

前言
最近OpenAI的宫斗剧上演的精妙绝伦,简直就是《硅谷》+《继承》,强烈推荐这两部剧集。AIGC的群里都在说Q*是揭示AI接近AGI的一篇论文,那就费点时间拨开云雾吧。为了方便大众更好地理解Q*,本人在快速浏览过论文后首先得出此结论公式:
Q* = (1992年的Q-learning + 1968年的A star算法) * Deep Transformer Learning
本篇文章解读两篇论文。强烈建议延伸阅读第二篇文章的视频:Q-Transformer
Q-Transformer简介之机器人如何实现自主Q学习的动画
1、第一篇介绍Q* search论文全称是:A* SEARCH WITHOUT EXPANSIONS: LEARNING HEURISTIC FUNCTIONS WITH DEEP Q-NETWORKS,作者是加州大学尔湾分校和南卡罗琳娜大学的研究员在2023年5月份提出的。原文链接:https://arxiv.org/abs/2102.04518
2、第二篇介绍Q transformer论文的全称是:Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions,作者是Deep Mind团队在2023年9月提出的。[2309.10150] Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions (arxiv.org)
Gpt-4先summary:
Q* search论文解决了使用A*搜索在大动作空间中高效解决问题的挑战,这是人工智能领域一个重要的方法。A*搜索的计算和内存需求随动作空间大小线性增长,尤其是当使用由深度神经网络学习的计算成本高昂的启发式函数时。为了克服这一问题,作者引入了Q*搜索,这是一种新的搜索算法,采用深度Q网络。这种方法允许通过网络的单次前向传递计算节点子项的转换成本和启发式值之和,无需显式生成这些子节点。这显著减少了计算时间和每次迭代生成的节点数量。作者以包含1872个元动作的大动作空间下的魔方为例,展示了Q*搜索的有效性。结果显示,Q*搜索比A*搜索快达129倍,生成的节点数量少达1288倍。此外,他们证明了Q*搜索在给定适当启发式函数的情况下总能找到最短路径。
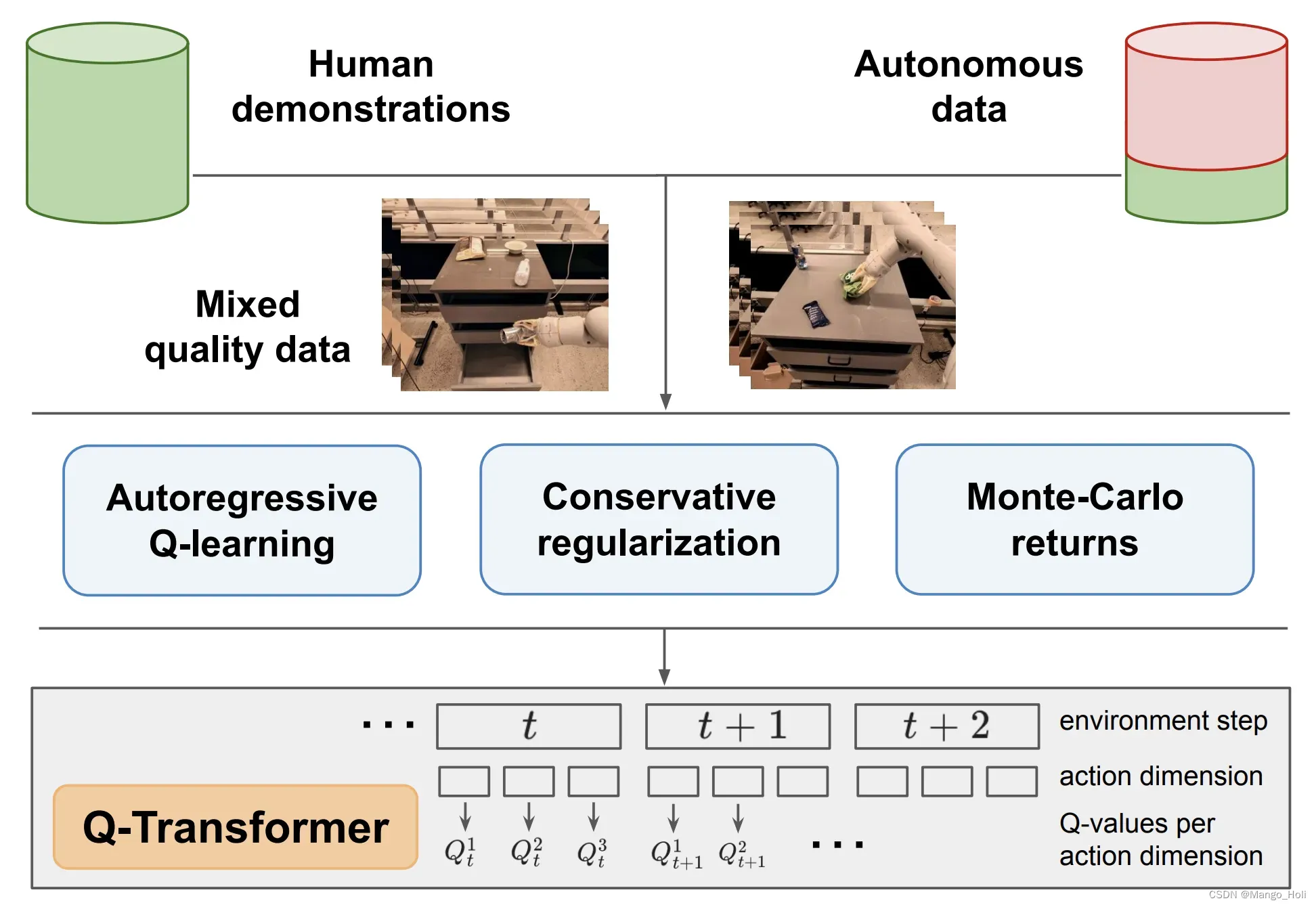
在Q transformer这项工作中,作者提出了一种可扩展的强化学习方法,用于从大型离线数据集中训练多任务策略,这些数据集可以利用人类示范和自动收集的数据。作者的方法使用Transformer为通过离线时差备份训练的Q函数提供可扩展的表示。因此,我们将这种方法称为Q-Transformer。通过离散化每个动作维度并将每个动作维度的Q值表示为单独的标记,我们可以应用有效的高容量序列建模技术进行Q学习。作者介绍了几个设计决策,这些决策使得离线RL训练具有良好的性能,并展示了Q-Transformer在一套大型多样化的现实世界机器人操控任务中,超越了以前的离线RL算法和模仿学习技术。
到这里GPT已经剥夺了我解读论文的乐趣了。
论文解读
【Q* Search】A* SEARCH WITHOUT EXPANSIONS: LEARNING HEURISTIC FUNCTIONS WITH DEEP Q-NETWORKS
首先,在介绍Q* search之前要知道,A*算法是一个贪心算法。其讲求邻近收益最大化,即找到最近最好的路径,以此猜测通过迷宫的最优方法。它主要用于agent在现实中的行动指导,对计算量和内存空间的要求很高,并根据需要行动的地图大小呈线性增长。常见的用法是用在物流计算的问题上。我以前学过经典的旅行商问题TSP,用的就是A star算法作为一个补偿算法,面对需要较大的计算代价来寻求最优解时,在较短时间内找到较优解,也可以理解为在找local minima。算法非常简单,也很好用。
Q*是什么呢,就是用了Deep Q-network来计算A star算法的邻近收益。Q-network的好处是能够计算下一节点的行动成本和启发值,而不用真的走到下一节点。翻译成人话就是:我在脑子里下棋。这就减少了计算开支、降低了内存空间的占用。作者用Q* search来解决魔方问题。解一个需要1872个动作才能完成的魔方,用Q*的好处是,当行动空间(action space)提高了157倍,计算时间只增加了不到4倍,计算内存空间也只增加了不到3倍。Q*相比A*快了129倍,并最多减少1288倍的计算空间。
看完abstract我就知道我不需要看全文了,只草草扫了一眼。如果有兴趣要复现算法并验证的小伙伴们,可以再去深入研究一下整个算法的代码实现,毕竟是强化学习,逻辑比较通俗易懂。想象你在下棋会比较好理解。在每次迭代中,Q* search会从OPEN中弹出一个节点操作元组(s,a),并创建一个新的节点s‘=A(s,a)。Q* search不去向s‘节点行动,而是将DQN应用到s’,以获得其所有下一步行动节点的过渡成本(transition cost)和待执行成本(cost-to-go)的总和。因此,我们只需要计算一次前向DNN,而不是计算|A|。Q* search强制打开所有下一次行动a‘的新节点操作元组(s’,a‘),其中代价是通过sum(通过s节点的路径+对应于下一次行动a’的DQN输出)。在Q* search中,唯一依赖行动空间的变量是OPEN节点。与A* search不同,无论行动空间的大小如何,每次迭代只生成一个节点,而启发式函数每次迭代只需要应用一次。以下post出这个论文里algorithm的伪代码给各位研究:
Algorithm Q* Search Input: starting state s0, DQN qφ OPEN ← priority queue CLOSED ← maps nodes to their path cost a = NO OP f(s0, a0) = mina′ q(s0, a′ ) g(s0) = 0 Push (s0, a, g(s0)) to OPEN with cost f(s0, a0) CLOSED[s0] = g(s0) while not IS EMPTY(OPEN) do (s, a, g(s)) = POP(OPEN) s ′ = A(s, a) if IS GOAL(s ′ ) then return PATH TO GOAL(s ′ ) end if g(s ′ ) = g(s) + g a (s, s′ ) if s ′ not in CLOSED or g(s ′ ) < CLOSED[s ′ ] then CLOSED[s ′ ] = g(s ′ ) q = qφ(s ′ , .) for a ′ in 0 to |A| do f(s ′ , a′ ) = g(s ′ ) + q[a ′ ] Push (s ′ , a′ , g(s ′ )) to OPEN with cost f(s ′ , a′ ) end for end if end while return failure
【Q Transformer】Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions
在这个项目中,作者提出了一种可扩展**的强化学习方法,用于在一个很大的利用人工演示和自动收集的离线数据库里训练多任务策略。这个方法用一个Transformer来提供对离线时间差异备份(temporal difference backups)训练的Q-functions的可扩展表示,所以又称为是Q-Transformer。Q-Transformer离散化每一个动作维度,并且将每一个动作维度的Q值作为独立的token,就得到了高效的高吞吐量序列建模技术,应用于Q-learning。作者用了一系列设计技巧来让离线的Q-Transformer强化学习在大型的复杂的现实世界机器人操作任务组中训练的结果优于以往的强化学习算法和模仿学习技术。这想必就是其被认为达到AGI的魅力之处。
**可伸缩性(可扩展性)是一种对软件系统计算处理能力的设计指标,高可伸缩性代表一种弹性,在系统扩展成长过程中,软件能够保证旺盛的生命力,通过很少的改动甚至只是硬件设备的添置,就能实现整个系统处理能力的线性增长,实现高吞吐量和低延迟高性能。
因github上的论文讲解已经很好地解释了原理,以下为我对其的中文理解和翻译:
Q Transformer方法论

作者首先描述如何通过应用行动空间的离散化和自回归来使用 Transformer 进行 Q-learning。使用 TD-learning进行Q-learning的常规方式是基于Bellman更新规则:
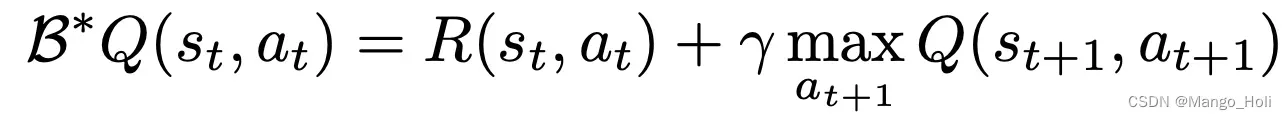

作者为行动空间(棋盘)中的每个动作维度(下棋)修改了Bellman更新规则公式,将原来的马尔科夫决策过程问题转换为对每个动作维度都进行 Q-learning。给定一个动作维度d A,新的Bellman更新规则就是:
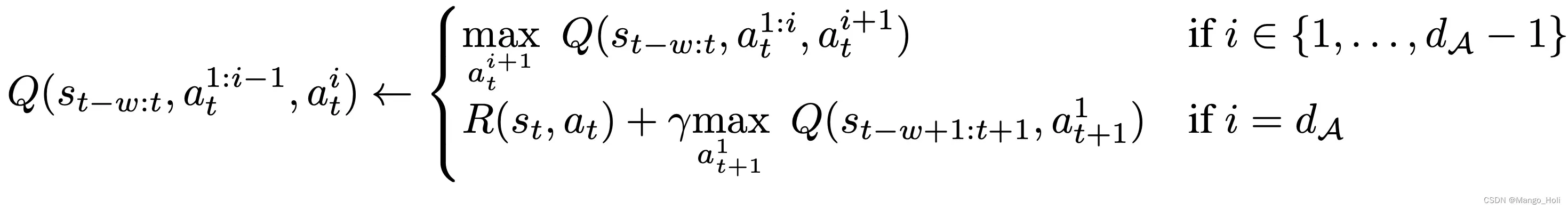

这意味着对于每个中间的动作维度,我们在相同情况下最优化下一个动作维度,并且对于最后一个动作维度,我们用机器人下一个状态的第一个动作维度来连接。这种分解确保Bellman更新规则的最优化很容易处理,同时确保我们仍然解决了马尔科夫决策过程问题。
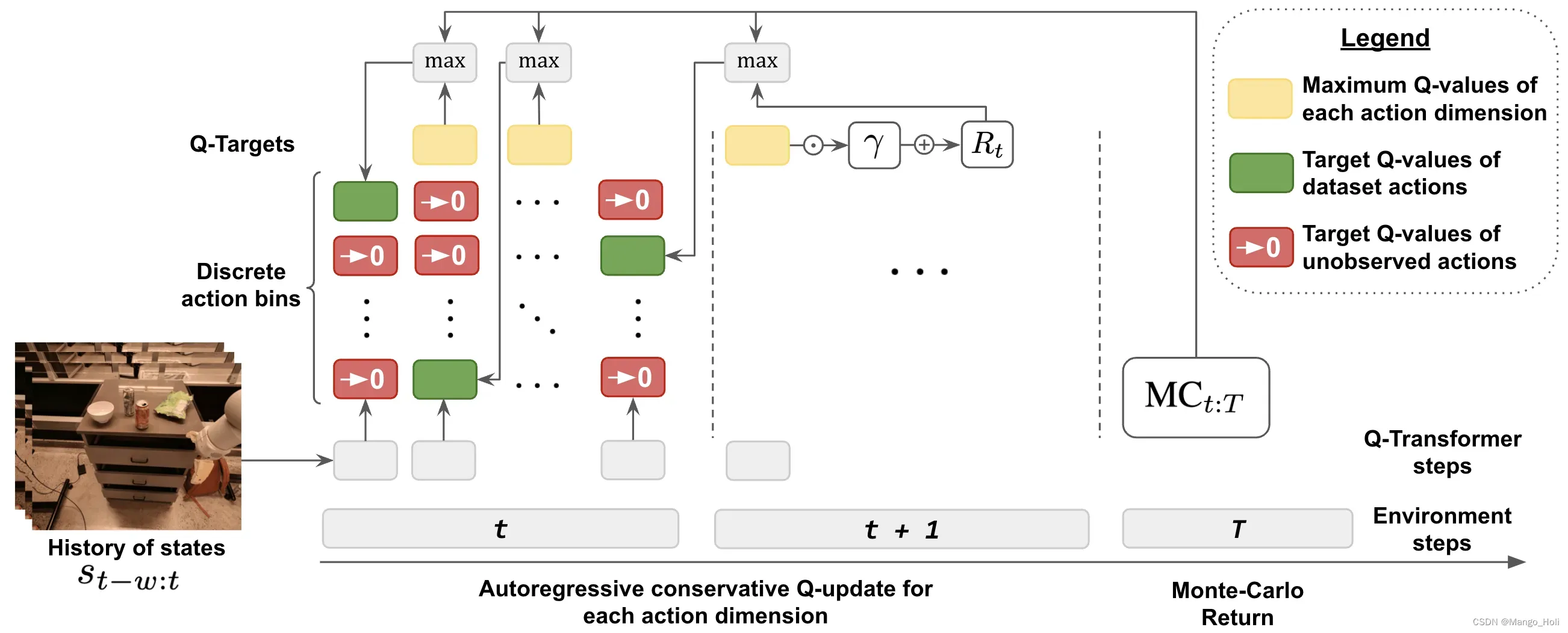

为了计算离线学习的分布变换,我们引入了一种简单的正则化技术,该技术可以将看不见的动作(上图有颜色的方框指的是在离散情况下看不见的动作箱)最小化到最低值,意味着能够逐帧探测动作变化。为了加速学习过程,我们还采用蒙特卡罗方法(T step的MC Return):计算给定动作情节的原始返回值和能省略每个动作维度的最大值的n步返回值。(还要再看论文研究一下)
实验结果
作者首先用 RT-1 论文中的一系列现实世界任务来评估 Q-Transformer,同时限制每个任务只能包含 100 个人类演示数据。除了人类演示之外,作者还添加了自动收集的失败情景视频。最后形成了包含来自人类演示的 38,000 个正面示例和自动收集的 20,000 个负面示例的数据集。
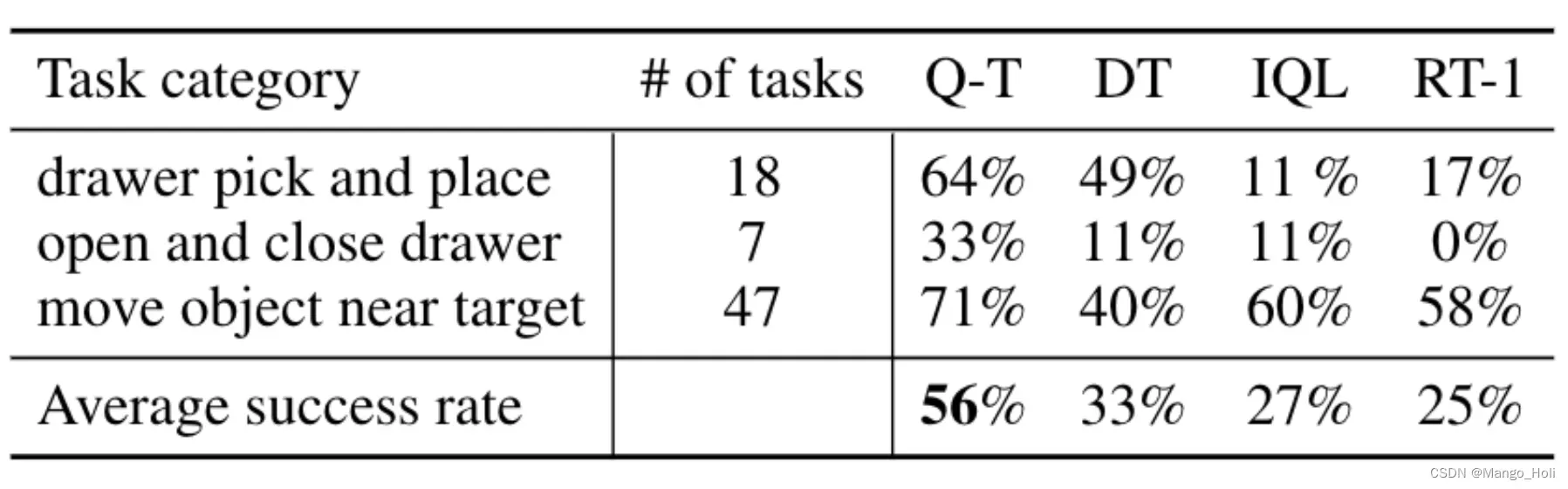

Q-Transformer机械臂执行“挑选物品”任务
与RT-1、 IQL和 Decision Transformer (DT) 等baseline模型相比,Q-Transformer可以有效地利用自动情景视频来显著提高能力,诸如从抽屉中拿出和放进物体、在目标点附近移动物体,以及开关抽屉等技能。
作者还在具有挑战性的模拟“挑选物品”任务中对这个方法进行了基准测试,其中只有约 8% 的数据是正例,其余的是噪声负例。Q-learning,例如 QT-Opt 、 IQL 、 AW-Opt 和 Q-Transformer 在这项任务上通常表现更好,因为它们能够利用负例通过动态编程来学习策略。
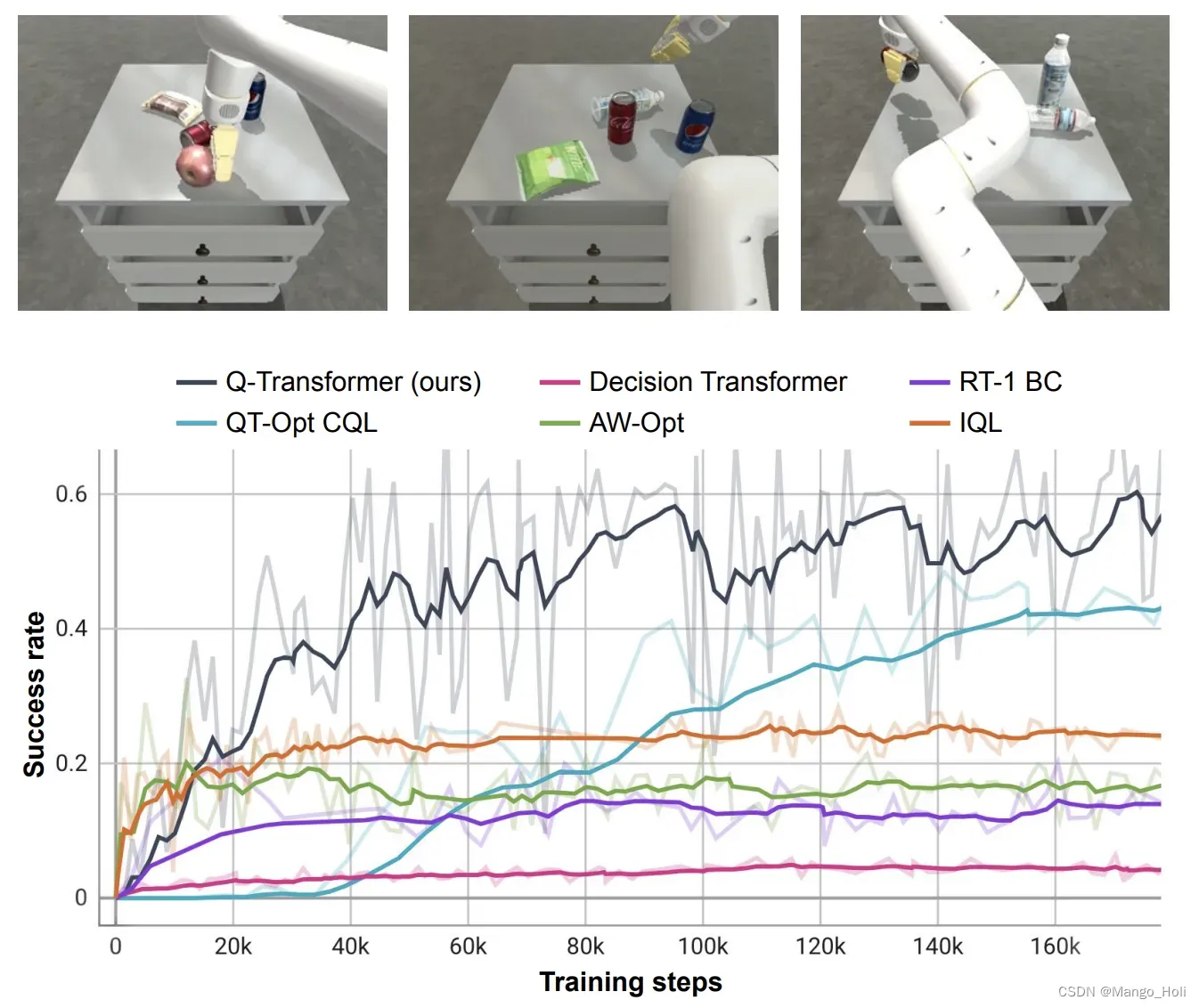

当去除掉在“挑选物品”任务上的决策时,我们注意到conservative正则化项(regularizer)和蒙特卡洛方法(MC return)对于保持性能都很重要。切换到 Softmax(类似于用于 离散动作的CQL)性能明显比较差。原因是它将数据分布和策略选择绑定的太多,这表明我们选择的正则化项(MC return)更适合完成这种任务。
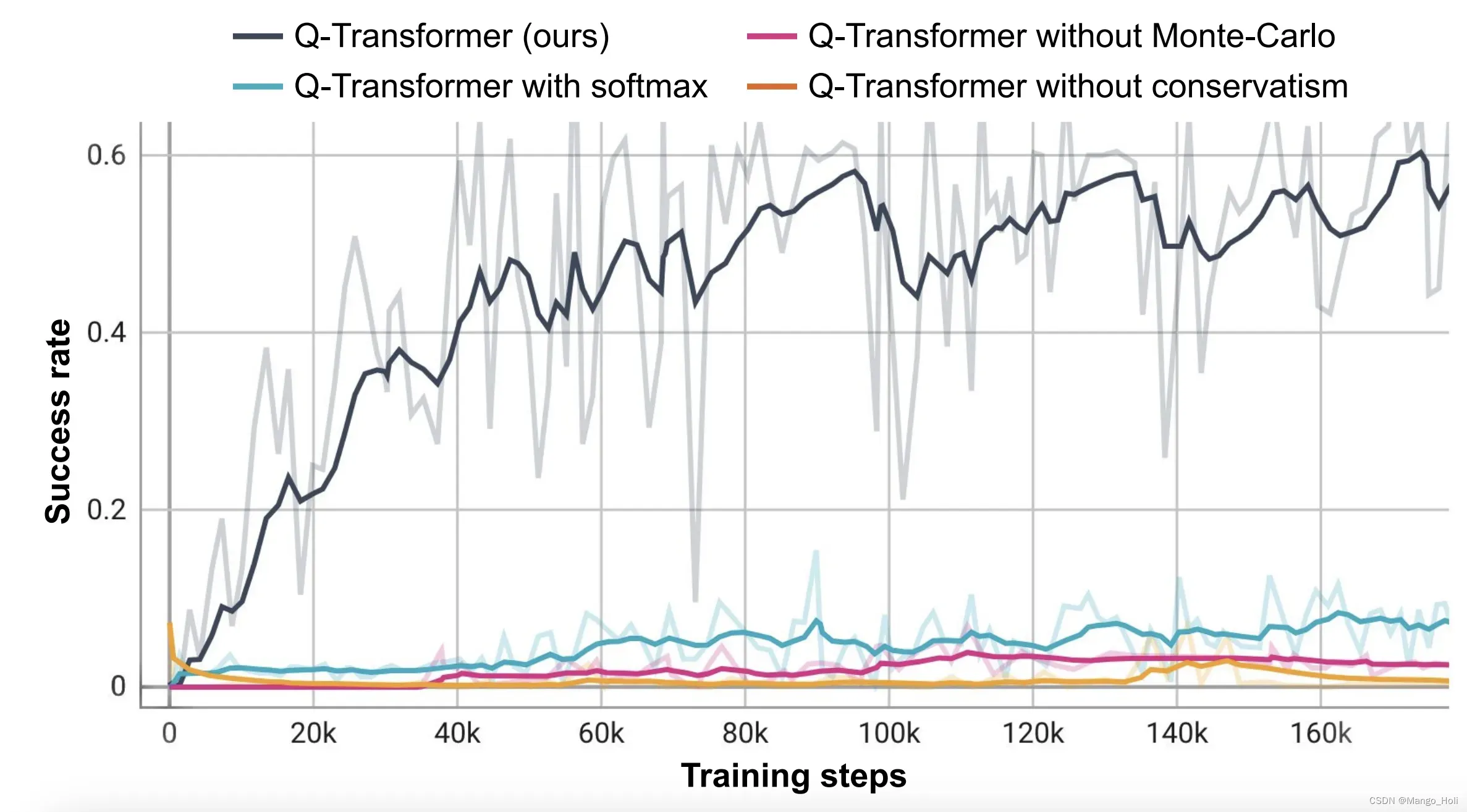
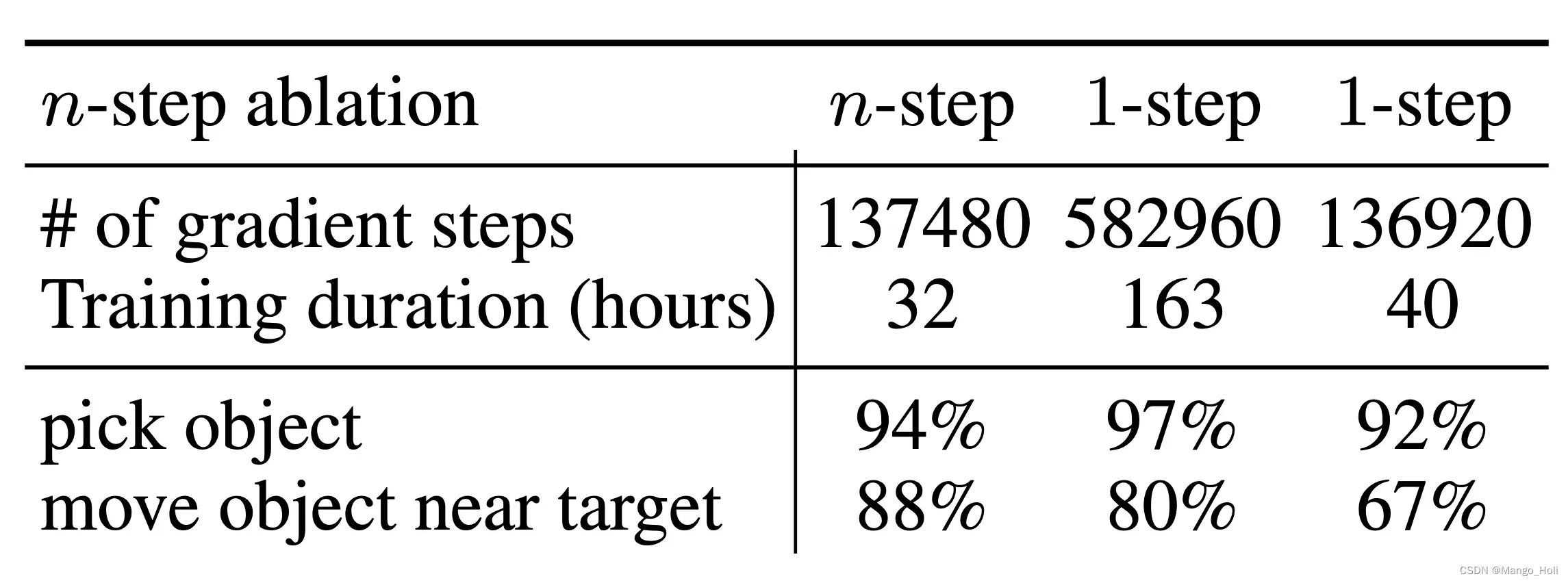
当去除了 n 步返回的影响时,作者注意到引入的偏差值可以帮助我们以更少的梯度实现同样的高性能,使它们成为许多问题的有效选择。

我们还尝试在更大的数据集上运行 Q-Transformer,将正面示例的数量扩大到 115,000 个,将负面示例的数量扩大到 185,000 个,从而产生 300,000 个片段。Q-Transformer 仍然能够从这个大型数据集中学习,甚至比 RT-1 BC 基线提供一些改进。所以说他是可扩展的模型嘛。


最后,我们使用 Q-Transformer 训练的 Q-function作为可视化行动模型,并结合语言规划器,做成类似于 SayCan 的东西。SayCan指的是论文“Do As I Can, Not As I Say: Grounding Language in Robotic Affordances”,论文链接在这里:https://arxiv.org/abs/2204.01691。有空我再研究一下。
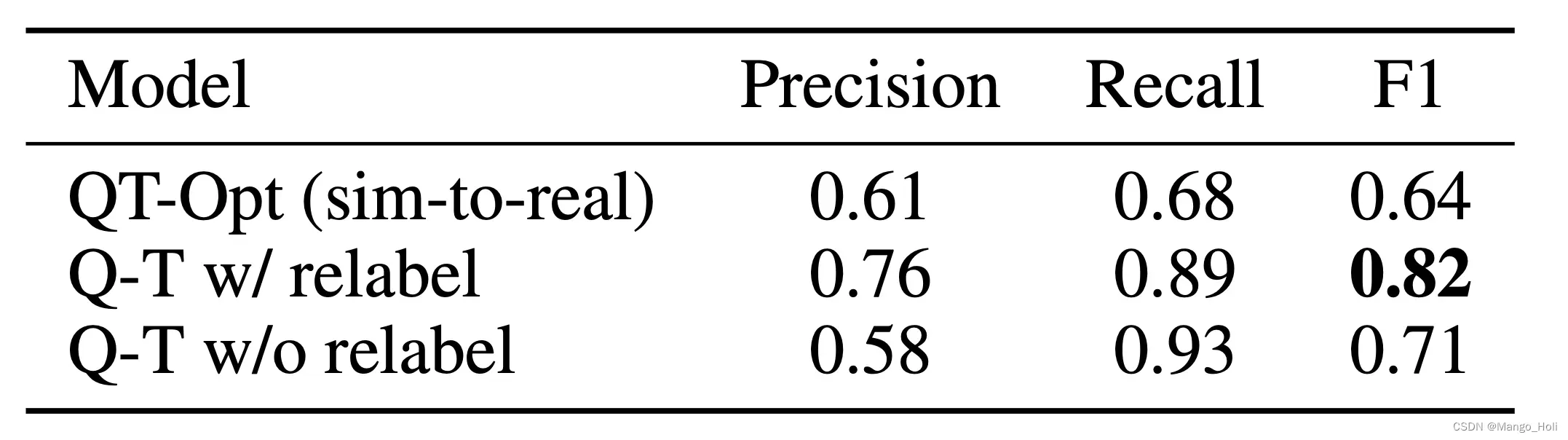

Q-Transformer 可视化行动的规划比之前使用 QT-Opt 训练的 Q-function效果要更好,特别是将其他无样本任务标记为当前任务的训练负样本时。由于 Q-Transformer 不需要像 QT-Opt 那样从仿真到真机做迁移学习(sim-to real transfer),因此更方便在没有模拟环境的情况下使用它。这里指的是类似无人驾驶的学习是有模拟环境的,建筑装修也有,但不会耗费极大的资源来建造一个无意义的制作爆米花的模拟环境,Q-Transformer在只有真实环境的训练数据下也可以学习。
为了测试这套完整的规划+执行系统,作者使用 Q-Transformer 进行可视化行动的规划和实际策略执行,结果显示它确实优于 QT-Opt 和 RT-1 组合。
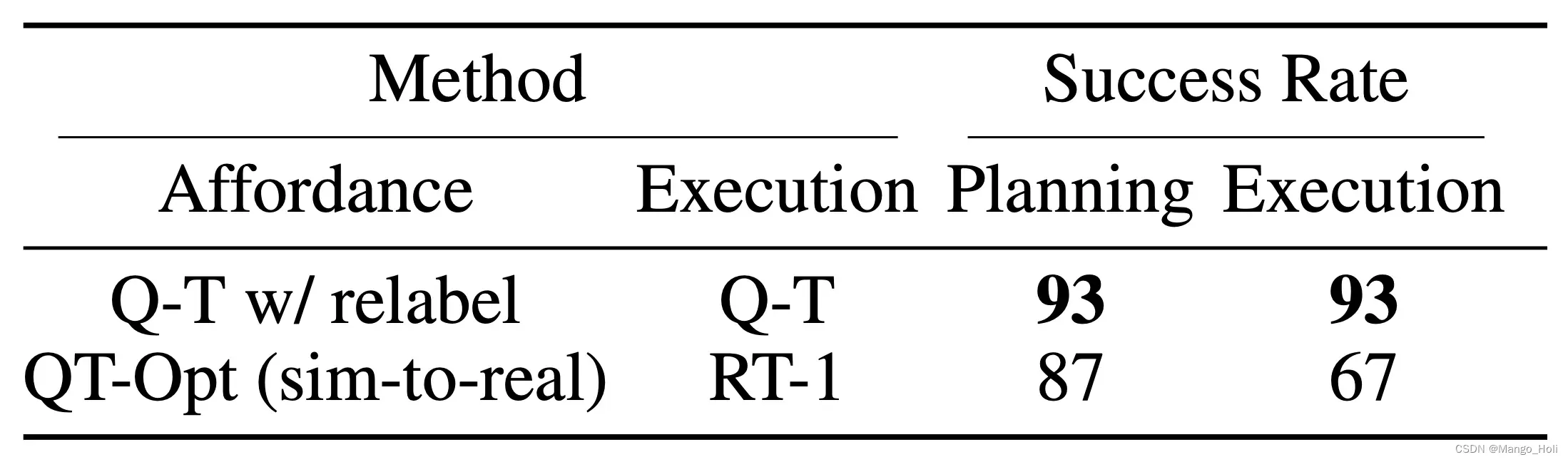

Q-Transformer结合语言规划器(Saycan like)
从给定图像的可视化行动示例中可以看出,Q-Transformer 能够提供可在下游计划和执行框架中使用的高质量可视化行动预测策略。
Q-Transformer大大降低了机器模仿学习人类的计算成本,在一些特定试验场景下的错误率控制在了20%以内,且在某些简单场景下表现非常出色,可能优于一只聪明的小鸡毛宝宝。我只能说一句,Well done,Q-Transformer。
文章出处登录后可见!