研究背景:
1. 当前生成对抗网络在许多图像任务中取得了不错的效果,但是需要大量的训练数据;
2. 目前关于小数据集的训练存在判别器容易过拟合的问题;
革新:
本文主要研究在有限数据集训练下判别器的过拟合问题,并引入多互补判别器,在训练过程中从不同角度提供监督信息。主要表现在两个方面:权重差异和数据差异。
网络结构:
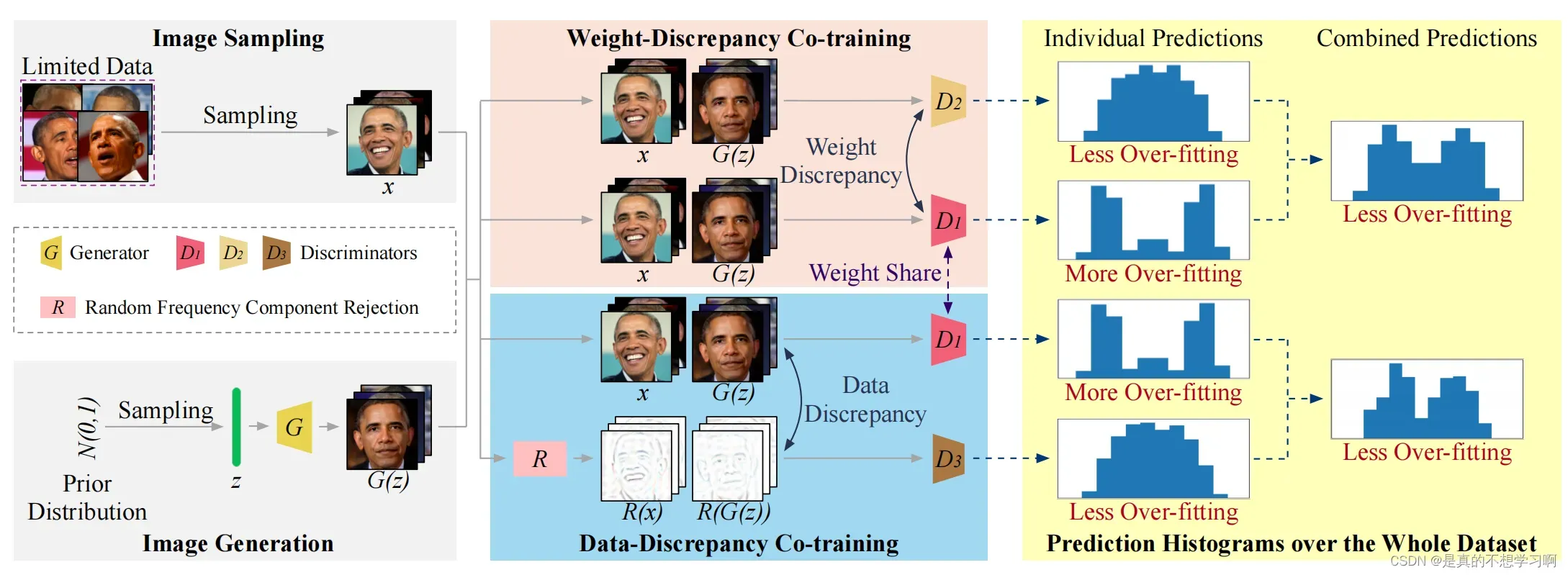 论文的网络结构主要包括四部分:采样、生成、权重差异协同训练和数据差异协同训练。为了解决小数据集上判别器过拟合的问题,本文提出了权重差和数据差。
论文的网络结构主要包括四部分:采样、生成、权重差异协同训练和数据差异协同训练。为了解决小数据集上判别器过拟合的问题,本文提出了权重差和数据差。
Weight-Discrepancy Co-training(WeCo):
WeCo的目的是通过两个判别器D1和D2的参数,采用参数多样化的想法,作者定义了权重差异损失,提取两个判别器的参数计算其余旋距离,其计算公式如下所示:
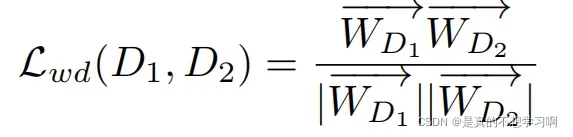
Lwd计算的是两组参数的余旋夹角,值越小,夹角越大,说明两组参数的距离越远,这在一定程度上抑制了判别器的过拟合。因为当一个趋于过拟合状态时候,权重差异损失会减缓另一个判别器的过拟合。
D1和D2的损失函数计算如下所示,关于权重差异损失加在D1项和D2项都没有什么区别。
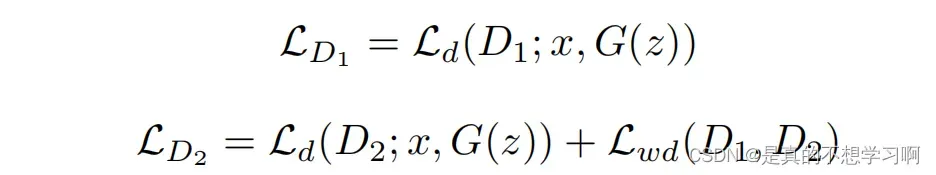
其中,Ld为判别损失:
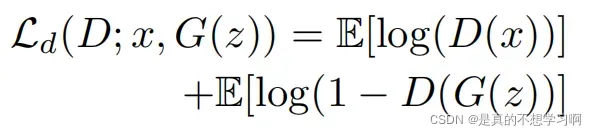
最后,WeCo总的损失为:
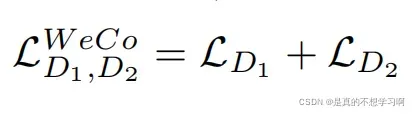
论文代码关于权重差异损失Lwd的计算如下:
W5 = None
W6 = None
for (w5, w6) in zip(self.D.parameters(), self.D2.parameters()):
if W5 is None and W6 is None:
W5 = w5.view(-1)
W6 = w6.view(-1)
else:
W5 = torch.cat((W5, w5.view(-1)), 0)
W6 = torch.cat((W6, w6.view(-1)), 0)
loss_weight = (torch.matmul(W5, W6) / (torch.norm(W5) * torch.norm(W6)) + 1) Data-Discrepancy Co-training(DaCo):
DaCo训练是从图像不同的视角进行协同判别,采用了D1和D3两个判别器,D1判别器和WeCo中的判别器是参数共享的,D3以原图的部分频率分量为输入(partial frequency components)。D1和D3的判别损失如下:
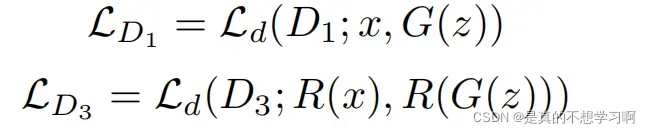
DaCo的总损失:
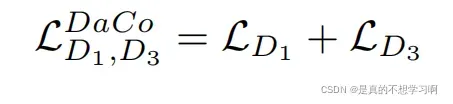
为什么GenCo是有效的?
1. GenCo在训练的过程中,即使一个判别器出现了过拟合,但是由于其他的判别器具有不同的参数和输入信息,其会去学习更加复杂的结构信息等,如下图,论文作者可视化了三个判别器学习的重点信息分布,从图中可以看出,三个判别器学习到的信息是互补的。图中,D1更多注意面部的风格,如:颜色、亮度等;D2更多注意在面部的细节,如:皱纹、面部轮廓等;D3注意在面部的表情,如:眼睛、嘴巴等。

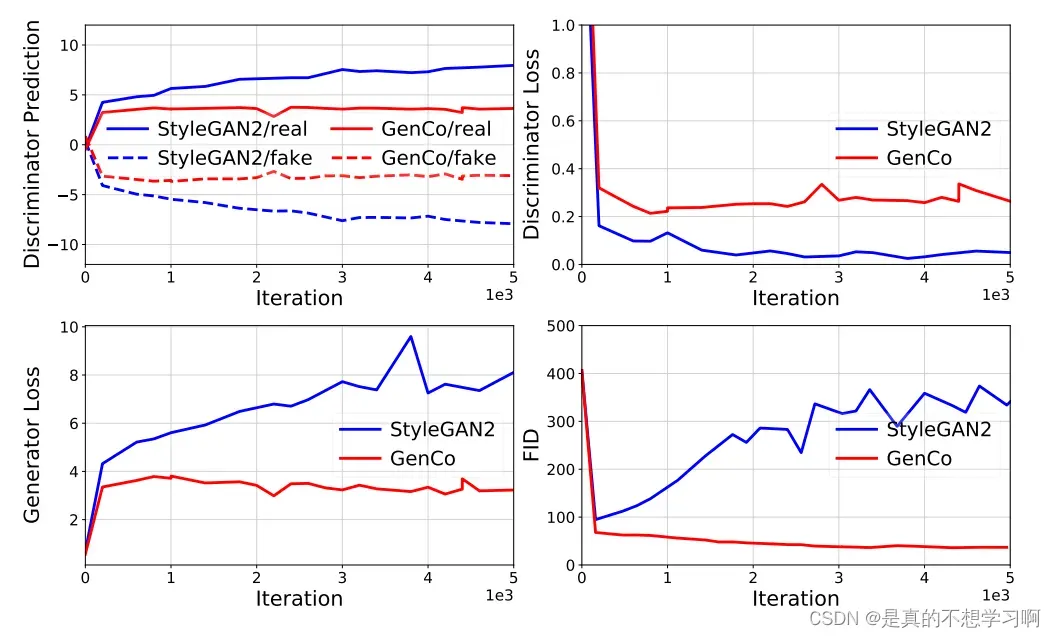
2. 文章作者分析了,当判别器损失较小时会使生成器的损失较大,导致训练处于发散状态。如下图所示。文章的WeCo和DaCo减小了判别器的过拟合,减小了生成器的损失,缓解了训练过程中的发散问题。
论文实验:
论文作者提供大量的实验及评价指标验证了GenCo的有效性。主要在CI-FAR,100-shot,AFHQ, FFHQ and LSUN-Cat数据集上进行了实验。
Experments on 100-shot and AFHQ:
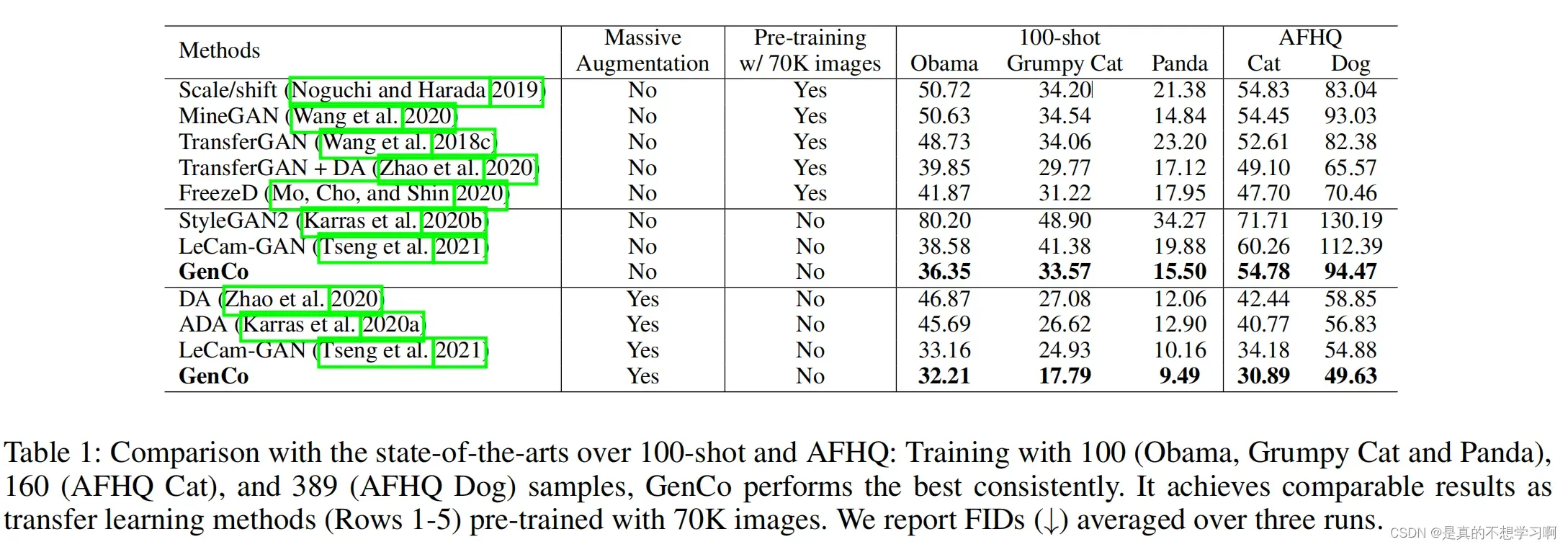
从表1可以看出,GenCo的FID分数优于现有的先进方法。

从图3的视觉结果可看出,GenCo在使用数据增强的情况下,生成结果的真实性明显由于DA的结果。
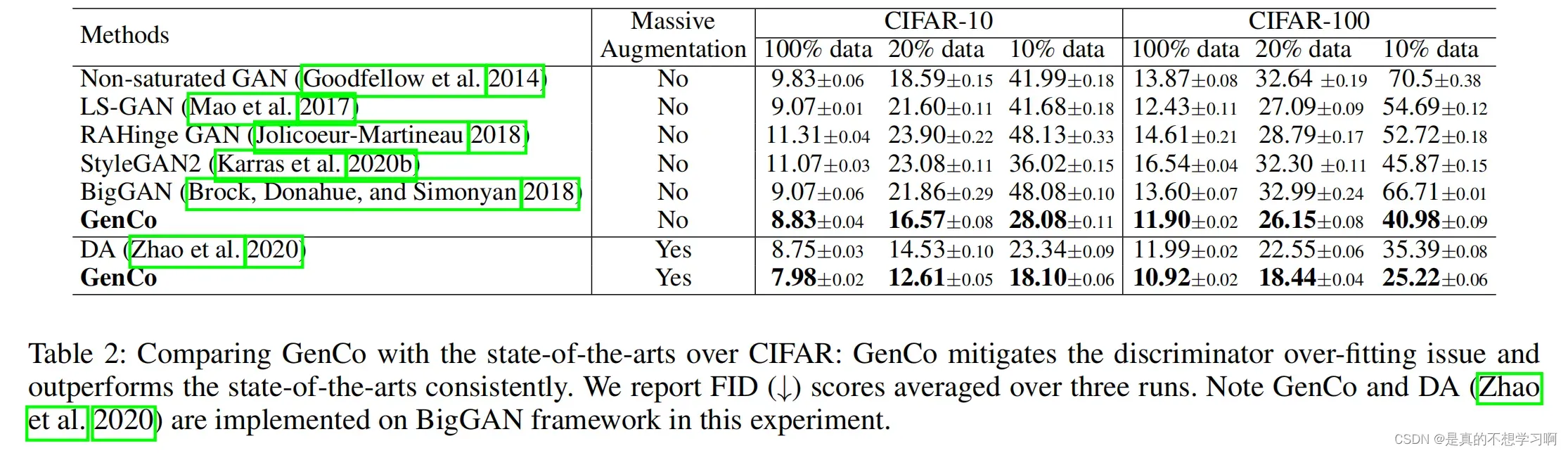
Experiments on CIFAR-10 and CIFAR-100:
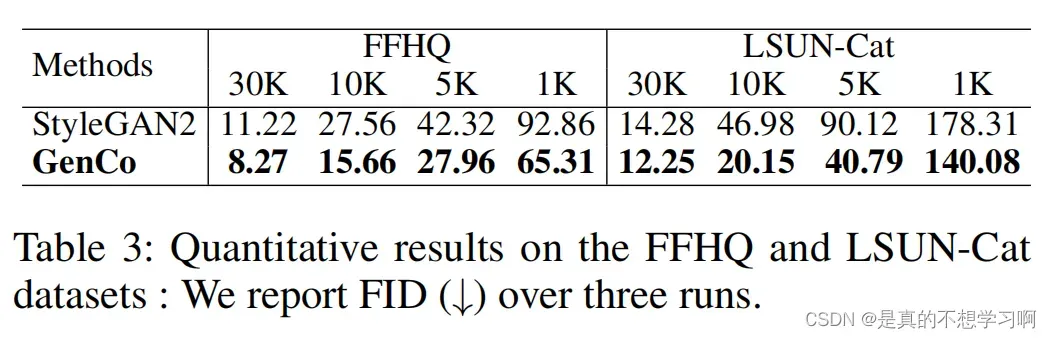
Experiments on FFHQ and LSUN-Cat:
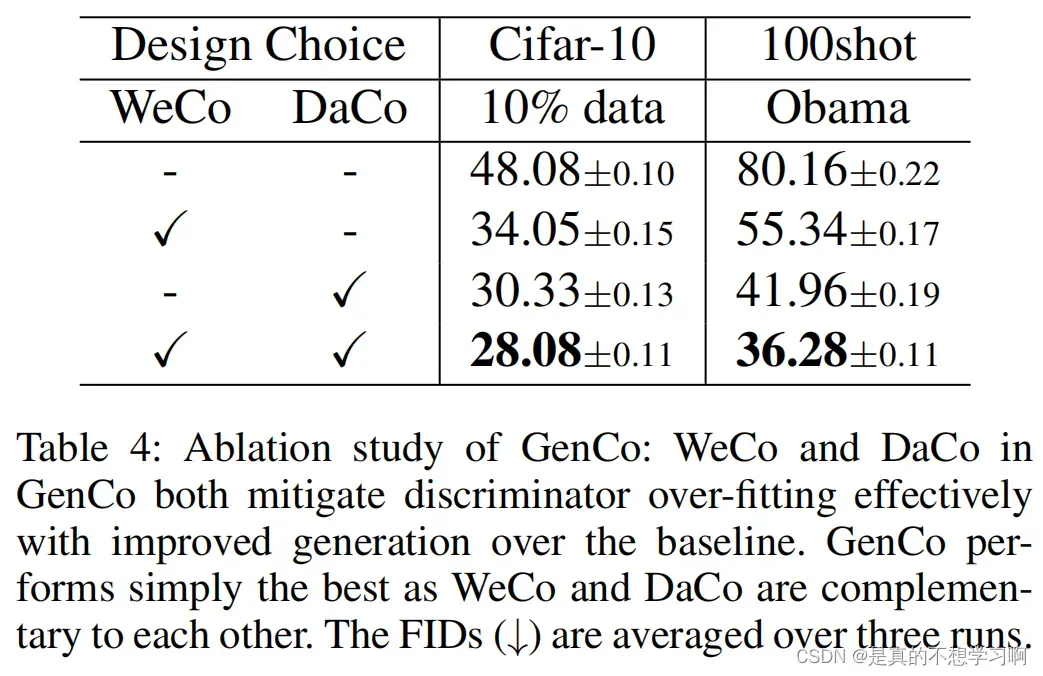
Ablation study:

讨论:
论文不仅在不同的数据集和评价指标上进行了实验展示,用于也将GenCo的方法与正则化技术进行组合,得到了不错的效果,加入GenCo以后基线模型的效果有了很大的提升。
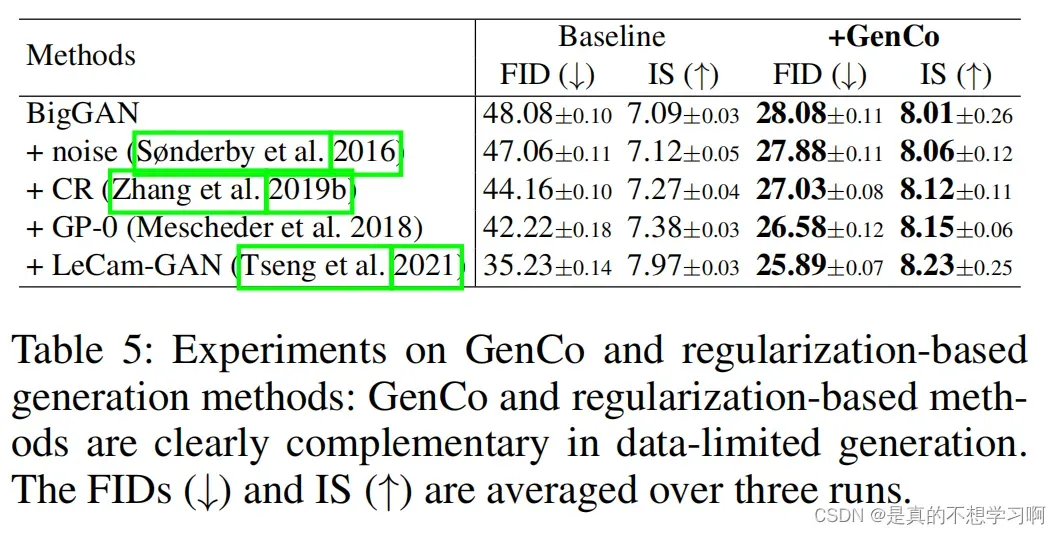
作者还将GenCo应用在不同的基线模型上,验证了GenCo的优越性。
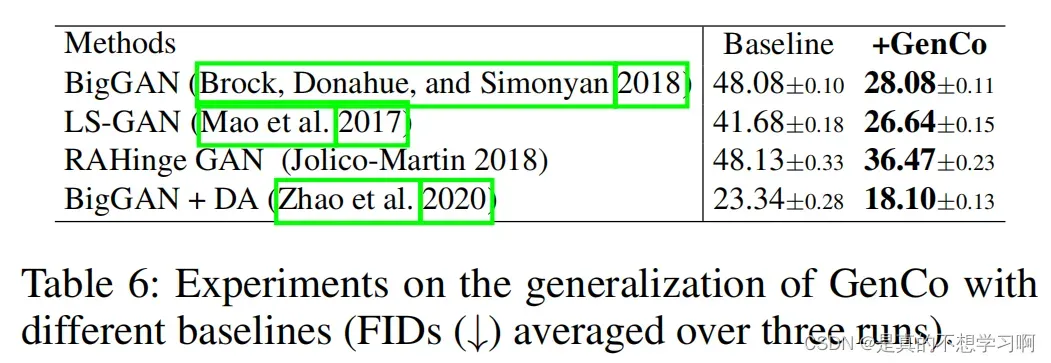
总结:
1. D1、D2、D3关注的信息不同,相当于提升网络整体的判别能力;
2. 论文从不同的基线模型和数据集上验证了GenCo的有效性,实验展示丰富;
版权声明:本文为博主是真的不想学习啊原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42019320/article/details/123199786