我一直不明白为什么要在神经网络中引入非线性激活函数(虽然我明白为什么只有线性是不够的,但我不明白为什么有非线性就足够了,不知道有没有像我这样的朋友),最近重温《李宏毅》在深度学习时恍然大悟。
参考视频:【機器學習2021】預測本頻道觀看人數 (下) – 深度學習基本概念簡介:大约看前10分钟就可以明白
如果不方便看飞机上的同学,可以看下面我的安排
为什么神经网络只是线性的?
众所周知,机器学习的过程是:首先假设一个函数,然后通过训练样本学习函数
的参数。
假设我们现在想使用神经网络来模拟一个函数,如下所示:
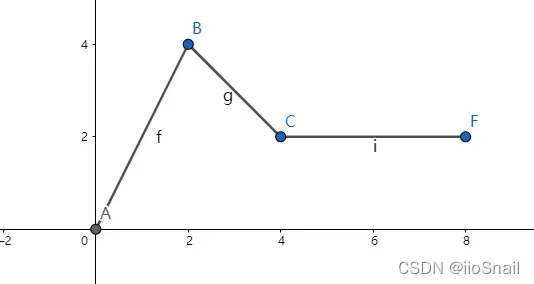
这是一个分段函数:
假设要模拟上述函数,设计如下神经网络: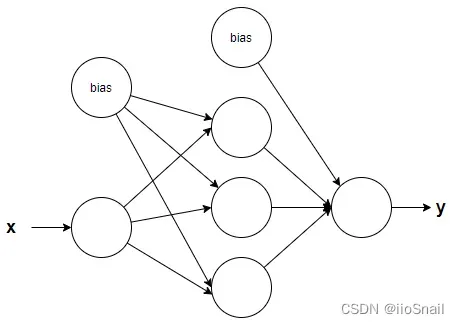
假设神经网络的隐藏层没有激活函数,那么这个神经网络的本质是什么?
首先,从输入层到隐藏层,其实有3条直线,假设:
那么隐藏层到输出层呢?其实就是加上上面三行,即:
那我们现在尝试绘制3条直线,看看加起来能不能模拟上述的分段函数:
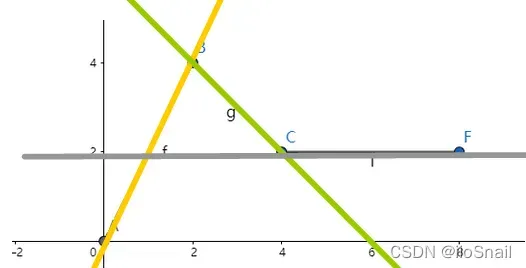
这里我随便绘制了3条线,如果将这3条线加起来是什么样子呢?其实还是一条直线。这个从公式很容易看出:
因此,如果神经网络只是线性的,那么无论有多少隐藏层,有多少个神经元,最终都是线性的。
为了让神经网络模拟复杂的函数(非线性),需要给神经元引入非线性激活函数。
为什么会有非线性
要回答这个问题,可以继续上面的例子,假设要拟合上面的分段函数,可以使用以下函数进行添加:
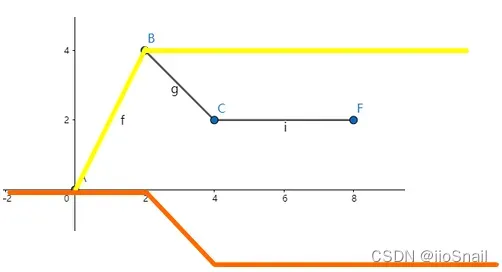
如果神经网络能模拟出黄色线和橙色线,那么让其相加,就可以得出函数。你看这两个线的长相有没有很熟悉。没错,就是sigmoid。
任何复杂的函数都可以由一个常量加一堆sigmoid函数模拟出来
下面,使用sigmoid来模拟一下该函数,即如图所示:
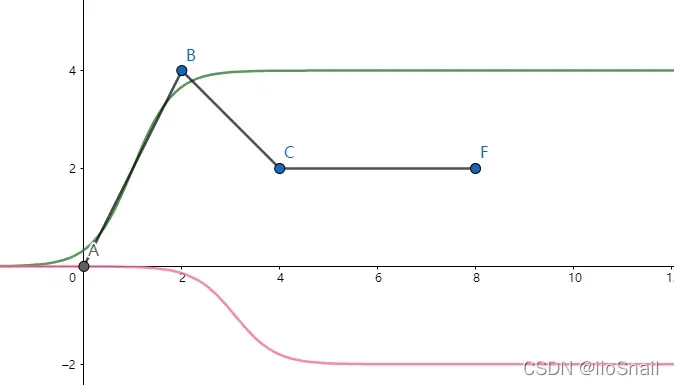
我们可以通过绿色函数和红色函数
大致模拟函数
,其中:
那么如果对应神经网络,每条线的权重如图:
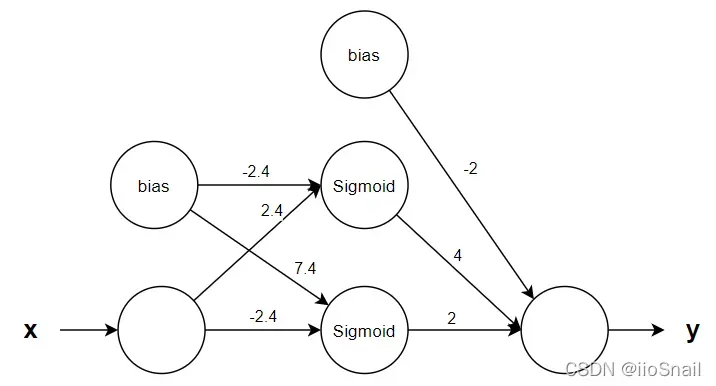
这里只用一个隐层两个神经元,因为已经足够了,如果实战时隐层设置了3个神经元,也没关系,因为神经网络会将其中一个神经元的参数都学习成0,这样相当于第三个神经元有和没有一样
这次在隐藏层增加了非线性函数sigmoid,则整个神经网络的运算过程为:
激活后的函数为:
然后到最后一个输出层:
这不就是最终的结论嘛,通过神经网络,模拟出了两条非线性的sigmoid函数,然后将其合并(相加),最终模拟出函数。
更复杂的功能呢? ,例如:
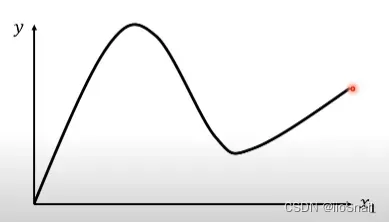
没关系,只需在图表上标记一些点,然后按照这些点进行模拟:
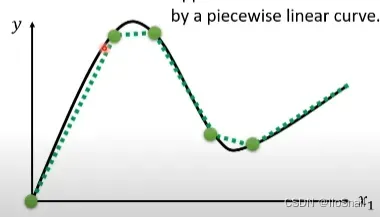
如果对应一个神经网络,就是做更多的隐藏层和神经元。
如果是Tanh,ReLU呢?也无非是对其进行各种变换,最后相加起来能得出要模拟的函数即可
版权声明:本文为博主iioSnail原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/zhaohongfei_358/article/details/123056206