

最近在看stable diffusion,想梳理一下代码流程,以便之后查阅
从txt2img.py开始看
1.首先是对文本进行编码


(1)调用的是 stable-diffusion/ldm/models/diffusion/ddpm.py的get_learned_conditioning函数
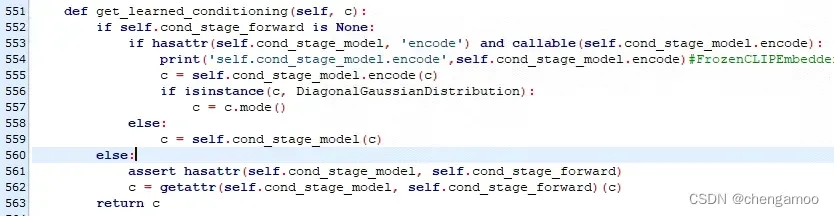

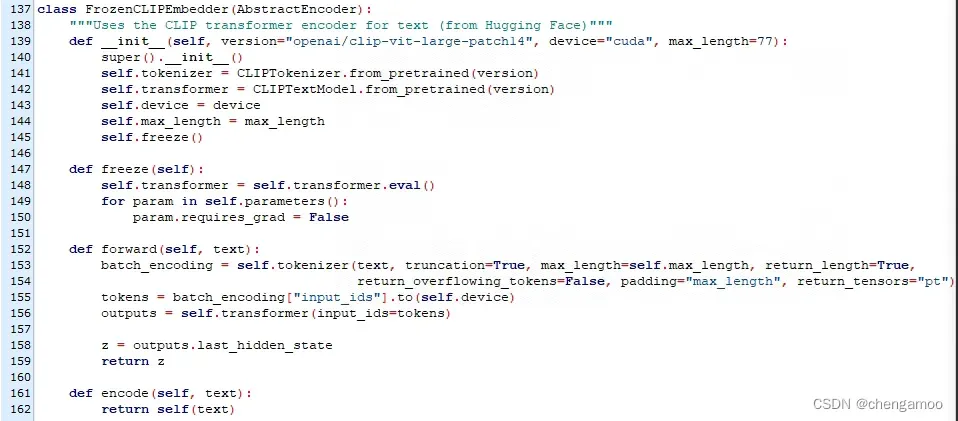
(2) 第555行表示使用CLIP的文本编码器对输入的文本进行编码,调用的是stable-diffusion/ldm/modules/encoders/modules.py中的FrozenCLIPEmbedder类

2.进行采样操作


(1)调用plms中的采样操作,在stable-diffusion/ldm/models/diffusion/plms.py中
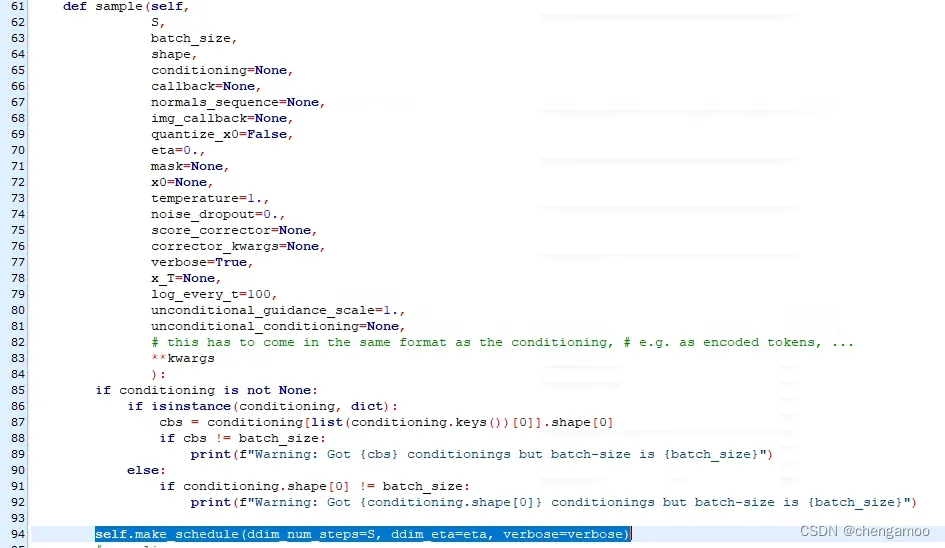



(2)调用self.plms_sampling函数
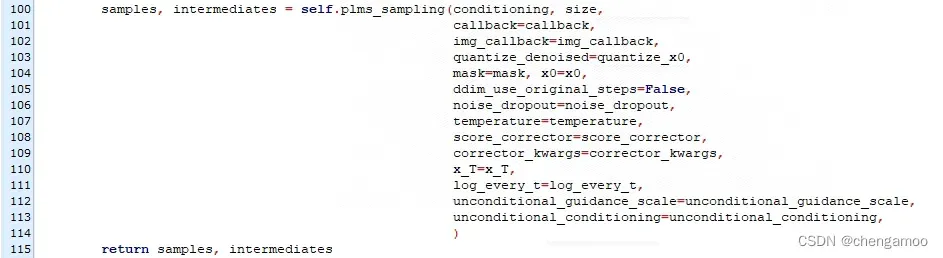

时间步的循环是从这里开始的
调用self.p_sample_plms函数



![]()

调用同文件下的DiffusionWrapper类,key=”crossattn”,c_crossattn=torch.cat([unconditional_conditioning, c])
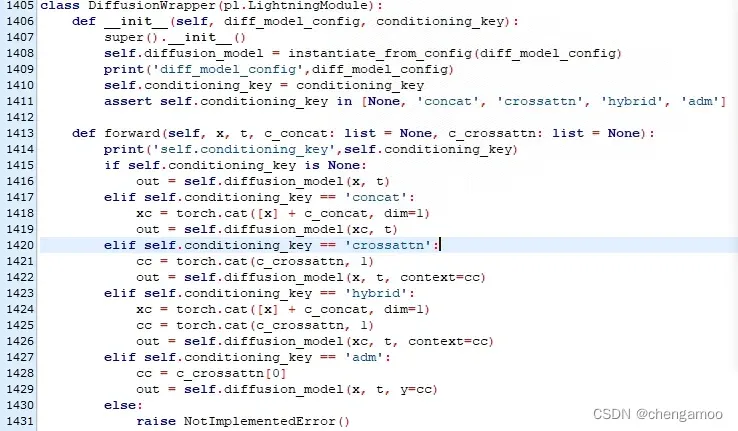



self.input_blocks的定义为


TimestepEmbedSequential的定义为


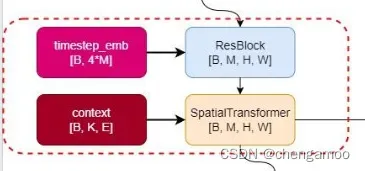
其中,TimestepBlock类型的layer为ResBlock,TimestepEmbedSequential的结构图可以表示成下图。

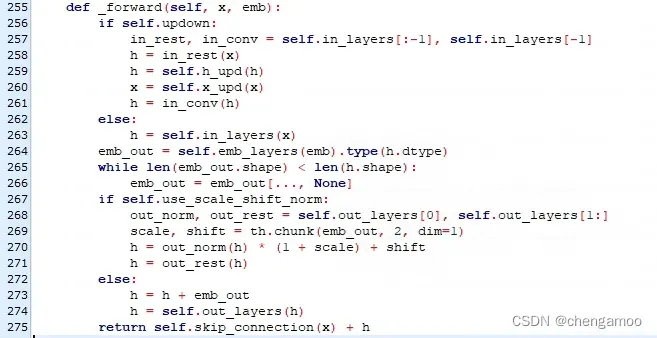
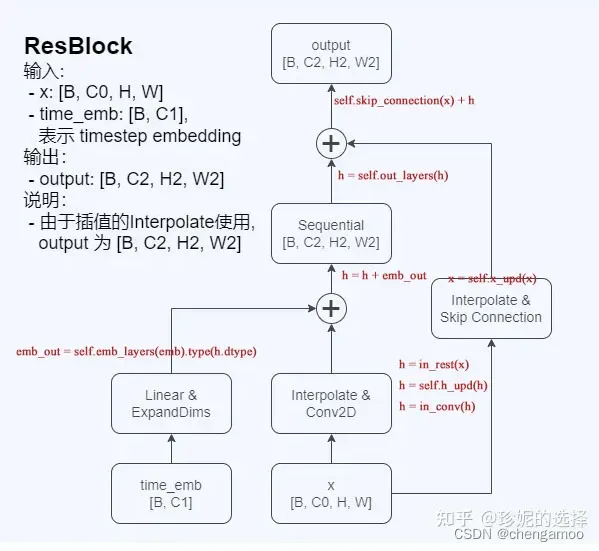
ResBlock的代码如下


SpatialTransforme在stable-diffusion/ldm/modules/attention.py中定义如下
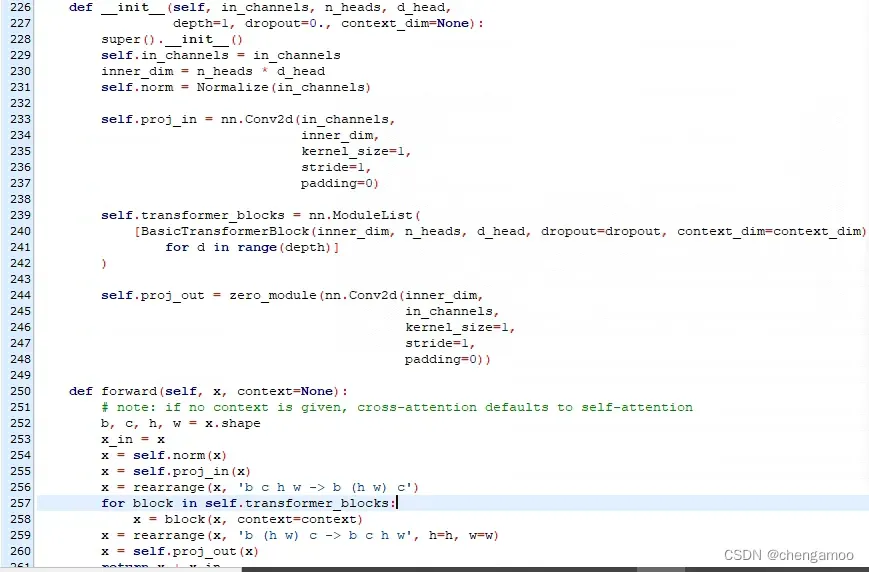

BasicTransformerBlock展示了图像和文本的融合过程
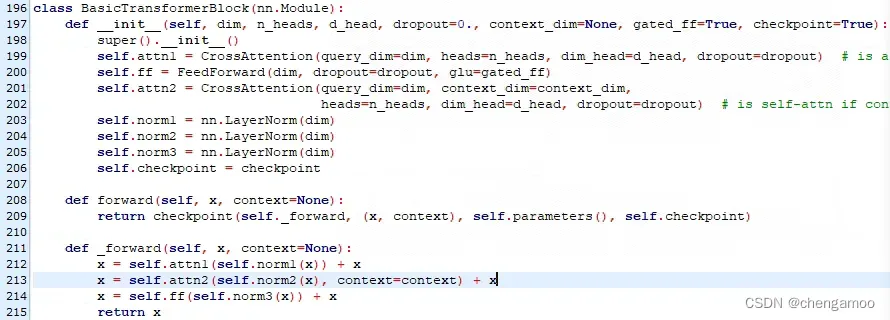

CrossAttention的定义如下,图像作为Q,文本作为K和V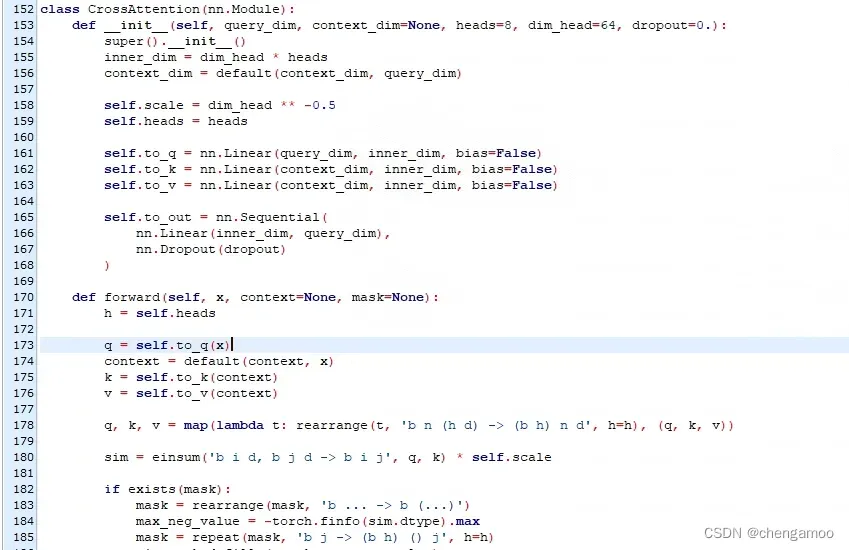

UNetModel的模型结构可参考如下Stable Diffusion 原理介绍与源码分析(一) – 知乎 (zhihu.com)
2.关于图像解码部分
得到去噪后的图像特征后进行解码
![]()

调用的是ddpm中的decode_first_stage函数 ,调用AutoencoderKL中的解码器


AutoencoderKL的解码器输出的就是最后的图像


想要了解更多扩散模型的知识,推荐这个视频54、Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读_哔哩哔哩_bilibili
文章出处登录后可见!