1、向量链式法则(chain rule)
标量链式法则(chain rule):

拓展到向量:

例子1:
x,w是长为n的向量,y是一个标量。
z函数是x和w做累积减去y做平方。

计算z关于w的一个导数。对z进行分解(decompose)。

例子2:
X是mxn的一个矩阵(matrix),w是一个长为n的向量,y是一个长为m的向量
z为X乘以w减去y然后进行L2norm

计算z对w的导数
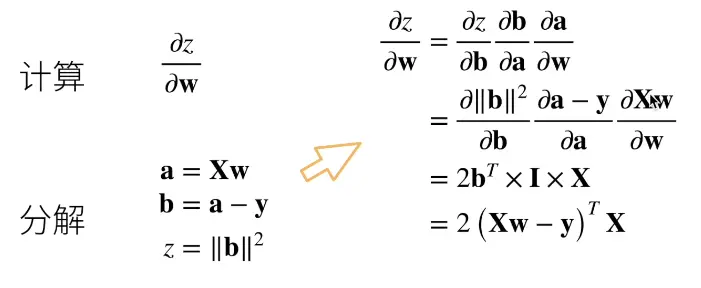
自动求导
自动求导计算了一个函数在指定值上的导数,他有别于符号(symbol)求导,数值求导。
符号(symbol)求导:
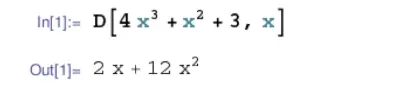
数值求导:
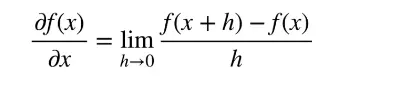
自动求导是怎么做出来的:
涉及到计算图(computational graph):就是将代码分解(decompose)成操作子(一个个的展开),将计算表示成一个无环图。
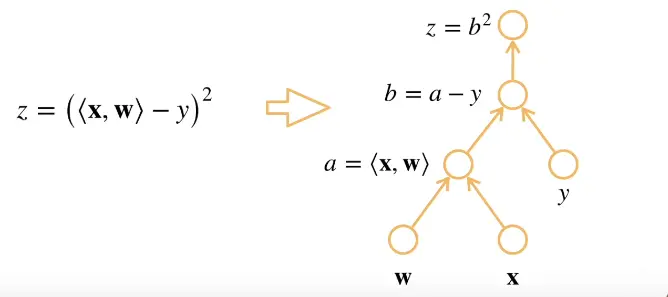
显式构造:TensorFlow、Theano、MXNet
from mxnet import sym
a=sym.var()
b=sym.var()
c=2*a+b
隐式构造:PyTorch、MXNet
from mxnet import autograd,nd
with autograd.record():
a=nd.ones((2,1))
b=nd.ones((2,1))
c=2*a+b
自动求导的两种模式
链式法则(chain rule):
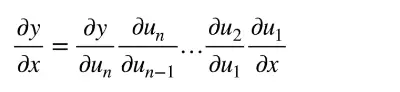
正向累积:
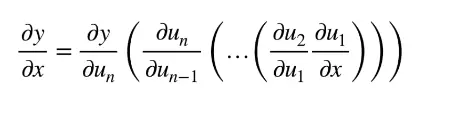
反向累积又称反向传递:
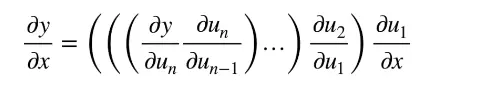
反向累积举例:
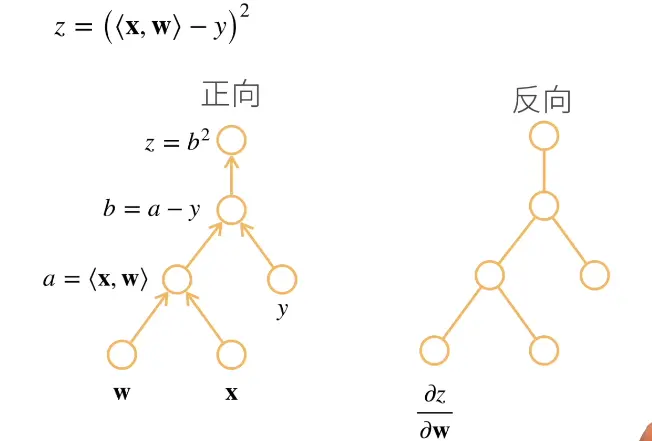
反向累积总结:
- 构造计算图(computational graph)。
- 前向:执行图,存储中间结果。
- 反向:从相反执行图去除不需要的枝干。
复杂度
计算复杂度:O(n),n是操作子个数,通常正向和方向的代价(cost)类似。
内存复杂度:O(n),因为需要存储正向的所有中间结果。
反向累积跟正向累积相比:
- O(n)计算复杂度用来计算一个变量的梯度(gradient)
- O(1)内存复杂度
自动求导的实现
1,假设(Hypothesis)我们对函数 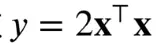
import torch
x=torch.arange(4.0) #创建一个x为0.1.2.3长为4的一个向量
print(x)
"""
在我们计算y关于x的梯度(gradient)之前,我们需要一个地方来存储梯度(gradient)
"""
x.requires_grad_(True)#告诉机器把梯度(gradient)存在这个地方,等价与x=torch.arange(4.0,requires_grad=True)
print(x.grad) #默认值是空的(用来存放y关于x的导数)
"""
然后我们再计算y
"""
y=2*torch.dot(x,x) #x和x的累积乘以2
print(y)
"""
通过调用反向传播(Back propagation)函数来自动计算y关于x每个分量的梯度(gradient)
"""
print(y.backward())# 就是求导
print(x.grad)#求完之后,通过x.grad访问导数
print(x.grad==4*x) 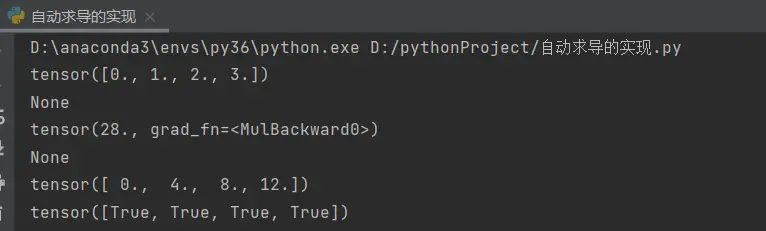
2、计算下一个函数
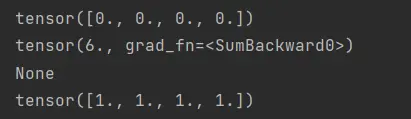
print(x.grad.zero_()) #在默认情况下,PyTorch会累积梯度(gradient),所以在计算下一个函数之前,我们需要清除之前的值。把0写入了梯度(gradient)里面(把梯度(gradient)清零)
y=x.sum() #求向量的和的导数是全1
print(y)
print(y.backward())
print(x.grad)
3、在深度学习(Deep learning)中,我们的目的不是计算微分矩阵(matrix),而是批量(batch)中每个样本单独计算的偏导数(partial derivative)之和
#对非标量调用“backward” 需要传入一个“gradient”参数,该参数指定微分函数
print(x.grad.zero_())
y=x*x #等价于 y.backward(torch.ones(len(x))) 假设(Hypothesis)y不是标量
print(y.sum().backward())
print(x.grad) 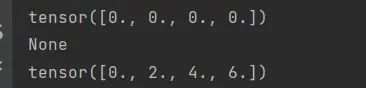
4、将某些计算移动到记录的计算图(computational graph)之外
print(x.grad.zero_())
y=x*x
u=y.detach() #u不再是关于x的函数 就是一个常数
z=u*x
print(z.sum().backward())
print(x.grad==u)
print(x.grad.zero_())
print(y.sum().backward())
print(x.grad==2*x) 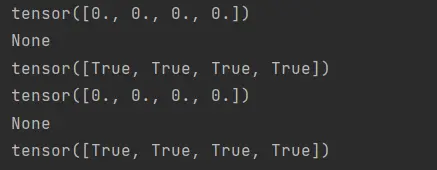
5、即使构建函数的计算图(computational graph)需要通过Python控制流(stream)(例如,条件、循环或者任意函数调用),我们仍然可以计算得到变量的梯度(gradient)
def f(a):
b=a*2
while b.norm() < 1000:
b=b*2
if b.sum() > 0:
c=b
else:
c=100*b
return c
a=torch.randn(size=(),requires_grad=True) #a为一个随机数,size为空就是一个标量,需要一个梯度(gradient)
d=f(a)
print(d.backward())
print(a.grad==d/a) 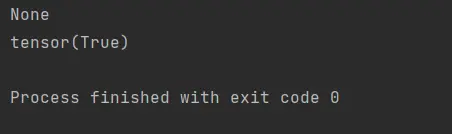
版权声明:本文为博主橙子吖21原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_42012782/article/details/121364983