01a
import numpy as np
import src.util as util
def calc_grad(X, Y, theta):
"""Compute the gradient of the loss with respect to theta."""
m, n = X.shape
margins = Y * X.dot(theta)
probs = 1. / (1 + np.exp(margins))
grad = -(1./m) * (X.T.dot(probs * Y))
return grad
def logistic_regression(X, Y):
"""Train a logistic regression model."""
m, n = X.shape
theta = np.zeros(n)
learning_rate = 1
i = 0
while True:
i += 1
prev_theta = theta
grad = calc_grad(X, Y, theta)
theta = theta - learning_rate * grad
if i % 10000 == 0:
print('Finished %d iterations' % i)
if np.linalg.norm(prev_theta - theta) < 1e-15:
print('Converged in %d iterations' % i)
break
return
def main1():
print('==== Training model on data set A ====')
Xa, Ya = util.load_csv('./data/ds1_a.csv', add_intercept=True)
logistic_regression(Xa, Ya)
print('\n==== Training model on data set B ====')
Xb, Yb = util.load_csv('./data/ds1_b.csv', add_intercept=True)
logistic_regression(Xb, Yb)
main1()
==== Training model on data set A ====
Finished 10000 iterations
Finished 20000 iterations
Finished 30000 iterations
Finished 40000 iterations
Finished 50000 iterations
Finished 60000 iterations
Finished 70000 iterations
Finished 80000 iterations
Finished 90000 iterations
Finished 100000 iterations
Finished 110000 iterations
Finished 120000 iterations
Finished 130000 iterations
Finished 140000 iterations
Finished 150000 iterations
Finished 160000 iterations
Finished 170000 iterations
Finished 180000 iterations
Finished 190000 iterations
Finished 200000 iterations
Finished 210000 iterations
Finished 220000 iterations
Finished 230000 iterations
Finished 240000 iterations
Finished 250000 iterations
Finished 260000 iterations
Finished 270000 iterations
Converged in 278192 iterations
==== Training model on data set B ====
Finished 10000 iterations
Finished 20000 iterations
Finished 30000 iterations
Finished 40000 iterations
Finished 50000 iterations
Finished 60000 iterations
Finished 70000 iterations
Finished 80000 iterations
Finished 90000 iterations
Finished 100000 iterations
Finished 110000 iterations
Finished 120000 iterations
Finished 130000 iterations
Finished 140000 iterations
Finished 150000 iterations
Finished 160000 iterations
Finished 170000 iterations
Finished 180000 iterations
Finished 190000 iterations
Finished 200000 iterations
Finished 210000 iterations
Finished 220000 iterations
Finished 230000 iterations
Finished 240000 iterations
Finished 250000 iterations
Finished 260000 iterations
Finished 270000 iterations
Finished 280000 iterations
Finished 290000 iterations
Finished 300000 iterations
Finished 310000 iterations
Finished 320000 iterations
Finished 330000 iterations
Finished 340000 iterations
Finished 350000 iterations
Finished 360000 iterations
Finished 370000 iterations
Finished 380000 iterations
Finished 390000 iterations
Finished 400000 iterations
Finished 410000 iterations
Finished 420000 iterations
Finished 430000 iterations
Finished 440000 iterations
Finished 450000 iterations
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-3-6657c6365cf0> in <module>
----> 1 main1()
<ipython-input-2-48aa178bac1f> in main1()
37 print('\n==== Training model on data set B ====')
38 Xb, Yb = util.load_csv('./data/ds1_b.csv', add_intercept=True)
---> 39 logistic_regression(Xb, Yb)
<ipython-input-2-48aa178bac1f> in logistic_regression(X, Y)
20 i += 1
21 prev_theta = theta
---> 22 grad = calc_grad(X, Y, theta)
23 theta = theta - learning_rate * grad
24 if i % 10000 == 0:
<ipython-input-2-48aa178bac1f> in calc_grad(X, Y, theta)
4
5 margins = Y * X.dot(theta)
----> 6 probs = 1. / (1 + np.exp(margins))
7 grad = -(1./m) * (X.T.dot(probs * Y))
8
KeyboardInterrupt:
可以发现对于A数据集,结果可以收敛,对于B数据集不收敛。
01b
首先注意到算法中和真正的Logistc 回归的算法不同,明显的不同是对于梯度下降时,梯度下降step的计算上,标准的Logistic 回归中,梯度下降每一步为:
而通过函数calc_grad可以总结出,这里的step为:
那么这个梯度下降试图找到的函数的最小值(原始函数),这个函数的主要部分必须是:
这种形式。
显然这个相比Logistic 回归要最小化的部分,sigmoid函数中,多了指数上的,这种y与
乘积的形式,会让人想到SVM里面的几何间隔和函数间隔的概念,那么无论是Logistic回归,还是这里已经改掉的似Logistic分类器也似SVM分类器的算法,本质上都是线性分类的问题,那么就要看不收敛是否是数据本身的问题(这个及时不考虑这些,也是第一个直觉的吧,先看看数据有没有问题)
所以,首先可视化数据
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcdefaults()
data_load_a = pd.read_csv('./data/ds1_a.csv')
x_train_a = data_load_a.loc[:, data_load_a.columns.str.contains('x')].values
x_train_a = np.column_stack((np.ones(x_train_a.shape[0]), x_train_a))
y_train_a = data_load_a.loc[:, 'y'].values.reshape((-1, 1))
data_load_b = pd.read_csv('./data/ds1_b.csv')
x_train_b = data_load_b.loc[:, data_load_b.columns.str.contains('x')].values
x_train_b = np.column_stack((np.ones(x_train_b.shape[0]), x_train_b))
y_train_b = data_load_b.loc[:, 'y'].values.reshape((-1, 1))
fig1 = plt.figure()
ax1 = fig1.add_subplot(121)
ax1.scatter(x_train_a[np.where(y_train_a == 1)[0], 1], x_train_a[np.where(y_train_a == 1)[0], 2], marker='o', color='blue')
ax1.scatter(x_train_a[np.where(y_train_a == -1)[0], 1], x_train_a[np.where(y_train_a == -1)[0], 2], marker='x', color='red')
ax1.set_title('Set_A', **dict(fontsize=15, weight='black'))
ax2 = fig1.add_subplot(122)
ax2.scatter(x_train_b[np.where(y_train_b == 1)[0], 1], x_train_b[np.where(y_train_b == 1)[0], 2], marker='o', color='blue')
ax2.scatter(x_train_b[np.where(y_train_b == -1)[0], 1], x_train_b[np.where(y_train_b == -1)[0], 2], marker='x', color='red')
ax2.set_title('Set_B', **dict(fontsize=15, weight='black'))
plt.show()
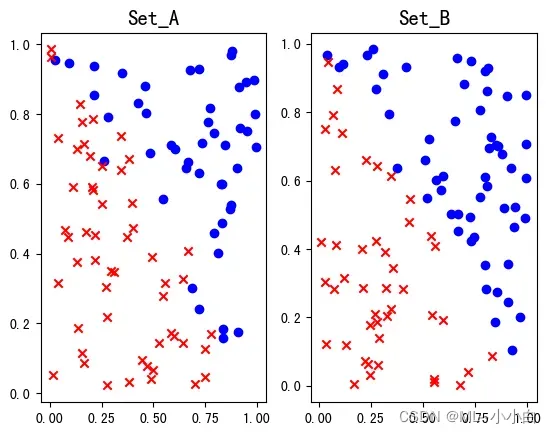
可以发现,B相对于A有个显著的不同是,B线性可分,A线性不可分,从原理上类似SVM中的软硬间隔,B是硬间隔,所以它的函数间隔可以无限的大,也就是缺少了约束,因此出现不收敛的问题,此外从上面的
中可以发现,分母的e指数部分中,由于线性可分,所以都可以得到无穷大,从而有利于整体的减小,所以可以一直增大
,从而无法收敛,而A可以收敛是总可以找到让“错误”分类最小的超平面,且由于总有误分类点,所以某些情况下,可以起到限制
的效果,所以表现出收敛。
01c
i.
不能。通过上一题的分析可以发现,学习率只是在迭代解中增加或减少每一步的大小,并没有从根本上解决问题,因为它是无效的。
ii.
def calc_grad(X, Y, theta):
"""Compute the gradient of the loss with respect to theta."""
m, n = X.shape
margins = Y * X.dot(theta)
probs = 1. / (1 + np.exp(margins))
grad = -(1./m) * (X.T.dot(probs * Y))
return grad
def logistic_regression(X, Y):
"""Train a logistic regression model."""
m, n = X.shape
theta = np.zeros(n)
learning_rate = 10
i = 0
while True:
i += 1
prev_theta = theta
grad = calc_grad(X, Y, theta)
theta = theta - learning_rate / i ** 2 * grad
if i % 1000000 == 0:
print('Finished %d iterations' % i)
if np.linalg.norm(prev_theta - theta) < 1e-15:
print('Converged in %d iterations' % i)
break
return
def main2():
print('==== Training model on data set A with learning rate decay with time====')
Xa, Ya = util.load_csv('./data/ds1_a.csv', add_intercept=True)
logistic_regression(Xa, Ya)
print('\n==== Training model on data set B with learning rate decay with time====')
Xb, Yb = util.load_csv('./data/ds1_b.csv', add_intercept=True)
logistic_regression(Xb, Yb)
main2()
==== Training model on data set A with learning rate decay with time====
Finished 1000000 iterations
Finished 2000000 iterations
Finished 3000000 iterations
Finished 4000000 iterations
Finished 5000000 iterations
Finished 6000000 iterations
Finished 7000000 iterations
Finished 8000000 iterations
Finished 9000000 iterations
Finished 10000000 iterations
Finished 11000000 iterations
Finished 12000000 iterations
Finished 13000000 iterations
Finished 14000000 iterations
Finished 15000000 iterations
Finished 16000000 iterations
Finished 17000000 iterations
Finished 18000000 iterations
Finished 19000000 iterations
Finished 20000000 iterations
Finished 21000000 iterations
Finished 22000000 iterations
Finished 23000000 iterations
Finished 24000000 iterations
Finished 25000000 iterations
Finished 26000000 iterations
Finished 27000000 iterations
Converged in 27083822 iterations
==== Training model on data set B with learning rate decay with time====
Finished 1000000 iterations
Finished 2000000 iterations
Finished 3000000 iterations
Finished 4000000 iterations
Finished 5000000 iterations
Finished 6000000 iterations
Finished 7000000 iterations
Finished 8000000 iterations
Finished 9000000 iterations
Finished 10000000 iterations
Finished 11000000 iterations
Finished 12000000 iterations
Finished 13000000 iterations
Finished 14000000 iterations
Finished 15000000 iterations
Finished 16000000 iterations
Finished 17000000 iterations
Finished 18000000 iterations
Finished 19000000 iterations
Finished 20000000 iterations
Finished 21000000 iterations
Finished 22000000 iterations
Finished 23000000 iterations
Finished 24000000 iterations
Finished 25000000 iterations
Finished 26000000 iterations
Finished 27000000 iterations
Converged in 27850565 iterations
上述结果表明,通过改变学习率随着迭代次数而衰减(每个学习率是初始学习率的),最终的结果是可以“收敛”的,但是这种收敛只达到了我们预设的收敛判断阈值并不是函数真正的全局收敛,因为当学习率衰减到足够小的值时,
的下一次迭代会因为学习率因子太小而变得小于收敛条件,从而成为一种不太小收敛意义重大。
iii.
暂时不知道linear scaling 是在干嘛,不做回答
iv.
def calc_grad(X, Y, theta):
"""Compute the gradient of the loss with respect to theta."""
m, n = X.shape
margins = Y * X.dot(theta)
probs = 1. / (1 + np.exp(margins))
grad = -(1./m) * (X.T.dot(probs * Y)) + 0.00136 * theta
return grad
def logistic_regression(X, Y):
"""Train a logistic regression model."""
m, n = X.shape
theta = np.zeros(n)
learning_rate = 10
i = 0
while True:
i += 1
prev_theta = theta
grad = calc_grad(X, Y, theta)
theta = theta - learning_rate * grad
if i % 1000000 == 0:
print('Finished %d iterations' % i)
if np.linalg.norm(prev_theta - theta) < 1e-15:
print('Converged in %d iterations' % i)
break
return
def main3():
print('==== Training model on data set A ====')
Xa, Ya = util.load_csv('./data/ds1_a.csv', add_intercept=True)
logistic_regression(Xa, Ya)
print('\n==== Training model on data set B ====')
Xb, Yb = util.load_csv('./data/ds1_b.csv', add_intercept=True)
logistic_regression(Xb, Yb)
main3()
==== Training model on data set A ====
Converged in 832 iterations
==== Training model on data set B ====
Converged in 909 iterations
可以发现,加入正则化项(罚项),且罚项前增加一个系数,平衡原损失函数与罚项的大小(上面代码中的罚项系数为0.00136*2=0.00272),可以很快地收敛。
v.
def calc_grad(X, Y, theta):
"""Compute the gradient of the loss with respect to theta."""
m, n = X.shape
margins = Y * X.dot(theta)
probs = 1. / (1 + np.exp(margins))
grad = -(1./m) * (X.T.dot(probs * Y))
return grad
def logistic_regression(X, Y):
"""Train a logistic regression model."""
m, n = X.shape
theta = np.zeros(n)
learning_rate = 1
i = 0
while True:
i += 1
prev_theta = theta
grad = calc_grad(X, Y, theta)
theta = theta - learning_rate * grad
if i % 1000000 == 0:
print('Finished %d iterations' % i)
if np.linalg.norm(prev_theta - theta) < 1e-15:
print('Converged in %d iterations' % i)
break
return
def main4():
print('==== Training model on data set A ====')
Xa, Ya = util.load_csv('./data/ds1_a.csv', add_intercept=True)
rand_mat = np.random.randn(Xa.shape[0], Xa.shape[1])
Xa = Xa + rand_mat
logistic_regression(Xa, Ya)
print('\n==== Training model on data set B ====')
Xb, Yb = util.load_csv('./data/ds1_b.csv', add_intercept=True)
rand_mat = np.random.randn(Xb.shape[0], Xb.shape[1])
Xb = Xb + rand_mat
logistic_regression(Xb, Yb)
main4()
==== Training model on data set A ====
Converged in 148 iterations
==== Training model on data set B ====
Converged in 127 iterations
原则上,加入噪声后,原来线性可分的数据集就变得不可分了,所以可以收敛。
01d
SVM本本身可以用合页损失函数的图像来理解,相比感知机,起图像沿着x轴向右平移了1,这样的其实比感知机有更加严格的损失标准,更高的置信度,而对于线性可分的数据集,SVM的合页损失函数和感知机的同样都可以达到0.
02a
按照题目的假设,即标准的Logistic回归,那么损失函数为:
对应的对数损失函数为:
当完成优化的时候,理论上,对数损失函数的导数在全局最优处应该为0,即(求导过程略,可以去找一下学习Logistic回归的推导):
其中,对于,因
有:
然后:
那么,当和
,那么:
02b
两个都不是彼此的“必要条件”,考虑,假设模型已经完全校准(perfectly calibrated),那么有:
对于上式右边部分,此时分子和分母都是正例,即:
而左边的分子部分,对于,由于:
所以:
所以对于完全校准的模型,不是模型达到最高准确率(这里考虑的情况下,为1)的必要条件。
反过来,如果模型已经达到了最高的准确率,即开始等式右侧等于1(所有假设函数输出结果大于0.5的都是正实例),那么必然不能等于等式右侧,因为等式左侧的概率部分必然不都等于1,而是位于(0.5,1)区间,那么左侧必然是小于1的,所以左右两边不可能相等,即达不到完全校准(perfectly calibrated)。
02c
类似02a中的过程,加入正则化项(罚项)实际上就是改变了损失函数,即:
那么当完成其优化以后,在最优化处梯度应该为0:
其中,对于,因
有:
然后:
所以当不为0时,原来的模型完全校准(perfectly calibrated)的等式已经不再成立,即加入正则化项会使得原本符合完全校准的Logistic 回归模型,变得不再完全校准。
03a
从定义开始:
代入:
所以有:
最后一个等于号由于优化变量是与只含x,y的项无关,所以可以舍弃。
03b
直接计算:
可用,
03c
首先从已知条件得到条件概率服从的分布:
从而:
取对数:
然后
制作:
那么求最优化(最小值),最优时对应梯度为0,即:
上面倒数第二个等号涉及到矩阵和向量的推导,细节可以在相关的数学基础中推导或参考。
然后:
03d
可以沿着从03b开始的思路重新思考此题,首先去去的后验概率分布,过程与03c开始部分相同,得到:
然后看先验概率分布:
所以:
所以:
上式为绝对值函数,无法推导,只能用数值求解。
04a
是合法的kernel,对称性显而易见,证明半正定性:
最后的不等号是因为和
都是合法的Kernel,即它们各自都半正定(
)
04b
不一定是合法Kernel,因为不一定是半正定矩阵,比如,则:
04c
结合04d,这里的a应该是指正实数。那么这是合法的kernel,因为这个因子显然不改变对称性,而半正定性也易证:
04d
对于a>0,同04c相反,这样使得矩阵不能够半正定,因此不是合法的Kernel。例如,a=-1,则:
04e
是合法的Kernel,对称性显而易见,对于半正定性,证明:
04f
是合法的Kernel,对称性显然,半正定性:
04g
是合法的Kernel,因为只要是合法的Kernel,那么里面的输入无所谓是两个n维的矢量还是d维的。
04h
是合法的Kernel,对称性是显然的,对于正定性做如下证明:
首先,的一般形式为:
所以:
而由04e可知,两个合法的Kernel的积仍然是合法的Kernel,因此是合法的,进一步,由04c可知,合法Kernel乘正实数因子仍然是合法的,即
是合法的,再由04a可知,任意两个合法的Kernel的和也是合法的,所以
是合法的。
05a
i.
在课程中,有提到过,对于标准的Logistic回归,以及在讲解SVM时候,为了避开繁杂而严格的推导,用的一个直觉式的,对于的表示方法,即通过迭代公式:
可以看出,如果一开始的是一个零向量,那么它迭代以后其实就是很多x的线性组合。
这里也是同样的道理,只不过每次迭代的不再是x,而是被映射到高维空间的矢量
,即:
因此,可以表示为
的线性组合:
ii.
直接代入上式的结果:
iii.
直接计算可得:
所以:
05b
直接修改代码:
import math
import matplotlib.pyplot as plt
import numpy as np
import src.util
def initial_state():
"""Return the initial state for the perceptron.
This function computes and then returns the initial state of the perceptron.
Feel free to use any data type (dicts, lists, tuples, or custom classes) to
contain the state of the perceptron.
"""
# *** START CODE HERE ***
return []
# *** END CODE HERE ***
def predict(state, kernel, x_i):
"""Peform a prediction on a given instance x_i given the current state
and the kernel.
Args:
state: The state returned from initial_state()
kernel: A binary function that takes two vectors as input and returns
the result of a kernel
x_i: A vector containing the features for a single instance
Returns:
Returns the prediction (i.e 0 or 1)
"""
# *** START CODE HERE ***
return sign(sum(beta * kernel(x, x_i) for beta, x in state))
# *** END CODE HERE ***
def update_state(state, kernel, learning_rate, x_i, y_i):
"""Updates the state of the perceptron.
Args:
state: The state returned from initial_state()
kernel: A binary function that takes two vectors as input and returns the result of a kernel
learning_rate: The learning rate for the update
x_i: A vector containing the features for a single instance
y_i: A 0 or 1 indicating the label for a single instance
"""
# *** START CODE HERE ***
state.append((learning_rate * (y_i - sign(sum(beta * kernel(x, x_i) for beta, x in state))), x_i))
# *** END CODE HERE ***
def sign(a):
"""Gets the sign of a scalar input."""
if a >= 0:
return 1
else:
return 0
def dot_kernel(a, b):
"""An implementation of a dot product kernel.
Args:
a: A vector
b: A vector
"""
return np.dot(a, b)
def rbf_kernel(a, b, sigma=1):
"""An implementation of the radial basis function kernel.
Args:
a: A vector
b: A vector
sigma: The radius of the kernel
"""
distance = (a - b).dot(a - b)
scaled_distance = -distance / (2 * (sigma) ** 2)
return math.exp(scaled_distance)
def train_perceptron(kernel_name, kernel, learning_rate):
"""Train a perceptron with the given kernel.
This function trains a perceptron with a given kernel and then
uses that perceptron to make predictions.
The output predictions are saved to src/output/p05_{kernel_name}_predictions.txt.
The output plots are saved to src/output_{kernel_name}_output.pdf.
Args:
kernel_name: The name of the kernel.
kernel: The kernel function.
learning_rate: The learning rate for training.
"""
train_x, train_y = util.load_csv('./data/ds5_train.csv')
state = initial_state()
for x_i, y_i in zip(train_x, train_y):
update_state(state, kernel, learning_rate, x_i, y_i)
test_x, test_y = util.load_csv('./data/ds5_train.csv')
plt.figure(figsize=(12, 8))
util.plot_contour(lambda a: predict(state, kernel, a))
util.plot_points(test_x, test_y)
plt.savefig('./output/p05_{}_output.pdf'.format(kernel_name))
predict_y = [predict(state, kernel, test_x[i, :]) for i in range(test_y.shape[0])]
np.savetxt('./output/p05_{}_predictions'.format(kernel_name), predict_y)
def main5():
train_perceptron('dot', dot_kernel, 0.5)
train_perceptron('rbf', rbf_kernel, 0.5)
05c
main5()
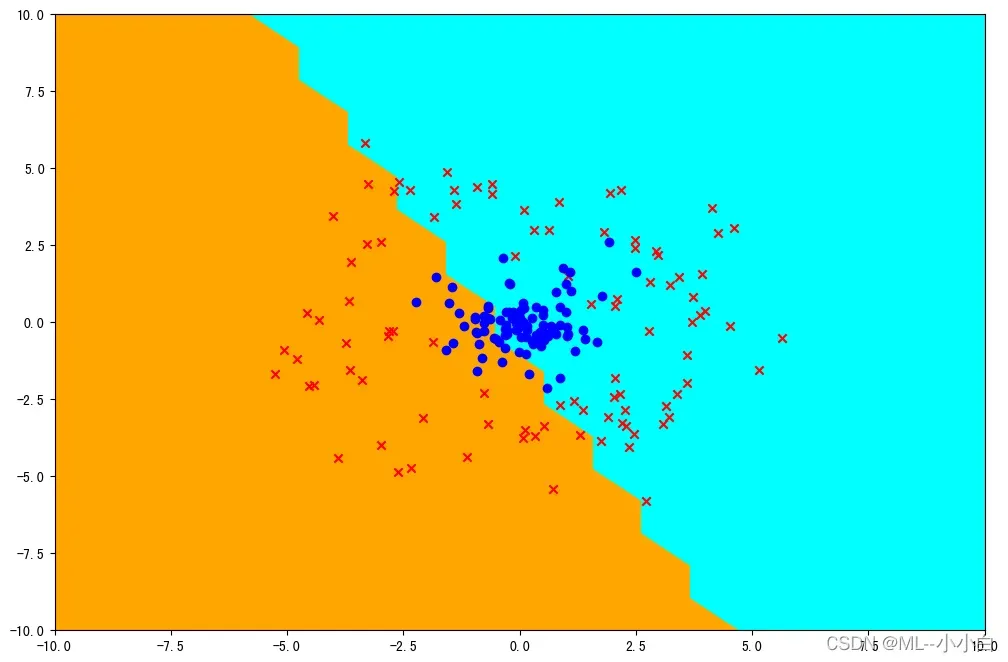
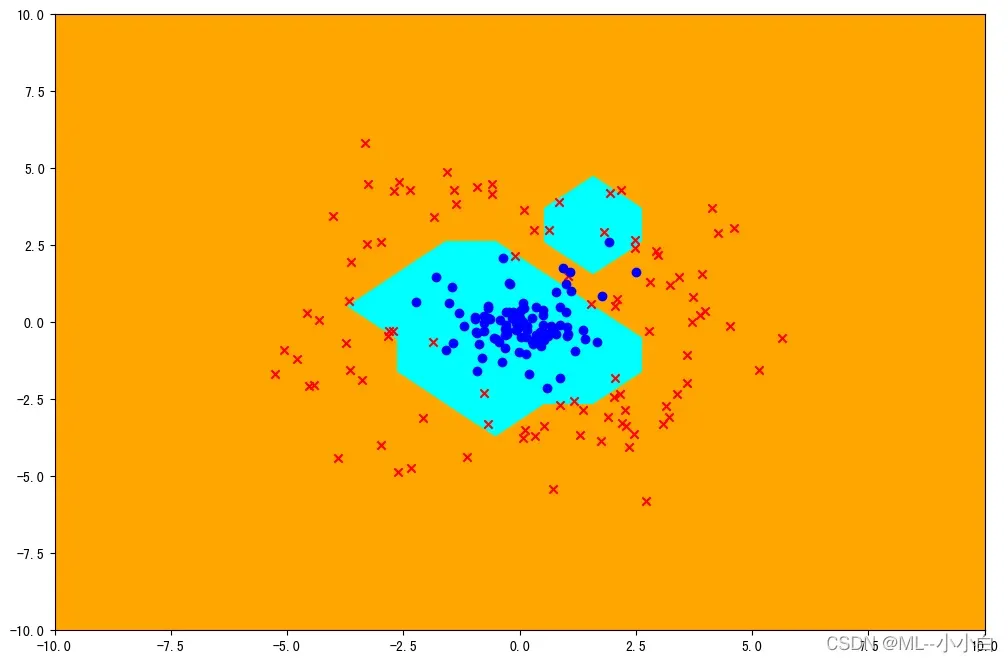
显然使用dot Kernel的效果要更差,因为原数据集不是线性可分的,dot Kernel实际上是线性的分类器,其并没有把原来的样本矢量映射到高维空间,而二维空间的线性从理论上就不能把两种正反实例分开,所以自然效果不好。另一方面,对于rbf的Kernel,其实它将原样本矢量映射到了无穷维空间,在无穷维空间中,可以找到可分离的超平面,其在二维空间的投影,就如图中所示,可以将二维中线性不可分的两类分开。
06a
添加的代码是:
import collections
import numpy as np
import src.util
import src.svm
def get_words(message):
"""Get the normalized list of words from a message string.
This function should split a message into words, normalize them, and return
the resulting list. For splitting, you should split on spaces. For normalization,
you should convert everything to lowercase.
Args:
message: A string containing an SMS message
Returns:
The list of normalized words from the message.
"""
# *** START CODE HERE ***
word_list = []
for word in message.strip().split(' '):
if not word:
continue
word_list.append(word.lower())
return word_list
# *** END CODE HERE ***
def create_dictionary(messages):
"""Create a dictionary mapping words to integer indices.
This function should create a dictionary of word to indices using the provided
training messages. Use get_words to process each message.
Rare words are often not useful for modeling. Please only add words to the dictionary
if they occur in at least five messages.
Args:
messages: A list of strings containing SMS messages
Returns:
A python dict mapping words to integers.
"""
# *** START CODE HERE ***
# get all words' list
words = [word for message in messages for word in get_words(message)]
# get the number of each word
word_count = collections.Counter(words)
# frequent word list where elements appear 5 times in words' list at least
freq_words = [word for word, freq in word_count.items() if freq >= 5]
# return dict
return {word: index for index, word in enumerate(freq_words)}
# *** END CODE HERE ***
def transform_text(messages, word_dictionary):
"""Transform a list of text messages into a numpy array for further processing.
This function should create a numpy array that contains the number of times each word
appears in each message. Each row in the resulting array should correspond to each
message and each column should correspond to a word.
Use the provided word dictionary to map words to column indices. Ignore words that
are not present in the dictionary. Use get_words to get the words for a message.
Args:
messages: A list of strings where each string is an SMS message.
word_dictionary: A python dict mapping words to integers.
Returns:
A numpy array marking the words present in each message.
"""
# *** START CODE HERE ***
m, n = len(messages), len(word_dictionary)
trans_mat = np.zeros((m, n), dtype=int)
for i, message in enumerate(messages):
for word in get_words(message):
if word in word_dictionary:
trans_mat[i, word_dictionary[word]] += 1
return trans_mat
# *** END CODE HERE ***
06b
关于这部分的知识,可以先通过讲义复习朴素贝叶斯和拉普拉斯平滑,还有前面提到的多元事件模型,有助于形成算法思路。了解了以上知识后,这里有个大概的思路。
进行预测,为了避免最终计算中的分母,考虑比较和
的比值:
为了避免连乘符号当中每个值都很小从而造成“下溢”,对该式取对数,从而可以从结果是否大于0来判断,是否是正例(spam):
其中,和
分别为:
上述结果总结如下:
def fit_naive_bayes_model(matrix, labels):
"""Fit a naive bayes model.
This function should fit a Naive Bayes model given a training matrix and labels.
The function should return the state of that model.
Feel free to use whatever datatype you wish for the state of the model.
Args:
matrix: A numpy array containing word counts for the training data
labels: The binary (0 or 1) labels for that training data
Returns: The trained model
"""
# *** START CODE HERE ***
m, n = matrix.shape
phi_y = np.sum(labels) / m
phi_k_y1 = (1.0 + matrix[ labels==1 ].sum(axis=0)) / (n + matrix[ labels==1 ].sum())
phi_k_y0 = (1.0 + matrix[ labels==0 ].sum(axis=0)) / (n + matrix[ labels==0 ].sum())
return phi_y, phi_k_y1, phi_k_y0
# *** END CODE HERE ***
def predict_from_naive_bayes_model(model, matrix):
"""Use a Naive Bayes model to compute predictions for a target matrix.
This function should be able to predict on the models that fit_naive_bayes_model
outputs.
Args:
model: A trained model from fit_naive_bayes_model
matrix: A numpy array containing word counts
Returns: A numpy array containg the predictions from the model
"""
# *** START CODE HERE ***
phi_y, phi_k_y1, phi_k_y0 = model
pre_result = matrix @ (np.log(phi_k_y1) - np.log(phi_k_y0)) + np.log(phi_y / (1 - phi_y))
return (np.sign(pre_result) + 1) // 2
# *** END CODE HERE ***
06c
def get_top_five_naive_bayes_words(model, dictionary):
"""Compute the top five words that are most indicative of the spam (i.e positive) class.
Ues the metric given in 6c as a measure of how indicative a word is.
Return the words in sorted form, with the most indicative word first.
Args:
model: The Naive Bayes model returned from fit_naive_bayes_model
dictionary: A mapping of word to integer ids
Returns: The top five most indicative words in sorted order with the most indicative first
"""
# *** START CODE HERE ***
phi_y, phi_k_y1, phi_k_y0 = model
inv_dictionary = {v: k for k, v in dictionary.items()}
top_five_indicative_word_idx = np.argsort(np.log(phi_k_y1) - np.log(phi_k_y0))[-5:]
return [inv_dictionary[idx] for idx in top_five_indicative_word_idx]
# *** END CODE HERE ***
06d
def compute_best_svm_radius(train_matrix, train_labels, val_matrix, val_labels, radius_to_consider):
"""Compute the optimal SVM radius using the provided training and evaluation datasets.
You should only consider radius values within the radius_to_consider list.
You should use accuracy as a metric for comparing the different radius values.
Args:
train_matrix: The word counts for the training data
train_labels: The spma or not spam labels for the training data
val_matrix: The word counts for the validation data
val_labels: The spam or not spam labels for the validation data
radius_to_consider: The radius values to consider
Returns:
The best radius which maximizes SVM accuracy.
"""
# *** START CODE HERE ***
best_radius = 0
best_error = 1
for radius in radius_to_consider:
state = src.svm.svm_train(train_matrix, train_labels, radius)
pred_result = src.svm.svm_predict(state, val_matrix, radius)
error_rate = np.abs(pred_result - val_labels).sum() / len(val_labels)
print(f'radius: {radius}, error_rate: {error_rate}')
if error_rate < best_error:
best_error = error_rate
best_radius = radius
return best_radius
# *** END CODE HERE ***
实话说,他提供的SVM的代码应该是一个极为简化的,具体的没有太细扣,就认为他是对的。
检验上面的函数是否能够run
def main6():
train_messages, train_labels = util.load_spam_dataset('./data/ds6_train.tsv')
val_messages, val_labels = util.load_spam_dataset('./data/ds6_val.tsv')
test_messages, test_labels = util.load_spam_dataset('./data/ds6_test.tsv')
dictionary = create_dictionary(train_messages)
util.write_json('./output/p06_dictionary', dictionary)
train_matrix = transform_text(train_messages, dictionary)
np.savetxt('./output/p06_sample_train_matrix', train_matrix[:100,:])
val_matrix = transform_text(val_messages, dictionary)
test_matrix = transform_text(test_messages, dictionary)
naive_bayes_model = fit_naive_bayes_model(train_matrix, train_labels)
naive_bayes_predictions = predict_from_naive_bayes_model(naive_bayes_model, test_matrix)
np.savetxt('./output/p06_naive_bayes_predictions', naive_bayes_predictions)
naive_bayes_accuracy = np.mean(naive_bayes_predictions == test_labels)
print('Naive Bayes had an accuracy of {} on the testing set'.format(naive_bayes_accuracy))
top_5_words = get_top_five_naive_bayes_words(naive_bayes_model, dictionary)
print('The top 5 indicative words for Naive Bayes are: ', top_5_words)
util.write_json('./output/p06_top_indicative_words', top_5_words)
optimal_radius = compute_best_svm_radius(train_matrix, train_labels, val_matrix, val_labels, [0.01, 0.1, 1, 10])
util.write_json('./output/p06_optimal_radius', optimal_radius)
print('The optimal SVM radius was {}'.format(optimal_radius))
svm_predictions = src.svm.train_and_predict_svm(train_matrix, train_labels, test_matrix, optimal_radius)
svm_accuracy = np.mean(svm_predictions == test_labels)
print('The SVM model had an accuracy of {} on the testing set'.format(svm_accuracy, optimal_radius))
main6()
Naive Bayes had an accuracy of 0.978494623655914 on the testing set
The top 5 indicative words for Naive Bayes are: ['urgent!', 'tone', 'prize', 'won', 'claim']
radius: 0.01, error_rate: 0.08258527827648116
radius: 0.1, error_rate: 0.05385996409335727
radius: 1, error_rate: 0.07001795332136446
radius: 10, error_rate: 0.12387791741472172
The optimal SVM radius was 0.1
The SVM model had an accuracy of 0.9695340501792115 on the testing set
版权声明:本文为博主ML–小小白原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_26928055/article/details/123255525