

Stable Diffusion于2022-08-23开源,点击体验
扩散模型的定义与采样方法
扩散模型通过定义一个不断加噪声的前向过程来将图片逐步变为高斯噪声,再通过定义了一个逆向过程将高斯噪声逐步去噪变为清晰图片以得到采样。
在采样过程中,根据是否添加额外的噪声,可以将扩散模型分为两类:一类是扩散随机微分方程模型(Diffusion SDE),另一类是扩散常微分方程(Diffusion ODE)。两种模型的训练目标函数都一样,通过最小化与噪声的均方误差来训练一个“噪声预测网络”。
Stable Diffusion WebUi简称 SDWebUi,web UI是一个基于 Gradio 库的 Stable Diffusion 浏览器界面。
1. 安装miniconda,创建虚拟环境(略)
2. 更换pypi源为国内源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple3. 下载安装依赖
- 下载 web ui 框架并进入路径
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitcd stable-diffusion-webui
- 下载 StableDiffusion(绘图) 和 CodeFormr(脸部修复)
mkdir repositoriesgit clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusiongit clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformersgit clone https://github.com/sczhou/CodeFormer.git repositories/CodeFormergit clone https://github.com/salesforce/BLIP.git repositories/BLIP
- 下载安装k-diffusion
pip install git+https://github.com/crowsonkb/k-diffusion.git --prefer-binary
- 下载gfpgan 可选 负责脸部修复face restoration
pip install gfpgan
- 安装之前下载的CodeFormer的依赖
pip install -r repositories/CodeFormer/requirements.txt --prefer-binary
- 安装 web ui框架的依赖
pip install -r requirements.txt --prefer-binary
- 更新numpy到最新版本(因为之前很多包都会引用到
numpy所以为了保证版本统一,在此更新为最新版)pip install -U numpy --prefer-binary
- 安装其它包
- pip install clip
- pip install opencv-python-headless
4. 下载模型文件
huggingface权限申请
目前stable diffusion的模型都已经在huggingface上开源发布了,主页上也说明了具体的使用方法,但是由于这种生成式的模型容易被滥用,因此使用受限无法直接下载,还需要在huggingface上注册个人账号后申请使用。
注册账号后,在https://huggingface.co/settings/tokens可以得到对应的Access repository,就可以下载模型了。
模型列表:Stable Diffusion Models
(可以多个模型并存,根据需要在画图过程中在页面左上角切换) 位置一律放在/stable-diffusion-webui/models/Stable-diffusion/ 下
5. 运行launch.py,安装最后的依赖
python3 launch.py --port 8090 --listen安装完依赖后,以后再运行可直接执行webui.py
python webui.py --port 8090 --listen6. 启动成功后,在浏览器输入URL即可访问

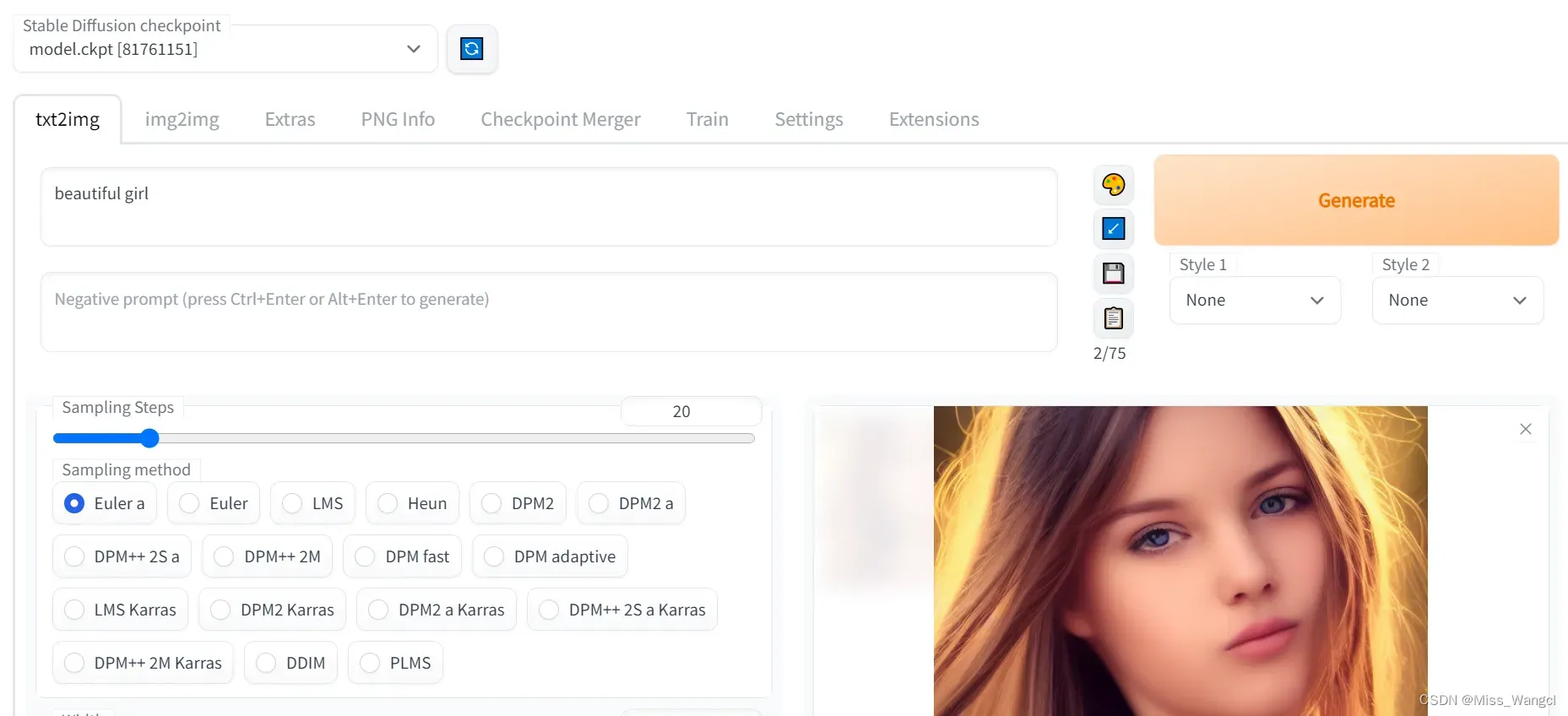

【Prompt 里填写想要的特征点,Negative prompt 里填不想要的特征点】
温馨提示:Prompt 里最大只支持 77 个词,多了会报错,删掉几个词就行
文章出处登录后可见!
已经登录?立即刷新