


类别:“机器学习中的数学”总目录
有时我们需要计算输入和输出都为向量的函数的所有偏导数。包含所有这样的偏导数的矩阵被称为Jacobian矩阵。具体来说,如果我们有一个函数

有时,我们也对导数的导数,二阶导数感兴趣。例如,有一个函数
在一维情况下,我们可以将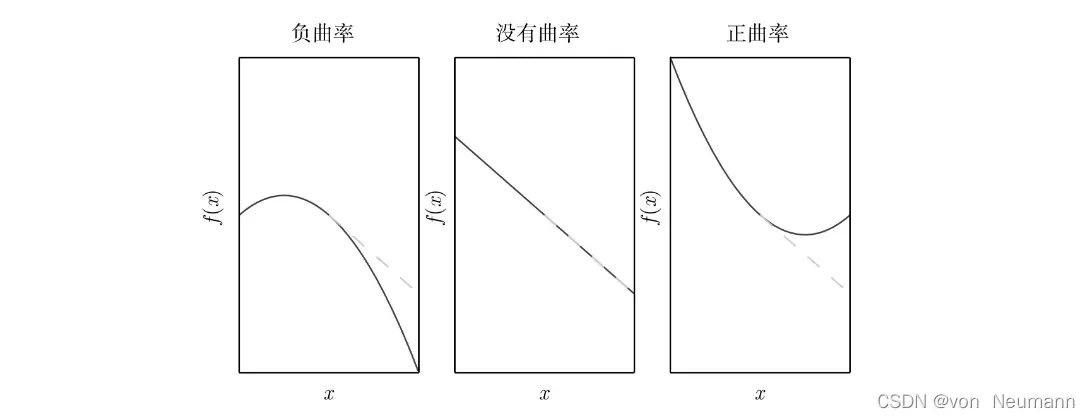
当我们的函数具有多维输入时,二阶导数也有很多。我们可以将这些导数合并成一个矩阵,称为Hessian矩阵:

Hessian等价于梯度的Jacobian矩阵。微分算子在任何二阶偏导连续的点处可交换,也就是它们的顺序可以互换:
这意味着
其中有3项:函数的原始值、函数斜率导致的预期改善和函数曲率导致的校正。当最后一项太大时,梯度下降实际上是可能向上移动的。当
最坏的情况下,
在多维情况下,我们需要检测函数的所有二阶导数。利用Hessian的特征值分解,我们可以将二阶导数测试扩展到多维情况。在临界点处(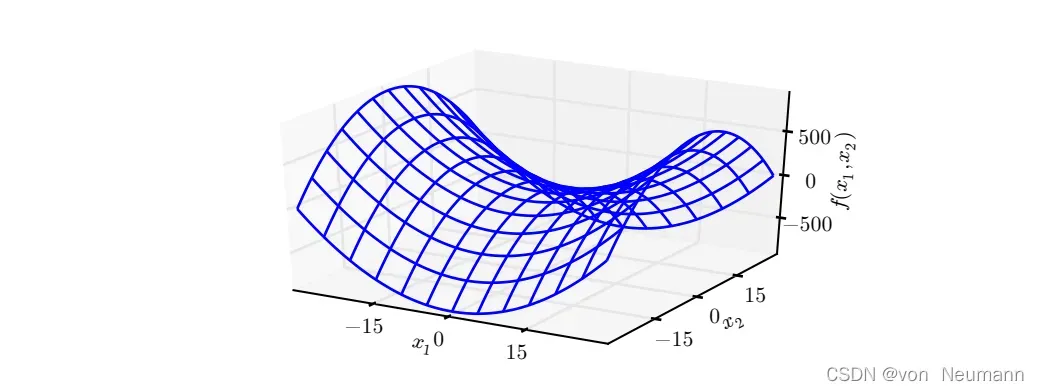
多维情况下,单个点处每个方向上的二阶导数是不同的。Hessian的条件数衡量这些二阶导数的变化范围。当Hessian的条件数很差时,梯度下降法也会表现得很差。这是因为一个方向上的导数增加得很快,而在另一个方向上增加得很慢。梯度下降不知道导数的这种变化,所以它不知道应该优先探索导数长期为负的方向。病态条件也导致很难选择合适的步长。步长必须足够小,以免冲过最小而向具有较强正曲率的方向上升。这通常意味着步长太小,以至于在其他较小曲率的方向上进展不明显,如下图所示: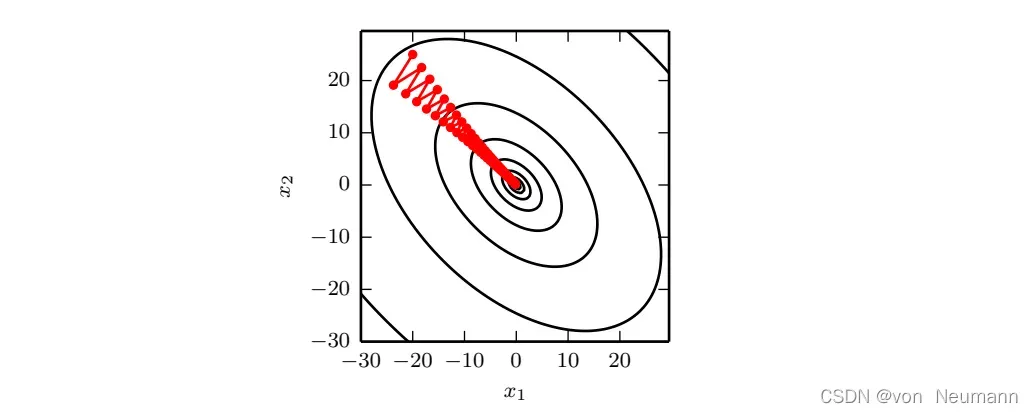


我们可以使用Hessian矩阵的信息来指导搜索,以解决这个问题。其中最简单的方法是牛顿法(Newton’smethod)。牛顿法基于一个二阶泰勒展开来近似
通过计算,我们可以得到这个函数的临界点:
如果
仅使用梯度信息的优化算法称为一阶优化算法,如梯度下降。使用Hessian矩阵的优化算法称为二阶最优化算法,如牛顿法。大多数优化算法适用于各种各样的函数,但几乎都没有理论保证。因为在深度学习中使用的函数族是相当复杂的,所以深度学习算法往往缺乏理论保证。在许多其他领域,优化的主要方法是为有限的函数族设计优化算法。在深度学习的背景下,限制函数满足Lipschitz连续或其导数Lipschitz连续可以获得一些保证。Lipschitz连续函数的变化速度以Lipschitz常数
这个属性允许我们量化自己的假设——梯度下降等算法导致的输入的微小变化将使输出只产生微小变化,因此是很有用的。Lipschitz连续性也是相当弱的约束,并且深度学习中很多优化问题经过相对较小的修改后就能变得Lipschitz连续。最成功的特定优化领域或许是凸优化。凸优化通过更强的限制提供更多的保证。凸优化算法只对凸函数适用,即Hessian处处半正定的函数。因为这些函数没有鞍点而且其所有全局极小点必然是全局最小点,所以表现很好。然而,深度学习中的大多数问题都难以表示成凸优化的形式。凸优化仅用作一些深度学习算法的子程序。凸优化中的分析思路对证明深度学习算法的收敛性非常有用,然而一般来说,深度学习背景下凸优化的重要性大大减少。
版权声明:本文为博主von Neumann原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/hy592070616/article/details/123148633