实验 1:PyTorch 使用简介
一、实验介绍
1.1 实验内容
Pytorch 是由Facebook 支持的一套深度学习开源框架,相比较 Tensorflow, 它更加容易快速上手,所以一经推出就广受欢迎。本课程是采用 Pytorch 开源框架进行案例讲解的深度学习课程。Tensor(张量)是 PyTorch 的基础数据结构, 自动微分运算是深度学习的核心。在本实验中我们将学习 PyTorch 中Tensor 的用法,以及简单的自动微分变量原理,最后,我们还会使用 PyTorch 构建一个简单的线性回归网络。
1.2 实验知识点
- PyTorch 简介
- PyTorch 中的张量及其运算
- PyTorch 中的自动微分运算
- 用 PyTorch 实现线性回归
1.3 实验环境
- Python3.9
- PyTorch1.10.2
- pycharm
二、有关张量(Tensor)运算的练习
2.1 使用Tensor
PyTorch 是一个开源的深度学习框架,由 Facebook 支持开发。它的前身为Torch,但因为 Torch 使用的编程语言是 Lua,在国内流行度很小。Facebook 为了迎合数量更多的 Python 用户的需求,推出了 PyTorch。PyTorch 完全开源意味着你可以轻易获取它的代码,并按照自己的需求对它进行修改。比如让 PyTorch 支持复数运算等等。PyTorch 还有另外一个非常出众的特点是,使用 PyT orch 框架编写出的神经网络模型的代码非常简洁。实现同样的功能,使用 PyTorch 框架编写的代码往往更清晰明了
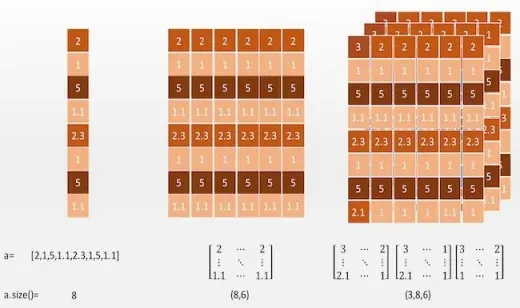
1 阶的张量可以看做是一个向量,通过索引可以取到一个“值”。
2 阶张量可以看做为一个矩阵,通过索引可以取到一个个的向量。
3 阶张量有点抽象,不过我们可以从图中看出,3 阶张量其实就是在 2 阶张量的矩阵中增加了一个深度。也就是说在 3 阶张量中我们可以通过索引取到一个个的矩阵。我们不难想象,4 阶张量也就是在 3 阶张量上增加了另外一个轴……我们可以使用 **Tensor.size()**方法获得一个张量的“尺寸”。在这里注意“尺寸”和维度是两个概念。就比如对于上图中的 1 阶张量,它的维度为 1,尺寸为 8; 对于上图中的 2 阶张量,它的维度为 2,尺寸为(8,6)。
要使用 PyTorch,首先需要在 Python 中引入 PyTorch 的包
import torch
# 计算机视觉软件包
import torchvision
# torch 版本
print(torch.__version__)
# 计算机视觉软件包版本
print(torchvision.__version__)
# 是否有GPU 及其版本
print(torch.cuda.is_available())
print(torch.version.cuda)
'''1.10.2
0.11.3
True
11.3'''
# 没有数据的创建选项:
# print(torch.eye(2))
# print(torch.zeros(2, 2))
# print(torch.ones(2, 2))
# print(torch.rand(2, 2))
'''tensor([[1., 0.],
[0., 1.]])
tensor([[0., 0.],
[0., 0.]])
tensor([[1., 1.],
[1., 1.]])
tensor([[0.3657, 0.9712],
[0.9962, 0.9617]])'''
2.2 基本 Tensor 运算
# 创建一个5*3的全1矩阵
y = torch.ones(5, 3)
print(y)
# 计算两个矩阵相加
z = x + y
print(z)
# 矩阵转置
print(y.t())
# 矩阵相乘
print(x.mm(y.t()))
# 点乘
print(x*y)
转置操作可以用.t()来完成,也可以用 transpose(0,1)来完成。
2.2 Tensor 与 numpy.ndarray 之间的转换
PyTorch 的Tensor 可以与Python 的常用数据处理包Numpy 中的多维数组进行转换。
import torch
import numpy as np
# 为深度学习创建PyTorch张量-最佳选择
# Tensor与tensor区别: 区别是:默认数据类型与指定的数据类型。
data = np.array([1, 2, 3])
# 另外一种转换 Tensor 的方法,为 torch.FloatTensor(data)
t1 = torch.Tensor(data)
t2 = torch.tensor(data)
t3 = torch.as_tensor(data)
t4 = torch.from_numpy(data)
# print(t1)
# print(t2)
# print(t3)
# print(t4)
# print(t1.dtype)
# print(t2.dtype)
# print(t3.dtype)
# print(t4.dtype)
'''tensor([1., 2., 3.])
tensor([1, 2, 3], dtype=torch.int32)
tensor([1, 2, 3], dtype=torch.int32)
tensor([1, 2, 3], dtype=torch.int32)
torch.float32
torch.int32
torch.int32
torch.int32'''
# tensor 转化为 numpy 的多维数组
print(t1.numpy())
'''[1. 2. 3.]'''
Tensor 和 Numpy 的最大区别在于 Tensor 可以在 GPU 上进行运算。
默认情况下,Tensor 是在 CPU 上进行运算的,如果我们需要一个 Tensor
在 GPU 上的实例,需要运行这个 **Tensor 的.cuda()**方法。
在下面的代码中,首先判断在本机上是否有 GPU 环境可用(有 NVIDIA 的GPU,并安装了驱动)。如果有 GPU 环境可用,那么再去获得张量 x,y 的 GPU 实例。注意在最后打印 x 和 y 这两个 GPU 张量的和的时候,我们调用了.cpu() 方法,意思是将 GPU 张量转化为 CPU 张量,否则系统会报错。
import torch
x = torch.rand(5, 3)
y = torch.ones(5, 3)
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
z = x+y
print(z)
print(z.cpu())
'''tensor([[1.4453, 1.6272, 1.3072],
[1.9444, 1.2703, 1.8512],
[1.8694, 1.1878, 1.8789],
[1.5737, 1.8825, 1.4636],
[1.8158, 1.9969, 1.8819]], device='cuda:0')
tensor([[1.4453, 1.6272, 1.3072],
[1.9444, 1.2703, 1.8512],
[1.8694, 1.1878, 1.8789],
[1.5737, 1.8825, 1.4636],
[1.8158, 1.9969, 1.8819]])'''
三、有关自动微分(Autograd)变量的练习
动态运算图(DynamicComputationGraph)是 PyTorch 的最主要特性,它可以让我们的计算模型更灵活、复杂,并可以让反向传播算法随时进行。而反向传播算法就是深度神经网络的核心。
下面是一个计算图的结构以及与它对应的 PyTorch 代码:

import torch
from torch.autograd import Variable
N, D = 3, 4
# 产生标准正态分布的随机数或矩阵的函数 randn
x = Variable(torch.randn(N, D), requires_grad=True)
y = Variable(torch.randn(N, D), requires_grad=True)
z = Variable(torch.randn(N, D), requires_grad=True)
a = x*y
b = a+z
c = torch.sum(b)
c.backward()
print(x.grad)
print(y.grad)
print(z.grad)
用来构建计算图的数据叫做自动微分变量(Variable),它与 Tensor 不同。每个 Variable 包含三个属性,分别对应着数据(data),父节点(creator), 以及梯度(grad)。其中**“梯度”就是反向传播算法所要传播的信息**。而父节点用于将每个节点连接起来构建计算图(如上图所示)。
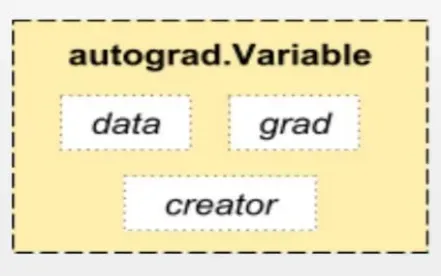
下面我们编写代码来实际使用自动微分变量。
import torch
# 导入自动梯度运算包,主要用Variable这个类
from torch.autograd import Variable
# 创建一个Variable ,包裹了2*2张量,将需要计算梯度属性置为True
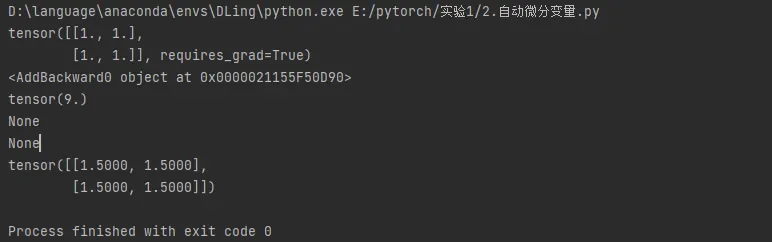
x = Variable(torch.ones(2, 2), requires_grad=True)
print(x)
y = x+2
# 每个Variable都有一个creator (创造者节点)
print(y.grad_fn)
z = torch.mean(y*y)
# .data 返回z包裹的Tensor
print(z.data)
# backward 可以实施反向传播算法,并计算所有计算图上叶子节点(没有子节点)的导数(梯度)信息。
# 注意,由于 z 和 y 都不是叶子节点,所以都没有梯度信息。
z.backward()
print(z.retain_grad())
print(y.retain_grad())
# z对x的倒数
print(x.grad)
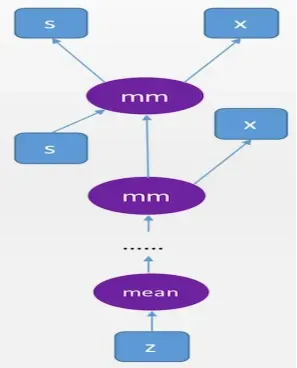
import torch
from torch.autograd import Variable
s = Variable(torch.FloatTensor([[0.01, 0.02]]), requires_grad=True)
x = Variable(torch.ones(2, 2), requires_grad=True)
for i in range(10):
s = s.mm(x)
z = torch.mean(s)
z.backward()
print(x.grad)
print(s.grad)
# s.grad 为None (s不是叶节点,没有梯度信息)
然后我们得到一个复杂的“深度”计算图:
四、实验总结
在本节实验中,熟悉了张量、自动微分变量的用法,认识了 PyTorch 中的计算图。
版权声明:本文为博主D之光原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/li520_fei/article/details/123179475