pandas简介
Pandas是基于NumPy的一种工具,Numpy是为了解决数据分析任务而创建的。在使用panda之前,需要安装Numpy。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集(Dataset)所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
pandas贯穿着整个数据分析过程的学习,为我们提供了数据结构和函数的设计,用于文件的读写,数据整理,数据分析,使表格化的工作快速、简单、表现有力。所以使用Pandas进行数据操作、预处理、清洗是Python数据分析中的重要技能。
pandas的数据结构
常见的数据存储形式有Excel和数据库两种,其对比如下:
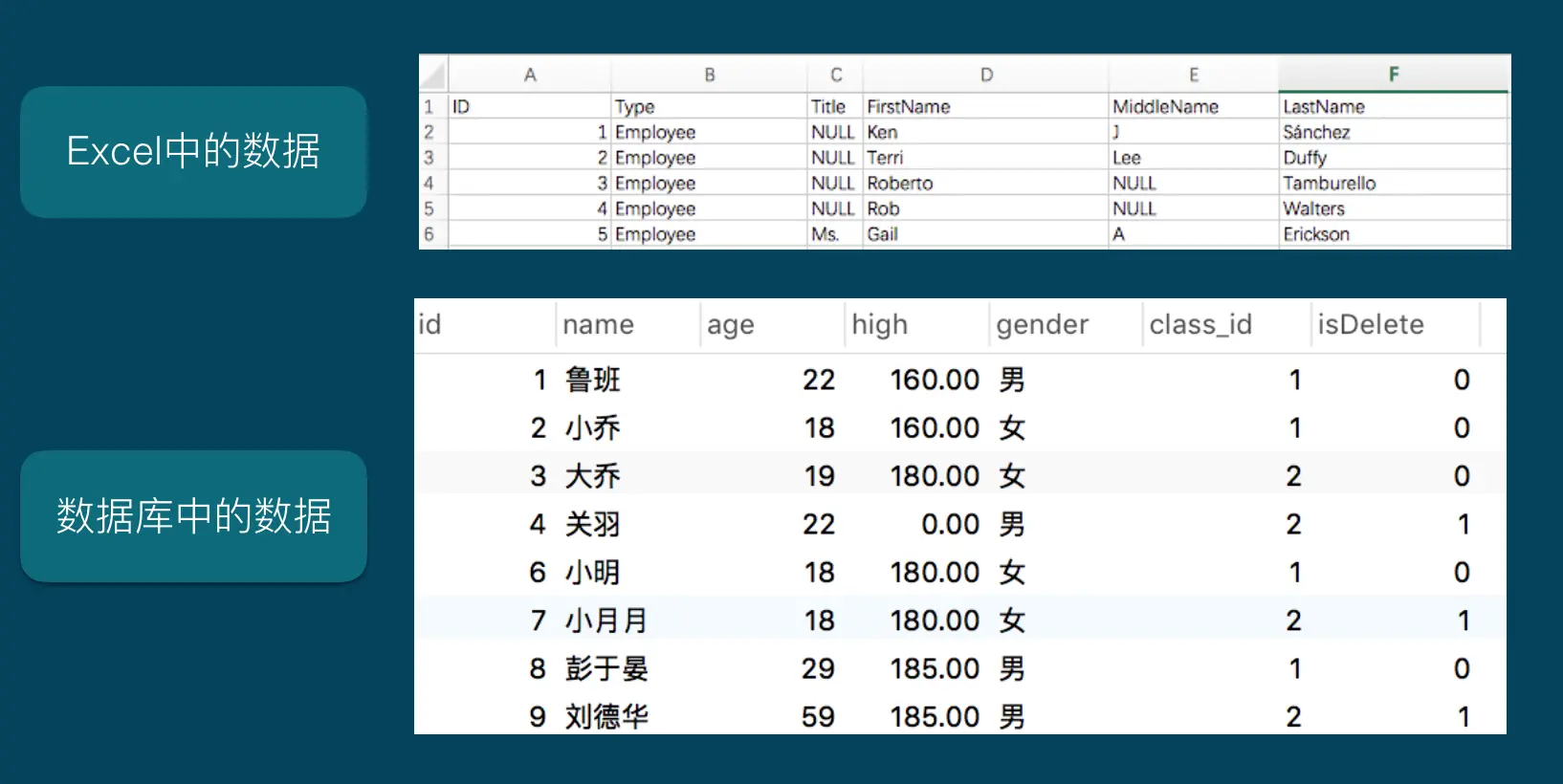
从中可以看出,这两种存储方式都是表格样式的,有行、有列,并且每一行和每一列都有自己的索引,可以方便我们获取数据。每一行的数据其实就是存储的一条完整的数据信息,而pandas的DataFrame,也拥有由相同的结构,每一行的内容体现为一组Series,下面进行举例:
import pandas as pd
#通过Series存储几个人的基本信息
s1 = pd.Series([1001,'张三','18','150.00','男'])
s2 = pd.Series([1002,'李四','19','167.00','女'])
s3 = pd.Series([1003,'王五','30','180.00','男'])
s4 = pd.Series([1004,'赵六','20','160.00','女'])
s5 = pd.Series([1005,'孙七','22','165.00','男'])
# 将五个人的信息存储为一个新列表,如果将si看做是元素,
# 这个新列表可以理解成一个行向量
series_list=[s1,s2,s3,s4,s5]
# 将列表转换为数据集(Dataset)的结构,类似于对行向量进行转置
df=pd.DataFrame(series_list)
# 打印刚刚构造的DataFrame
print(df)
运行结果如图:

可以根据打印结果进一步解析DataFrame的结构:
DataFrame结构与Excel表格非常像,每一行都存储了一组完整的信息,每一列的数据类型都相同。由于我们没有定义行列索引,因此系统自动分配了默认值,以方便更好地使用数据。
构建数据表的类简单介绍
我们在使用pandas构建数据表时,常常会用到的类有含Series和DataFrame,接下来我们先简单介绍一下这两个类的构建数据表的初始化方法。
Series创建方法
Series是Pandas中最基本的对象,因此它也是基于Numpy的。Numpy是用于处理大型矩阵(matrix)的工具,所以Series创建的元素拥有一维行向量的特征就不足为奇了。但是,Series与Numpy有所不同,它可以为数据定义标签,也就是索引。这个索引可已有系统分配,也可以我们自行定义:
from pandas import Series
# Series可以使用两个参数,其中index参数对应的数组存储值就是索引。
sel = Series(data=[1,'2140',22,'优秀研究生'],
index = ['排名','ID号','年龄','评语'])
# “data=”与“index=”不写也不会影响运行结果,但为了代码的可读性,我们不做省略
print(sel)
观察一下运行结果:

这个结果的出现不免让人有些疑惑。刚才我们使用Series创建的内容,明明是一个一维行向量,可到这里却变成列向量了。这是不是因为我们添加了索引才引发的问题呢?为了解决疑问,我们将刚才的数据也加上索引看看:
import pandas as pd
s1 = pd.Series(data=[1001,'张三','18','150.00','男'],
index = ['ID','name','age','high','sex'])
s2 = pd.Series([1002,'李四','19','167.00','女'])
s3 = pd.Series([1003,'王五','30','180.00','男'])
s4 = pd.Series([1004,'赵六','20','160.00','女'])
s5 = pd.Series([1005,'孙七','22','165.00','男'])
series_list=[s1,s2,s3,s4,s5]
df=pd.DataFrame(series_list)
print(df)
运行一下:
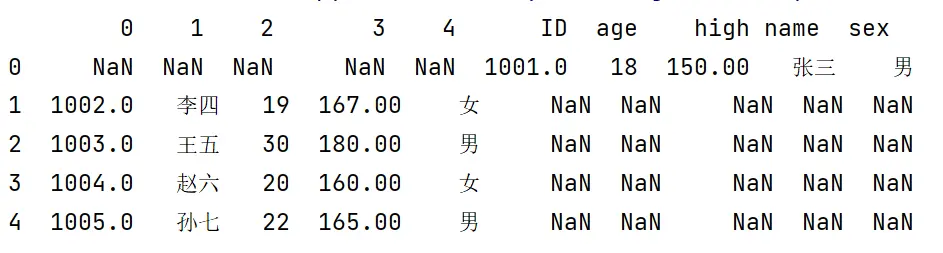
很尴尬的结果,可以看出,我们加的索引是列索引,但是被放到了系统分配的索引后面,并且数据位置也都没有匹配。实际上,我们在生成表格的时候,每一行的每个元素都要与索引进行一 一对应,即data内的数据要与index内的数据对应,但是刚刚的代码,s1是和自定义的索引对应的,而s2到s5没有指明,因此默认和系统生成的索引对应,也就出现了这种结果。
想要解决这个问题,可行的办法目前只有在s2到s5中,也加入“index = [‘ID’,‘name’,‘age’,‘high’,‘sex’]”:
import pandas as pd
s1 = pd.Series(data=[1001,'张三','18','150.00','男'],
index = ['ID','name','age','high','sex'])
s2 = pd.Series([1002,'李四','19','167.00','女'],
index = ['ID','name','age','high','sex'])
s3 = pd.Series([1003,'王五','30','180.00','男'],
index = ['ID','name','age','high','sex'])
s4 = pd.Series([1004,'赵六','20','160.00','女'],
index = ['ID','name','age','high','sex'])
s5 = pd.Series([1005,'孙七','22','165.00','男'],
index = ['ID','name','age','high','sex'])
series_list=[s1,s2,s3,s4,s5]
df=pd.DataFrame(series_list)
print(df)
运行结果为:
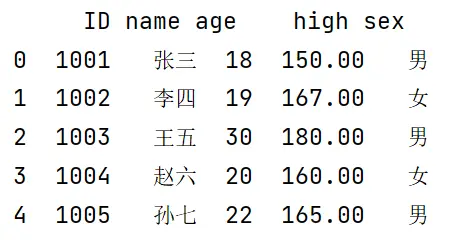
运行结果和我们想的一样。可以看到,我们生成的索引确实是列索引,s1到s5也都还是行向量。因此可以得出结论:当使用Series构建一个只有一行元素的表格时,打印出来的结果呈现的是列向量的形状。这个结论在很多类似情况下也都成立。
DataFrame创建方法
DataFrame,中文名为数据表,是一种2维数据结构,数据以表格的形式存储,分成若干行和列。通过 DataFrame可以很方便地处理数据。DataFrame拥有三个参数:data,index和columns,分别代表了数据、行索引和列索引。
注意:DataFrame添加索引时,index代表的是行索引,这一点区别于Series。
调用DataFrame()可以将多种格式的数据转换为DataFrame对象,在数据查找查找等功能上非常高效。细心的小伙伴可能已经发现,在之前的代码中我们已经在最后打印之前使用了到了DataFrame了,但是添加索引的工作是由Series完成的,较为麻烦。那么我们接下来看看如何使用DataFrame添加索引:
import pandas as pd
s1 = [1001,'张三','18','150.00','男']
s2 = [1002,'李四','19','167.00','女']
s3 = [1003,'王五','30','180.00','男']
s4 = [1004,'赵六','20','160.00','女']
s5 = [1005,'孙七','22','165.00','男']
list=[s1,s2,s3,s4,s5]
df=pd.DataFrame(data = list,
columns = ['ID','name','age','high','sex'],
index = ['a','b','c','d','e'])
print(df)
看看结果:
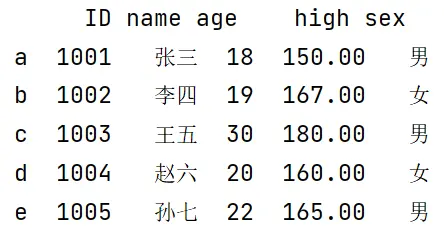
这样构建数据表,代码简洁了许多,数据表也更完整了。当然,为了使用方便,我们还可以用字典的格式为数据表添加列索引,如下所示:
import pandas as pd
dic = {'ID':[1001,1002,1003,1004,1005],
'name':['张三','李四','王五','赵六','孙七'],
'age':['18','19','30','20','22'],
'high':['150.00','167.00','180.00','160.00','165.00'],
'sex':['男','女','男','女','男']}
df=pd.DataFrame(data = dic
index = ['a','b','c','d','e'])
print(df)
让我们看一下运行结果:
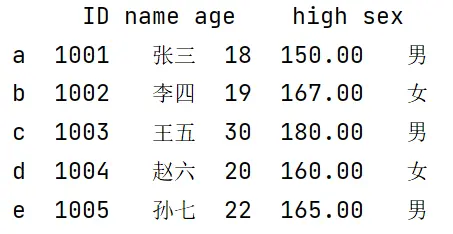
这也是一种按列键入的构成表格的方法。
表格内容的查找方法
上文中,我们已经介绍了两个常用类的初始化方法,但仅仅创建数据表这个功能对于我们来说还是远远不够的。Series和DataFrame还有许多方法可以完成我们更多的需求。下面我们做一个对Series和DataFrame类的较深度的解析:
揭秘Series
基本取值方法
使用Series创建的数组,可以使用很多函数提取我们想要的内容,比如values(获取数据值)、index(获取索引值)、items(获取每对索引和值)等Series的属性可以帮助我们获取各部分的或全部的数据。但是要格外注意使用不同方法时对输出类型的差异。
现在,拿出我们之前构建的表尝试一下:
from pandas import Series
sel = Series(data=[1,'2140',22,'优秀研究生'],
index = ['排名','ID号','年龄','评语'])
# 获取数据值
print(sel.values,'\n')
# 获取索引值
print(sel.index.tolist(),'\n')
# 获取每对索引和值
print(sel.items)
看看运行结果:

如果我们想把索引和值制作成列表格式输出还可以做以下改动:
print(list(sel.items()))
修改后的结果为:
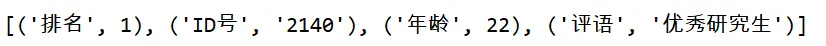
实际上,values、index、items返回的对象分别是List、Index、Zip类型,而为了方便我们使用和观察数据,以上的代码分别使用了series.index.tolist()和list(series.items())方法将结果转化成了List类型。
实际上,sel.tiems()的返回值为sel的地址,因此使用循环也可以从这个地址中取到内容:
for val in sel.items:
print(val)
另外,这种方法也可以用于DataFrame的取值之中。感兴趣的小伙伴可以自己试一下
“消失”的默认索引
通过以上的例子不难看出,通过Series构成的数据集(Dataset)和list类型非常相似,简直像是可外加索引的list类型。实际上,除了外表的相似,这两者之间获取内容的方法也十分相似。比如通过索引值访问元素、切片选择多个数据:
from pandas import Series
sel = Series(data=[1,'2140',22,'优秀研究生'],
index = ['排名','ID号','年龄','评语'])
# 通过索引找到某个元素
print(sel['评语'])
# 通过索引找到多个元素
print(sel[['排名','评语']])
# 切片索引进行查找
print(sel['排名':'年龄'])
一定要仔细观察代码哦,这里的格式还是有很多细节的。下面看看结果:
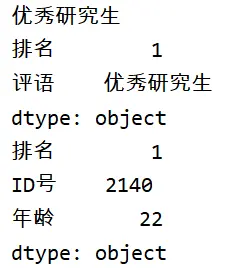
既然这么像数组,那么就有一个问题需要大家思考:搜索列表元素依据的下标是默认存在的,那么Series构建的数据集(Dataset)是不是也有一个默认存在的“下标”呢?当然有,那就是默认索引。其实,我们添加的索引只是显示上对默认索引进行了覆盖,实际上,就和下标一样,默认索引是一直都存在的,因此,我们就依然可以依据默认索引的值进行检索:
from pandas import Series
sel = Series(data=[1,'2140',22,'优秀研究生'],
index = ['排名','ID号','年龄','评语'])
# 通过索引找到某个元素
print(sel[3])
# 通过索引找到多个元素
print(sel[[0,3]])
# 切片索引进行查找
print(sel[0:2])
让我们看看结果:

基本和之前根据自定义索引操作得到的结果一样。但是,如果使用默认索引对[n:N]进行切片的话,只可以拿到n到N-1的数据,这一点是和用自定义索引取值有区别的。
当然,我们也可以用循环来遍历数据表,方法如下:
from pandas import Series
sel = Series(data=[1,'2140',22,'优秀研究生'],
index = ['排名','ID号','年龄','评语'])
for index,value in list(sel.items()):
print(index,value)
用这样的方法可以根据我们的需要遍历索引和值,当然,也可以调用keys方法遍历索引:
for val in sel.keys():
print(val)
或者用这样的方法拿到值:
for val in sel:
print(val)
大家可以自己尝试。
揭秘DataFrame
以上我们分析了Series穿件的数据表,但是发现了一些问题,Series只能创建一行带有索引的数据,因此打印出来通常是列的形式,相当于在对一维行向量进行操作,没有很好体现数据表的二维性。接下来我们研究DataFrame类型:
对于一个DataFrame类型来说,我们需要知道的基本信息有:表格的维度、行列数以及行列索引。想要获取以上的内容,就需要使用一些函数:
import pandas as pd
s1 = [1001,'张三','18','150.00','男']
s2 = [1002,'李四','19','167.00','女']
s3 = [1003,'王五','30','180.00','男']
s4 = [1004,'赵六','20','160.00','女']
s5 = [1005,'孙七','22','165.00','男']
list=[s1,s2,s3,s4,s5]
df=pd.DataFrame(data = list,
columns = ['ID','name','age','high','sex'],
index = ['a','b','c','d','e'])
print(df.shape) # 获取数据表的行数以及列数
print(df.index.tolist()) # 获取数据表的航索引
print(df.columns.tolist()) # 获取数据表的列索引
print(df.ndim) # 获取数据维度
让我们看看结果:
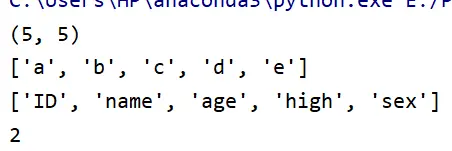
当我们想要查看列表的结构,但是列表的数据量太大,不方便全部打印出来的话,我们还可以用到这两个函数:
print(df.head(2)) # 打印数据表前两行
print(df.tail(2)) # 打印数据表后两行
大家可以自己运行一下,看看结果如何。
还需要提醒大家一下,这两个方法有默认参数,其值为5。如果表格不足五行,那么就会全部输出。
接下来我们讨论如何有针对性的获取数据:
我们创建的df是一个类似于二维列表的数据类型,因此对它的取值也和对列表的取值有几分相像,比如:
print(df[1:3]) # 获取第2到3行数据
print(df['name']) # 获取列索引为name的一列数据
print(df[['name','age']]) # 获取列索引name和age列的两列数据
print(df[1:3][['name','age']]) # 获取几行数据的name和age列的两列数据
先看看结果:
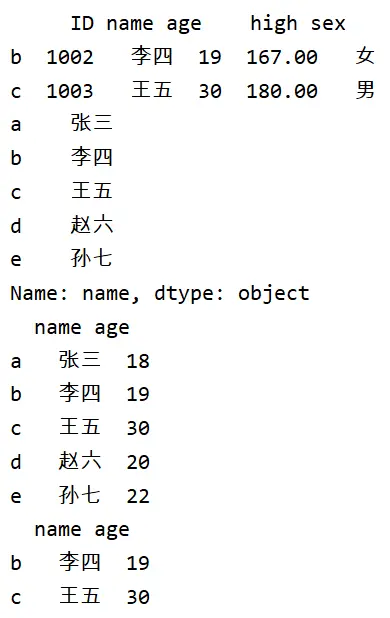
这些方法有一些值得注意的点,首先,这样取值的方法里,是不能通过
print(df[0])
这样的语句输出第一行的数据的,计算机会报错。我们想要拿到第一行的数据应该借用切片,可以写成:
print(df[0:1])
要记住切片法是不会输出结尾的那一行的。比如df[0:3],拿到的就是第一行(计算机编号是0的那一行)到第3行(计算机编号是2的那一行)。至于计算机编号为3的第四行则不会输出。这个规律在对列切片时依旧适用,在后面会讲到的loc和iloc两种方法中也适用。
其次,虽然有依据两个数字选取连续多行的方法,但是想要选取连续多列,只能够把每一列的索引都告诉计算机,比如我们要查看name、age、high三列的数据,那么就需要用以下代码:
print(df[['name','age','high']])
一定要注意,用双中括号,要区别于取单列;另外这种方式并不可以依据位置索引取行数据,比如df[‘001’],这种写法计算机不认识。最后,如果我们想取某几行的某几列,就需要杂交一下。
这种取值方式多少会让我们有些疑惑,毕竟局限性还是蛮高的,有没有什么方式能够弥补这些不足吗?
loc方法
loc的功能是通过行标签索引筛选。当然,搭配列索引筛选对于它来说也是非常容易的。还是使用之前构建的数据表举例:
print(df.loc['a']) # 以列的形式输出a行,输出结果里没有行索引a
print(df.loc[['a','c']]) # 输出第a行和第c行,输出结果带有行索引a和c
print(df.loc['a':'c']) # 输出a行到c行,输出结果包含行索引a到c
print(df.loc['a','name']) # 输出a行name列数据
print(df.loc[['a','c'],['name','high']]) # 输出a和c行name列和high列数据
print(df.loc['a':'c','name':'high']) # 输出a行name列到high列数据
print(df.loc['a',:]) # 输出a行所有列,效果同print(df.loc['a'])
下面看看结果:

这种方法就可以很好的解决刚刚的问题,但需要注意格式,取单独几行几列要用中括号括起来并以逗号隔开,取连续多行列只需冒号隔开。
iloc方法
iloc方法可以通过行位置索引进行筛选,其写法与loc大同小异,只需把标签索引换成位置索引即可:
print(df.iloc[1])
print(df.iloc[[1,3]])
print(df.iloc[1:3])
print(df.iloc[1,1])
print(df.iloc[[1,3],[1,3]])
print(df.iloc[1:3,1:3])
print(df.iloc[1,:])
这里的注意事项和loc非常相似,就不做赘述了,大家可以自行尝试。
版权声明:本文为博主有理想的打工人原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/weixin_54929649/article/details/121365231