-vector multiplication。Sparsity系统会做如register blocking, cache blocking, loop unrolling, matrix reordering和reorganization for multiple vectors等优化,最后通过code generator产生C代码。文中主要讨论寄存器级优化,包括register blocking和reorganization for multiple vectors。为了找最优的register block size参数,performance model被用来预测参数配置下的性能。
- Active Harmony:2002年的论文《Active Harmony: Towards Automated Performance Tuning》中的Active Harmony automated runtime tuning system聚焦于使用库的通用应用,使它们变得tunable。该系统在运行时自动搜索算法(如heap sort或是quick-sort)与参数(read-ahead size)从而达到性能优化(从CPU时间或者memory space上)的目的。它需要库的配合,系统中的Library Specification Layer帮助库开发者暴露同一API的多个变体,这样就可以选取合适的库。然后Harmony Controller会基于该层来进行库的选择。自动选择算法早期用的是greedy算法,之后用Nelder-Mead simplex方法。由于该算法要求函数是连续的,因此使用nearest integer point来近似连续空间中所选点的性能。
- SPIRAL:2004年的论文《Spiral: A Generator for Platform-Adapted Libraries of Signal Processing Alogorithms》中的SPIRAL主要用于生成用于信号处理变换(如DFT, WHT, Haar transform, discrete wavelet transform)的库。它包含三个主要组件:formula generator根据变换生成算法(用SPL表示),formula translator将算法编译成程序,与search engine。先由formula generator和formula translator产生不同的实现,search engine在它们之中搜索给定平台上的最优的版本。系统中实现了多种搜索方法:exhaustive search, DP, random search, hill climbing search和STEER,以及结合上述搜索方法的元搜索算法。
- OSKI:2005年的论文《OSKI: A library of automatically tuned sparse matrix kernels》中的OSKI(Optimized Sparse Kernel Interface)是用于稀疏线性代数的库。它采用基于库(Library-based)的方法,针对稀疏矩阵上的计算(如matrix-vector multiply,triangular solve), 通过调节选取数据结构与代码变换,预编译了每个操作的上百个变体(通过数据结构的选取和代码变换),然后在运行时选取最优的变体。 另外,它还提供一些机制帮助tuning,如库可以对给定矩阵上的操作进行监视,然后用该信息确定如何调参。它还允许用户提供workload的hint(如矩阵的结构信息)。
- BTO:2009年的论文《Automating the Generation of Composed Linear Algebra Kernels》中的Build to Order BLAS(BTO)编译器主要用于BLAS中level 1和2操作(相比level 3其数据重用比较少)。编译器的输入是由annotated MATLAB表示的矩阵与向量计算的语句序列,输出是经过tuning后的C++实现。该编译器会枚举循环融合的策略决定,然后使用基于analytical与empirical的技术确定最好的选择。
- BLIS:2001年的论文《A Family of High-Performance Matrix Multiplication Algorithms》针对硬件中的多层存储层次结构,相应地采用分层的方法实现矩阵乘法。经验表明,高性能硬件架构包含各种类型(local, shared, distributed)存储,使得对一个操作需要多个算法才能达到最优性能。2001年论文《FLAME: Formal Linear Algebra Methods Environment》中的FLAME(Formal Linear Algebra Methods Environment)主要用于生成高性能线性代数算法的实现。FLAME让开发者可以系统性地对于一个操作构建一族算法。2015年论文《BLIS: A Framework for Rapidly Instantiating BLAS Functionality》 中的BLIS(BLAS-like Library Instantiation Software)作为FLAME的一部分,是一种允许开发者在新的硬件架构上快速生成高性能的BLAS(或类似BLAS)实现的基础框架。各种GEMM上由于参数组合(如conjugation, side, uplo, trans, diag等)会需要很多实现。而它可以提高开发这些实现的效率。2008年的论文《Anatomy of High-Performance Matrix Multiplication》介绍了GotoBLAS(现OpenBLAS)中高性能矩阵相乘实现中的设计。基于分层思想,它将GEMM的计算通过blocking与packing分层,并分析了其中相关参数(如分块大小)如何选取。BLIS中也基于这种层次化结构,并将循环内层称为micro-kernel(这一层是架构相关的),外面两层称为macro-kernel(这层处理不同操作的差异)。这样,对于一个硬件架构,只要开发micro-kernel,然后调整macro-kernel中的关键参数,便可自动实例化高性能的level-3 BLAS功能。这种模块化的设计,为使用解析的方法确定参数提供了方便。之后,2016年的论文《Analytical Modeling Is Enough for High-Performance BLIS》基于BLIS,尝试通过解析模型的方式确定矩阵相乘实例化时中的参数。
这些早期的作品非常具有开创性,为后续的发展奠定了良好的基础。这些方法大致可以分为两类,一类是算法实现的自动选择,一类是算法实现中的参数调整。在本文主要关注的后一类方法中,这些早期工作的局限性主要体现在几个方面:
- 适用范围比较受限,大多还是集中在BLAS。
- 在tuning过程中考虑的参数比较有限(主要考虑block size)。
- 硬件平台主要是CPU。
毋庸置疑,BLAS非常重要,它浓缩了工程中的最常见的矩阵计算形式。在机器学习,尤其是深度学习领域,虽然各种算法与网络架构日新月益,层出不穷,但很多计算(尤其是计算密集型的)最后能被转为BLAS操作。一个对计算优化来说的好消息是近几年来Transfomer系模型的繁荣(用Transformer定义所有ML模型,特斯拉AI总监Karpathy发推感叹AI融合趋势,虽然最近貌似又被反超了一把:魔改ResNet反超Transformer再掀架构之争!作者说“没一处是创新”,这些优化trick值得学)。Transformer的好处是它的主要计算是Matmul而不是更为复杂的Conv和RNN。或许,Transformer网络结构的受人欢迎与快速发展也可部分归因于其对计算加速的友好。
但话说回来,BLAS虽然应用广泛,但现实应用中的计算远不止于此。在各种科学计算,以及机器学习模型中除BLAS外的其它张量计算,也都会有较为严苛的性能要求。另外,将神经网络中的的算子独立地tuning会失去结合上下文优化的机会。总得来说,我们要考虑的是对于通用的张量计算,如何对于给定算法,针对特定硬件平台生成高性能的实现,或者说确定它的schedule参数。这些参数可能涉及tiling, parallelism(如何在core上分布), loop orders(维度上访问顺序)等多个方面。另外,除CPU外,在GPU,NPU,FPGA等硬件平台上由于新的约束或硬件特性给tuning带来了更大更多的挑战。因此,对于更广泛的计算类型、更大的搜索空间、与更多样的硬件平台上的算子自动生成仍然有很大的探索空间与研究价值。
Auto-tuning问题本质上是调度参数空间中的搜索问题,也即调度参数上的组合优化问题。遗憾的是它是NP-hard的。这意味着,这样的问题通常无法有多项式复杂度的算法,或者说是intractable的。由于算子优化中的参数搜索空间往往很大,因此要在合理时间内找到最优解几乎不可能。这样的情境我们似乎有种熟悉感,因为已经遇到过很多了。像神经网络架构搜索,异构调度,模型压缩,编译器(如instruction scheduling, graph coloring)等方向中其实都有类似的问题。由经验可知,对于这类问题,虽然我们无法保证找到最优解,但仍可以通过一些方法找到一个比较优的解,从而帮助我们优化性能。对于这类NP-hard问题的通用解法与套路,之前曾经在一篇文章中简单讨论过:《奔跑吧,旅行商 – 当机器学习遇上组合优化》,这里就不再多说了。后面,我们也会看到一些熟悉的方法再次出现在auto-tuning领域。
对于更通用的计算,尤其是如火如荼的深度神经网络中的张量计算,如何自动生成高性能算子一直是多年来的热门话题。学术界和工业界都对它充满热情,相关的研究和实践也在不断涌现。其实,这些只是铺垫。以后有时间的话,我会写下一篇,再讲。 . .
版权声明:本文为博主ariesjzj原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/jinzhuojun/article/details/122891904