1.引言
在深度学习领域,损失函数定义了模型的预测值与目标值之间的距离。所以我们必须正确选择它,只有这样所有参数才会根据它们的值进行更新。损失函数的选择取决于模型的设计。
在这篇文章中,我们主要讨论两个常见的任务,即回归和分类。
2.回归损失
这里我们从损失函数的计算公式及其背后的数学开始。接下来,我们提供一些可视化的例子,让理论知识更清晰,让我们对它有更深入的理解。
2.1 MSE Loss
Mean Square Error (MSE) 是回归任务中最通用的损失函数,MSE是目标值与预测值之间差值平方和的均值,MSE的公式定义如下: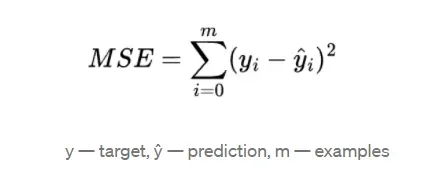
优势:
- 易于引导
- 有解析解
- 预测值越接近真实值,梯度越小
缺点:
- 对异常值不稳健
正如我们所了解到的一样,MSE 总体上对预测错误的情形进行了严厉的惩罚,但这是一把双刃剑,假如我们训练数据中存在较大的异常值,此时我们将会有一个巨大的权重更新,这有可能会使模型失去平衡。
MSE简单的可导性使它成为一种非常流行的损失函数,我们可以在一些回归问题中找到它。
2.2 MAE Loss
Mean Absolute Error (MAE) 是目标值与预测值差的绝对值之和的均值。MAE的公式定义如下: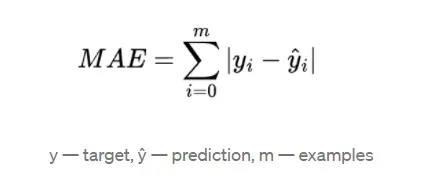
优势:
- 对异常值鲁棒
缺点:
- 无解析解
- 所有预测误差具有相同的梯度幅度值
MAE 是目标和预测值之间差异的绝对值。这个函数的主要问题是它实际上没有解析解。
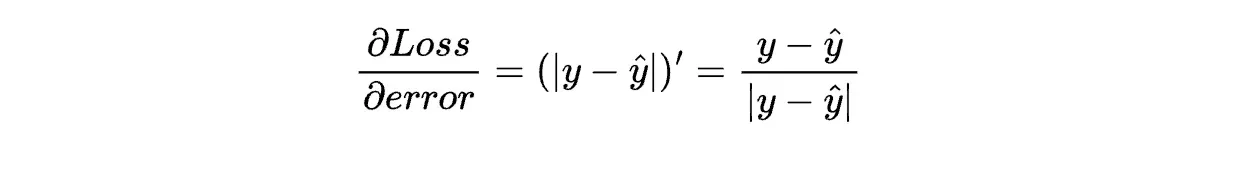
如上述公式所示,对于预测错误时,反传的梯度值为 1 或 -1。这意味着无论误差有多大,我们都会用相同的值更新权重。
MSE损失函数的明显用途是回归问题,但它也用于其他领域 比如在CycleGAN论文中,它用作一致性损失主要是用来计算原始图像和重新生成的图像之间的差异性。
2.3 Pseudo-Huber Loss
Pseudo-Huber Loss损失函数的定义如下: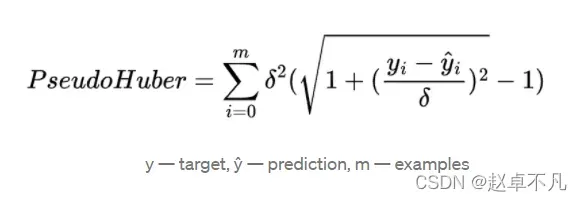
优势:
- 对异常值鲁棒
- 有解析解
缺点:
- 需要对delta参数进行微调
Pseudo-Huber损失函数是MAE函数的鲁棒性和 MSE的实际现有解的结合体。该损失函数还有一个附加参数 delta,主要用于控制函数从二次到线性切换的位置。此外该参数还用于剪裁梯度值,从而可以限制异常值的影响。
当delta=5时Pseudo-Huber函数的图像和导数图像,如下所示: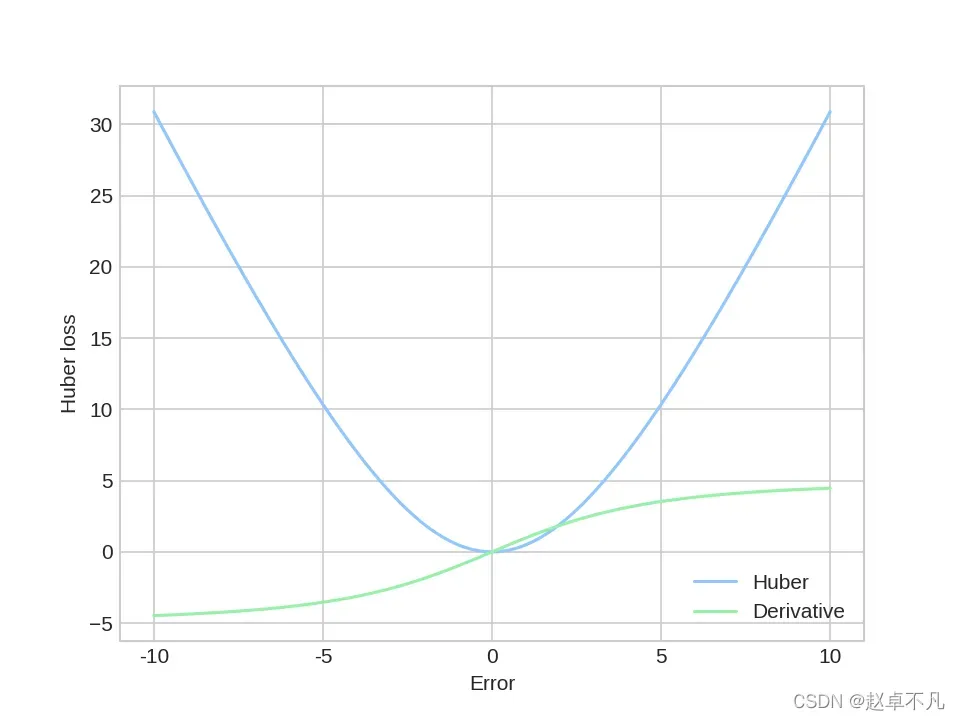
由于具有裁剪梯度的能力,Pseudo-Huber损失函数被用于Fast R-CNN模型中,以防止梯度爆炸。
2.4 对比
了解了一些理论之后,我们举个栗子,对比一下上面的函数。
下图中,蓝线上的采样点为我们的真值,红色x为我们的预测值。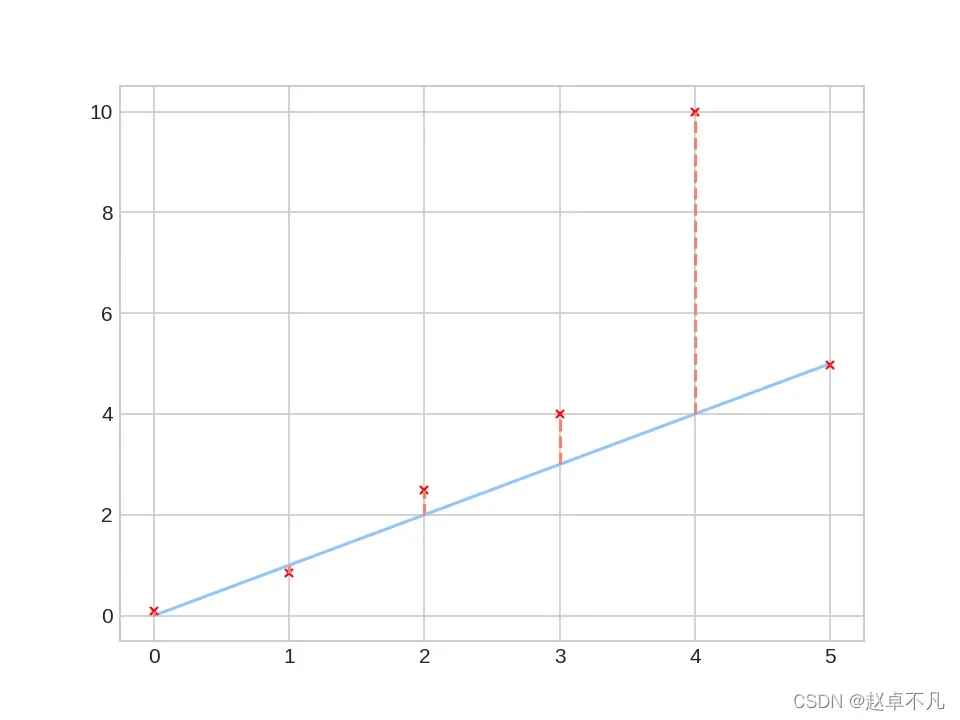
接下来我们看看不同损失函数的计算值: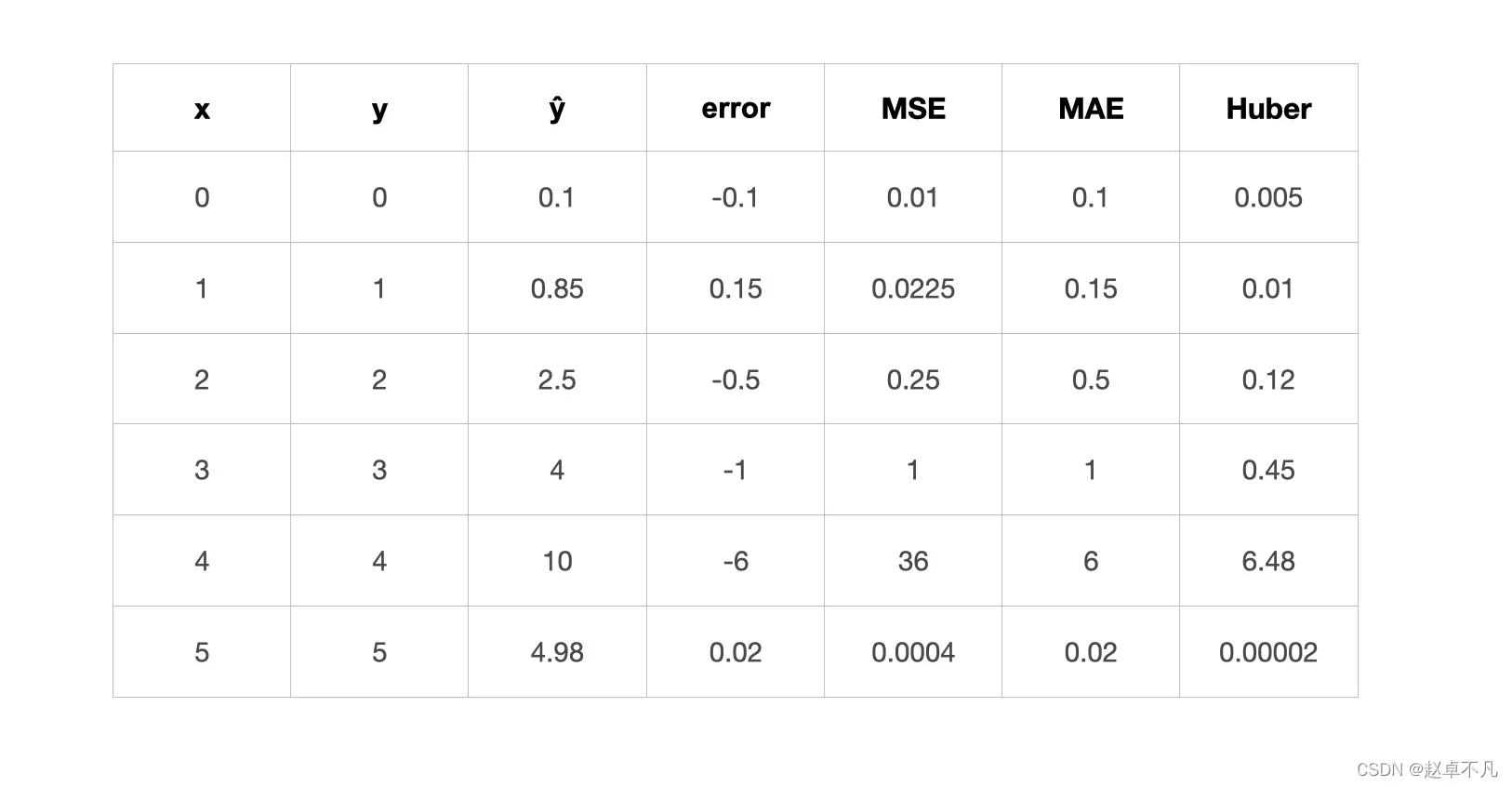
如上所示,Pseudo-Huber损失函数显示具备MAE LOSS对异常值的鲁棒性以及MSE LOSS对预测值越接近真值梯度越小的特性。
3.分类损失
3.1 Categorical Cross Entropy Loss
CCE损失函数的定义如下: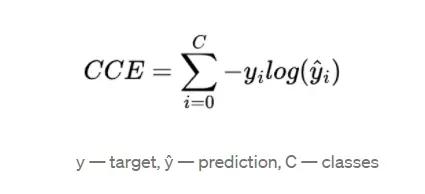
优势:
- 严重惩罚错误的预测
- 能很好地解决多类问题
接下来让我们创建一个简单的多类预测模型来对猫、汽车和犀牛进行分类,看看它在实践中是如何工作的。
如上所示,分类交叉熵损失侧重于期望的输出并严重惩罚错误的预测。当我们查看其功能图时,此时它变得更加直观。如下: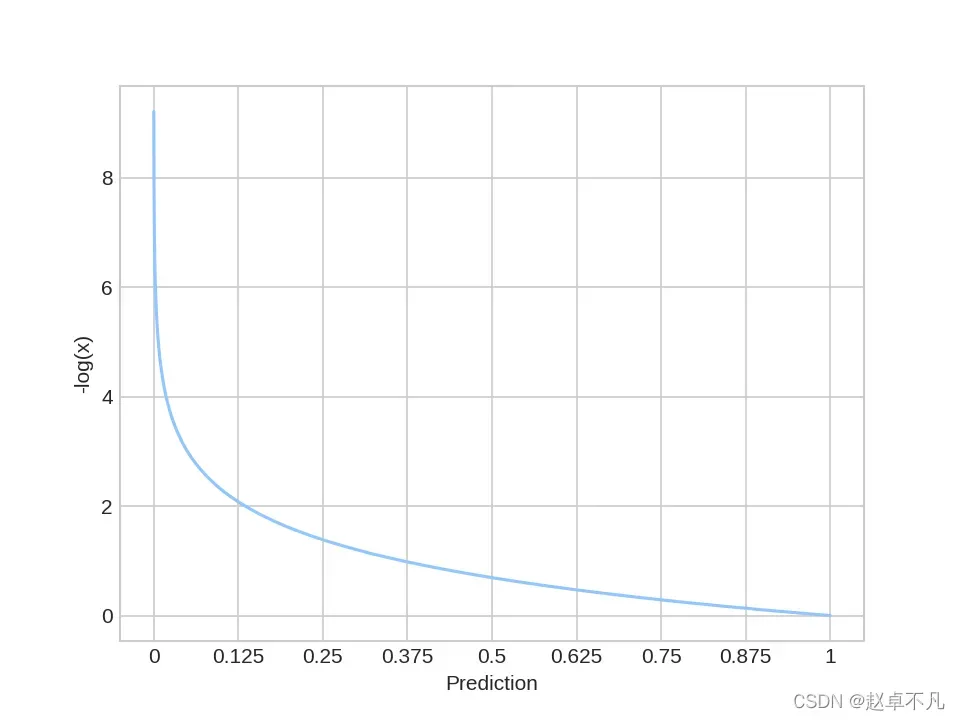
CCE LOSS是大多数多分类问题的首选损失函数
3.2 Binary Cross-Entropy
BCE损失函数的定义如下:
优势:
- 适用于多标签问题和二元分类
BCE损失函数的工作原理类似于类别交叉熵损失函数。它以指数方式惩罚错误的预测。主要区别在于应用场景, BCE 主要用于多标签分类,其输入可以属于多个类别。最简单的例子是比如像蜘蛛侠这样的电影,它可以同时被归类为动作、冒险、奇幻和科幻类型。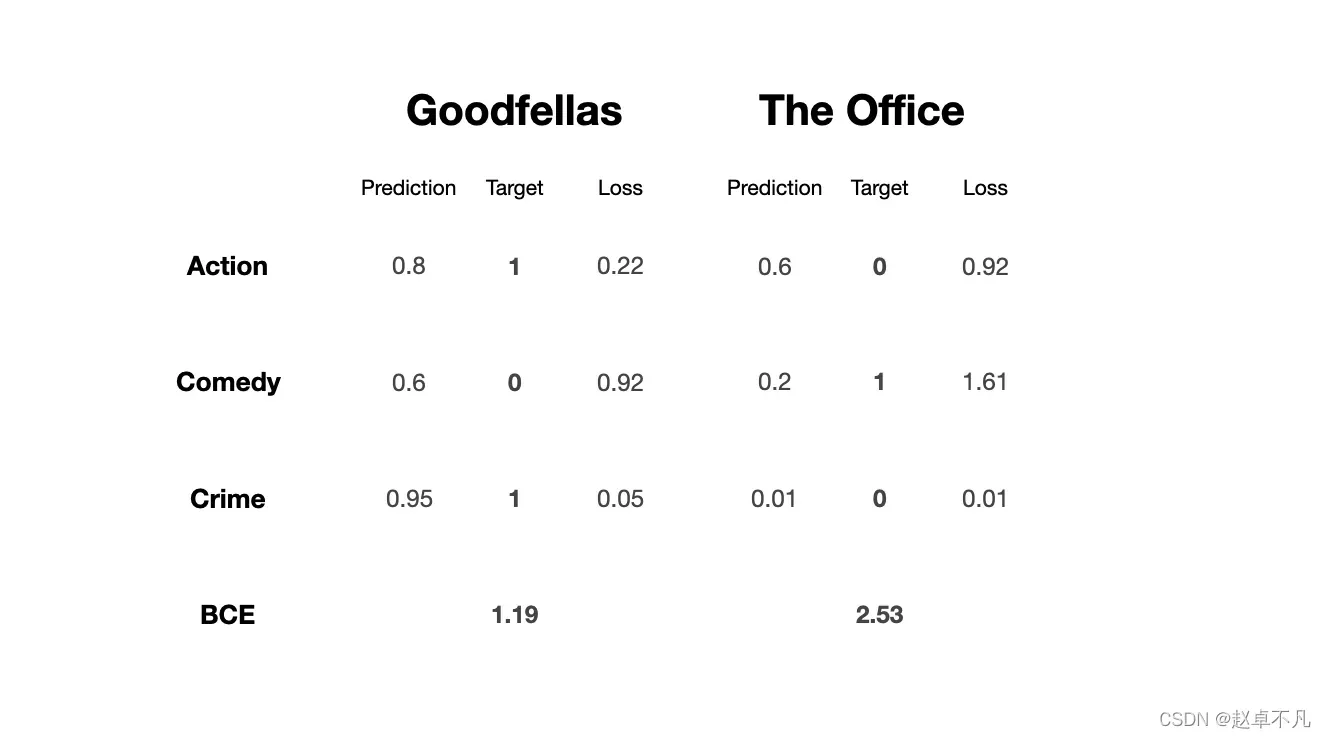
在学习了CCE损失之后,BCE损失应该非常直观。它们的工作原理相同,但应用场景不同。
3.3 KL-pergence Loss
KL-散度损失函数的定义如下: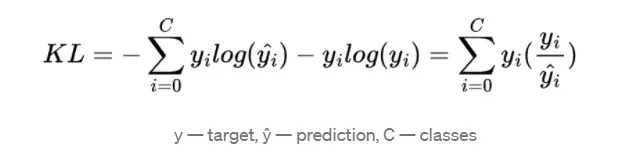
优势:
- 适用于逼近复杂的目标分布,例如图像
如上所示,KL 散度损失是从我们网络预测的交叉熵分布与目标分布的熵之间的差异。它告诉我们模型离期望的分布有多远。
那么我们应该什么时候使用它呢?
想象一下,如果我们的任务是生成图像,那么目标分布要复杂得多。在这种情况下,KL 散度损失的效果最好。
4.总结
损失函数是深度学习相关问题的核心组成部分,主要用于评估模型的性能并相应地更新权重。
通过这篇文章,希望你能了解具体损失函数的优缺点,以及应该在哪些场景下使用。
参考
关注公众号《AI算法之道》,获取更多AI算法资讯。
版权声明:本文为博主赵卓不凡原创文章,版权归属原作者,如果侵权,请联系我们删除!