



🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、 简介
1.1 Ambari介绍
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Spark等。
1.2 关于本手册
本手册假定您已经通过Ambari完成了HDP的安装,如果您还没有完成安装,请参考:【Ambari】CentOS7.3 内网环境安装Ambari2.7.4+HDP3.1.4(阿里云服务器)_ambari-agent.x86_64.0.2.7.4.0-118下载-CSDN博客。
二、综合运维
您可以在管理界面中可以进行集群、节点和服务级别的管理和运维。在“综合运维”部分,我们将介绍集群和节点级别的管理和运维以及通用的服务管理。
2.1 Ambari一览
Ambari是集群图形化管理应用程序。通过Ambari可视性来控制 Hadoop 集群,您可以轻松地部署、安装、监控和集中操作整个的 HDP集群。如下所示,Ambari承载管理控制台、Web 服务器和应用程序逻辑。它负责安装软件、配置、启动和停止服务,以及管理在集群运行的服务。
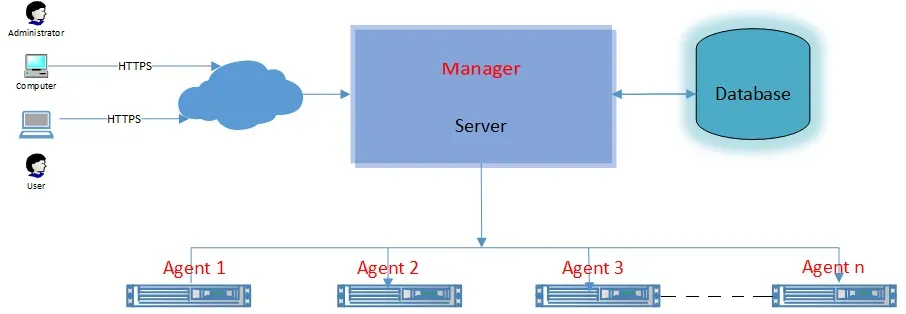

Ambari由以下几部分组成:
- 集群代理(ambari-agent):在集群中的每台主机上都必须安装代理。它负责启动和停止进程,安装、卸载配置、 报警以及监视主机。(Ambari安装时候会自动安装)
- 元数据库:存储系统的配置和监视日志信息。通常有多个逻辑数据库运行在一个或多个数据库服务器。我们默认使用MySQL关系型数据库。
- 服务端(ambari-server):Ambari-server集群安装和配置统一的配置和管理,控制集群代理完成整个集群组件的安装和卸载等基本管理。
2.1.1 命令行操作
通过命令行,您可以启动、停止和重启ambari-server服务。
ambari-server start|stop|restart|status启动、停止和重启ambari-agent及查看当前状态(在对应节点上执行)
ambari-agent start|stop|restart|status

2.1.2 登入和登出
登入
打开客户端浏览器(推荐使用Google Chrome),输入管理节点IP或DNS地址,比如http://192.168.2.161:8180/(192.168.2.161是管理节点IP, 端口号是8080),输入用户名和密码。初次登入时候必须以admin的身份登录,admin的默认密码是admin。


登出
点击用户界面右上角的登入用户名显示下拉式菜单,点击“Sign out”菜单登出系统,如下:


2.1.3. 管理界面首页
管理界面有以下一些重要元素:


三、服务的管理和运维
下面介绍服务相关的管理和运维操作,我们只对HDFS这一个组件的操作进行说明,YARN、HBase等组件操作基本类似,下面我们介绍两种常用的操作:服务重启和配置添加。
3.1 HDFS运维
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
3.1.1 启动/停止/删除HDFS服务
在“HDFS”服务主页面上,将鼠标移至HDFS框的右上角“Action”,出现下拉菜单,您可以点击菜单栏中的选项启动、停止、删除该HDFS服务。
如下红框中的启动、停止等操作是针对整个HDFS服务的操作。
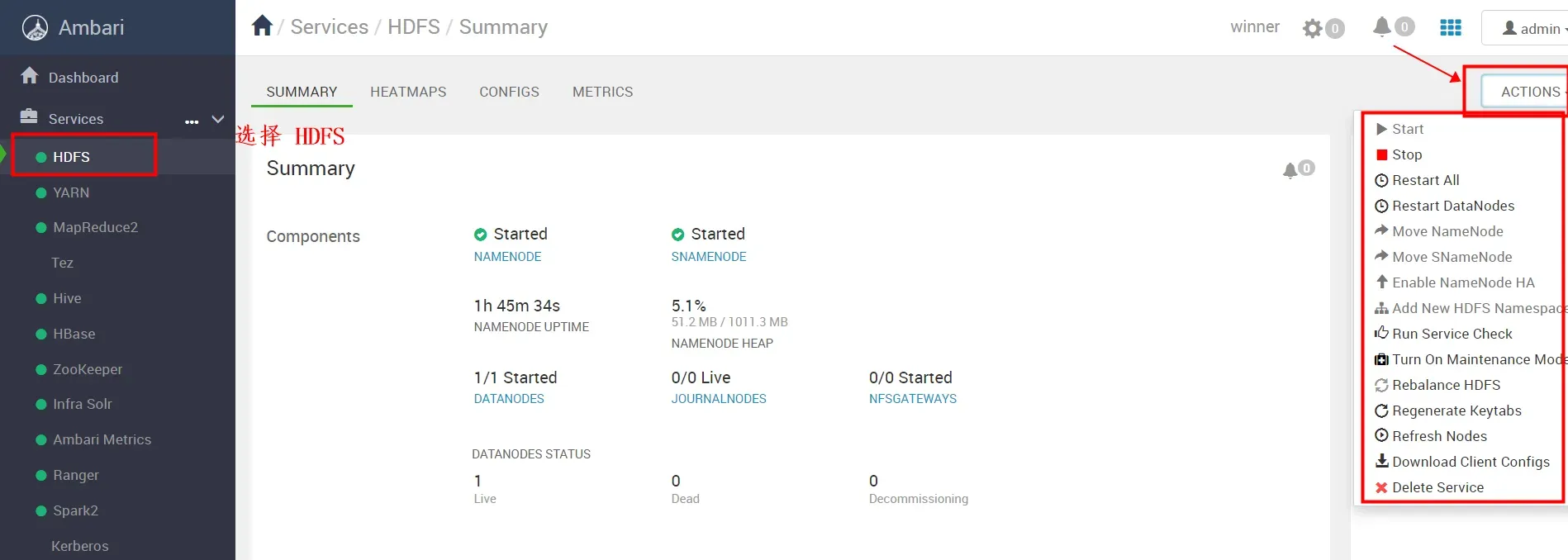

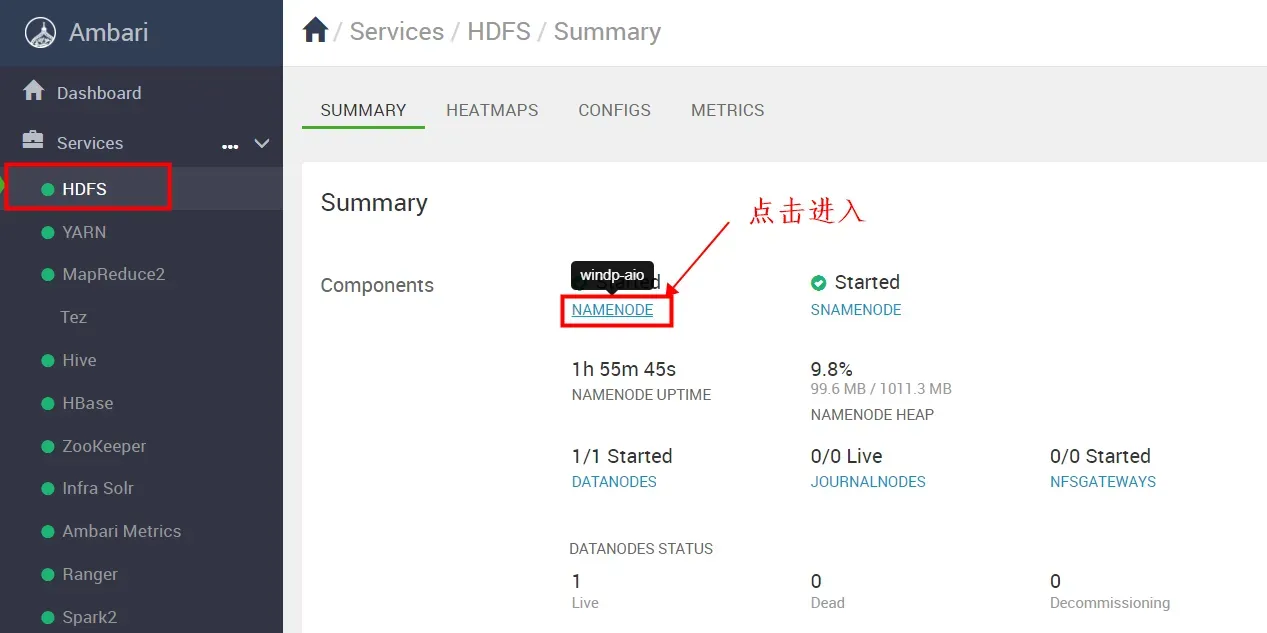
单个服务的启动或停止,我们可以选择点击进入”NAMENODE”服务

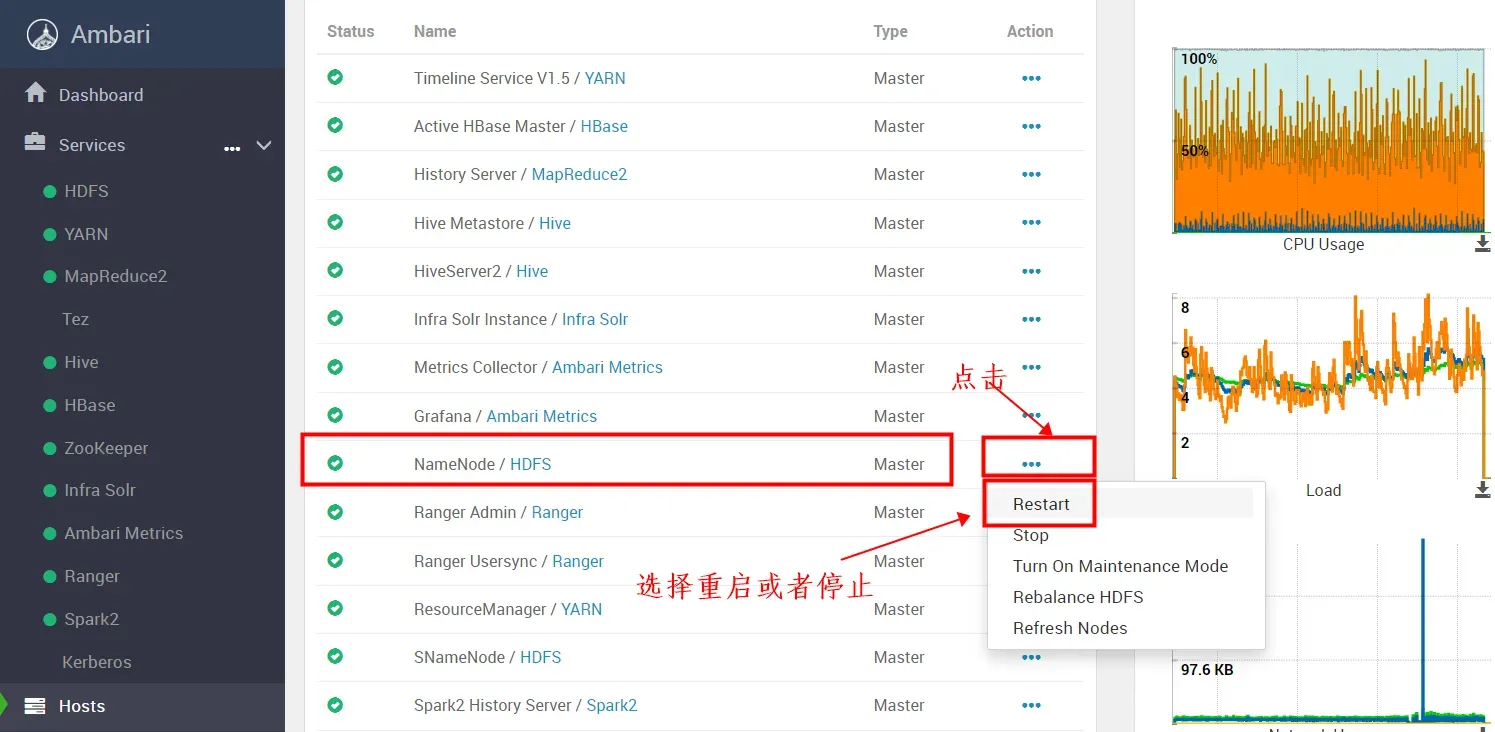
如下图,我们可以对单个服务“NameNode” 选择 restart、stop等操作

3.1.2 HDFS服务的配置
选择config下的“SETTINGS”可以进行基本的配置,包括NameNode和Datanode内存、NameNode和DataNode数据保存目录等。
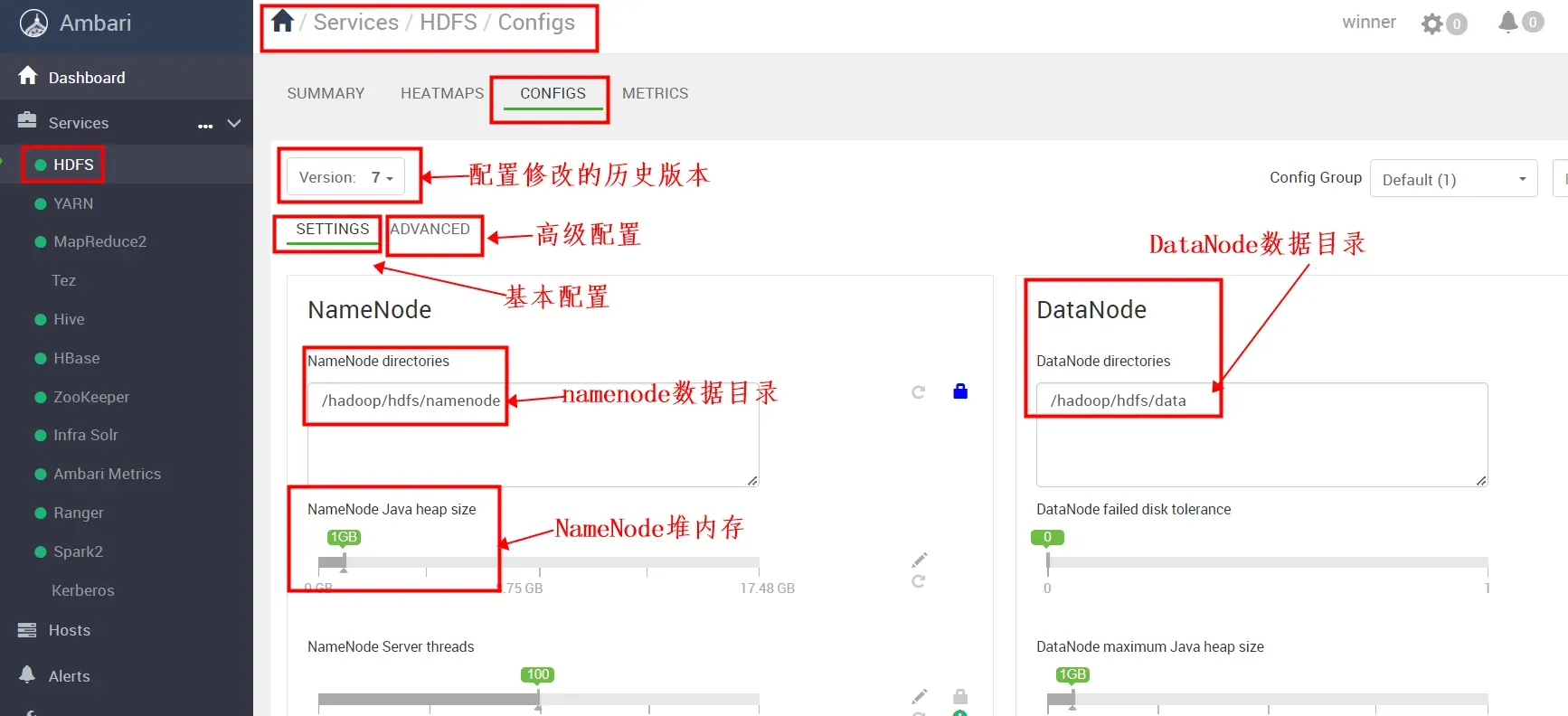

如下图,我们将 “NameNode Java heap size”调整为2G后保存
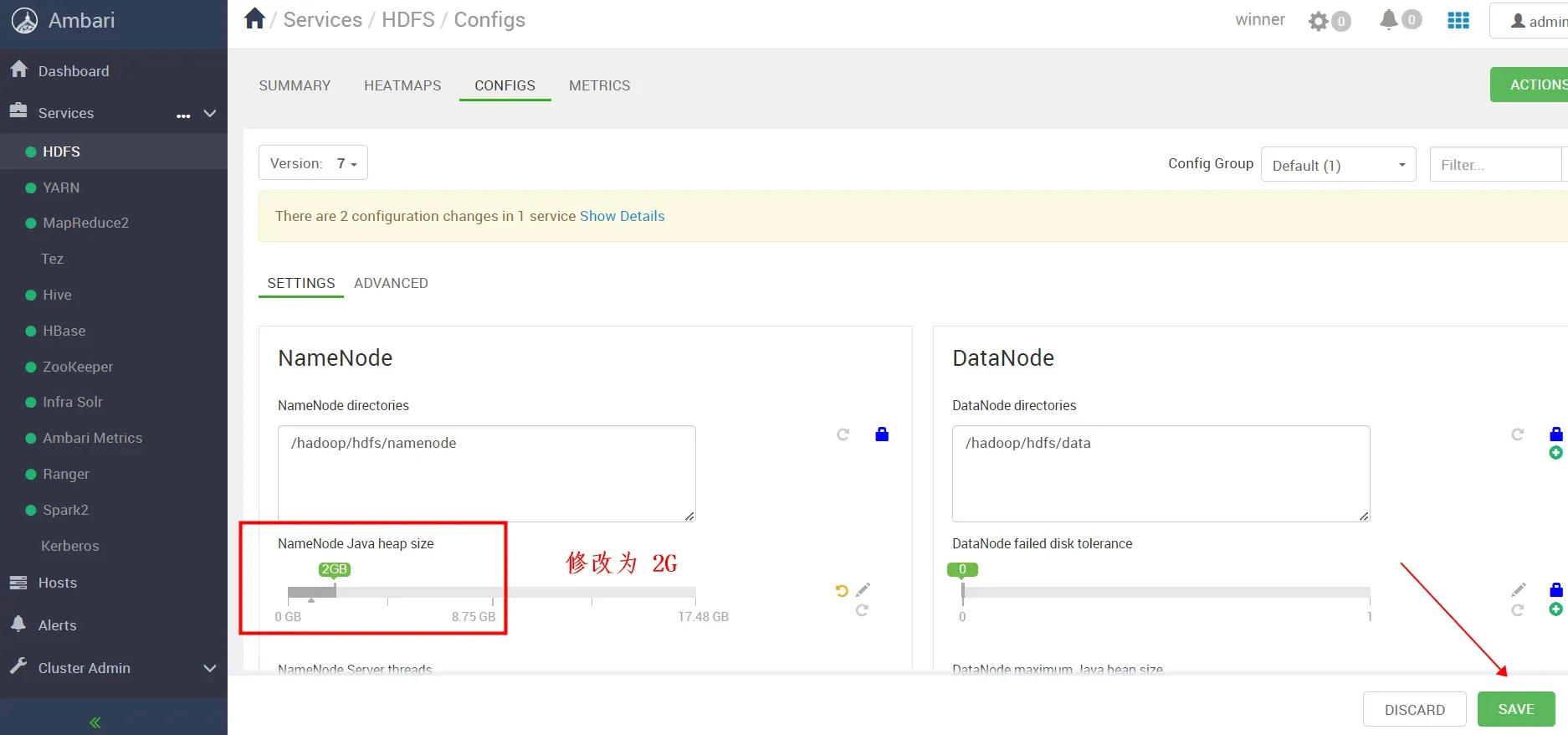

备注操作信息后,选择“save”保存


选择“OK”


选择“PROCESS ANYWAY”


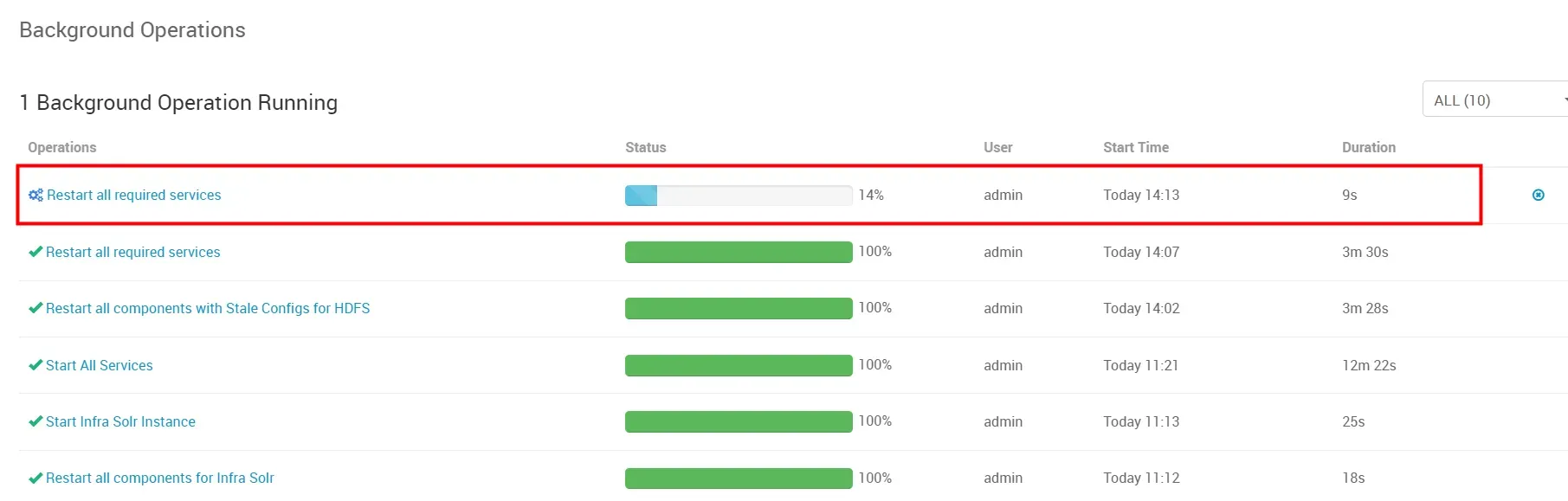
配置修改完成后,需要重启相关服务组件来刷新配置,我们选择 “RESTART All Required”
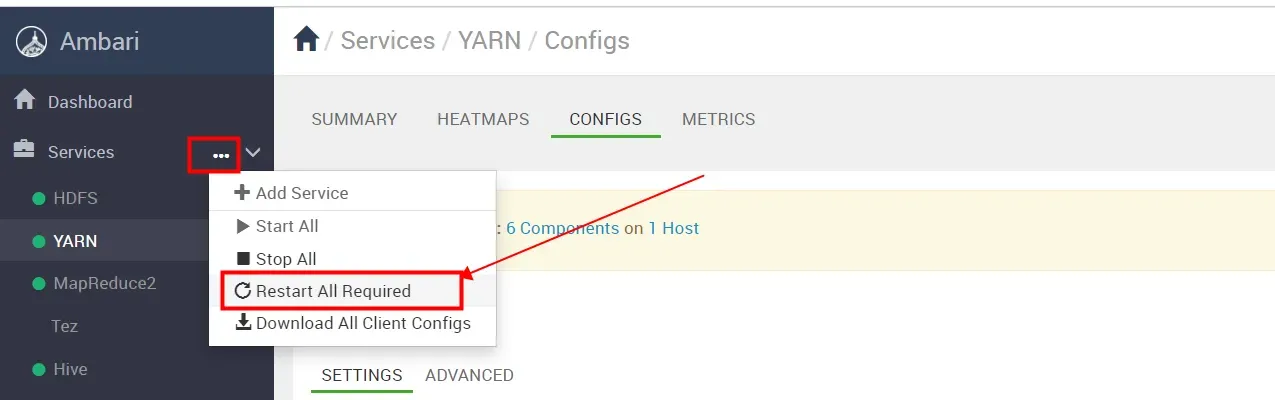

确定全部重启

等待全部重启完成

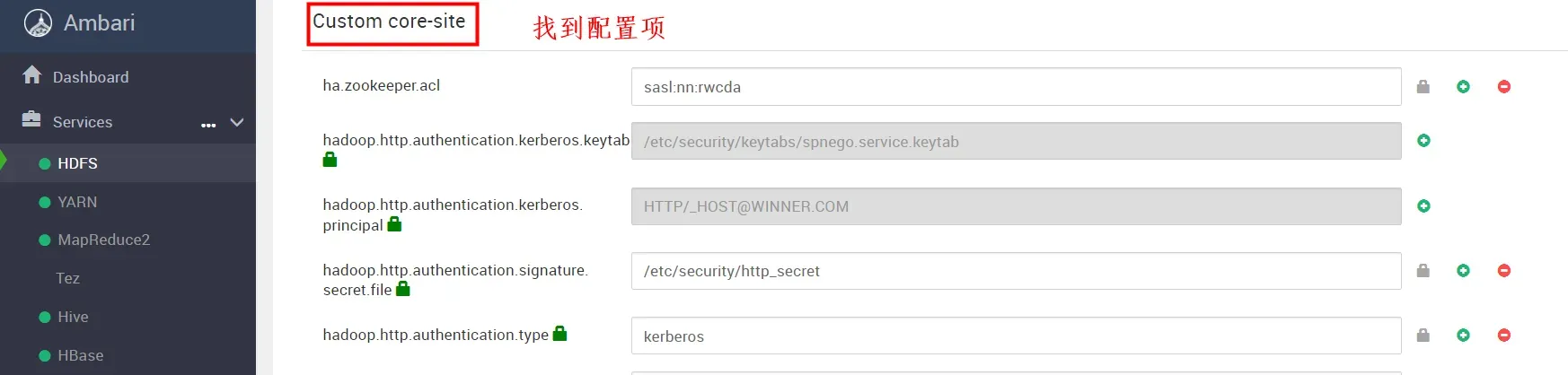
ADVANCED中Customer Core-site增加配置

找到 “Customer core-site”

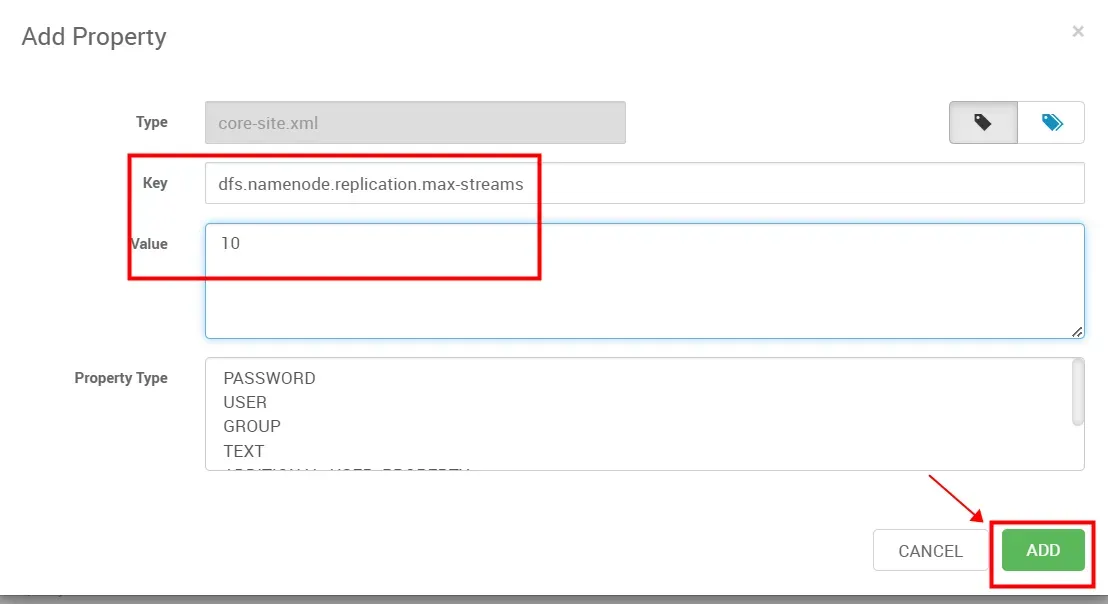
选择“Add Property”
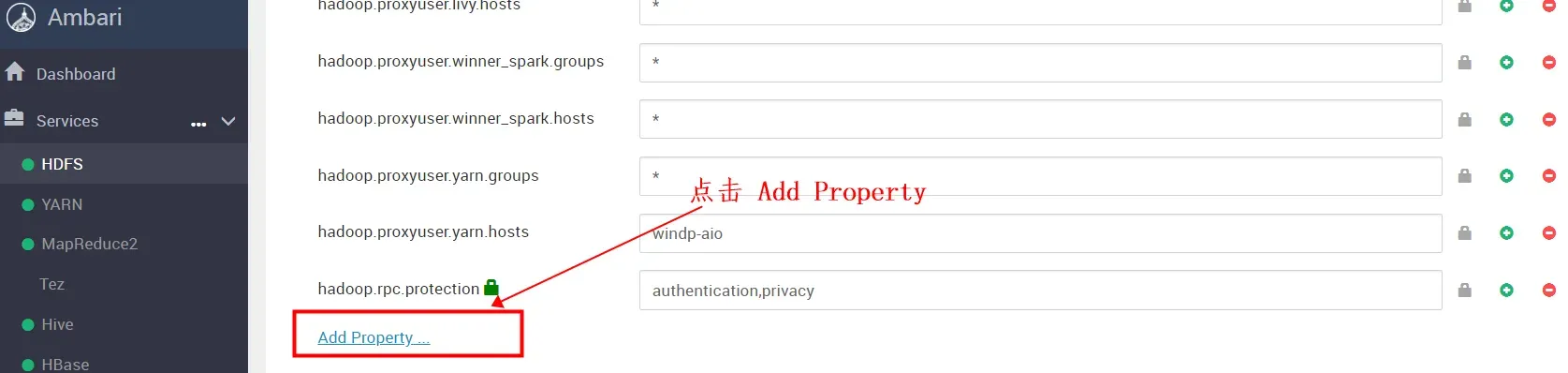

将如下的键值对关系配置到对应的页面,要添加三次
dfs.namenode.replication.max-streams 10
dfs.namenode.replication.max-streams-hard-limit 20
dfs.namenode.replication.work.multiplier.per.iteration 10

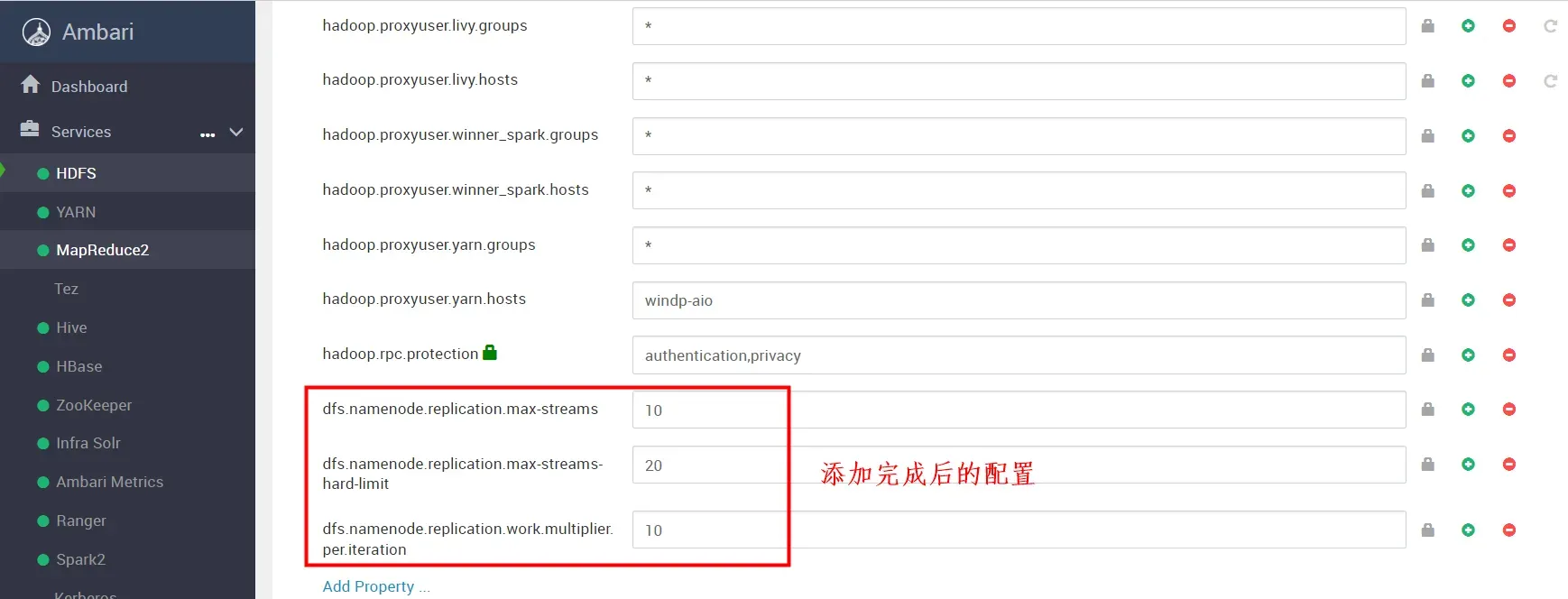
添加完成后的配置,添加完成后选择“save”保存

备注操作信息后,选择“save”保存

选择“PROCESS ANYWAY”


配置修改完成后,需要重启相关服务组件来刷新配置,我们选择 “RESTART All Required”
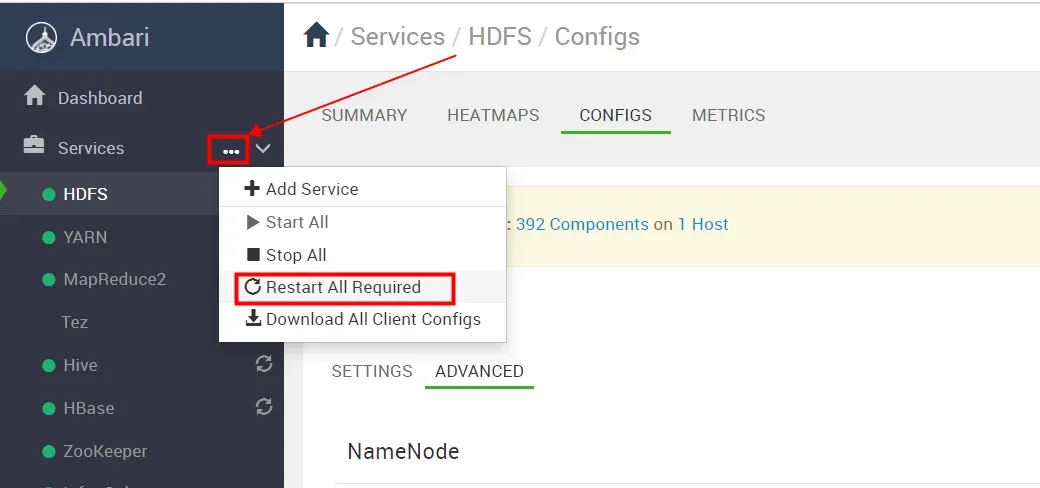

确定全部重启

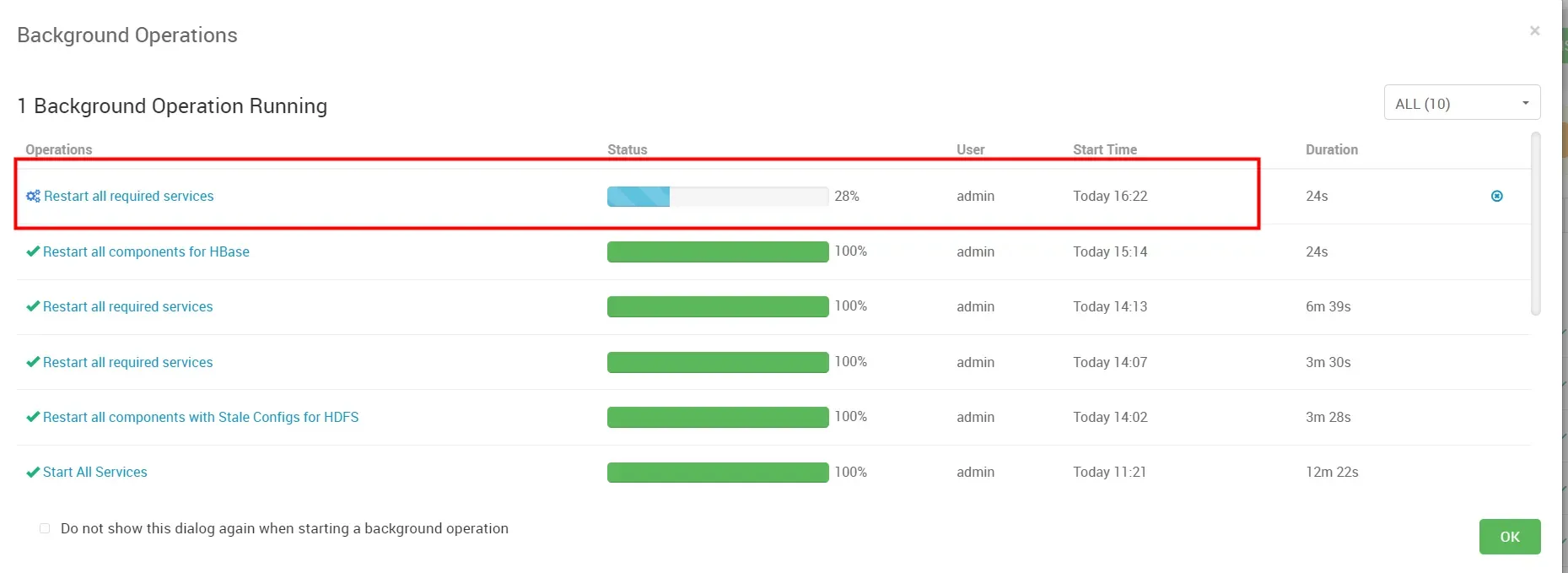
等待重启完成,重启完成后配置生效。

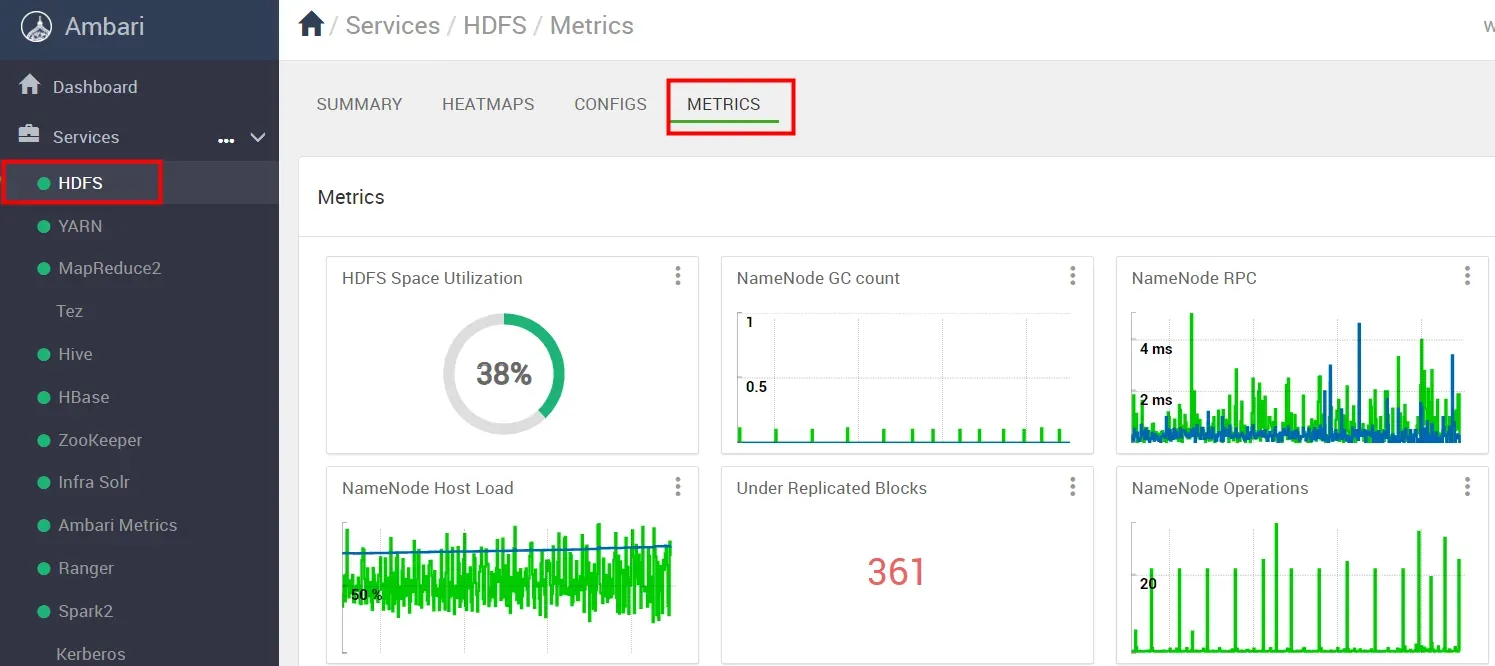
3.1.3 HDFS服务监控
如下图,Metrics 是监控信息,包括NameNode内存,RPC,Heap、Load、blocks数等监控项。

对于HDFS、HBase、YARN等服务组件,我们上面只列举了重启和配置修改等操作,更多的复杂操作建议联系大数据工程师完成。
文章出处登录后可见!