


Alpaca(https://github.com/tatsu-lab/stanford_alpaca)在70亿参数的LLaMA-7B上进行微调,通过52k指令数据(https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json),在8个80GB A100上训练3小时,在对话上的性能比肩GPT-3.5。
目录
- 指令微调数据来源:self-instruct
- Alpaca-LoRA
- 微调LLaMA-7B
指令微调数据来源:self-instruct
52k数据所对应的alpaca_data.json是一个字典列表,每个字典包含以下字段:
- instruction:52k条指令中的每一条都是唯一的;
- input:可以是空的(以instruction作为上下文),也可以是与instruction相关的文本;
- output:由GPT3.5的API生成的对应回答。
比如在中文版52k指令(https://github.com/hikariming/alpaca_chinese_dataset)中:
[
{
"instruction": "\"给出三个保持健康的小贴士。\"",
"input": "",
"output": "1. 饮食要均衡,确保摄入足够的水果和蔬菜。\n2. 经常锻炼,保持身体活跃和强壮。\n3. 要保证充足的睡眠,并保持一个稳定的睡眠时间表。"
},
{
"instruction": "\"三原色是什么?\"",
"input": "",
"output": "\"三原色是红色、蓝色和黄色。\""
},
...
{
"instruction": "将以下内容分类为动物、植物和矿物。",
"input": "\"橡树,铜矿石,大象\"",
"output": "\"橡树:植物\n铜矿石:矿物\n大象:动物\""
},
]
关于52k数据,是通过openAI的API用self-instruct方式生成的,花费500美元,self-instruct是将预训练语言模型与指令对齐的方法(https://github.com/yizhongw/self-instruct):
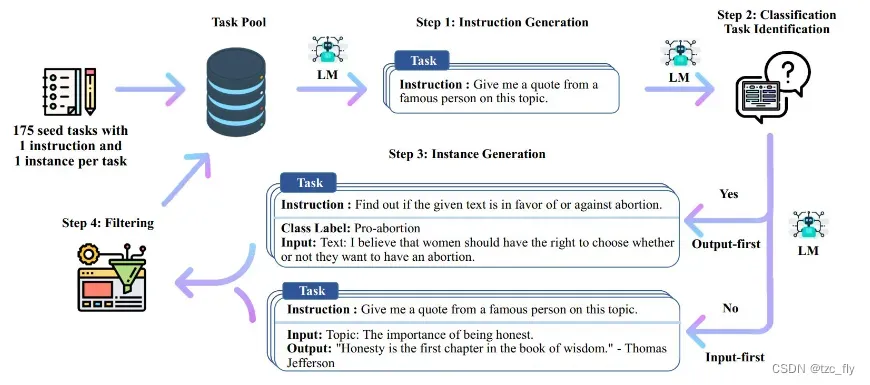
一共包含4个步骤:

- Step1:通过模型生成新的指令,根据人工设计的175个任务,每个任务都有对应的(指令,输入,输出)或(指令,输出);使用模型生成新的指令;
- Step2:对模型生成的指令进行判断(指令是否是一个分类任务);
- Step3:根据Step2的判断结果,给出不同的输出,
如果是分类任务,就通过模型输出 Class_label 和 Input(Output-first);
如果不是分类任务,就通过模型输出 Input 和 Output(Input-first); - Step4:过滤及后处理,对上述模型生成的数据进行过滤和后处理,将经过过滤和后处理的数据添加到种子池中。
对于以上4个步骤进行不断循环,直到种子池有足够多的数据(通常会设定一个具体的参数,比如:52000),生成过程停止。
比如在项目 https://github.com/yizhongw/self-instruct 中,依次执行:
# 1. Generate instructions from the seed tasks
./scripts/generate_instructions.sh
# 2. Identify whether the instruction represents a classification task or not
./scripts/is_clf_or_not.sh
# 3. Generate instances for each instruction
./scripts/generate_instances.sh
# 4. Filtering, processing, and reformatting
./scripts/prepare_for_finetuning.sh
175个人工设计的种子任务在 https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl 中:
{"id": "seed_task_0",
"name": "breakfast_suggestion",
"instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?",
"instances":
[{
"input": "",
"output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."
}],
"is_classification": false}
...
{"id": "seed_task_174",
"name": "fact_checking",
"instruction": "Fact checking - tell me if the statement is true, false, or unknown, based on your knowledge and common sense.",
"instances":
[{
"input": "Philadelphia is among the top 10 safest cities in the US.",
"output": "false"
}],
"is_classification": true}
执行:
python self_instruct/bootstrap_instructions.py --batch_dir "自己定义的目录,比如data/gpt3.5" --num_instructions_to_generate 100 --seed_tasks_path data/seed_tasks.jsonl --engine "davinci" --api_key "自己的openai API"
上述指令生成100条数据,这只会产生较少费用,生成数据会写入data/gpt3.5/machine_generated_instructions.jsonl中,这些数据是通过openAI的API生成了与种子任务关联度比较弱的一些任务描述(因为相似度高的对微调没有用)。
然后判断是否为分类任务:
python self_instruct/identify_clf_or_not.py --batch_dir data/gpt3.5 --engine "davinci" --request_batch_size 5 --api_key "自己的openai API"
结果写入data/gpt3.5/is_clf_or_not_davinci_template_1.jsonl中,然后根据步骤2的结果生成输出:
python self_instruct/generate_instances.py --batch_dir data/gpt3.5 --input_file machine_generated_instructions.jsonl --output_file machine_generated_instances.jsonl --max_instances_to_gen 5 --engine "davinci" --request_batch_size 5 --api_key "自己的openai API"
结果写入 data/gpt3.5/machine_generated_instances.jsonl中,然后进行过滤和后处理:
python self_instruct/prepare_for_finetuning.py --instance_files data/gpt3.5/machine_generated_instances.jsonl --classification_type_files data/gpt3.5/is_clf_or_not_davinci_template_1.jsonl --output_dir data/gpt3.5/finetuning_data --include_seed_tasks --seed_tasks_path data/seed_tasks.jsonl
运行后会生成两个数据文件,均在data/gpt3.5/finetuning_data目录下:
- all_generated_instances.jsonl,all_generated_instances.jsonl中包含的是 instruction,input,output,这是用于微调LLaMA-7B的格式。
- gpt3_finetuning_data_xxx.jsonl,包含的是prompt,completion,这是用于微调GPT3的格式。
Alpaca-LoRA
LoRA可以降低微调LLM的成本,在神经⽹络模型中,模型参数通常以矩阵的形式表示。对于⼀个预训练好的模型,其参数矩阵已经包含了很多有⽤的信息。为了使模型适应特定任务,需要对这些参数进⾏微调。LoRA是一种思想:用低秩的方法调整参数矩阵,低秩表示一个矩阵可以用两个小矩阵相乘近似(LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)。
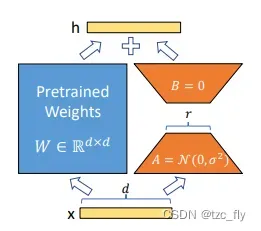
LoRA包含以下步骤:

- 1.选择目标层:首先,在预训练神经网络模型中选择要应用LoRA的目标层,这些层通常是与特定任务相关的,比如自注意力机制中的Q和K矩阵;
- 2.初始化映射矩阵和逆映射矩阵:为目标层创建两个较小的矩阵A和B;
A是映射矩阵,一般用随机高斯分布初始化,deepspeed chat中用LoRA策略时则通过0矩阵占位,A矩阵用于降维;
B是逆映射矩阵,用0矩阵初始化,用于升维; - 3.参数变换:将目标层的原始参数矩阵W通过A和B进行变换:
- 4.微调:使用
- 5.梯度更新:在微调过程中,计算损失函数关于映射矩阵A和逆映射矩阵B的梯度,并使⽤优化算法,如Adam、SGD对A和B进⾏更新,注意,在更新过程中,原始参数矩阵W保持不变,即训练的时候固定原始LLM的参数,只训练A和B;
- 6.重复更新:重复步骤3-5,直到达到预定的epoch或模型收敛。

HuggingFace已经将LoRA封装到了PEFT中(Parameter-Efficient Fine-Tuning),PEFT库可以使预训练语⾔模型⾼效适应各种下游任务,⽽⽆需微调模型的所有参数,即仅微调少量模型参数,从⽽⼤⼤降低了计算和存储成本。
历史:
Alpaca率先带动self-instruct,启发后续的人也采用提示GPT API的方式生成数据,比如BELLE、ChatLLaMA、ColossalChat,从而解决数据扩展的问题。然后又有新的LLM用Alpaca去生成新的数据进行微调,⽐如ChatDoctor ⽤到Alpaca的数据进⾏微调,有⼈用BELLE数据微调chatGLM。

微调LLaMA-7B
下载Alpaca-LoRA项目,并安装所需的依赖:
$ git clone https://github.com/tloen/alpaca-lora.git
$ pip install -r requirements.txt
下载预训练模型的权重,以及斯坦福进一步清洗后的微调数据(原本的52k数据中存在一些有问题的信息):
$ git clone https://huggingface.co/decapoda-research/llama-7b-hf
$ git clone https://huggingface.co/datasets/yahma/alpaca-cleaned
预训练模型包含33个405MB的bin文件,大约占14GB内存。
在alpaca-lora-main/finetune.py中,设置batch_size=4(micro_batch_size: int = 4)以适配16GB的单个GPU(显存占用9GB),由于微调时间很长,大约60h,所以新建finetune.sh后台运行:
nohup python -u finetune.py \
--base_model '/data/temp/my-alpaca-lora/llama-7b-hf' \
--data_path '/students/julyedu_636353/alpaca-lora-main/alpaca-cleaned' \
--output_dir '/data/temp/my-alpaca-lora' \
>> log.out 2>&1 & # 后台运行, 日志写到 log.out
可以直接获取已经训练好的LoRA权重(67MB):
git clone https://huggingface.co/tloen/alpaca-lora-7b
或者获取通过GPT4生成指令数据微调后的LoRA权重(模型为LLaMA-7B,主要微调方式为Alpaca,低成本的微调策略为LoRA),故称LoRA权重为适配器adapter weights,GPT4对应的LoRA权重也应该是67MB:
git clone https://huggingface.co/chansung/gpt4-alpaca-lora-7b
利用alpaca-lora-main/generate.py进行推理,其中使用import gradio as gr实现了快捷的可视化界面,新建inference.sh,推理时占用显存8GB:
python generate.py \
--load_8bit \
--base_model '/data/temp/my-alpaca-lora/llama-7b-hf' \
--lora_weights 'home/user/alpaca-lora-main/gpt4-alpaca-lora-7b'
对于一个问题,单个GPU上生成所需时间依旧很慢,大约1分钟,示例如下:
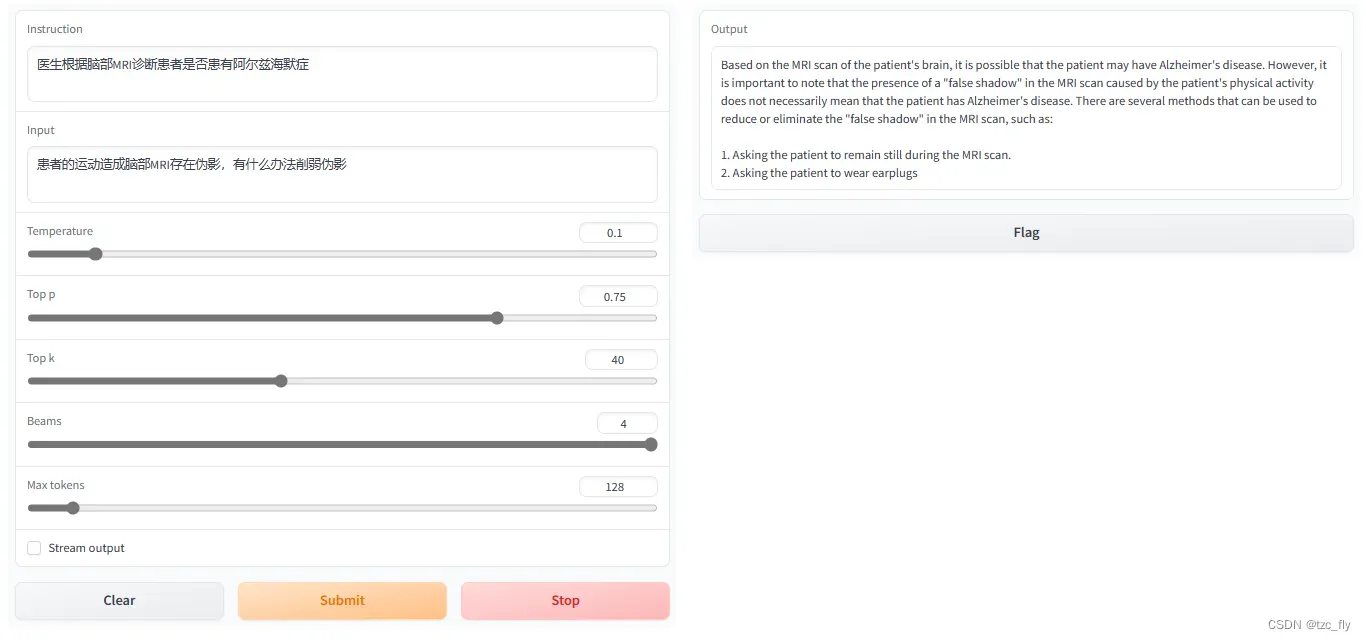

再尝试一个新问答:


也可以只使用instruct进行问答:


文章出处登录后可见!