英特尔OpenVINO工具套件高级课程&实验操作记录与学习总结
第一课动手实验:如何充分使用OpenVINO™工具套件?-在线测试
1.人体动作姿势识别示例
设置实验路径
设定OpenVINO的路径:
export OV=/opt/intel/openvino_2021/
设置当前实验的路径:
export WD=~/OV-300/01/3D_Human_pose/
注:实验文件夹名为OV-300,位于主目录下。本环境下,文件的上传与下载方法,参考右上角帮助手册。
运行初始化OpenVINO的脚本
source $OV/bin/setupvars.sh
当你看到:[setupvars.sh] OpenVINO environment initialized 表示OpenVINO环境已经成功初始化。
运行OpenVINO依赖脚本的安装
进入脚本目录:
cd $OV/deployment_tools/model_optimizer/install_prerequisites/
安装OpenVINO需要的依赖:
sudo ./install_prerequisites.sh
PS:此步骤为模拟开发机本地进行OpenVINO使用的步骤,所以 之后你在本地使用OpenVINO之前需要遵循此步骤。
安装OpenVINO模型下载器的依赖文件
转到模型下载器的文件夹:
cd $OV/deployment_tools/tools/model_downloader/
安装模型下载器的依赖:
python3 -mpip install –user -r ./requirements.in
安装下载转换pytorch模型的依赖:
sudo python3 -mpip install –user -r ./requirements-pytorch.in
安装下载转换caffe2模型的依赖:
sudo python3 -mpip install –user -r ./requirements-caffe2.in
PS:此步骤为模拟开发机本地进行OpenVINO使用的步骤,所以 之后你在本地使用OpenVINO之前需要遵循此步骤。
通过模型下载器下载人体姿态识别模型
正式进入实验目录:
cd $WD
查看human_pose_estimation_3d_demo需要的模型列表:
cat /opt/intel/openvino_2021//deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
通过模型下载器下载模型:
python3 $OV/deployment_tools/tools/model_downloader/downloader.py –list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst -o $WD
使用模型转换器把模型转换成IR格式
OpenVINO支持把市面上主流的框架比如TensorFlow/Pytorch->ONNX/CAFFE等框架构建好的模型转换为IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py –list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
PS:目前OpenVINO的推理引擎只能够推理经过转换完成的IR文件,无法直接推理.pb/.caffemode/.pt等文件。
编译OpenVINO的Python API
只需要编译一次:
source $OV/inference_engine/demos/build_demos.sh -DENABLE_PYTHON=ON
若你需要使用OpenVINO的PythonAPI,请加入如下编译出来的库地址(否则会找不到库):
export PYTHONPATH=”$PYTHONPATH:/home/dc2-user/omz_demos_build/intel64/Release/lib/”
播放待识别的实验视频
由于网页播放器的限制,请手动输入以下命令播放视频:
show 3d_dancing.mp4
PS:请务必使用键盘逐字母进行输入
运行人体姿势识别Demo
运行人体姿势识别Demo:
python3 $OV/inference_engine/demos/human_pose_estimation_3d_demo/python/human_pose_estimation_3d_demo.py -m $WD/public/human-pose-estimation-3d-0001/FP16/human-pose-estimation-3d-0001.xml -i 3d_dancing.mp4 –no_show -o output.avi
请耐心等待程序运行完成,若屏幕出现Inference Completed!! 则表示推理完成,请输入“ls”罗列当前文件夹的所有文件
转换并播放识别结果视频
由于平台限制,我们必须先将输出结果视频转换为MP4格式,使用如下命令:
ffmpeg -i output.avi output.mp4
手动输入以下命令播放推理结果视频:
show output.mp4
2.图像着色示例
设置实验路径
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Colorization/
初始化OpenVINO
source $OV/bin/setupvars.sh
开始实验
正式进入工作目录:
cd $WD
查看该demo的所需模型:
cat $OV/deployment_tools/inference_engine/demos/colorization_demo/python/models.lst
由于实验模型体积较大,模型已经提前下载,请继续下一步。
查看原始视频
所有show命令都请手动输入:
show butterfly.mp4
运行着色Demo
python3 $OV/inference_engine/demos/colorization_demo/python/colorization_demo.py -m $WD/public/colorization-siggraph/colorization-siggraph.onnx -i butterfly.mp4 –no_show -o output.avi
PS:细心的同学会发现,这个实验中可以直接使用onnx格式进行实验,这说明推理引擎是支持简单的onnx进行推理(当然你转换为IR也可以)。请耐心等待程序运行完成,你将会看到“Inference Completed”的字样。输出avi将保存于当前文件夹,使用小写“LL”命令查看当前文件夹。
查看着色实验的输出视频
请先使用ffmpeg将.avi转换为.mp4格式:
ffmpeg -i output.avi output.mp4
手动输入指令播放视频:
show output.mp4
PS:若转换完成使用show命令无法显示,请稍后30s再试。
3.音频检测示例
初始化环境
#初始化工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Audio-Detection/
#初始OpenVINO
source $OV/bin/setupvars.sh
进入音频检测目录
#进入OpenVINO中自带的音频检测示例:
cd $OV/data_processing/dl_streamer/samples/gst_launch/audio_detect
#可以查看检测到的标签文件
vi ./model_proc/aclnet.json
#您也可以播放音频文件以供稍后检测
show how_are_you_doing.mp3
运行音频检测
# 运行示例
bash audio_event_detection.sh
分析音频检测结果
# 结果不是很适合观察,可以运行以下命令
bash audio_event_detection.sh | grep “label”:” |sed ‘s/.*label”//’ | sed ‘s/”label_id.start_timestamp”😕/’ | sed ‘s/}].//’
#现在你可以看到在时间戳600000000的时候,我们检测到语音了,但并不知道内容是什么,因为它知识一个检测示例,并不是一个识别示例:“Speech”,600000000
4.公式识别
初始化环境
#初始化环境
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Formula_recognition/
#初始化OpenVINO
source $OV/bin/setupvars.sh
查看可识别的字符
cd $WD
#手写字符:
vi hand.json
#打印字符:
vi latex.json
查看要识别的公式
# 进入材料目录
cd $WD/…/Materials/
#查看打印公式
show Latex-formula.png
#查看手写公式
show Hand-formula.png
运行公式识别
cd $WD
#识别打印公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-encoder/FP16/formula-recognition-medium-scan-0001-im2latex-encoder.xml -m_decoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/FP16/formula-recognition-medium-scan-0001-im2latex-decoder.xml –vocab_path latex.json -i $WD/…/Materials/Latex-formula.png -no_show
识别手写公式
# 识别手写公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-encoder/FP16/formula-recognition-polynomials-handwritten-0001-encoder.xml -m_decoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-decoder/FP16/formula-recognition-polynomials-handwritten-0001-decoder.xml –vocab_path hand.json -i $WD/…/Materials/Hand-formula.png -no_show
挑战任务
#可上传自己的手写公式,保存为PNG格式来示例进行识别
#上传文件的方法位于页面右上角的帮助手册
#如果你想跳过这个任务,直接点击OK
5.环境深度识别
初始化环境
#环境目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/MonoDepth_Python/
#初始化OpenVINO
source $OV/bin/setupvars.sh
转换原始模型文件为IR文件
进入工作目录
cd $WD
#下载好的模型为TensorFlow格式,使用converter准换为IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py –list $OV/deployment_tools/inference_engine/demos/monodepth_demo/python/models.lst
查看需要识别的原图
#查看原始文件
show tree.jpeg
运行深度识别示例
# 进入工作目录
cd $WD
运行示例,自动分离出图像中景深不同的地方:
python3 $OV/inference_engine/demos/monodepth_demo/python/monodepth_demo.py -m $WD/public/midasnet/FP32/midasnet.xml -i tree.jpeg
#查看显示结果
show disp.png
6.目标识别示例
初始化环境
#定义OpenVINO 目录
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/01/Object_Detection/
#初始化OpenVINO
source $OV/bin/setupvars.sh
# 进入工作目录
cd $WD
选择适合您的型号
#由于支持目标检测的模型很多,可以在不同的拓扑网络下选择合适的模型:
vi $OV/inference_engine/demos/object_detection_demo/python/models.lst
注:关于SSD, Yolo, centernet, faceboxes or Retina拓扑网络的区别,本课程不会继续深入,有兴趣的同学可以自行上网了解。在OpenVINO中的deployment_tools/inference_engine/demos/的各个demo文件夹中都有model.lst列出了该demo支持的可直接通过downloader下载使用的模型
转换模型至IR格式
#本实验已经事先下完成:pedestrian-and-vehicle-detector-adas 与 yolo-v3-tf
#使用Converter进行IR转换,由于pedestrian-and-vehicle-detector-adas 为英特尔预训练模型,已经转换IR完成,只需要对yolo-v3进行转换:
python3 $OV/deployment_tools/tools/model_downloader/converter.py –name yolo-v3-tf
查看要检测的视频
cd $WD/…/Materials/Road.mp4
#播放视频:
show Road.mp4
使用SSD模型运行目标检测示例
cd $WD
#运行 OMZ (ssd) model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/intel/pedestrian-and-vehicle-detector-adas-0001/FP16/pedestrian-and-vehicle-detector-adas-0001.xml –architecture_type ssd -i $WD/…/Materials/Road.mp4 –no_show -o $WD/output_ssd.avi
#转换为mp4格式进行播放
ffmpeg -i output_ssd.avi output_ssd.mp4
show output_ssd.mp4
运行Yolo-V3下的目标检测示例
#运行 the Yolo V3 model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/public/yolo-v3-tf/FP16/yolo-v3-tf.xml -i $WD/…/Materials/Road.mp4 –architecture_type yolo –no_show -o $WD/output_yolo.avi
#转换为mp4格式进行播放
ffmpeg -i output_yolo.avi output_yolo.mp4
show output_yolo.mp4
!请比较两个模型在相同代码下的检测性能
7.自然语言处理示例(NLP)——自动回答问题
初始化环境
#定义工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/NLP-Bert/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#进入目录
cd $WD
查看支持的型号列表
#可用列表:
cat $OV/deployment_tools/inference_engine/demos/bert_question_answering_demo/python/models.lst
注:在OpenVINO中的deployment_tools/inference_engine/demos/的各个demo文件夹中都有model.lst列出了该demo支持的可直接通过downloader下载使用的模型,且我们已经事先下载好全部模型为IR格式。
打开要识别的网址
#使用浏览器打开一个英文网址进行浏览,例如Intel官网:https://www.intel.com/content/www/us/en/homepage.html
运行NLP示例
python3 $OV/inference_engine/demos/bert_question_answering_demo/python/bert_question_answering_demo.py -m $WD/intel/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.xml -v $OV/deployment_tools/open_model_zoo/models/intel/bert-small-uncased-whole-word-masking-squad-0001/vocab.txt –input=https://www.intel.com/content/www/us/en/homepage.html –input_names=input_ids,attention_mask,token_type_ids –output_names=output_s,output_e
#在Type question (empty string to exit): 输入core。即可查看当前对于core(酷睿)的可知信息,例如: Intel® Core™ processors provide a range of performance from entry-level to the highest level 。当然你也可以输入别的问题。对比网站上的相关描述
注:–input=https://www.intel.com/content/www/us/en/homepage.html 为我们需要访问的英文网站
挑战任务
#在上一个步骤的实验基础上,尝试使用不同的网址作为–input 的输入,并尝试提出一些别的关键词问题。并思考如何能够提升这个示例的准确性。
#在上一个步骤的实验基础上,尝试使用不同的模型作为-m/-v 的输入(模型位于$WD/INTEL/目录下),并尝试提出一些别的关键词问题。并思考如何能够提升这个示例的准确性。
注意:本例只支持英文网站,网站可以正常访问。
第 2 课动手实验:如何构建异构系统 – 动手实验 – 在线测试
1.上传性能评估脚本到DevCloud
初始实验路径
#定义OpenVINO 文件夹
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/02/LAB1/
#初始化OpenVINO
source $OV/bin/setupvars.sh
# 进入实验目录
cd $WD
查看当前设备信息
通过OpenVINO自带脚本可以查询当前环境的设备信息:
python3 $OV/inference_engine/samples/python/hello_query_device/hello_query_device.py
DevCloud 介绍
英特尔® DevCloud 提供对各种英特尔® 架构CPU/GPU/NCS2/智能硬件等设备的免费访问,帮助您获得英特尔® 软件的即时动手体验,并执行您的边缘、人工智能、高性能计算 (HPC) 和渲染工作负载。借助预装的英特尔® 优化框架、工具(OpenVINO Toolkit, OneAPI)和库,您拥有快速跟踪学习和项目原型制作所需的一切。
本次实验提供了4个可用节点:
idc004nc2: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
idc007xv5: Intel – xeon e3-1268l-v5, intel-hd-p530
idc008u2g: Intel – atom e3950, intel-hd-505,myriad-1-VPU
idc014:Intel – i7 8665ue, intel-uhd-620
注:NCS2中文名为第二代神经计算棒,是英特尔公司推出的边缘计算设备,体积和U盘相似,接口为USB3.0,内置Myriad X计算芯片,功耗仅为2W,理论算力可达1TOPS。OpenVINO可以通过“MYRIAD”的插件将深度学习模型部署在上面。
上传Benchmark_App.py至DevCloud中运行
我们将需要运行的代码提交至idc004nc2节点中执行:
python3 submit_job_to_DevCloud.pyc idc004nc2
PS:因为有一定的网络延迟,若命令无反应,可重复尝试几次该命令。
请耐心等待实验状态成为“C”,脚本执行完成,上传的脚本位于当前文件目录下,名为userscript.py, 其功能是将OpenVINO的人脸识别模型运行在NCS2上以得到性能参数。
比较不同CPU下NCS2的性能
根据刚才上传的指令,将同样的代码上传至idc008u2g节点。
上传命令为:
python3 submit_job_to_DevCloud.pyc “目标节点名称”
PS:该指令默认上传当前目录下的userscript.py脚本。
请对比不同CPU(Atom和 Core)的条件下,NCS2的性能是否有差异?
idc004nc2: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
执行命令:python3 submit_job_to_DevCloud.pyc idc004nc2
[Step 11/11] Dumping statistics report
Count: 260 iterations
Duration: 10297.15 ms
Latency: 158.08 ms
Throughput: 25.25 FPS
idc008u2g: Intel – atom e3950, intel-hd-505,myriad-1-VPU
执行命令:python3 submit_job_to_DevCloud.pyc idc008u2g
[Step 11/11] Dumping statistics report
Count: 260 iterations
Duration: 10294.75 ms
Latency: 157.99 ms
Throughput: 25.26 FPS
挑战任务1:将推理任务部署在节点的不同推理设备上
修改userscript.py:
vi userscript.py
在第43行: target_device= “MYRIAD”
注:可使用“:wq”指令保存更改并退出该界面。
你可以在这里选择你想要运行的设备:”CPU/GPU/MYRIAD”
CPU:对应 英特尔中央处理器
GPU:对应 英特尔集成显卡
MYRIAD:这个名称对应的设备是刚才提到的NCS2
这里你可以自行发挥,尝试使用不同的设备 或者Devcloud节点运行这个性能测试脚本
设备:GPU
Devcloud节点:idc007xv5: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
执行命令:python3 submit_job_to_DevCloud.pyc idc007xv5
[Step 11/11] Dumping statistics report
Count: 724 iterations
Duration: 10031.90 ms
Latency: 27.45 ms
Throughput: 72.17 FPS
设备:CPU
Devcloud节点:idc007xv5: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
执行命令:python3 submit_job_to_DevCloud.pyc idc007xv5
[Step 11/11] Dumping statistics report
Count: 920 iterations
Duration: 10015.39 ms
Latency: 10.82 ms
Throughput: 91.86 FPS
target_device= “MYRIAD”
设备:MYRIAD
Devcloud节点:idc007xv5: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
执行命令:python3 submit_job_to_DevCloud.pyc idc007xv5
2022年 02月 21日 星期一 06:17:38 CST,设备:MYRIAD,运行脚本报错 RuntimeError: Can not init Myriad device: NC_ERROR。
2022年 02月 21日 星期一 03:56:50 CST,网页shell卡死失效,无法保存退出(:wq),无执行结果。2022年 02月 21日 星期一 05:55:18 CST,ok处理好了,不是卡死是命令在web shell上无效,改用 ctrl+[ 退出INSERT模式就ok了。
挑战任务2:打印出NCS2的工作温度
请根据:hello_query_device.py 代码中的关于温度显示的片段,更改userscript.py,使之可以显示当前NCS2的工作温度。
请在userscript.py的 line:136 后 添加适当的代码,来显示当前NCS2的温度。
提示:请在确保target_device为“MYRIAD”的前提下,使用函数:self.ie.get_metric(metric_name=“DEVICE_THERMAL”,device_name=‘MYRIAD’ ) 获取温度。
答案userscript…py 位于上一级目录的Solution文件夹中,你可以复制到当前文件夹进行使用。
2022年 02月 21日 星期一 04:03:53 CST,这个有难度,先跳过。
2.利用多硬件协同推理
初始化实验目录
#定义OV目录
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/02/LAB2/
#初始化OpenVINO
source $OV/bin/setupvars.sh
# 进入工作目录
cd $WD
不同型号的性能测试
我们为您准备了三种型号:
face-detection-adas-0001.xml
head-pose-estimation-adas-0001.xml
text-spotting-0003-recognizer-encoder.xml
请对userscript.py进行编辑:
在line 44: path_to_model=”/app/face-detection-adas-0001.xml” 中对 face-detection-adas-0001.xml 进行替换,即可测试不同的模型
设备:CPU
Devcloud节点:idc007xv5: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
模型:head-pose-estimation-adas-0001.xml
执行命令:python3 submit_job_to_DevCloud.pyc idc007xv5
[Step 11/11] Dumping statistics report
Count: 720 iterations
Duration: 10055.01 ms
Latency: 27.66 ms
Throughput: 71.61 FPS
设备:CPU
Devcloud节点:idc007xv5: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
模型:face-detection-adas-0001.xml
执行命令:python3 submit_job_to_DevCloud.pyc idc007xv5
[Step 11/11] Dumping statistics report
Count: 923 iterations
Duration: 10018.43 ms
Latency: 10.79 ms
Throughput: 92.13 FPS
2022年 02月 21日 星期一 05:27:26 CST,vi编辑userscript.py文件的时候,发现文件中的内容少了(可能是前面的实验操作,操作失误错删除了?),少了line 44: path_to_model=”/app/face-detection-adas-0001.xml”配置这段,这咋整…。
2022年 02月 21日 星期一 05:50:11 CST,系统又默认恢复了???。
使用多个硬件进行协同推理
OpenVINO提供了多硬件协同推理的“MULTI”插件,你只需要编译Target_device的对象,不需要改动原先代码,便可以实现协同推理。
例如:target_device=“MULTI:CPU,GPU” , 即可使用CPU+GPU协同推理 ,其中CPU(1st priority) and GPU (2nd priority)。
注:本实验所有的GPU均为英特尔集成显卡,在进行实验之前,请务必确认运行的节点包含GPU设备(某些型号的至强处理器不包含GPU设备)。MYRIAD也是同理,请在实验前确保实验节点拥有该硬件!
target_device=“MULTI:CPU,GPU”
设备:MULTI:CPU,GPU
Devcloud节点:idc007xv5: Intel – core i5-6500te, intel-hd-530,myriad-1-VPU
执行命令:python3 submit_job_to_DevCloud.pyc idc007xv5
[Step 11/11] Dumping statistics report
Count: 1065 iterations
Duration: 10037.20 ms
Throughput: 106.11 FPS
进行性能比较实验
请在idc004nc2节点下,完成如下表格并分析性能数据:
逐个参数修:vi userscript.py
target_device=“MULTI:CPU,GPU” //设备,line43
path_to_model=”/app/head-pose-estimation-adas-0001.xml” //模型,line44
运行任务:python3 submit_job_to_DevCloud.pyc idc004nc2

2022年 02月 21日 星期一 06:33:15 CST,该睡觉了,睡醒再整了。
Intel DevCloud引导
由于实验内容有限,暂时不列举其他DevCloud平台上有趣的动手实验,以及超过30种边缘设备,Atom,Xeon,Core应有尽有,更有11代TigerLake CPU设备等你来试,感兴趣的同学请自行移至英特尔DevCloud官网进行体验。
2022年 02月 21日 星期一 21:14:54 CST,更多设备的性能测试,自己到DevCloud官网体验了。
第三课动手实验:AI应用中的视频处理-在线测试
1.测试当前设备的解码密度
初始化环境
#定义OV目录
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/03/
#初始化OpenVINO
source $OV/bin/setupvars.sh
执行解码密度测试
进入工作目录
cd $WD
由于当前环境只有 CPU,且DevCloud只接受.py脚本。
所以需要你通过如下指令获取及结果为25 FPS per channel的通道数:
bash decode.sh video1.mp4 CPU CPU 1
bash decode.sh video1.mp4 CPU CPU 10
bash decode.sh video1.mp4 CPU CPU 100
你也可以自行调整通道数,使之最后接近per-stream= 25FPS/channel。
请记录你的答案!
Redistribute latency…
FpsCounter(1sec): total=740.71 fps, number-streams=1, per-stream=740.71 fps
FpsCounter(1sec): total=742.76 fps, number-streams=1, per-stream=742.76 fps
FpsCounter(1sec): total=732.41 fps, number-streams=1, per-stream=732.41 fps
FpsCounter(1sec): total=722.62 fps, number-streams=1, per-stream=722.62 fps
FPSCounter(average): total=732.91 fps, number-streams=1, per-stream=732.91 fps
Redistribute latency…
FpsCounter(1sec): total=621.85 fps, number-streams=10, per-stream=62.19 fps (56.99, 63.98, 59.99, 57.99, 65.98, 61.99, 64.98, 61.99, 63.98, 63.98)
FpsCounter(1sec): total=621.26 fps, number-streams=10, per-stream=62.13 fps (68.59, 59.64, 59.64, 59.64, 59.64, 59.64, 64.61, 62.62, 63.62, 63.62)
FpsCounter(1sec): total=699.73 fps, number-streams=10, per-stream=69.97 fps (69.77, 69.77, 69.77, 67.78, 70.77, 69.77, 69.77, 68.78, 71.77, 71.77)
FpsCounter(1sec): total=713.92 fps, number-streams=10, per-stream=71.39 fps (71.99, 70.99, 71.99, 69.99, 70.99, 69.99, 71.99, 71.99, 71.99, 71.99)
FpsCounter(1sec): total=651.90 fps, number-streams=10, per-stream=65.19 fps (61.99, 62.99, 67.99, 64.99, 61.99, 63.99, 65.99, 65.99, 67.99, 67.99)
Redistribute latency…
New clock: GstSystemClock0 %)
FpsCounter(1sec): total=134.83 fps, number-streams=100, per-stream=1.35 fps (1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 2.00, 1.00, 1.00, 2.00, 2.00, 1.00, 2.00, 2.00, 1.00, 1.00, 1.00, 1.00, 2.00, 1.00, 1.00, 1.00, 2.00, 1.00, 1.00, 2.00, 1.00, 2.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 2.00, 2.00, 2.00, 2.00, 2.00, 1.00, 1.00, 1.00, 2.00, 1.00, 2.00, 3.00, 2.00, 1.00, 2.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 2.00, 1.00, 2.00, 1.00, 1.00, 2.00, 2.00, 1.00, 1.00, 2.00, 1.00, 2.00, 1.00, 2.00, 1.00, 1.00, 1.00, 1.00, 1.00, 2.00, 1.00, 1.00, 1.00, 2.00, 2.00, 2.00, 2.00, 1.00, 1.00, 1.00, 2.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 2.00, 1.00, 2.00, 1.00, 1.00)
FpsCounter(1sec): total=367.22 fps, number-streams=100, per-stream=3.67 fps (2.00, 2.99, 2.99, 2.99, 5.99, 2.99, 1.00, 2.00, 2.00, 2.99, 2.00, 2.99, 1.00, 2.00, 8.98, 2.99, 1.00, 2.00, 2.00, 2.99, 1.00, 2.99, 5.99, 2.00, 1.00, 3.99, 5.99, 1.00, 8.98, 2.99, 2.99, 2.00, 2.99, 2.00, 2.00, 2.00, 14.97, 2.00, 4.99, 1.00, 2.99, 2.00, 2.99, 10.98, 2.00, 8.98, 7.98, 2.00, 2.99, 2.00, 2.99, 2.99, 2.00, 2.99, 1.00, 2.00, 2.99, 1.00, 2.99, 2.99, 2.99, 10.98, 2.99, 2.00, 9.98, 2.00, 2.99, 2.99, 1.00, 2.99, 2.00, 2.00, 7.98, 10.98, 2.99, 2.99, 3.99, 2.99, 2.99, 5.99, 16.96, 6.99, 2.99, 1.00, 2.99, 2.99, 2.00, 14.97, 2.99, 2.00, 1.00, 4.99, 2.99, 2.99, 2.99, 2.00, 2.99, 2.99, 2.99, 2.00)
FpsCounter(1sec): total=659.83 fps, number-streams=100, per-stream=6.60 fps (5.00, 6.00, 6.00, 6.00, 7.00, 4.00, 7.00, 8.00, 9.00, 8.00, 5.00, 9.00, 7.00, 4.00, 7.00, 6.00, 6.00, 3.00, 7.00, 6.00, 6.00, 7.00, 7.00, 8.00, 7.00, 9.00, 6.00, 7.00, 6.00, 9.00, 8.00, 5.00, 5.00, 6.00, 7.00, 6.00, 4.00, 6.00, 9.00, 6.00, 5.00, 8.00, 8.00, 9.00, 8.00, 4.00, 6.00, 9.00, 5.00, 7.00, 9.00, 8.00, 6.00, 6.00, 6.00, 9.00, 9.00, 5.00, 8.00, 7.00, 6.00, 5.00, 10.00, 7.00, 2.00, 6.00, 4.00, 6.00, 5.00, 8.00, 7.00, 9.00, 4.00, 5.00, 6.00, 5.00, 8.00, 7.00, 5.00, 7.00, 3.00, 9.00, 9.00, 5.00, 7.00, 7.00, 10.00, 3.00, 9.00, 7.00, 7.00, 8.00, 6.00, 7.00, 6.00, 6.00, 9.00, 7.00, 6.00, 5.00)
FpsCounter(1sec): total=702.32 fps, number-streams=100, per-stream=7.02 fps (5.99, 8.98, 5.99, 6.98, 6.98, 5.99, 5.99, 7.98, 7.98, 7.98, 8.98, 4.99, 8.98, 7.98, 6.98, 8.98, 5.99, 7.98, 7.98, 5.99, 5.99, 4.99, 7.98, 8.98, 6.98, 6.98, 6.98, 5.99, 6.98, 5.99, 5.99, 5.99, 6.98, 8.98, 6.98, 7.98, 7.98, 5.99, 6.98, 7.98, 6.98, 7.98, 6.98, 6.98, 5.99, 7.98, 7.98, 6.98, 6.98, 3.99, 4.99, 7.98, 6.98, 5.99, 6.98, 7.98, 7.98, 7.98, 5.99, 6.98, 5.99, 6.98, 5.99, 5.99, 8.98, 6.98, 5.99, 8.98, 5.99, 7.98, 4.99, 7.98, 6.98, 7.98, 6.98, 6.98, 6.98, 6.98, 6.98, 6.98, 6.98, 5.99, 6.98, 5.99, 7.98, 6.98, 6.98, 7.98, 7.98, 6.98, 4.99, 7.98, 5.99, 7.98, 5.99, 7.98, 7.98, 6.98, 5.99, 5.99)
通道数接近per-stream= 25FPS/channel)
Redistribute latency…
New clock: GstSystemClock
FpsCounter(1sec): total=531.74 fps, number-streams=25, per-stream=21.27 fps (24.94, 23.94, 20.95, 19.95, 20.95, 21.95, 18.95, 20.95, 19.95, 23.94, 20.95, 12.97, 23.94, 20.95, 17.96, 23.94, 13.97, 19.95, 23.94, 26.94, 24.94, 22.95, 20.95, 19.95, 20.95)
FpsCounter(1sec): total=750.60 fps, number-streams=25, per-stream=30.02 fps (31.94, 30.94, 29.94, 27.95, 28.95, 31.94, 31.94, 28.95, 29.94, 30.94, 30.94, 28.95, 30.94, 30.94, 30.94, 29.94, 27.95, 30.94, 29.94, 28.95, 31.94, 29.94, 27.95, 27.95, 28.95)
FpsCounter(1sec): total=683.31 fps, number-streams=25, per-stream=27.33 fps (26.97, 26.97, 28.97, 25.97, 29.97, 27.97, 26.97, 29.97, 27.97, 24.97, 25.97, 25.97, 26.97, 30.97, 26.97, 29.97, 25.97, 28.97, 27.97, 25.97, 24.97, 28.97, 26.97, 25.97, 23.98)
FpsCounter(1sec): total=732.91 fps, number-streams=25, per-stream=29.32 fps (27.96, 29.96, 27.96, 29.96, 25.96, 30.95, 27.96, 27.96, 27.96, 31.95, 29.96, 29.96, 31.95, 29.96, 29.96, 27.96, 31.95, 28.96, 27.96, 29.96, 29.96, 27.96, 27.96, 29.96, 29.96)
FpsCounter(1sec): total=734.54 fps, number-streams=25, per-stream=29.38 fps (27.98, 30.98, 25.98, 29.98, 27.98, 32.98, 27.98, 27.98, 28.98, 29.98, 29.98, 31.98, 29.98, 28.98, 27.98, 27.98, 29.98, 24.98, 29.98, 29.98, 31.98, 27.98, 27.98, 31.98, 31.98)
第四课动手实验:如何进行AI推理的性能对比-在线测试
1.数据精度对推理性能的影响
初始化环境
#定义OV目录
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/04/
#初始化OpenVINO
source $OV/bin/setupvars.sh
编译示例
#一键编译OpenVINO中的C++ sample
source $OV/inference_engine/samples/cpp/build_samples.sh
开始实验
开始实验:
cd $WD
将刚才编译完成的benchmark_app 复制到当前文件夹:
cp /home/dc2-user/inference_engine_04_samples_build/intel64/Release/benchmark_app $WD
获取模型
下载模型:
python3 $OV/deployment_tools/tools/model_downloader/downloader.py –name face-detection-adas-0001 -o $WD
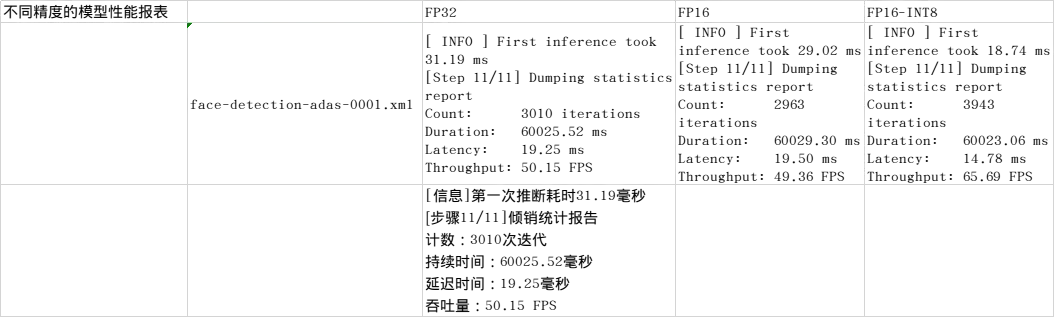
执行不同精度的模型性能测试
./benchmark_app -m intel/face-detection-adas-0001/FP32/face-detection-adas-0001.xml
./benchmark_app -m intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml
./benchmark_app -m intel/face-detection-adas-0001/FP16-INT8/face-detection-adas-0001.xml
比较不同精度的模型性能,以及模型推理延迟或读取网络的时间……看看有什么不同。
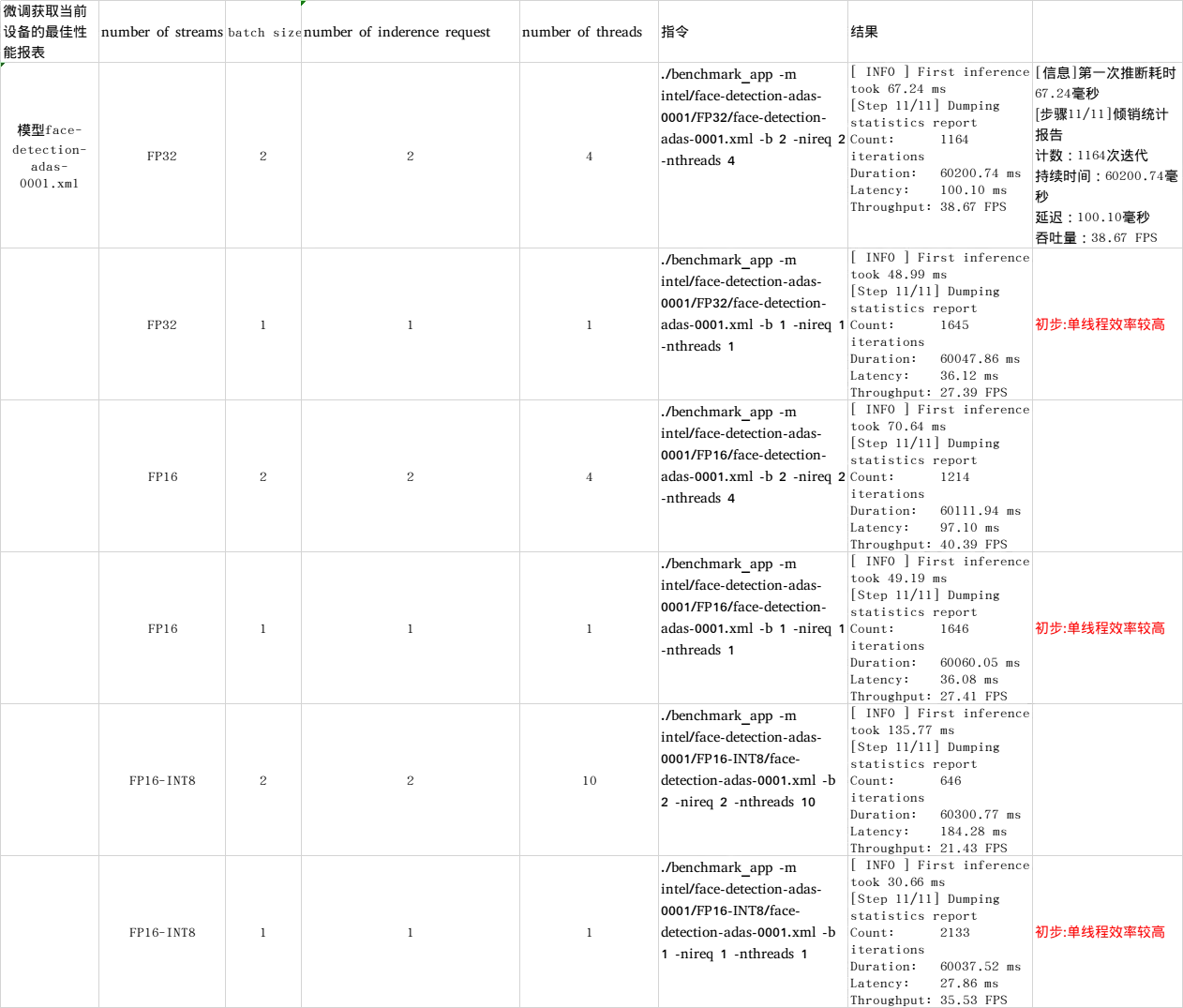
挑战任务
请输入:
./benchmark_app -help
以获得更多benchmark_app 的可评估参数。
请尝试设置不同的参数:
number of streams (-nstreams)
batch size (-b)
number of inderence request (-nireq)
number of threads (-nthreads)
例如:./benchmark_app -m intel/face-detection-adas-0001/FP32/face-detection-adas-0001.xml -b 2 -nireq 2 -nthreads 4
从您当前的设备中获得最佳性能
第六课动手实验:AI应用中的音频处理-在线测试
1.声音检测实验
初始化环境
#定义工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/06/Lab1/
export MODELS_PATH=~/OV-300/06/Lab1/
#初始化OpenVINO
source $OV/bin/setupvars.sh
开始实验
# 进入实验目录
cd $WD
#下载并使用MO转换声音识别模型
bash download_audio_models.sh
#通过vi查看模型拓扑结构
vi $MODELS_PATH/audio_models/aclnet/FP32/aclnet.xml
注:可以看到该xml的版本以及 数据精度为:FP32,input shape=“1, 1, 1, 16000”。使用“:q”指令退出该界面。
播放需要检测的声音文件
#使用show命令,播放mp3
show how_are_you_doing.mp3
注:由于功能限制,必须手动逐字输入该命令。并且由于限制,平台只能够播放MP3格式文件,实验运行的声音材料为WAV格式,本平台事先已经将WAV转换成MP3格式可供使用。
运行Demo
#运行命令:
bash audio_event_detection.sh
注:屏幕上将会打印DL-Streamer的pipeline指令和该指令的全部输出结果
#运行命令过滤结果,看看检测到了哪些声音:
bash audio_event_detection.sh | grep “label”:” | sed ‘s/label_id.*//’ |sed ‘s/.*label”/==>/’

挑战任务:提高程序的识别准确率
# 您可以从音频文件中听不到昆虫的声音,但程序检测到了昆虫的声音。请思考如何改善这个问题?
注:检测村内是否有每种声音都会有一个临界值,即检测阈值
#修改aclnet.json 脚本来实现你的猜想:
vi $WD/model_proc/aclnet.json
解决方案:尝试 “Insects (flying)” 在 0.5 至0.9 之间更改,更改后保存完再次运行audio_event_detection.sh进行测试,直至检测不到昆虫噪音。
{
“index”: 7,
“label”: “Insects (flying)”,
“threshold”: 0.5 //修改为上临界值0.9
},
测试结果(无昆虫噪音):
==>:“Rain”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
==>:“Speech”,”
思考任务
你可以上传你的WAV文件进行测试,不过若是想使用平台进行播放mp3,记得使用:
ffmpeg -i xxx.wav output.mp3
转换成MP3进行播放哦,并且需要修改audio_event_detection.sh里面的输入wav名称。
注意:页面顶部的帮助手册中提供了上传和下载文件的教程。这个实验可以通过按 OK 键跳过。
2022年 02月 21日 星期一 22:47:34 CST,后面还有任务,先跳过。
2.声音识别实验
初始化环境
#定义工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/06/Lab2/
#添加OpenVINO Python API路径
export PYTHONPATH=”$PYTHONPATH:/home/dc2-user/omz_demos_build/intel64/Release/lib/”
#初始化OpenVINO
source $OV/bin/setupvars.sh
# 进入工作目录
cd $WD
将原生模型转换为IR格式
#使用converter.py将事先准备好的mozilla-deepspeech-0.6.1进行IR转换 :
python3 $OV/deployment_tools/tools/model_downloader/converter.py –name mozilla-deepspeech-0.6.1 -o $WD
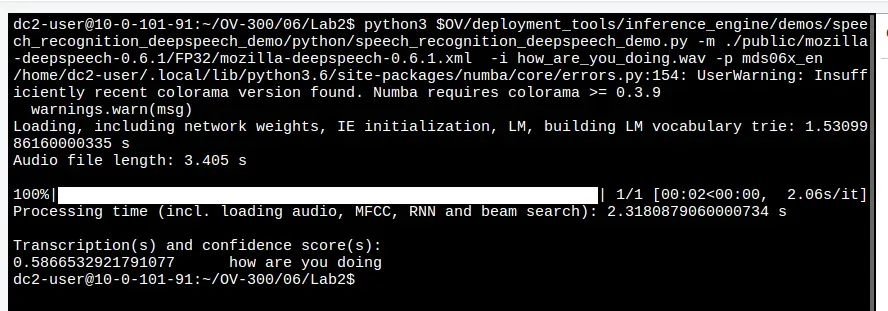
运行声音识别Demo
#播放要识别的声音文件:
show how_are_you_doing.mp3
#运行语音识别示例:
python3 $OV/deployment_tools/inference_engine/demos/speech_recognition_deepspeech_demo/python/speech_recognition_deepspeech_demo.py -m ./public/mozilla-deepspeech-0.6.1/FP32/mozilla-deepspeech-0.6.1.xml -i how_are_you_doing.wav -p mds06x_en
注:音频输入为wav格式, 你可以在屏幕上看到刚才的音频的识别结果。
思考任务
#使用你自带的wav文件进行声音识别示例,看看能否正确识别到文件中的声音。
#你可以尝试用中文或英文作为语音输入,并尝试探索其识别的准确性。
2022年 02月 21日 星期一 22:59:47 CST,后面还有任务,先跳过。
第七课动手实验:如何实现DL-streamer包含的高级功能?-在线测试
1.使用DL-streamer进行表情识别
初始化环境
#定义工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/07/
#初始化OpenVINO
source $OV/bin/setupvars.sh
开始实验
# 进入实验目录
cd $WD
#播放原视频示例:
show video1.mp4
运行识别示例
#运行人脸识别和分类示例:
bash face_detection_and_classification.sh video1.mp4
#获得output.mp4,获得可播放的标准MP4格式,使用:
ffmpeg -i output.mp4 output_1.mp4
#播放生成的视频:
show output_1.mp4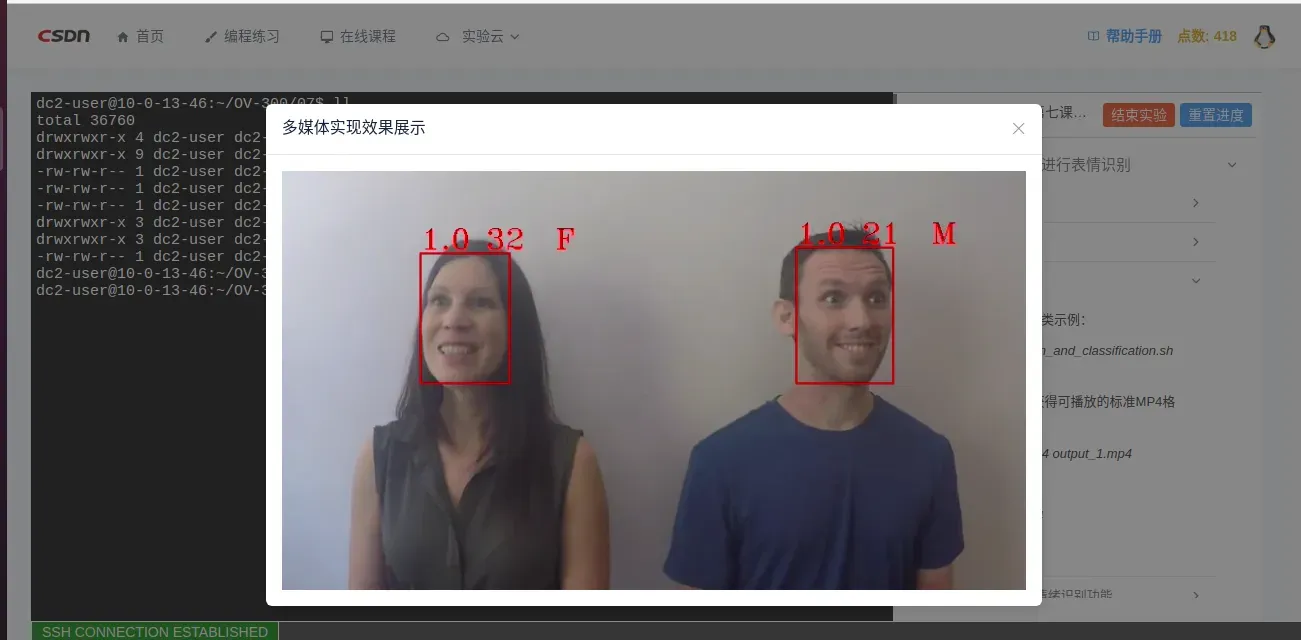
挑战任务:增加情绪识别功能
#请你思考如何在年龄/性别识别的基础上,怎么情绪识别的功能:
修改 postproc_callbacks/age_gender_classification.py 脚本,我们往里添加的代码是:
if 'prob_emotion' == layer_name:
emotions = ["neutral", "happy", "sad", "surprise", "anger"]
tensor.set_label(emotions[numpy.argmax(data)])
continue
修改 face_detection_and_classification.sh 脚本。需要和 age-gender-recognition模型一样,同理增加emotion-recognition的部分,所用 模型为emotions-recognition-retail-003.xml
注:答案可以在Solution中获取
cd Solution
#查看age_gender_classification.py/face_detection_and_classification.sh脚本的改动
bash face_detection_and_classification.sh video1.mp4
ffmpeg -i output.mp4 output_1.mp4
#播放生成的视频:
show output_1.mp4
dc2-user@10-0-13-46:~/OV-300/07$ ll
total 36760
drwxrwxr-x 4 dc2-user dc2-user 4096 Feb 22 00:08 ./
drwxrwxr-x 9 dc2-user dc2-user 4096 Nov 29 22:04 ../
-rw-rw-r-- 1 dc2-user dc2-user 1926 Nov 30 16:10 face_detection_and_classification.sh
-rw-rw-r-- 1 dc2-user dc2-user 5760389 Feb 21 23:25 output_1.mp4
-rw-rw-r-- 1 dc2-user dc2-user 15066315 Feb 22 00:17 output.mp4
drwxrwxr-x 3 dc2-user dc2-user 4096 Feb 22 00:05 postproc_callbacks/
drwxrwxr-x 3 dc2-user dc2-user 4096 Feb 22 00:16 Solution/
-rw-rw-r-- 1 dc2-user dc2-user 16788193 Oct 25 03:22 video1.mp4
dc2-user@10-0-13-46:~/OV-300/07$
postproc_callbacks/目录:
dc2-user@10-0-13-46:~/OV-300/07/postproc_callbacks$ ll
total 20
drwxrwxr-x 3 dc2-user dc2-user 4096 Feb 22 00:05 ./
drwxrwxr-x 4 dc2-user dc2-user 4096 Feb 22 00:08 ../
-rw-rw-r-- 1 dc2-user dc2-user 1067 Feb 22 00:05 age_gender_classification.py
drwxrwxr-x 2 dc2-user dc2-user 4096 Feb 22 00:16 __pycache__/
-rw-rw-r-- 1 dc2-user dc2-user 1382 Oct 25 03:22 ssd_object_detection.py
dc2-user@10-0-13-46:~/OV-300/07/postproc_callbacks$
Solution目录:
dc2-user@10-0-13-46:~/OV-300/07/Solution$ ll
total 24
drwxrwxr-x 3 dc2-user dc2-user 4096 Feb 22 00:16 ./
drwxrwxr-x 4 dc2-user dc2-user 4096 Feb 22 00:08 ../
-rw-rw-r-- 1 dc2-user dc2-user 1087 Oct 25 03:22 age_gender_classification.py
-rw-rw-r-- 1 dc2-user dc2-user 2103 Nov 30 16:44 face_detection_and_classification.sh
drwxrwxr-x 2 dc2-user dc2-user 4096 Nov 30 16:45 __pycache__/
-rw-rw-r-- 1 dc2-user dc2-user 1397 Oct 25 03:22 ssd_object_detection.py
dc2-user@10-0-13-46:~/OV-300/07/Solution$
~/OV-300/07/Solution/age_gender_classification.py
# ==============================================================================
# Copyright (C) 2018-2020 Intel Corporation
#
# SPDX-License-Identifier: MIT
# ==============================================================================
from gstgva import VideoFrame
import numpy
def process_frame(frame: VideoFrame) -> bool:
for roi in frame.regions():
for tensor in roi.tensors():
if tensor.name() == 'detection':
continue
layer_name = tensor.layer_name()
data = tensor.data()
if 'age_conv3' == layer_name:
tensor.set_label(str(int(data[0] * 100)))
continue
if 'prob' == layer_name:
tensor.set_label(" M " if data[1] > 0.5 else " F ")
continue
if 'prob_emotion' == layer_name:
emotions = ["neutral", "happy", "sad", "surprise", "anger"]
#print(data, emotions[numpy.argmax(data)])
tensor.set_label(emotions[numpy.argmax(data)])
continue
return True
2022年 02月 22日 星期二 00:40:30 CST,添加line23-27行代码。
if 'prob_emotion' == layer_name:
emotions = ["neutral", "happy", "sad", "surprise", "anger"]
#print(data, emotions[numpy.argmax(data)])
tensor.set_label(emotions[numpy.argmax(data)])
continue
~/OV-300/07/Solution/face_detection_and_classification.sh
#!/bin/bash
# ==============================================================================
# Copyright (C) 2018-2021 Intel Corporation
#
# SPDX-License-Identifier: MIT
# ==============================================================================
set -e
INPUT=${1:-https://github.com/intel-iot-devkit/sample-videos/raw/master/head-pose-face-detection-female-and-male.mp4}
DEVICE=${2:-CPU}
if [[ $3 == "display" ]] || [[ -z $3 ]]; then
SINK_ELEMENT="gvawatermark ! videoconvert !avenc_mpeg4 ! mp4mux! filesink location=output.mp4"
elif [[ $3 == "fps" ]]; then
SINK_ELEMENT="gvafpscounter ! fakesink async=false "
else
echo Error wrong value for SINK_ELEMENT parameter
echo Possible values: display - render, fps - show FPS only
exit
fi
MODEL1=face-detection-adas-0001
MODEL2=age-gender-recognition-retail-0013
SCRIPTDIR="$(dirname "$(realpath "$0")")"
PYTHON_SCRIPT1=$SCRIPTDIR/postproc_callbacks/ssd_object_detection.py
PYTHON_SCRIPT2=$SCRIPTDIR/postproc_callbacks/age_gender_classification.py
if [[ $INPUT == "/dev/video"* ]]; then
SOURCE_ELEMENT="v4l2src device=${INPUT}"
elif [[ $INPUT == *"://"* ]]; then
SOURCE_ELEMENT="urisourcebin buffer-size=4096 uri=${INPUT}"
else
SOURCE_ELEMENT="filesrc location=${INPUT}"
fi
DETECT_MODEL_PATH=${MODELS_PATH}/intel/face-detection-adas-0001/FP32/face-detection-adas-0001.xml
CLASS_MODEL_PATH=${MODELS_PATH}/intel/age-gender-recognition-retail-0013/FP32/age-gender-recognition-retail-0013.xml
EMOTION_MODEL_PATH=${MODELS_PATH}/intel/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.xml
echo Running sample with the following parameters:
echo GST_PLUGIN_PATH=${GST_PLUGIN_PATH}
PIPELINE="gst-launch-1.0 \
$SOURCE_ELEMENT ! decodebin ! \
gvainference model=$DETECT_MODEL_PATH device=$DEVICE ! queue ! \
gvapython module=$PYTHON_SCRIPT1 ! \
gvaclassify model=$CLASS_MODEL_PATH device=$DEVICE ! queue ! \
gvaclassify model=$EMOTION_MODEL_PATH device=$DEVICE ! queue ! \
gvapython module=$PYTHON_SCRIPT2 ! \
$SINK_ELEMENT"
echo ${PIPELINE}
PYTHONPATH=$PYTHONPATH:$(dirname "$0")/../../../../python \
${PIPELINE}
2022年 02月 22日 星期二 00:40:30 CST,添加line41行代码。
EMOTION_MODEL_PATH=${MODELS_PATH}/intel/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.xml
2022年 02月 22日 星期二 00:56:06 CST,这相应配置都修改了,运行怎么无效果呀???没有情绪识别信息输出。
第八课动手实验:整合实现AI应用中的音视频处理-在线测试
1.视频+音频处理实验
实验目标
你的任务:
构建一个包含视频处理与音频处理的pipeline流水线程序
在OV-300/08/目录下,这些是你拥有的资源:
在/Models/目录下
音频检测模型
/Models/audio_detection/FP16/aclnet.xml
目标检测模型
/Models/person-vehicle-bike-detection-crossroad-0078/FP16/person-vehicle-bike-detection-crossroad-0078.xml
object.list.yml
A list of objects to detect:目标列表
sound.list.yml
A list of sounds to detect:声音种类列表
Road.mp4
输入MP4(包含了音频+视频)
audio_video_detect.py
音频检测的可用代码
准备实验
#初始化环境
export OV= (填写你的答案)
export OV=/opt/intel/openvino_2021/
export WD=(填写你的答案)
export WD=/home/dc2-user/OV-300/08
#初始化 OpenVINO
(填写你的答案)
source $OV/bin/setupvars.sh
进行实验
# 进入实验目录
(填写你的答案)cd $WD
#播放待检测的视频road.mp4
(填写你的答案)show road.mp4
#编辑run.sh 来完成实验目标
(填写你的答案)vi run.sh
注:audio pipeline参考 /opt/intel/openvino_2021/data_processing/dl_streamer/samples/gst_launch/audio_detect/audio_event_detection.sh中截取你需要的音频处理command line部分(注意模型和Json的名称相对应),来添加aclnet.xml的音频检测功能,粘贴至run.sh中。
video-decode-pipelide参考/opt/intel/openvino_2021/data_processing/dl_streamer/samples/gst_launch/vehicle_pedestrian_tracking/vehicle_pedestrian_tracking.sh来添加 person-vehicle-bike-detection-crossroad-0078模型的车辆行人识别功能。
dc2-user@10-0-255-63:~/OV-300/08$ pwd
/home/dc2-user/OV-300/08
dc2-user@10-0-255-63:~/OV-300/08$ ll
total 48780
drwxrwxr-x 5 dc2-user dc2-user 4096 Feb 22 02:08 ./
drwxrwxr-x 9 dc2-user dc2-user 4096 Nov 29 22:04 ../
-rw-rw-r-- 1 dc2-user dc2-user 3146 Nov 30 19:39 audio_video_detect.py
drwxrwxr-x 4 dc2-user dc2-user 4096 Oct 25 11:32 Models/
-rw-rw-r-- 1 dc2-user dc2-user 64 Nov 30 18:41 object.list.yml
-rw-rw-r-- 1 dc2-user dc2-user 1340 Oct 25 03:22 OV-300.08.How
drwxrwxr-x 2 dc2-user dc2-user 4096 Feb 22 02:05 __pycache__/
-rw-rw-r-- 1 dc2-user dc2-user 49906354 Oct 25 03:22 road.mp4
-rw-rw-r-- 1 dc2-user dc2-user 1822 Feb 22 02:05 run.sh
drwxrwxr-x 3 dc2-user dc2-user 4096 Nov 30 19:39 Solution/
-rw-rw-r-- 1 dc2-user dc2-user 72 Nov 30 18:40 sound.list.yml
dc2-user@10-0-255-63:~/OV-300/08$
dc2-user@10-0-255-63:~/OV-300/08$ pwd
/home/dc2-user/OV-300/08
dc2-user@10-0-255-63:~/OV-300/08$ tree -L 5
.
├── audio_video_detect.py
├── Models
│ ├── audio_detection
│ │ ├── aclnet.json
│ │ └── FP16
│ │ ├── aclnet.bin
│ │ ├── aclnet.mapping
│ │ └── aclnet.xml
│ └── person-vehicle-bike-detection-crossroad-0078
│ ├── FP16
│ │ ├── person-vehicle-bike-detection-crossroad-0078.bin
│ │ └── person-vehicle-bike-detection-crossroad-0078.xml
│ └── person-vehicle-bike-detection-crossroad-0078.json
├── object.list.yml
├── OV-300.08.How
├── __pycache__
│ └── audio_video_detect.cpython-36.pyc
├── road.mp4
├── run.sh
├── Solution
│ ├── audio_event_detection.sh
│ ├── audio_video_detect.py
│ ├── object.list.yml
│ ├── __pycache__
│ │ └── audio_video_detect.cpython-36.pyc
│ ├── run.sh
│ ├── sound.list.yml
│ └── starting-point-run.sh
└── sound.list.yml
8 directories, 21 files
dc2-user@10-0-255-63:~/OV-300/08$
完成实验
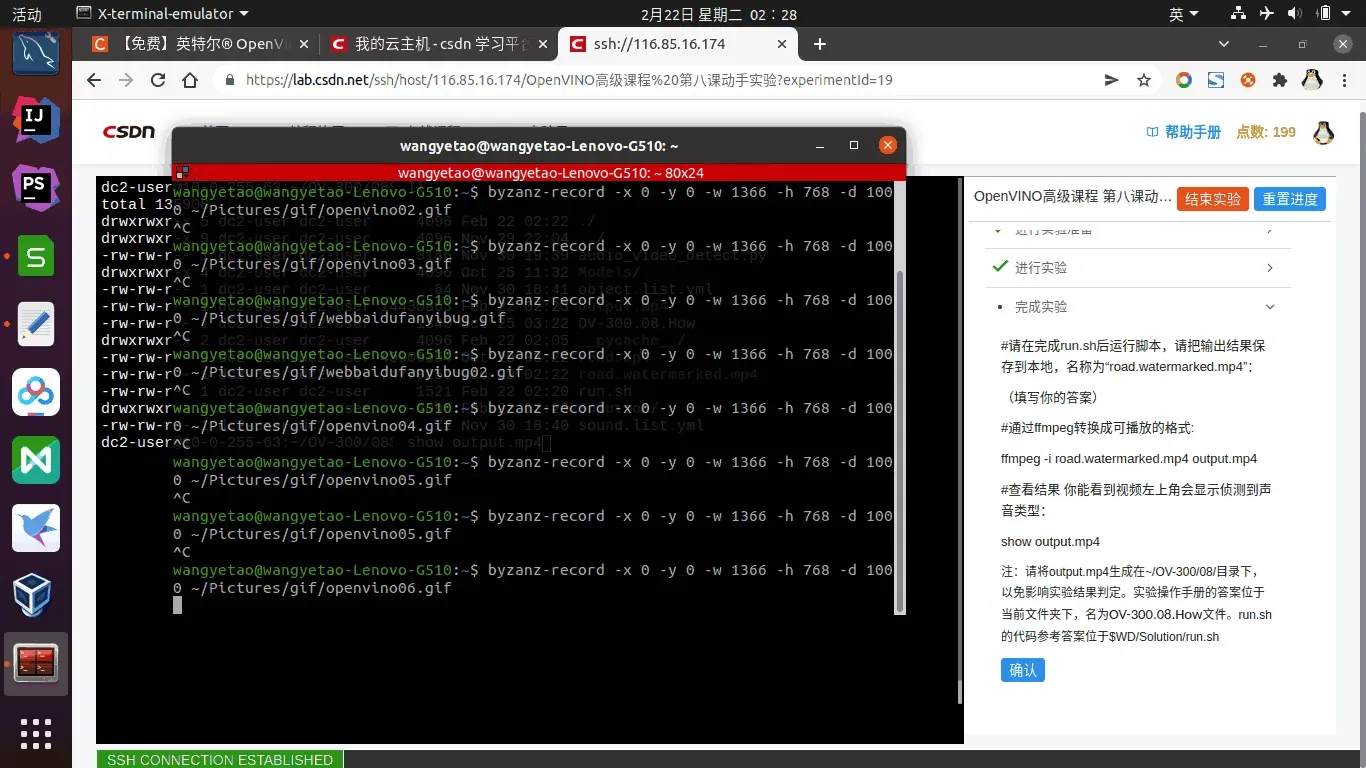
#请在完成run.sh后运行脚本,请把输出结果保存到本地,名称为“road.watermarked.mp4”:
(填写你的答案)
bash run.sh road.mp4
#通过ffmpeg转换成可播放的格式:
ffmpeg -i road.watermarked.mp4 output.mp4
#查看结果可以看到检测到的声音类型会显示在视频的左上角:
show output.mp4
注:请将output.mp4生成在~/OV-300/08/目录下,以免影响实验结果判定。实验操作手册的答案位于当前文件夹下,名为OV-300.08.How文件。run.sh的代码参考答案位于$WD/Solution/run.sh
/home/dc2-user/OV-300/08/OV-300.08.How
OpenVINO 300
Lesson 08
Lab 1
=============================================================================
Your task:
Build a pipeline that will process both video and audio
In the directory you can find:
under /Models/
The audio detection model
/Models/audio_detection/FP16/aclnet.xml
The object detection model
/Models/person-vehicle-bike-detection-crossroad-0078/FP16/person-vehicle-bike-detection-crossroad-0078.xml
object.list.yml
A list of objects to detect
sound.list.yml
A list of sounds to detect
Road.mp4
Input (audio + Video)
audio_video_detect.py
python script to add the audio detection to the GST-buffer
=============================================================================
1) Get started
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/08/
Initialize OpenVINO
source $OV/bin/setupvars.sh
This is the file to edit ---->>>
your baseline is run.sh
2) Copy the audio detection pipeline from the DL-streamer samples..
vi /opt/intel/openvino_2021/data_processing/dl_streamer/samples/gst_launch/audio_detect/audio_event_detection.sh
3) Results could be found under Solutions directory
./Solution/run.sh
Just copy to your directory and run
You can see the result video in Road.watermarked.mp4 or displayed to screen
(need to edit run.sh to change that selection)
/home/dc2-user/OV-300/08/Solution/run.sh
#Copyright (C) 2018-2021 Intel Corporation
#Licensed under the Apache License, Version 2.0 (the "License");
INPUT=${WD}/road.mp4
AUDIO_MODEL=${WD}/Models/audio_detection/FP16/aclnet.xml
AUDIO_MODEL_PROC=${WD}/Models/audio_detection/aclnet.json
DETECTION_MODEL=${WD}/Models/person-vehicle-bike-detection-crossroad-0078/FP16/person-vehicle-bike-detection-crossroad-0078.xml
DETECTION_MODEL_PROC=${WD}/Models/person-vehicle-bike-detection-crossroad-0078/person-vehicle-bike-detection-crossroad-0078.json
gst-launch-1.0 uridecodebin uri=file:${INPUT} name=front_end \
front_end. ! queue ! \
audioresample ! audioconvert ! audio/x-raw, channels=1,format=S16LE,rate=16000 ! audiomixer output-buffer-duration=100000000 ! \
gvaaudiodetect model=$AUDIO_MODEL model-proc=$AUDIO_MODEL_PROC sliding-window=0.2 !\
gvametaconvert ! gvametapublish file-format=json-lines file-path=/tmp/audio_event_stream ! audioconvert !\
fakesink \
front_end. ! queue ! \
gvadetect model=$DETECTION_MODEL model-proc=$DETECTION_MODEL_PROC ! \
gvapython module=${WD}/audio_video_detect.py class=AudioEventWatermark ! \
videoconvert ! gvawatermark ! videoconvert ! avenc_mpeg4!\
mpegtsmux ! filesink location=road.watermarked.mp4
#===> for saving the output to a file
#gvawatermark ! videoconvert ! x264enc key-int-max=30 speed-preset=fast tune=zerolatency !\
#mpegtsmux ! filesink location=Road.watermarked.mp4
#Replace the last 2 lines with this line to present the video to screen.
#videoconvert ! gvawatermark ! ximagesink
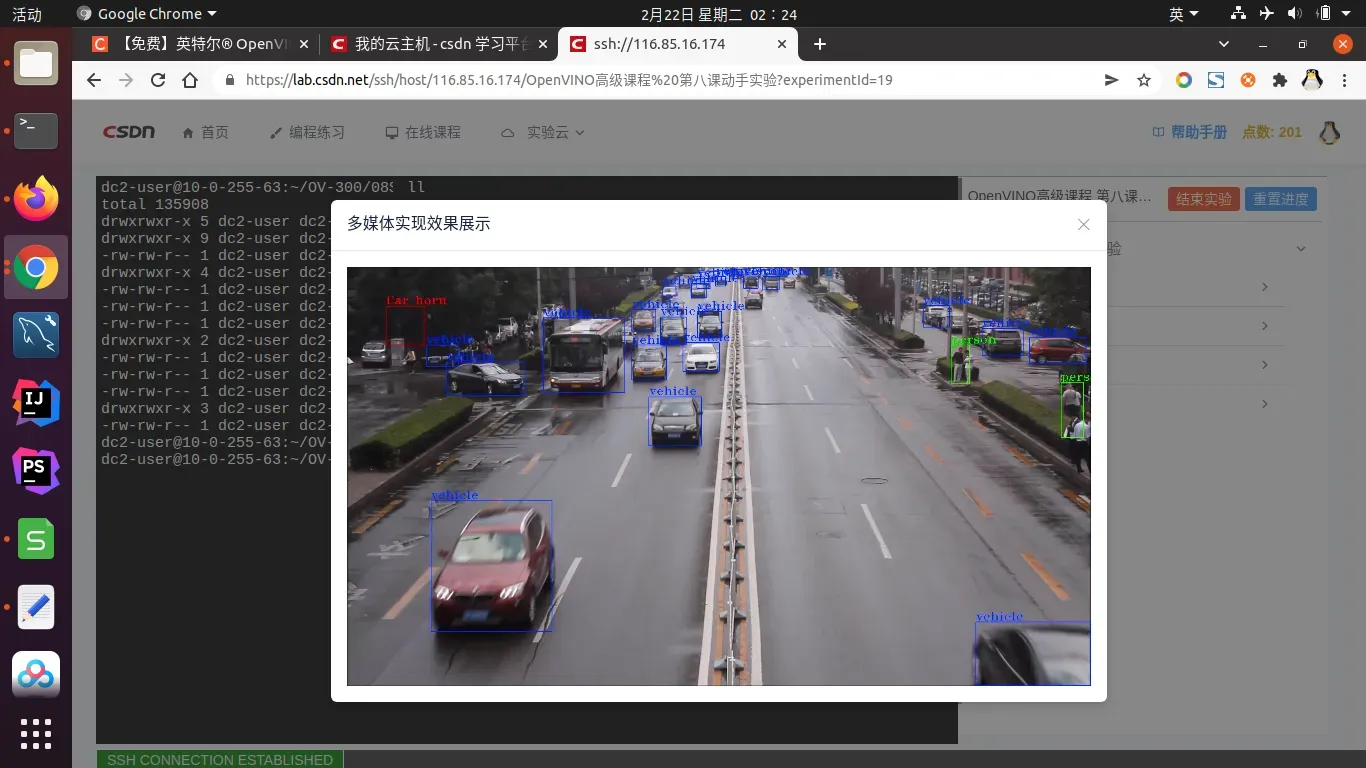

2022年 02月 22日 星期二 02:31:27 CST,OK,实验完成!全部实验完成!
BEGIN:2022-02-20 23:53:49
END:2022年 02月 22日 星期二 02:31:27 CST
OpenVINO高级课程结业证书
您已完成 “英特尔® OpenVINO™工具套件高级课程” 学习
恭喜您获得“英特尔® OpenVINO™工具套件高级课程 ”专属证书!证书编号:L0102022022201041003,您可以在CSDN官网查询,查询地址:https://edu.csdn.net/cert?username=u014132947 。
Ok完成
版权声明:本文为博主dnbug Blog原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/u014132947/article/details/123037156