–NeoZng【neozng1@hnu.edu.cn】
如果觉得作者的文笔还不错,请点赞关注!
Transformer是NLP领域的基础架构,也即是前述的自注意力机制加上Encoder-Decorder的结构,这相当于CV领域的CNN架构。这里我们不会从最原始的ViT开始,而是直接介绍FAIR退出的DERT模型和其改进版的可形变注意力版本,因为这是在公开数据集上基于transformer的模型第一次拥有了获得超过CNN-based的模型的表现。
不过由于自注意力模块的架构不同于CNN,这导致基本无法使用现有的硬件(如google的npu和nvidia的nn-core与部分cuda-core)和软件(例如针对3x3conv优化的winograd加速算法)对其性能进行优化。而且拥有相同精度的transformer模型的参数量和计算量往往远超CNN,因此目前对于我们而言,很难将其部署在边缘平台上,在RoboMaster中也没有太大的舞台,故这里对ViT只是进行尽量完整的介绍以便读者能够了解学术界的前沿。
请注意,学习ViT需要一些auto-encoder和自注意力模块的基本知识,这在之前介绍vision attention机制的时候已经提到这一点,有了前述基础,相信你理解ViT也并不会遇到太多的困难,我们可以将vision transformer看作将所有的CNN都替换为自注意力,卷积是一种特殊的自注意力操作(局部),而自注意力又可以看成广义的卷积(kernel和padding都等于图像大小的卷积,并且使用循环padding,即将图像复制并平铺在原图的四周)。
笔者的另一篇文章详细介绍了transformer模型(也就是增强的自注意力):占位符,还有一篇介绍auto Encoder-Decoder模型的总览性的文章:占位符
- DETR(DEtectionTRsformer)
DETR是facebook AI research lab(现在已经叫MetaAI了)发布的一个端到端的检测器,它将目标检测作为一个集合预测的问题,因为它限定了transformer的输出个数和Decoder的输入。端到端的设计使DETR也实现了真正的nms-free,它只会输出限定数量的预测框和其对应的类别。
DETR的检测pipeline
DETR没有太过极端(同时也是为了减小运算量),它仍然采用CNN作为backbone提取特征,之后将其输出序列化并加上位置编码,投入标准的transformer encoder-decoder架构中,最后输出100个prediction box和class(固定100个输出,若途中没有那么多目标就输出no object,即空集)。在CNN之后的结构和最早的ViT并没有什么不同,关键是DETR优化了损失函数和正样本匹配方法,将正样本和预测框进行全局二分匹配以找到最优的标签分配,从而实现上述的端到端方法。
我们直接顺着pipeline,按照结构顺序来分析DETR: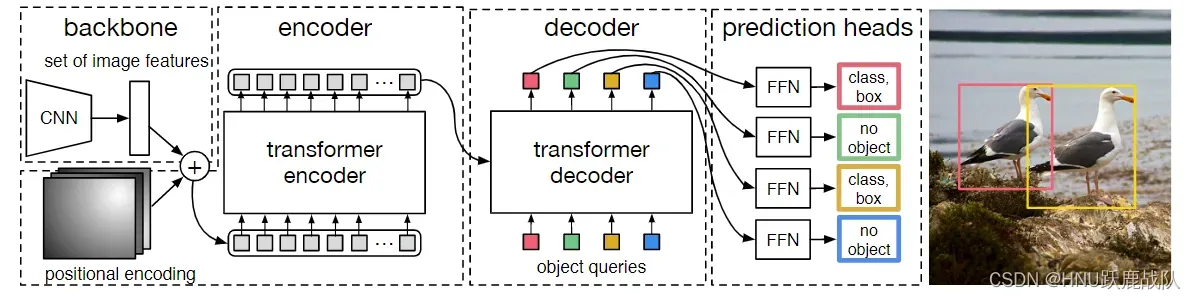
DETR的结构和数据流 - 首先是backbone部分,文中提到采用了传统的卷网络但也没有说具体是用的哪一个网络,具体可以看看它的代码。同时我们需要为生成的feature map添加位置编码,因为自注意力计算是位置无关的,导致无法充分利用位置关系,故为每个位置添加位置编码使得transfomer捕捉到这种信息。关于位置编码原文也给出了参考文献和使用不同位置编码得到效果的ablation,将其看作为每个位置的feature map附上其坐标信息即可(可以是element-wise add、scalar mutiply或者concatenate)。
加上了位置编码之后我们就可以把图片拆分成一个个小块(把三维的dxWxH的feature map变成一维的即序列化,因为feature map上的一个像素对应着原图的一块区域,所以这里说是原图上的一个块,一般称为patch),投入transformer中。 - 这里使用的transformer结构如下图所示,Encoder中堆叠数个多头自注意力、前向网络和跳连接+归一化组成的基本结构,然后选择一些层的输出作为Query和Key添加到Decoder的输入中(这些mutil-head attention的输入并没有特定的要求,可以是任意打乱顺序的层,类似于FPN中的多尺度特征连接,融合不同尺度的特征)。
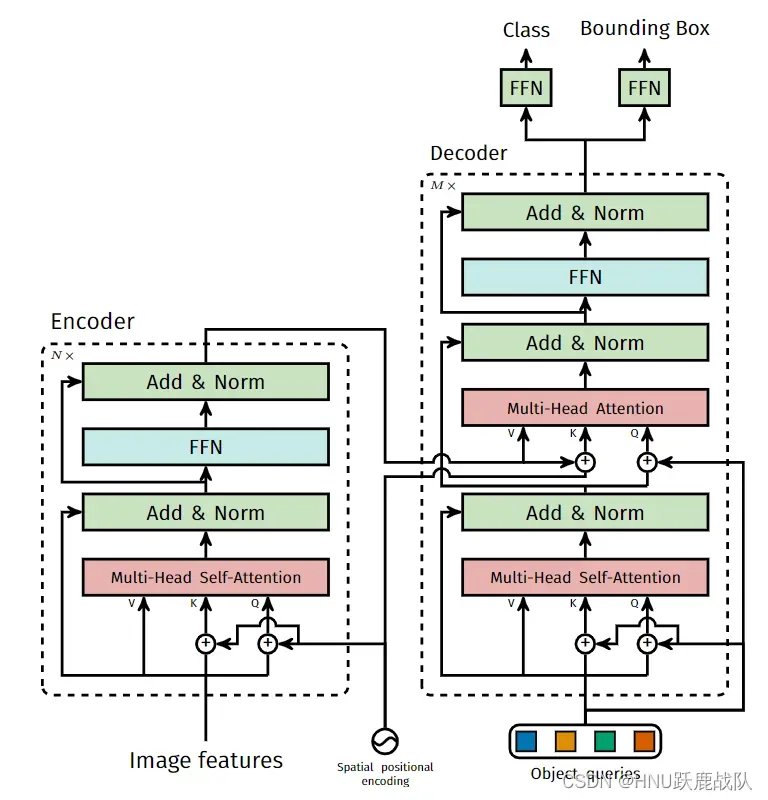
DETR中的transformer结构
Decoder不同于Encoder的就是上述的Mutil-Head Attention结构,不仅会用到前层输入还会使用Encoder的中间层或末层输出。同时最重要的是Decoder的第一层输入是一个可学习的Obejct Queries,他和FFN、自注意力中的QKV权重一样会随着网络的训练而改变。它在Transformer架构中的地位,相当于CNN架构中的anchor,并且这是一个动态的、可变的自适应anchor,只不过换了一种形式出现而已。经过学习后,object queries中的每一个单元都会对应到一些特定的目标,论文也给出了预测框中的top 20(限定transformer的decoder输出100个检测结果)的可视化图表。其在MS COCO上检测的结果显示,每一个slot(可以看成是一个object querie的单元,或是预测集合中的一个元素)都会对应到一些特定大小和比例的目标,这就和anchor非常非常类似了。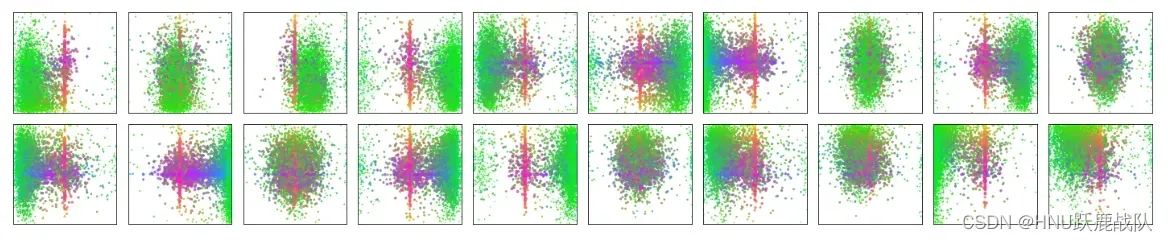
预测可视化结果,每个结果由一个点表示到一个检测框。绿色代表小目标,红色代表水平大目标,蓝色代表垂直大目标 - 最后就是head部分,几个FFN(feedforward network,其实就是全连接)后输出预测框位置和分类。这里主要介绍一下训练时的标签匹配方法。这部分匹配和anchor-based的方法相似,要将GT分配给最合适的anchor进行训练,但是由于使用的时end-to-end的策略,在标签分配时自然只能将预测结果和GT进行一对一匹配,而DETR设置的100个框显然远远多于一张图片中含有的GT个数(除了个别小样本数据集,如果要扩展到这些数据集上,修改框个数即可),因此没有匹配到GT的预测会被设为空,不对应任何目标。
- Deformable DETR
和其他的ViT一样,DETR最大的问题就是transformer模块计算的巨大开销,自注意力(全局+密集)计算的复杂度是,更何况是多头自注意力。我想作者的灵感应该来自deformable conv和pooling,既然卷积可以形变并且可以看作一个局部的注意力模块,那为什么不能让自注意力稍稍不那么“全局”,并且可以自适应的选择需要需要特别注意的那些像素呢?并且之前我们在介绍Vision Attention的时候,GCNet就提出高层次的特征生成的注意力几乎是位置无关的,所以我们并不需要计算所有像素两两的相关性。于是Deformable DETR就自然而然地诞生了。
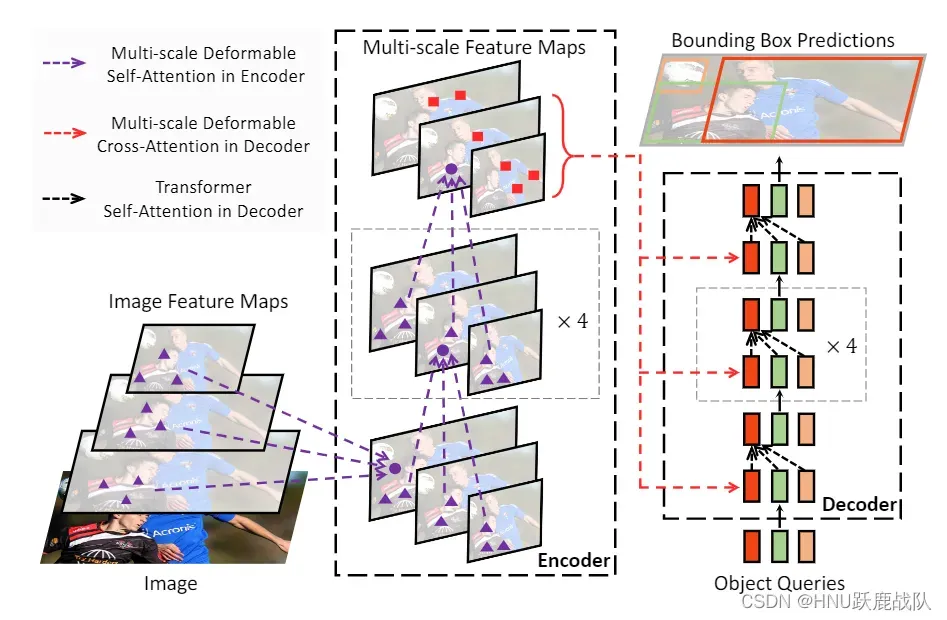
DDETR的架构
DDETR的整体和思想架构和DETR的区别不算太大,最关键的就是将自注意力替换成了可形变注意力,因此同时需要学习一组用于计算注意力偏移量的参数。可形变注意力不再计算query和其他所有点的相关性而是只计算部分点,那么怎样知道是哪些部分?这就交给offsets进行学习,经过训练offsets能得到对当前query最重要的那些位置。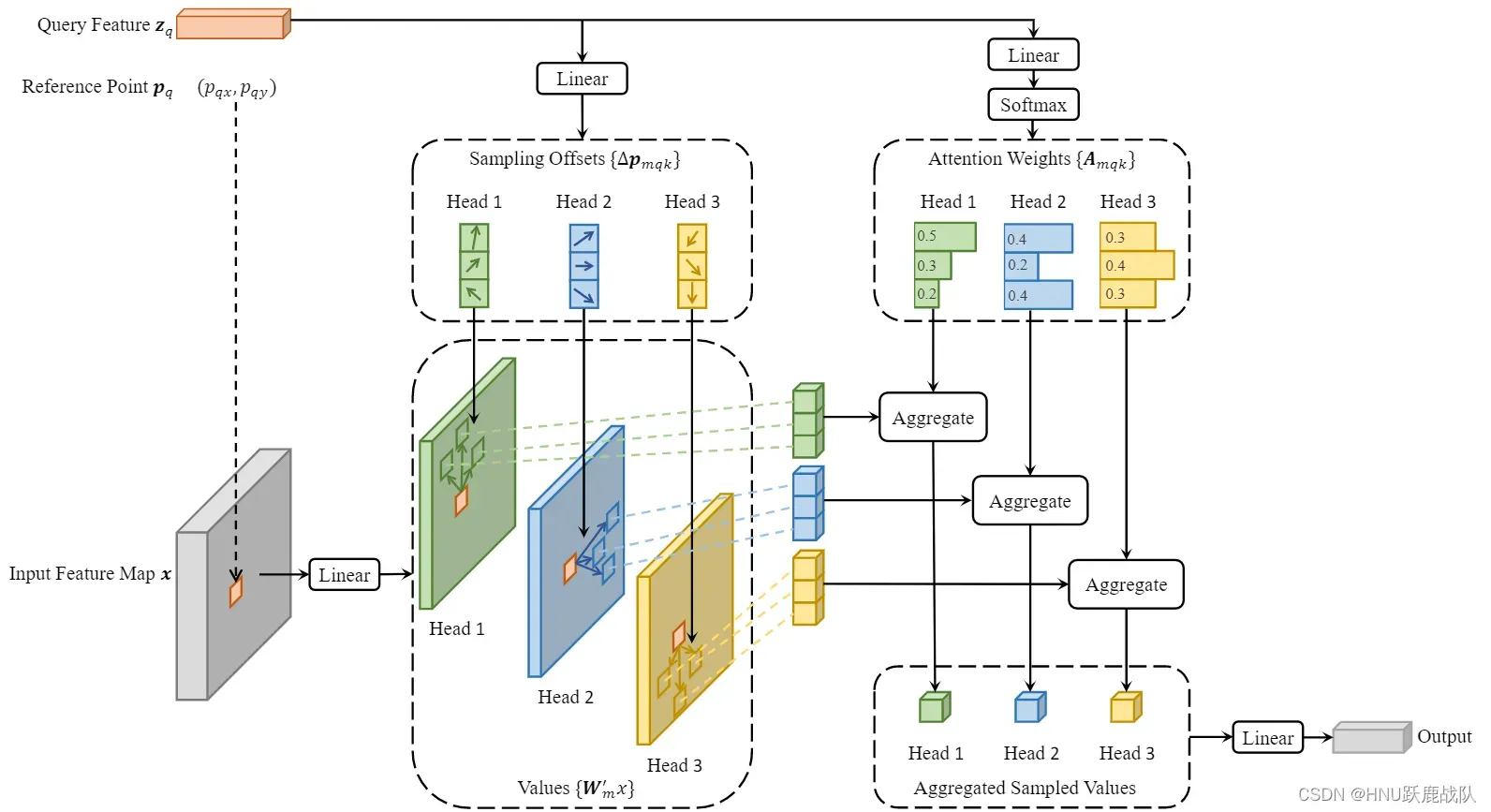
Deformable Attention模块
feature map通过简单的线性变换生成Value,Query feature同样经过线性变换生成数个头的注意力偏移量和每个位置注意力的权重,最后将那些位置的feature采集起来并乘以权重得到最后的输出。可以看到上图中Reference Point在Input Feathre Map上的位置已经用相同的粉色标记了出来。
通过替换全局的自注意力,时间复杂度下降到,其中k为偏移量的个数,也就是用于和query point计算相关性的点的个数。此时,虽然自注意力是”局部“的,但是deformable attention仍然可以通过学习大的offsets从而计算两个相离很远的像素的相关性,这里的”局部“应该作”部分“或者”稀疏“来理解,而不是像卷积一样定域的。
由于encoder不再是transfomer一样处理序列化的数据的结构,这里的编码器反倒和Vision Attention的计算非常相似,颇有折衷的感觉,这也说明CNN和Transformer架构处在不断地相互学习和融合的过程中。从他的架构上我们还可以看出DDETR在Encoder结构上显式地建模了多尺度特征的融合,而不像DETR一样只使用的CNN backbone的最后一层输出。至于Decoder,还是使用传统的全局自注意力,将Encoder的最后一层输出序列化后融入自己每一层的V和K矩阵中(同样是element-wise add),第一层的输入同样是一个需要训练的Object Query。这里的特征数量已经没有原来这么多,因此处理速度还可以接受。
关于具体的实现细节,作者开源了代码,请参考:GitHub/Deformable DETR: Deformable Transformers for End-to-End Object Detection.
最后的最后,大家可以参照这篇文章:目标检测模型的评测与训练技巧,总结的非常好强烈推荐(虽然是两年多前的文章了但是还是非常棒,不过没怎么涉及到细节而是从宏观的角度上复盘了几年来目标检测的发展。建议作为复习或者扩展再自己详细查找相关资料)。如果能看懂/概览里面的内容并且没有任何压力说明你已经悄悄入门目标检测了。而这两年来的发展,主要是对于标签分配、anchor的思考和backbone的优化与训练调优等,单阶段和两阶段网络的差异被进一步模糊,Transfomer架构也在CV领域大放异彩,更多的细节和内容就需要读者自己查阅资料了解了。
神经网络-卷积网络-检测网络部分至此在已经编写的内容中占了整个教程一半的篇幅(43206词),希望读者有所收获有所创作。至于分割任务和视频分析等,在比赛中用的比较少,在此不过多赘述。不过目标检测和图像分类作为CV的基石,许多trick和模块都是和其他任务相似的。有了目标检测的基础,相信你在其他任务的学习上也不会遇到什么困难。
理论部分到此结束,网络检测的实践将在第6章再次展开!
如果觉得作者的文笔还不错,请点赞关注!
过滤器和状态估计的内容将在下一期更新,用于装甲板运动预测和数据平滑过滤。
版权声明:本文为博主HNU跃鹿战队原创文章,版权归属原作者,如果侵权,请联系我们删除!