
1. CUDA 基础
1.1. CUDA 简介
GPU 加速计算正在逐步取代 CPU 计算,近年来加速计算带来了越来越多的突破性进展,各类应用程序对加速计算日益增长地需求、便捷地编写加速计算的程序的需求以及不断改进的支持加速计算的硬件设施,所有这一切都在推动着计算方式从 CPU 计算过渡到 GPU 加速计算。
无论是从出色的性能还是易用性来看,CUDA计算平台均是加速计算的重要实现方式。CUDA 提供了一种可扩展于 C、C++、Python 和 Fortran 等语言的编码接口,并行化后的代码能够在 NVIDIA GPU 上运行,以大幅加速应用程序。它包含有 DNN、BLAS、图形分析 和 FFT 等等库,并且还附带功能强大的命令行和可视化分析器。
CUDA 支持许多领域的超性能计算应用程序:计算流体动力学、分子动力学、量子化学、物理学 和高性能计算 (HPC)等等。
学习 CUDA 将能帮你加速自己的应用程序。应用程序加速后的执行速度会远远超过原本在 CPU 上的执行速度,使那些在 CPU 上性能受限的计算得以进行下去。在本教程中, 你将学习使用 CUDA 的 C/C++ 接口作为加速应用程序编程的入门知识,这些入门知识足以让你加速自己的 CPU 应用程序,以获得性能上的巨大提升并帮你迈入全新的计算领域。
1.2. 学习前的准备工作
如要充分利用本教程学习CUDA,那么你应该要先有如下知识储备:
- 在 C++/C 中声明变量、编写循环并使用 if/else 语句。
- 在 C++/C 中定义和调用函数。
- 在 C++/C 中分配数组。
说白了就是要有C或C++语言的基础,此外不需要事先知道任何关于 CUDA 的知识,当你在本教程完成学习后,你就可以做到:
- 编写、编译及运行既可调用 CPU 函数也可启动 GPU 核函数的 C/C++ 程序。
- 通过配置参数控制并行线程的层次结构。
- 重构串行循环以在 GPU 上并行执行其迭代。
- 分配和释放可用于 CPU 和 GPU 的内存。
- 处理 CUDA 代码产生的错误。
- 加速 CPU 应用程序。
1.3. 加速系统的硬件设施
带有GPU的计算机系统称为加速系统(又称异构系统,即指包含CPU和GPU的系统)。在一个包含 NVIDIA GPU 的加速系统的实验环境上,可以使用 nvidia-smi 命令查询有关此 GPU 的信息。例如:
nvidia-smi
按回车之后,将输出该机器上的GPU信息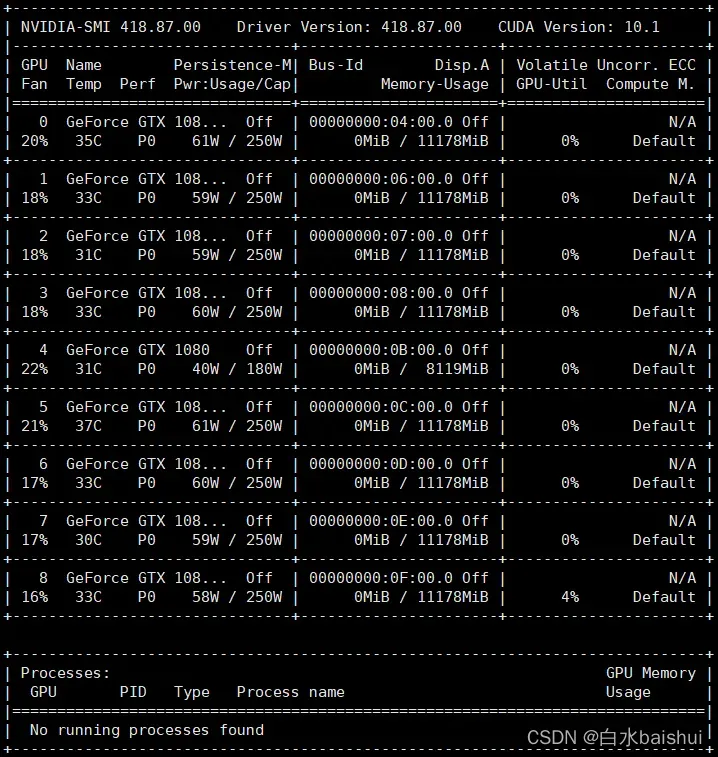
需要注意的是,加速系统在运行程序时首先会运行 CPU 程序,在运行到需要GPU进行大规模并行计算的函数时,再将对应函数载入GPU执行。
也就是说,由GPU加速的依然还是纯CPU的应用程序,只是某些模块在运行时调入了GPU中,该模块在同步完毕后将会重新回到CPU中执行主程序的后续代码:
2. 编写在GPU运行的代码
CUDA 为许多编程语言提供了扩展接口,而在本教程用CUDA为 C/C++ 提供的接口来展示。对编程语言的扩展可以让开发人员在 GPU 上更加方便的运行 CUDA 库的函数。
以下是一个.cu文件(.cu是 CUDA 加速程序的文件扩展名,实际上.cu文件只是含有CUDA代码的.cpp文件,没有别的特殊之处)。其中包含两个函数,第一个函数CPUFunction()将在 CPU 上运行,第二个函数GPUFunction()将在 GPU 上运行:
// 在CPU上运行的函数
void CPUFunction() {
printf("This function is defined to run on the CPU.\n");
}
// 在GPU上运行的函数
__global__ void GPUFunction() {
printf("This function is defined to run on the GPU.\n");
}
int main() {
CPUFunction(); // 调用CPU函数
GPUFunction<<<1, 1>>>(); // 调用GPU函数
cudaDeviceSynchronize(); // 同步
}
基于上面的代码,我们来看看一些需要特别注意的重要代码行,以及其他一些在加速计算中使用的常用术语:
__global__ void GPUFunction():
- __global__关键字表明该函数将在 GPU 上运行并可全局调用( 既可以由CPU ,也可以由 GPU 调用);
- 通常,我们将在 CPU 上执行的代码称为Host(主机)代码,而将在 GPU 上运行的代码称为Device(设备)代码;
- 注意返回类型为void。使用__global__关键字定义的函数返回值需为void类型。
GPUFunction<<<1, 1>>>():
- 通常,我们把要运行在 GPU 上的函数称为 kernel (核)函数;
- 启动核(kernel)函数时,我们必须事先配置GPU参数,使用<<< … >>>语法向核函数传递两个必要的参数;
- 在<<< … >>>中传递的参数用于为核函数设定线程的层次结构,第一个参数定义线程块(Block)的数量,第二个参数定义Block中含有的线程(Thread)数量。例如本例中的核函数GPUFunction()将在包含 1 个线程(第二个配置参数)的 1 个线程块(第一个执行配置参数)上运行。
cudaDeviceSynchronize():
- 与其他并行化的代码类似,核函数启动方式为异步,即 CPU 代码将继续执行而不会等待核函数执行完成;
- 调用 CUDA 提供的函数cudaDeviceSynchronize可以让Host 代码(CPU) 等待 Device 代码(GPU) 执行完毕,再在CPU上继续执行。
2.1. 编写运行一个 Hello GPU 核函数
#include <stdio.h>
void helloCPU() {
printf("Hello from the CPU.\n");
}
// __global__ 表明这是一个全局GPU核函数.
__global__ void helloGPU() {
printf("Hello from the GPU.\n");
}
int main() {
helloCPU(); // 调用CPU函数
/* 使用 <<<...>>> 配置核函数的GPU参数,
* 第一个1表示1个线程块,第二个1表示每个线程块1个线程。*/
helloGPU<<<1, 1>>>(); // 调用GPU函数
cudaDeviceSynchronize(); // `cudaDeviceSynchronize` 同步CPU和GPU
}
现在来编译并运行加速后的CUDA代码。将上述文件命名为hello-gpu.cu,执行命令:
nvcc hello-gpu.cu -o hello-gpu
./hello-gpu
得到了答案:
3. CUDA 线程的层次结构

从上面的图中可以看出,CUDA线程的层次结构分为三层:Thread(线程)、Block(块)、Grid(网格),网格由块组成,块由线程组成。
3.1. 运行核函数
我们可以通过配置参数指定核函数如何在 GPU 的多个线程中并行运行。具体来说,就可以配置 Block 的数量以及每个 Block 中所包含 Thread 的数量。配置参数的语法如下:
<<< Block 数, 每个Block中的 Thread 数>>>
启动核函数时,核函数代码由我们自行配置的 Block 中的每个 Thread 执行。因此,如果假设已定义一个名为someKernel的核函数,则GPU线程可以配置为下列情况:
- someKernel<<<1, 1>>()在GPU中为该核函数分配1个具有1个线程的线程块,核函数中的代码将只运行1次;
- someKernel<<<1, 10>>()在GPU中为该核函数分配1个具有10个线程的线程块,核函数中的代码将运行10次;
- someKernel<<<10, 1>>()在GPU中为该核函数分配10个具有1个线程的线程块,核函数中的代码将运行10次;
- someKernel<<<10, 10>>()在GPU中为该核函数分配10个具有10个线程的线程块,核函数中的代码将运行100次;
开始并行运行的内核函数示例:
#include <stdio.h>
__global__ void firstParallel() {
printf("This is running in parallel.\n");
}
int main() {
firstParallel<<<5, 5>>>(); // 在GPU中为核函数分配5个具有5个线程的线程块,将运行25次;
cudaDeviceSynchronize(); // 同步
}
将上述代码命名为basic-parallel.cu,然后编译运行:
nvcc basic-parallel.cu -o basic-parallel
./basic-parallel
结果如下,数了一下,确实是25次: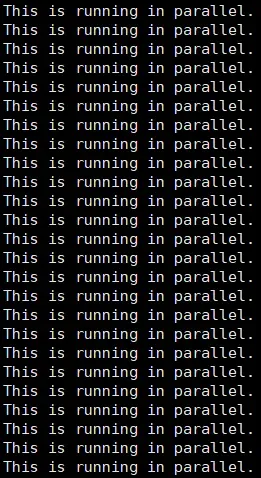
3.2. 线程和块的索引

如图所示,每个线程在其线程块的内部都会被分配一个索引,从 0 开始。此外,每个线程块也会被分配一个索引,也是从 0 开始。正如线程组成线程块,线程块又会组成网格(Grid),而网格是 CUDA 线程层次结构中级别最高的实体,它没有索引。
简言之,CUDA 核函数在由一个或多个线程块组成的网格中执行,且每个线程块中均包含相同数量的一个或多个线程(每个线程块中的线程数量相同)。
在核函数中,可以通过两个变量来获取到索引:threadIdx.x(线程索引)和blockIdx.x(线程块索引)。
现在让我们使用索引来控制特定的线程和块:
#include <stdio.h>
// 核函数
__global__ void printSuccessForCorrectExecutionConfiguration() {
// 当执行到第255个线程块的第1023个线程时,才输出
if(threadIdx.x == 1023 && blockIdx.x == 255) {
printf("Success!\n"); // 输出 Success!
printf("threadIdx.x: %d\n", threadIdx.x); // 输出线程ID
printf("blockIdx.x: %d\n", blockIdx.x); // 输出线程块ID
}
}
int main() {
// 配置该核函数由256个含有1024个线程的线程块中执行
printSuccessForCorrectExecutionConfiguration<<<256, 1024>>>();
cudaDeviceSynchronize(); // 同步
}
将上述代码命名为thread-and-block-idx.cu,然后编译运行:
nvcc thread-and-block-idx.cu -o thread-and-block-idx
./thread-and-block-idx
输出: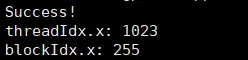
3.3. 用 CUDA 加速 For 循环
到此为止,加速 for 循环就是一个可行的操作了。在加速计算中,for 循环不再顺序执行每次迭代,而是让每次迭代都在不同的线程中并行执行。
例如,现在有以下在 CPU 中执行的 for 循环:
int N = 10;
for (int i = 0; i < N; ++i) {
printf("%d\n", i);
}
如要并行此循环,必须执行以下 2 个步骤:
- 编写一个执行单次工作迭代的核函数。
- 调用内核函数时,为其配置执行参数,即并行线程数,每个线程执行一次迭代。
以下示例程序:
#include <stdio.h>
// 核函数
__global__ void loop() {
// 输出每一个线程的线程号(0~9)
printf("This is iteration number %d\n", threadIdx.x);
}
int main() {
loop<<<1, 10>>>(); // 执行核函数
cudaDeviceSynchronize();
}
将上述代码命名为single-block-loop.cu,然后编译运行:
nvcc single-block-loop.cu -o single-block-loop
./single-block-loop
输出: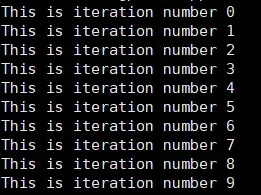
3.4. 管理不同块之间的线程
之前提到过,一个线程块可以包含多个线程,那么我们就可以调整线程块的大小以实现更多类型的并行化。线程块包含的线程具有数量限制:确切地说是1024个(即每个块中的线程数量 <= 1024)。通常为了增加加速应用程序中的并行量,我们需要利用多个线程块,并在它们之间进行协调。
CUDA 核函数中,记录了每个块中线程数的变量是blockDim.x(一个线程块中包含的线程数量,每个块中包含的线程数都是一样的)。通过将此变量与blockIdx.x和threadIdx.x变量结合使用,并借助表达式threadIdx.x + blockIdx.x * blockDim.x计算线程ID。该表达式可以用C++中访问二维数组的索引计算来类比看待,以增强理解。
下面是一个详细的例子:
配置参数<<<10, 10>>>将启动共计拥有 100 个线程的网格,该网格又分为由 10 个线程组成的 10 个线程块(即一个线程块中含有10个线程,blockDim.x=10)。这时候,就可以利用表达式threadIdx.x + blockIdx.x * blockDim.x来计算某个线程的唯一索引(0 至 99 之间)了。
- 如果线程块blockIdx.x索引为 0,则blockIdx.x * blockDim.x为 0。以 0 为起始索引加上可能的threadIdx.x值(0 至 9),便可在网格中找到索引为 0 至 9 的线程。
- 如果线程块blockIdx.x索引为 1,则blockIdx.x * blockDim.x为 10。以 10 为起始索引加上可能的threadIdx.x值(0 至 9),便可在网格中找到索引为 10 至 19 的线程。
- 如果线程块blockIdx.x索引为 5,则blockIdx.x * blockDim.x为 50。以 50 为起始索引加上可能的threadIdx.x值(0 至 9),便可在网格中找到索引为 50 至 59 的线程。
- 如果线程块blockIdx.x索引为 9,则blockIdx.x * blockDim.x为 90。以 90 为起始索引加上可能的threadIdx.x值(0 至 9),便可在网格中找到索引为 90 至 99 的线程。
现在我们来加速具有多个线程块的For循环:
#include <stdio.h>
__global__ void loop()
{
// 在Grid中遍历所有thread
int i = blockIdx.x * blockDim.x + threadIdx.x;
printf("%d\n", i);
}
int main()
{
/*
* 配置参数还可以试试其他的,例如:
* <<<5, 2>>>
* <<<10, 1>>>
*/
loop<<<2, 5>>>();
cudaDeviceSynchronize();
}
将上述代码命名为multi-block-loop.cu,然后编译运行:
nvcc multi-block-loop.cu -o multi-block-loop
./multi-block-loop
输出:
4. 分配可同时被GPU和CPU访问的内存
CUDA 的最新版本(版本 6 和更高版本)可以便捷地分配和释放既可用于 Host 也可被 Device 访问的内存。
在 Host(CPU)中,我们一般适用malloc和free来分配和释放内存,但这样分配的内存无法直接被Device(GPU)访问,所以在这里我们用cudaMallocManaged和cudaFree两个函数来分配和释放同时可被 Host 和 Device 访问的内存。如下例所示:
// CPU
int N = 10;
size_t size = N * sizeof(int);
int *a;
a = (int *)malloc(size); // 分配CPU内存
free(a); // 释放CPU内存
// GPU
int N = 10;
size_t size = N * sizeof(int);
int *a;
cudaMallocManaged(&a, size);// 为a分配CPU和GPU内存
cudaFree(a); // 释放GPU内存
实际上,cudaMallocManaged在统一内存中创建了一个托管内存池(CPU上有,GPU上也有),内存池中已分配的空间可以通过相同的指针直接被CPU和GPU访问,底层系统在统一的内存空间中自动地在设备和主机间进行传输。数据传输对应用来说是透明的,大大简化了代码。
现在让我们来看看如何利用GPU来执行数组元素的乘法操作:
#include <stdio.h>
// 初始化数组
void init(int *a, int N) {
int i;
for (i = 0; i < N; ++i) {
a[i] = i;
}
}
// CUDA 核函数,所有元素乘2
__global__ void doubleElements(int *a, int N) {
int i;
i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
a[i] *= 2;
}
}
// 检查数组内所有元素的值是否均为复数
bool checkElementsAreDoubled(int *a, int N) {
int i;
for (i = 0; i < N; ++i) {
if (a[i] != i*2) return false;
}
return true;
}
int main() {
int N = 1000;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size); // 为a分配CPU和GPU空间
init(a, N); // 为数组a赋值
size_t threads_per_block = 256; // 定义每个block的thread数量
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block; // 定义block的数量
doubleElements<<<number_of_blocks, threads_per_block>>>(a, N); // 执行核函数
cudaDeviceSynchronize(); // 同步
bool areDoubled = checkElementsAreDoubled(a, N); // 检查元素是否为复数
printf("All elements were doubled? %s\n", areDoubled ? "TRUE" : "FALSE");
cudaFree(a); // 释放由cudaMallocManaged
}
将上述代码命名为double-elements.cu,然后编译运行:
nvcc double-elements.cu -o double-elements
./double-elements
输出:
5. 网格大小与实际并行工作量不匹配

5.1. 网格大于工作量
鉴于 GPU 的硬件特性,线程块中的线程数最好配置为 32 的倍数。但是在实际工作中,很可能会出现这样的情况,我们手动配置参数所创建的线程数无法匹配为实现并行循环所需的线程数,比如实际上需要执行1230次循环,但是你却配置了2048个线程。
我们不可能每次配置参数的时候都手动去算一遍最佳配置,更何况并不是所有的数都是 32 的倍数。不过这个问题现在已经可以通过以下三个步骤轻松地解决:
- 首先,设置配置参数,使总线程数超过实际工作所需的线程数。
- 然后,在向核函数传递参数时传递一个用于表示要处理的数据集总大小或完成工作所需的总线程数 N。
- 最后,计算网格内的线程索引后(使用threadIdx + blockIdx*blockDim),判断该索引是否超过 N,只在不超过的情况下执行与核函数相关的工作。
以下是一种可选的配置方式,适用于 工作总量 N 和线程块中的线程数已知的情况。如此一来,便可确保网格中至少始终能执行 N 次任务,且最多只浪费 1 个线程块的线程数量:
// 假设N是已知的
int N = 100000;
// 把每个block中的thread数设为256
size_t threads_per_block = 256;
// 根据N和thread数量配置Block数量
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
some_kernel<<<number_of_blocks, threads_per_block>>>(N);
由于上述执行配置致使网格中的线程数超过 N,因此需要注意 some_kernel 定义中的内容,以确保 some_kernel 在由其中一个额外的(大于N的)线程执行时不会尝试访问超出范围的数据元素,也就是要加个判断:
__global__ some_kernel(int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) { // 保证线程ID小于元素数量N
// 并行代码
}
使用不匹配的配置参数来加速 For 循环
#include <stdio.h>
__global__ void initializeElementsTo(int initialValue, int *a, int N) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
if (i < N) {
a[i] = initialValue;
}
}
int main() {
int N = 1000;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size);
size_t threads_per_block = 256;
// 这是惯用的CUDA语法
// 为 number_of_blocks 分配一个值,以确保线程数至少与指针 a 中可供访问的元素数同样多。
size_t number_of_blocks = (N + threads_per_block - 1) / threads_per_block;
int initialValue = 6; // 初始化的值
initializeElementsTo<<<number_of_blocks, threads_per_block>>>(initialValue, a, N);
cudaDeviceSynchronize();
// 检查元素值是否被初始化
for (int i = 0; i < N; ++i) {
if(a[i] != initialValue) {
printf("FAILURE: target value: %d\t a[%d]: %d\n", initialValue, i, a[i]);
exit(1);
}
}
printf("SUCCESS!\n");
cudaFree(a);
}
将上述代码命名为mismatched-config-loop.cu,然后编译运行:
nvcc mismatched-config-loop.cu -o mismatched-config-loop
./mismatched-config-loop
输出:
5.2. 网格小于工作量

有时,工作量比网格大,或者出于某种原因,一个网格中的线程数量可能会小于实际工作量的大小。请思考一下包含 1000 个元素的数组和包含 250 个线程的网格(此处使用极小的规模以便于说明)。此网格中的每个线程将需使用 4 次。如要实现此操作,一种常用方法便是在核函数中使用跨网格循环。
在跨网格循环中,每个线程将在网格内使用threadIdx + blockIdx*blockDim计算自身唯一的索引,并对数组内该索引的元素执行相应运算,然后用网格中的线程数加上自身索引值,并重复此操作,直至超出数组范围。
例如,对于包含 500 个元素的数组a和包含 250 个线程的网格,网格中索引为 20 的线程将执行如下操作:
- 对a[20]执行相应运算;
- 将线程索引增加 250,使网格的大小达到 270
- 对a[270]执行相应运算;
- 将线程索引增加 250,使网格的大小达到 520
- 由于 520 现已超出数组范围,因此线程将停止工作。
CUDA 提供一个记录了网格中线程块数的变量:gridDim.x。然后可以利用它来计算网格中的总线程数,即网格中的线程块数乘以每个线程块中的线程数:gridDim.x * blockDim.x。现在来看看以下核函数中网格跨度循环的示例:
__global void kernel(int *a, int N)
{
int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;
int gridStride = gridDim.x * blockDim.x; // grid 的一个跨步
for (int i = indexWithinTheGrid; i < N; i += gridStride) {
// 对 a[i] 的操作;
}
}
上面是一个简单的例子,现在让我们看一个更详细的例子,它使用跨越网格的循环来处理大于网格的数组:
#include <stdio.h>
// 初始化数组a
void init(int *a, int N) {
int i;
for (i = 0; i < N; ++i) {
a[i] = i;
}
}
__global__ void doubleElements(int *a, int N) {
// 使用grid-stride循环,这样每个线程可以处理数组中的多个元素。
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x; // grid 的一个跨步
for (int i = idx; i < N; i += stride) {
a[i] *= 2;
}
}
// 检查数组内所有元素的值是否均为复数
bool checkElementsAreDoubled(int *a, int N) {
int i;
for (i = 0; i < N; ++i) {
if (a[i] != i*2) return false;
}
return true;
}
int main() {
int N = 10000;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size);
init(a, N); // 初始化数组a
size_t threads_per_block = 256; // 每个block的thread数量
size_t number_of_blocks = 32; // block数量
doubleElements<<<number_of_blocks, threads_per_block>>>(a, N);
cudaDeviceSynchronize();
bool areDoubled = checkElementsAreDoubled(a, N);
// 检查数组内所有元素的值是否均为复数
printf("All elements were doubled? %s\n", areDoubled ? "TRUE" : "FALSE");
cudaFree(a);
}
将上述代码命名为grid-stride-double.cu,然后编译运行:
nvcc grid-stride-double.cu -o grid-stride-double
./grid-stride-double
输出:
6. 错误处理
CUDA 函数发生错误时会返回一个类型为cudaError_t的变量,该变量可用于检查调用函数时是否发生错误。以下是对调用cudaMallocManaged函数执行错误处理的示例:
cudaError_t err;
err = cudaMallocManaged(&a, N) // 假设a和N已经被定义
if (err != cudaSuccess) { // `cudaSuccess` 是一个 CUDA 变量.
printf("Error: %s\n", cudaGetErrorString(err)); // `cudaGetErrorString` 是一个 CUDA 函数.
}
但是,核函数并不会返回类型为cudaError_t的值(因为核函数的返回值为void)。为检查执行核函数时是否发生错误(例如配置错误),CUDA 提供了cudaGetLastError函数,可以用于检查核函数执行期间发生的错误。
// 这段程序中的核函数会出一个CUDA错误,但是核函数本身无法捕获该错误
someKernel<<<1, -1>>>(); // 线程数不能为-1
cudaError_t err;
err = cudaGetLastError(); // `cudaGetLastError` 会捕获上面代码中的最近的一个错误
if (err != cudaSuccess) {
printf("Error: %s\n", cudaGetErrorString(err));
}
另一个要注意的点是,为了捕捉在异步核函数执行期间发生的错误,一定要检查后续同步 CPU 与 GPU 时 API 调用所返回的状态(例如cudaDeviceSynchronize);如果之前执行的某一个核函数失败了,则将会返回错误。
添加了错误处理的示例:
#include <stdio.h>
// 初始化数组a
void init(int *a, int N) {
int i;
for (i = 0; i < N; ++i) {
a[i] = i;
}
}
// CUDA 核函数 数组元素值乘2
__global__ void doubleElements(int *a, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gridDim.x * blockDim.x;
// for (int i = idx; i < N; i += stride) {
// 这里出现一个数值越界错误
for (int i = idx; i < N + stride; i += stride) {
a[i] *= 2;
}
}
// 检查数组元素是否均为复数
bool checkElementsAreDoubled(int *a, int N) {
int i;
for (i = 0; i < N; ++i) {
if (a[i] != i*2) return false;
}
return true;
}
int main() {
int N = 10000;
int *a;
size_t size = N * sizeof(int);
cudaMallocManaged(&a, size);
init(a, N);
cudaError_t syncErr, asyncErr; // 定义错误处理变量
// size_t threads_per_block = 1024;
// 线程数大于1024(前面说过每个block的线程数不能超过1024)
size_t threads_per_block = 2048;
size_t number_of_blocks = 32;
doubleElements<<<number_of_blocks, threads_per_block>>>(a, N); // 执行核函数
syncErr = cudaGetLastError(); // 捕获核函数执行期间发生的错误
asyncErr = cudaDeviceSynchronize(); // 同步,并捕获同步期间发生的错误
// 输出错误 说明:两个错误需分别设置(即每次运行时只保留一个错误)
if (syncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(syncErr));
if (asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
bool areDoubled = checkElementsAreDoubled(a, N); // 验证数组元素值是否均为复数
printf("All elements were doubled? %s\n", areDoubled ? "TRUE" : "FALSE");
cudaFree(a);
}
将上述代码命名为add-error-handling.cu,然后编译运行:
nvcc add-error-handling.cu -o add-error-handling
./add-error-handling
输出:
6.1. 定制一个 CUDA 错误处理宏
创建一个包装 CUDA 函数调用的宏对于检查错误十分有用。以下是一个宏示例,我们可以在其他的 CUDA 代码中随时使用:
#include <stdio.h>
#include <assert.h>
// CUDA 错误处理宏
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
int main() {
// checkCuda 宏可以返回 CUDA 函数返回的错误类型`cudaError_t`的值
checkCuda( cudaDeviceSynchronize() )
}
7. 总结
至此,我们已经完成了预期的学习目标:
- 编写、编译及运行既可调用 CPU 函数也可启动GPU核函数的 C/C++ 程序。
- 使用执行配置来控制并行线程层次结构。
- 重构串行循环以在 GPU 上并行执行其迭代。
- 分配和释放可用于 CPU 和 GPU 的内存。
- 处理 CUDA 代码生成的错误。
现在,加速 CPU 应用程序进行是可行的了。
7.1 用 CUDA 实现向量加法
为了展示如何结合本教程中提到的内容,让我们通过一个向量和向量加点的案例来使用上面的知识:
#include <stdio.h>
#include <assert.h>
// CUDA 错误处理宏
inline cudaError_t checkCuda(cudaError_t result)
{
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
// 初始化数组 a
void initWith(float num, float *a, int N) {
for(int i = 0; i < N; ++i) {
a[i] = num;
}
}
// 向量加法核函数
__global__ void addVectorsInto(float *result, float *a, float *b, int N) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride) {
result[i] = a[i] + b[i]; // 元素a[i] + 元素 b[i]
}
}
// 检查 CUDA 向量加分是否计算正确
void checkElementsAre(float target, float *array, int N) {
for(int i = 0; i < N; i++) {
if(array[i] != target) {
printf("FAIL: array[%d] - %0.0f does not equal %0.0f\n", i, array[i], target);
exit(1);
}
}
printf("SUCCESS! All values added correctly.\n");
}
int main() {
const int N = 10;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
// 分配内存,且检查执行期间发生的错误
checkCuda( cudaMallocManaged(&a, size) );
checkCuda( cudaMallocManaged(&b, size) );
checkCuda( cudaMallocManaged(&c, size) );
initWith(3, a, N); // 将数组a中所有的元素初始化为3
initWith(4, b, N); // 将数组b中所有的元素初始化为4
initWith(0, c, N); // 将数组c中所有的元素初始化为0,数组c是结果向量
// 配置参数
size_t threadsPerBlock = 256;
size_t numberOfBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N); // 执行核函数
checkCuda( cudaGetLastError() ); // 检查核函数执行期间发生的错误
checkCuda( cudaDeviceSynchronize() ); // 同步,且检查执行期间发生的错误
checkElementsAre(7, c, N); // 检查向量加的结果是否正确
// 释放内存,且检查执行期间发生的错误
checkCuda( cudaFree(a) );
checkCuda( cudaFree(b) );
checkCuda( cudaFree(c) );
}
7.2. 二维和三维的网格和块
网格和线程块最多可以定义有 3 个维度,使用多个维度定义网格和线程块在处理具有多个维度的数据时可能很有效,例如二维矩阵。如果要定义二维或三维的网格或线程块,可以使用 CUDA 的dim3关键字来定义多维网格或块,即如下所示:
dim3 threads_per_block(16, 16, 1);
dim3 number_of_blocks(16, 16, 1);
someKernel<<<number_of_blocks, threads_per_block>>>();
鉴于以上示例,someKernel 内部的变量 gridDim.x、gridDim.y、blockDim.x 和 blockDim.y 均将等于 16。
7.3 用 CUDA 实现矩阵乘法
#include <stdio.h>
#define N 64
// GPU 矩阵乘法
__global__ void matrixMulGPU( int * a, int * b, int * c ) {
int val = 0;
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
if (row < N && col < N) {
for ( int k = 0; k < N; ++k )
val += a[row * N + k] * b[k * N + col];
c[row * N + col] = val;
}
}
// CPU矩阵乘法
void matrixMulCPU( int * a, int * b, int * c ) {
int val = 0;
for( int row = 0; row < N; ++row )
for( int col = 0; col < N; ++col ) {
val = 0;
for ( int k = 0; k < N; ++k )
val += a[row * N + k] * b[k * N + col];
c[row * N + col] = val;
}
}
int main() {
int *a, *b, *c_cpu, *c_gpu;
int size = N * N * sizeof (int); // Number of bytes of an N x N matrix
// 分配内存
cudaMallocManaged (&a, size);
cudaMallocManaged (&b, size);
cudaMallocManaged (&c_cpu, size);
cudaMallocManaged (&c_gpu, size);
// 初始化数组
for( int row = 0; row < N; ++row )
for( int col = 0; col < N; ++col )
{
a[row * N + col] = row;
b[row * N + col] = col + 2;
c_cpu[row * N + col] = 0;
c_gpu[row * N + col] = 0;
}
dim3 threads_per_block (16, 16, 1); // 一个 16 * 16 的线程阵
dim3 number_of_blocks ((N / threads_per_block.x) + 1, (N / threads_per_block.y) + 1, 1);
matrixMulGPU <<< number_of_blocks, threads_per_block >>> ( a, b, c_gpu ); // 执行核函数
cudaDeviceSynchronize(); // 同步
matrixMulCPU( a, b, c_cpu ); // 执行 CPU 版本的矩阵乘法
// 比较 CPU 和 GPU 两种方法的计算结果是否一致
bool error = false;
for( int row = 0; row < N && !error; ++row )
for( int col = 0; col < N && !error; ++col )
if (c_cpu[row * N + col] != c_gpu[row * N + col]) {
printf("FOUND ERROR at c[%d][%d]\n", row, col);
error = true;
break;
}
if (!error)
printf("Success!\n");
// 释放内存
cudaFree(a); cudaFree(b);
cudaFree( c_cpu ); cudaFree( c_gpu );
}
版权声明:本文为博主白水baishui原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/baishuiniyaonulia/article/details/123023666