

实践题目:基于不同策略的英文单词的词频统计和检索系统
、实验目的
掌握基于顺序表的顺序查找、基于链表的顺序查找、折半查找)、二叉排序树和哈希表(包括基于开放地址法的哈希查找)
- 实验内容
一篇英文文章存储在一个文本文件中,然后分别基于线性表、二叉排序树和哈希表不同的存储结构,完成单词词频的统计和单词的检索功能。同时计算不同检索策略下的平均查找长度ASL,通过比较ASL的大小,对不同检索策略的时间性能做出相应的比较分
- 需求分析
首先我们需要仔细阅读实验要求文件,根据文件内容是让我们实现一个基于不同策略的英文单词的词频统计和检索系统;也就是用几种不同的方法来实现单词的词频统计和检索这两个功能;几种不同的方法分别是:线性表(包括基于顺序表的顺序查找、基于链表的顺序查找、折半查找)、二叉排序树和哈希表(包括基于开放地址法的哈希查找;第一个功能:词频统计是从一个txt文件中获取单词,然后将获取到的单词和出现的次数按一定顺序写入另一个txt文件中;第二个功能:单词检索是从各种方法存储单词的结构中查找相对应的单词,并算出查找时间和平均查找长度;功能分析图如图4.1所示:
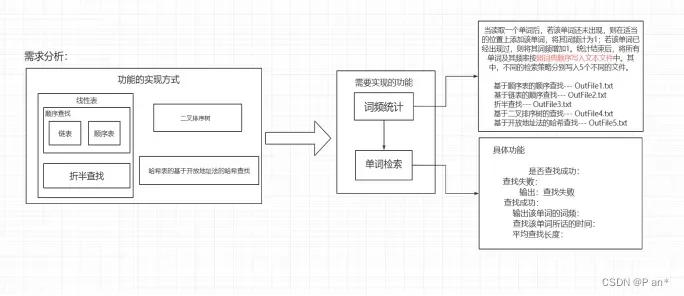

图4.1
2、技术选择:
根据需求分析,我们选择有C语言实现该系统;需要创建的结构体有:链表、顺序表、二叉树、数组实现的哈希表;各结构体定义如图4.2所示:
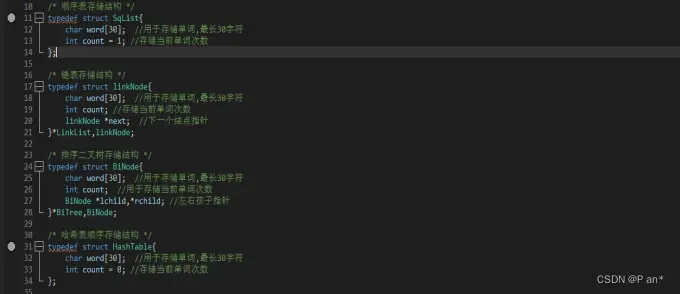

图4.2
3、函数定义:
定义了两类函数,第一类是:菜单函数(各个菜单页面的函数);第二类是:功能函数(用于功能的实现);函数的命名采用了驼峰命名法,让函数更有辨识度;函数定义如图4.3所示:
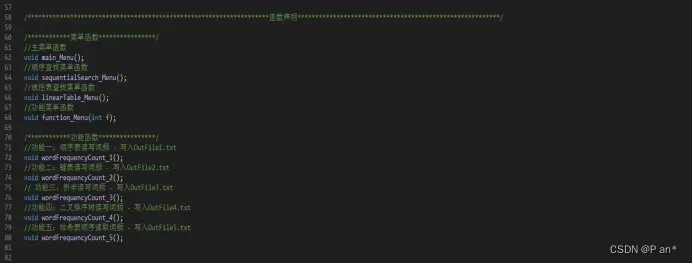

图4.3
五、实验结果截图:
(一)、核心代码分析:
1、全局变量的定义:
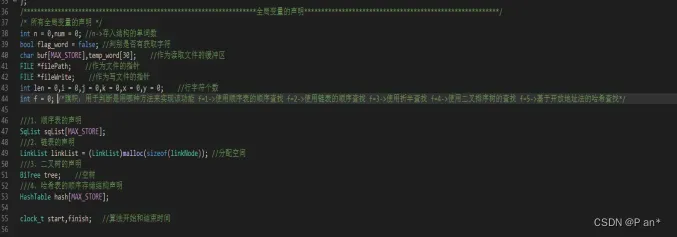

图5.1
图5.1是基于不同策略的英文单词的词频统计和检索系统的所有全局变量的定义;其中:n是用于记录存入结构的单词数;flag_word是在字符数据存入结构体时判别是否有获取到字符的;buf[MAX_STORE],temp_word[30]是作为读取文件的缓冲区;*filePath和*fileWrite分别是文件的指针和写文件的指针;f是旗帜用于判断是用哪种方法来实现该功能 f=1->使用顺序表的顺序查找 f=2->使用链表的顺序查找 f=3->使用折半查找 f=4->使用二叉排序树的查找 f=5->基于开放地址法的哈希查找;还有顺序表、链表、二叉树、哈希表数组存储结构的声明。
2、从文件获取字符:
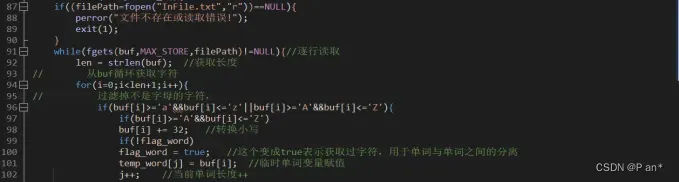

图5.2
图5.2是程序从InFile.txt文件获取单词字符的代码实现;该代码先调用了fopen函数打开了该文件,然后调用了fgets函数从文件中逐行获取字符存入buf数组中,然后通过for循环、if语句来过滤掉不是字母的字符,并且将大写的字母转成小写、然后将处理好的单词存入temp_word临时数组中,同时让flag_word变成true代表已经获取到一个单词了,j用来记录该单词有多少个字母组成。该代码在多个函数都有运用到。
3、顺序表存储单词:
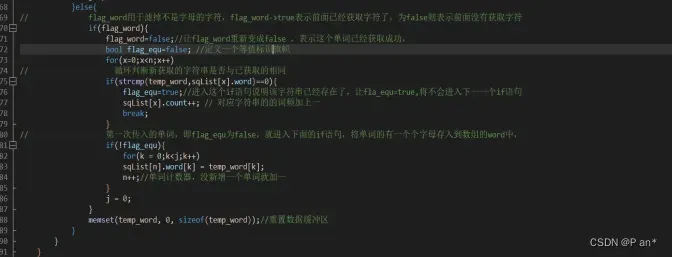

图5.3
图5.3中的代码是当程序从文件中获取到一个单词后,让flag_word为true,并且遇到非字母字符时执行图5.3中的代码,然后循环判断新获取的字符串是否与已获取的相同,如果相同则样对应的单词的频率加一,让后让flag_equ等于true,这样程序将不会单词新增代码;如果没有相同的,则会执行单词新增代码,将单词添加到顺序结构中,并且让该单词的词频等于一、还有用n对添加的单词进行计数。依次循环操作,直到将文件中的单词全部遍历存储完为止。
4.顺序表单词排序并写入文件:
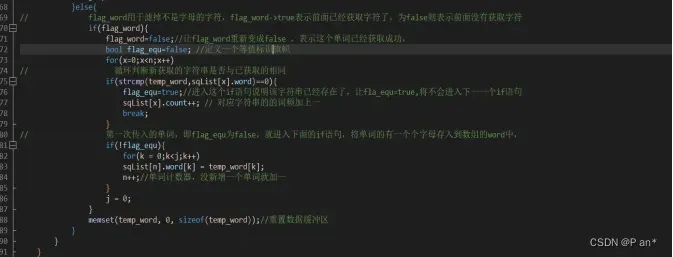
图5.4
图5.4中的代码是通过冒泡排序,还有strcmp函数对顺序表中的元素进行安首字母a-z的排序;排好序之后,调用fopen函数创建一个可写入文件,先将单词的个数写入文件,然后循环依次将排序好的顺序表中的数据写入文件中,最后关闭数据流。
5.链表存储单词:
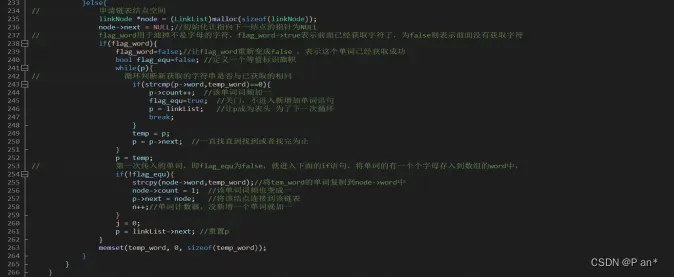

图5.5
图5.5是链表存储单词的程序代码;通过图5.2的代码获取到一个单词后就执行该程序代码,先申请链表结点空间初始化结点,然后通过旗帜flag_word实现开关门原理,也就是当程序获取到单词后,旗帜flag_word就变成true,然后就循环判断新获取的字符串是否与已获取的相同;如果有相同就在该单词的词频加一;如果没有相同就让该单词添加到新创建的结点,然后进行单词计数。依次循环进行程序就将文件中的单词种类和词频全部添加到链表结构中。
6.链表单词排序并写入文件:
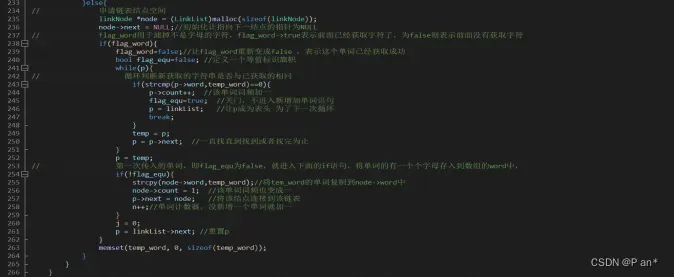
图5.6
图5.6是通冒泡排和strcmp函数将链表中的单词按首字母a-z顺序进行排序,然后通过fopen函数创建一个可写入的OutFile2.txt文件,然后先将链表中的单词数n写入文件中,接线来通过循环将这些排序好的单词写入OutFile2.txt文件中;最后关闭数据流。
7.二叉树存入单词并排序:
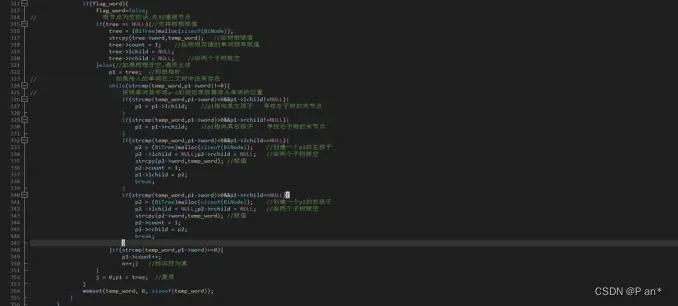

图5.7
图5.7是将图5.2代码中获取到的单词存入二叉树结构并且在存入的时候进行了单词首字母按a-z的规则进行排序;也是通过flag_word旗帜来实现文本中单词的分割;当传入第一个单词后程序先创建了一个树的根结点,并将第一个单词存入根结点,然后让单词计数器n++;并让根结点的左右子树为NULL;然后传入下一个单词的时候就与二叉树中已存入单词进行对比,如果有相同就在该单词的词频加一,如果没有相同就循环按照单词首字母a-z的规则进行寻找即将存入单词在二叉树的位置;如果在寻找位置的过程中遇到左子树或者右子树为空是,则要新建结点;找到位置后将单词存入,然后让单词计数器n++。
8.二叉树存储单词写入文件:
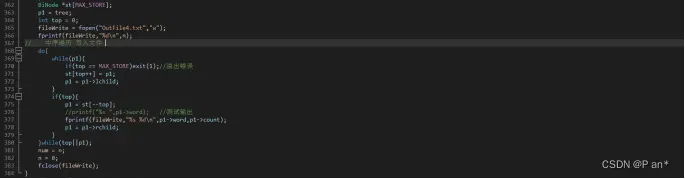

图5.8
图5.8是将二叉树中已经按照首字母a-z规则排序好的单词,以二叉树中序循环遍历的形式写入用fopen函数创建的可写入文件OutFile4.txt中;最后关闭数据流。
9.哈希表顺序结构存储单词:
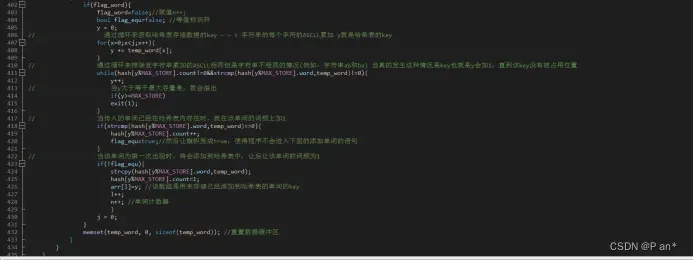

图5.9
图5.9是将图5.2中获取的单词存入哈希表顺序结构的代码实现;该代码也是通过旗帜flag_word的开闭原理来实现情况分类的;该哈希表采用单词字母的ASCLL累加所得到的值当做该单词存储的key;为了避免累加的ASCLL相同但是字符串不相同的情况(例如:字符串ab和ba),使用可一个循环来将key修改;然后数据在哈希表存储的位置采用了key%哈希数组最大容量(求余法);然后就是通过strcmp来判断即将存入的单词是否已经在哈希数组中存在了;如果已经存在就在该单词的词频加一,如果没有存入,将将该单词存入;哈希数组中每存入一个单词就将干单词的key存入到数组arr中,并且单词计数器n加一。
10.哈希表顺序结构存数据排序并写入文件:
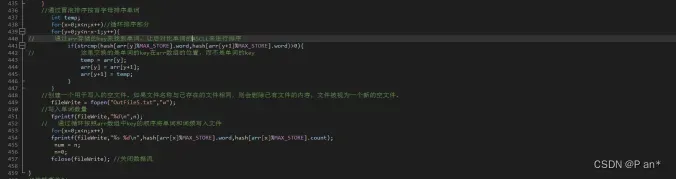

图5.10
图5.10是将哈希数组中存储的的单词进行排序,然后写入文件;排序是通过数组arr中存储key来找到哈希数组中的性对应的单词,然后通过strcmp来进行单词首字母对比,按照首字母a-z的规则对arr数组中的key的排序;然后按照arr数组中key的顺序来进行哈希数组中数据的写入文件。
11.词频统计调用方法的选择:
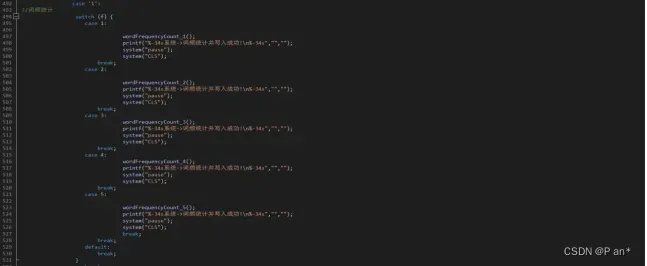

图5.11
图5.11是词频统计功能实现多方式的代码;该功能用来一个旗帜f和一个switch选择器实现;当我们在菜单选择基于顺序表的顺序查找–>旗帜f=1、基于链表的顺序查找–>旗帜f=2、基于折半查找–>旗帜f=3、基于二叉排序树的查找–>旗帜f=4、基于开放地址法的哈希查找–>旗帜f=5。然后通过f的改变在switch中调用相应的函数。
12.单词查找调用方法的选择:
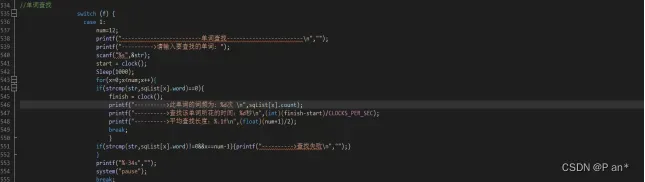

图5.12.1
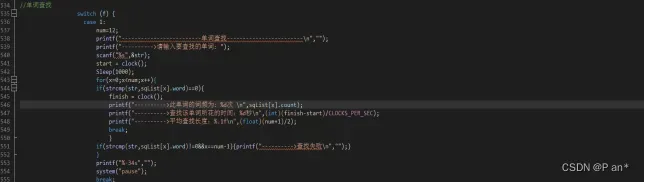
图5.12.2
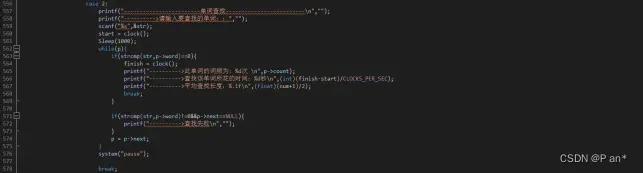

图5.12.3
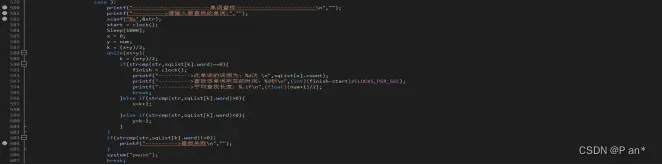

图5.12.4
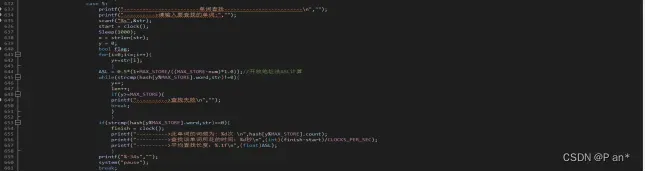

图5.12.5
图5.12.1是基于顺序表的顺序查找–>旗帜f=1、图5.12.2是基于链表的顺序查找–>旗帜f=2、图5.12.3是基于折半查找–>旗帜f=3、图5.12.4是基于二叉排序树的查找–>旗帜f=4、图5.12.5是基于开放地址法的哈希查找–>旗帜f=5;然后通过f的改变在switch中调用相应的函数。
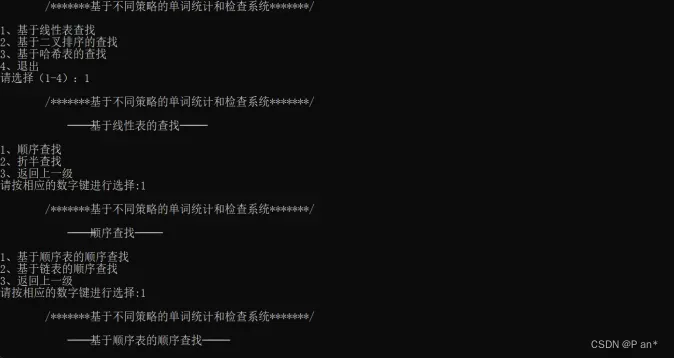
(二)、实验结果截图:
1、菜单显示:

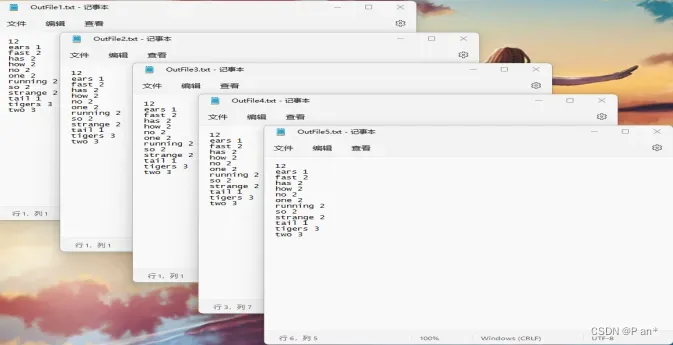
2、词频统计结果:

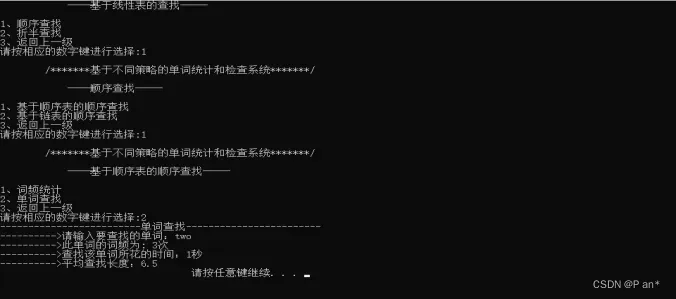
3、单词查找结果:
(1)、查找成功:

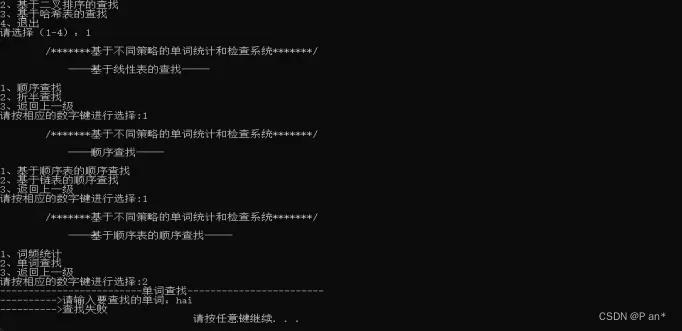
- 、查找失败:

#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include<math.h>
#include <windows.h>
#define MAX_STORE 5000
/********************************************************************结构体定义*********************************************************/
/* 顺序表存储结构 */
struct SqList{
char word[30]; //用于存储单词,最长30字符
int count = 1; //存储当前单词次数
};
/* 链表存储结构 */
typedef struct linkNode{
char word[30]; //用于存储单词,最长30字符
int count; //存储当前单词次数
linkNode *next; //下一个结点指针
}*LinkList,linkNode;
/* 排序二叉树存储结构 */
typedef struct BiNode{
char word[30]; //用于存储单词,最长30字符
int count; //用于存储当前单词次数
BiNode *lchild,*rchild; //左右孩子指针
}*BiTree,BiNode;
/* 哈希表顺序存储结构 */
struct HashTable{
char word[30]; //用于存储单词,最长30字符
int count = 0; //存储当前单词次数
};
/********************************************************************全局变量的声明*********************************************************/
/* 所有全局变量的声明 */
int n = 0,num = 0,ALS=-999; //n->存入结构的单词数
bool flag_word = false; //判别是否有获取字符
char buf[MAX_STORE],temp_word[30]; //作为读取文件的缓冲区
FILE *filePath; //作为文件的指针
FILE *fileWrite; //作为写文件的指针
int len = 0,i = 0,j = 0,k = 0,x = 0,y = 0; //行字符个数
int f = 0; /*旗帜:用于判断是用哪种方法来实现该功能 f=1->使用顺序表的顺序查找 f=2->使用链表的顺序查找 f=3->使用折半查找 f=4->使用二叉排序树的查找 f=5->基于开放地址法的哈希查找*/
///1、顺序表的声明
SqList sqList[MAX_STORE];
///2、链表的声明
LinkList linkList = (LinkList)malloc(sizeof(linkNode)); //分配空间
///3、二叉树的声明
BiTree tree; //空树
///4、哈希表的顺序存储结构声明
HashTable hash[MAX_STORE];
clock_t start,finish; //算法开始和结束时间
/********************************************************************函数声明*********************************************************/
/************菜单函数****************/
//主菜单函数
void main_Menu();
//顺序查找菜单函数
void sequentialSearch_Menu();
//线性表查找菜单函数
void linearTable_Menu();
//功能菜单函数
void function_Menu(int f);
/************功能函数****************/
//功能一:顺序表读写词频 – 写入OutFile1.txt
void wordFrequencyCount_1();
//功能二:链表读写词频 – 写入OutFile2.txt
void wordFrequencyCount_2();
// 功能三:折半读写词频 – 写入OutFile3.txt
void wordFrequencyCount_3();
//功能四:二叉排序树读写词频 – 写入OutFile4.txt
void wordFrequencyCount_4();
//功能五:哈希表顺序读取词频 – 写入OutFile5.txt
void wordFrequencyCount_5();
/*******************************************************************函数实现************************************************************/
//功能三:折半读写词频 – 写入OutFile3.txt
void wordFrequencyCount_3(){
if((filePath=fopen(“InFile.txt”,”r”))==NULL){
perror(“文件不存在或读取错误!”);
exit(1);
}
while(fgets(buf,MAX_STORE,filePath)!=NULL){//逐行读取
len = strlen(buf); //获取长度
// 从buf循环获取字符
for(i=0;i<len+1;i++){
// 过滤掉不是字母的字符,
if(buf[i]>=’a’&&buf[i]<=’z’||buf[i]>=’A’&&buf[i]<=’Z’){
if(buf[i]>=’A’&&buf[i]<=’Z’)
buf[i] += 32; //转换小写
if(!flag_word)
flag_word = true; //这个变成true表示获取过字符,用于单词与单词之间的分离
temp_word[j] = buf[i]; //临时单词变量赋值
j++; //当前单词长度++
}else{
// flag_word用于滤掉不是字母的字符,flag_word->true表示前面已经获取字符了,为false则表示前面没有获取字符
if(flag_word){
flag_word=false;//让flag_word重新变成false ,表示这个单词已经获取成功,
bool flag_equ=false; //定义一个等值标识旗帜
for(x=0;x<n;x++)
// 循环判断新获取的字符串是否与已获取的相同
if(strcmp(temp_word,sqList[x].word)==0){
flag_equ=true;//进入这个if语句说明该字符串已经存在了,让fla_equ=true,将不会进入下一一个if语句
sqList[x].count++; // 对应字符串的的词频加上一
break;
}
// 第一次传入的单词,即flag_equ为false,就进入下面的if语句,将单词的有一个个字母存入到数组的word中,
if(!flag_equ){
for(k = 0;k<j;k++)
sqList[n].word[k] = temp_word[k];
n++;//单词计数器,没新增一个单词就加一
}
j = 0;
}
memset(temp_word, 0, sizeof(temp_word));
}
}
}
//通过冒泡排序按首字母排序单词
SqList temp;
for(x=0;x<n;x++)//循环排序部分
for(y=0;y<n-x-1;y++){
if(strcmp(sqList[y].word,sqList[y+1].word)>0){
//调用strcmp来比较(比较的也是阿斯克码) sqList[y].word,sqList[y+1].word 如果返回值小于 0,则表示 str1 小于 str2。 如果返回值大于 0,则表示 str1 大于 str2。如果返回值等于 0,则表示 str1 等于 str2。
// 题目要求a-z排列,因为上面以及将所有的大写字母转换为小写,所以这里比较一次就行了
temp = sqList[y];
sqList[y] = sqList[y+1];
sqList[y+1] = temp;
}
}
//创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。
fileWrite = fopen(“OutFile3.txt”,”w”);
//写入单词数量
fprintf(fileWrite,”%d\n”,n);
// 循环将单词和词频写入
for(x=0;x<n;x++)
fprintf(fileWrite,”%s %d\n”,sqList[x].word,sqList[x].count);
num = n;
n = 0;
fclose(fileWrite);
}
//功能一:顺序表读写词频 – 写入OutFile1.txt
void wordFrequencyCount_1(){
if((filePath=fopen(“InFile.txt”,”r”))==NULL){
perror(“文件不存在或读取错误!”);
exit(1);
}
while(fgets(buf,MAX_STORE,filePath)!=NULL){//逐行读取
len = strlen(buf); //获取长度
// 从buf循环获取字符
for(i=0;i<len+1;i++){
// 过滤掉不是字母的字符,
if(buf[i]>=’a’&&buf[i]<=’z’||buf[i]>=’A’&&buf[i]<=’Z’){
if(buf[i]>=’A’&&buf[i]<=’Z’)
buf[i] += 32; //转换小写
if(!flag_word)
flag_word = true; //这个变成true表示获取过字符,用于单词与单词之间的分离
temp_word[j] = buf[i]; //临时单词变量赋值
j++; //当前单词长度++
}else{
// flag_word用于滤掉不是字母的字符,flag_word->true表示前面已经获取字符了,为false则表示前面没有获取字符
if(flag_word){
flag_word=false;//让flag_word重新变成false ,表示这个单词已经获取成功,
bool flag_equ=false; //定义一个等值标识旗帜
for(x=0;x<n;x++)
// 循环判断新获取的字符串是否与已获取的相同
if(strcmp(temp_word,sqList[x].word)==0){
flag_equ=true;//进入这个if语句说明该字符串已经存在了,让fla_equ=true,将不会进入下一一个if语句
sqList[x].count++; // 对应字符串的的词频加上一
break;
}
// 第一次传入的单词,即flag_equ为false,就进入下面的if语句,将单词的有一个个字母存入到数组的word中,
if(!flag_equ){
for(k = 0;k<j;k++)
sqList[n].word[k] = temp_word[k];
n++;//单词计数器,没新增一个单词就加一
}
j = 0;
}
memset(temp_word, 0, sizeof(temp_word));//重置数据缓冲区
}
}
}
//通过冒泡排序按首字母排序单词
SqList temp;
for(x=0;x<n;x++)//循环排序部分
for(y=0;y<n-x-1;y++){
if(strcmp(sqList[y].word,sqList[y+1].word)>0){
//调用strcmp来比较(比较的也是阿斯克码) sqList[y].word,sqList[y+1].word 如果返回值小于 0,则表示 str1 小于 str2。
// 如果返回值大于 0,则表示 str1 大于 str2。如果返回值等于 0,则表示 str1 等于 str2。
// 两个字符串 第一个字符和第一个字符比,如果ASCLL相同 则第二个和第二个相比依此类推
// 题目要求a-z排列,因为上面以及将所有的大写字母转换为小写,所以这里比较一次就行了
temp = sqList[y];
sqList[y] = sqList[y+1];
sqList[y+1] = temp;
}
}
//创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。
fileWrite = fopen(“OutFile1.txt”,”w”);
//写入单词数量
fprintf(fileWrite,”%d\n”,n);
// 循环将单词和词频写入
for(x=0;x<n;x++)
fprintf(fileWrite,”%s %d\n”,sqList[x].word,sqList[x].count);
num = n;
n = 0;
fclose(fileWrite);//关闭数据流
}
//功能二:链表读写词频 – 写入OutFile2.txt
void wordFrequencyCount_2(){
linkList->next = NULL;
linkNode *p = linkList;linkNode *temp = p;
if((filePath=fopen(“InFile.txt”,”r”))==NULL){
perror(“文件不存在或读取错误!”);
exit(1);
}
while(fgets(buf,MAX_STORE,filePath)!=NULL){//逐行读取
len = strlen(buf); //获取长度
for(i=0;i<len+1;i++){
if(buf[i]>=’a’&&buf[i]<=’z’||buf[i]>=’A’&&buf[i]<=’Z’){
if(buf[i]>=’A’&&buf[i]<=’Z’)buf[i] += 32; //转换小写
if(!flag_word)flag_word = true; //标识符转换
temp_word[j] = buf[i]; //临时单词变量赋值
j++; //当前单词长度++
}else{
// 申请链表结点空间
linkNode *node = (LinkList)malloc(sizeof(linkNode));
node->next = NULL;//初始化让指向下一结点的指针为NULL
// flag_word用于滤掉不是字母的字符,flag_word->true表示前面已经获取字符了,为false则表示前面没有获取字符
if(flag_word){
flag_word=false;//让flag_word重新变成false ,表示这个单词已经获取成功
bool flag_equ=false; //定义一个等值标识旗帜
while(p){
// 循环判断新获取的字符串是否与已获取的相同
if(strcmp(p->word,temp_word)==0){
p->count++; //该单词词频加一
flag_equ=true; //关门,不进入新增加单词语句
p = linkList; //让p成为表头 为了下一次循环
break;
}
temp = p;
p = p->next; //一直找直到找到或者找完为止
}
p = temp;
// 第一次传入的单词,即flag_equ为false,就进入下面的if语句,将单词的有一个个字母存入到数组的word中,
if(!flag_equ){
strcpy(node->word,temp_word);//将tem_word的单词复制到node->word中
node->count = 1; //该单词词频也变成一
p->next = node; //将该结点连接到该链表
n++;//单词计数器,没新增一个单词就加一
}
j = 0;
p = linkList->next; //重置p
}
memset(temp_word, 0, sizeof(temp_word));
}
}
}
//通过排序按首字母排序单词 for(表头的next;指针不为空;指向下一个) for(表头next的下一个next;指针不为空;指向下一个)
for(p=linkList->next;p!=NULL;p=p->next)
for(temp=p->next;temp!=NULL;temp=temp->next){
if(strcmp(p->word,temp->word)>0){
//调用strcmp来比较(比较的也是阿斯克码) sqList[y].word,sqList[y+1].word 如果返回值小于 0,则表示 str1 小于 str2。
// 如果返回值大于 0,则表示 str1 大于 str2。如果返回值等于 0,则表示 str1 等于 str2。
// 题目要求a-z排列,因为上面以及将所有的大写字母转换为小写,所以这里比较一次就行了
x = p->count;
strcpy(temp_word,p->word);
p->count = temp->count;
strcpy(p->word,temp->word);
temp->count = x;
strcpy(temp->word,temp_word);
}
}
memset(temp_word, 0, sizeof(temp_word));
//创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。
fileWrite = fopen(“OutFile2.txt”,”w”);
fprintf(fileWrite,”%d\n”,n);//写入单词数量
p=linkList->next;
num = n;
n = 0;
// 循环将单词和词频写入
while(p){
fprintf(fileWrite,”%s %d\n”,p->word,p->count);
p=p->next;
}
fclose(fileWrite);//关闭数据流
}
//功能四:二叉排序树读写词频 – 写入OutFile4.txt
void wordFrequencyCount_4(){
BiNode *p1,*p2; //声明两个结点指针
if((filePath=fopen(“InFile.txt”,”r”))==NULL){
perror(“文件不存在或读取错误!”);
exit(1);
}
while(fgets(buf,MAX_STORE,filePath)!=NULL){//逐行读取
len = strlen(buf); //获取长度
for(i=0;i<len+1;i++){
if(buf[i]>=’a’&&buf[i]<=’z’||buf[i]>=’A’&&buf[i]<=’Z’){
if(buf[i]>=’A’&&buf[i]<=’Z’)buf[i] += 32; //转换小写
if(!flag_word)flag_word = true; //标识符转换
temp_word[j] = buf[i]; //临时单词变量赋值
j++; //当前单词长度++
}else{
if(flag_word){
flag_word=false;
// 根节点为空的话,先创建根节点
if(tree == NULL){//先将树根赋值
tree = (BiTree)malloc(sizeof(BiNode));
strcpy(tree->word,temp_word); //给树根赋值
n++;
tree->count = 1; //给树根存储的单词频率赋值
tree->lchild = NULL;
tree->rchild = NULL; //给两个子树赋空
}else{//如果树根非空,遍历主体
p1 = tree; //树根指针
// 如果传入的单词在二叉树中没有存在
while(strcmp(temp_word,p1->word)!=0){
// 按照单词首字母a-z的规则寻找需存入单词的位置
if(strcmp(temp_word,p1->word)<0&&p1->lchild!=NULL){
p1 = p1->lchild; //p1指向其左孩子 寻找左子树的末节点
}
if(strcmp(temp_word,p1->word)>0&&p1->rchild!=NULL){
p1 = p1->rchild; //p1指向其右孩子 寻找右子树的末节点
}
if(strcmp(temp_word,p1->word)<0&&p1->lchild==NULL){
p2 = (BiTree)malloc(sizeof(BiNode)); //创建一个p1的左孩子
p2 ->lchild = NULL;p2->rchild = NULL; //给两个子树赋空
strcpy(p2->word,temp_word); //赋值
n++;
p2->count = 1;
p1->lchild = p2;
break;
}
if(strcmp(temp_word,p1->word)>0&&p1->rchild==NULL){
p2 = (BiTree)malloc(sizeof(BiNode)); //创建一个p1的右孩子
p2 ->lchild = NULL;p2->rchild = NULL; //给两个子树赋空
strcpy(p2->word,temp_word); //赋值
n++;
p2->count = 1;
p1->rchild = p2;
break;
}
}if(strcmp(temp_word,p1->word)==0){
p1->count++;
} //标识符为真
}
j = 0;p1 = tree; //复原
}
memset(temp_word, 0, sizeof(temp_word));
}
}
}
BiNode *st[MAX_STORE];
p1 = tree;
int top = 0;
fileWrite = fopen(“OutFile4.txt”,”w”);
fprintf(fileWrite,”%d\n”,n);
// 中序遍历 写入文件
do{
while(p1){
if(top == MAX_STORE)exit(1);//溢出错误
st[top++] = p1;
p1 = p1->lchild;
}
if(top){
p1 = st[–top];
//printf(“%s “,p1->word); //测试输出
fprintf(fileWrite,”%s %d\n”,p1->word,p1->count);
p1 = p1->rchild;
}
}while(top||p1);
num = n;
n = 0;
fclose(fileWrite);
}
//功能五:哈希表顺序读取词频 – 写入OutFile5.txt
void wordFrequencyCount_5(){
int arr[30];
int l=0;
if((filePath=fopen(“InFile.txt”,”r”))==NULL){
perror(“文件不存在或读取错误!”);
exit(1);
}
while(fgets(buf,MAX_STORE,filePath)!=NULL){//逐行读取
len = strlen(buf); //获取长度
for(i=0;i<len+1;i++){
if(buf[i]>=’a’&&buf[i]<=’z’||buf[i]>=’A’&&buf[i]<=’Z’){
if(buf[i]>=’A’&&buf[i]<=’Z’)buf[i] += 32; //转换小写
if(!flag_word)flag_word = true; //标识符转换
temp_word[j] = buf[i]; //临时单词变量赋值
j++; //当前单词长度++
}else{
if(flag_word){
flag_word=false;//赋值n++;
bool flag_equ=false; //等值标识符
y = 0;
// 通过循环来获取哈希表存储数据的key ——> 字符串的每个字符的ASCLL累加 y就是哈希表的key
for(x=0;x<j;x++){
y += temp_word[x];
}
// 通过循环来排除党字符串累加的ASCLL相同但是字符串不相同的情况(例如:字符串ab和ba) 当真的发生这种情况是key也就是y会加1,直到该key没有被占用位置
while(hash[y%MAX_STORE].count!=0&&strcmp(hash[y%MAX_STORE].word,temp_word)!=0){
y++;
// 当y大于等于最大容量是,就会溢出
if(y>=MAX_STORE)
exit(1);
}
// 当传入的单词已经在哈希表内存在时,就在该单词的词频上加1
if(strcmp(hash[y%MAX_STORE].word,temp_word)==0){
hash[y%MAX_STORE].count++;
flag_equ=true;//然后让旗帜变成true,使得程序不会进入下面的添加单词的语句
}
// 当该单词为第一次出现时,将会添加到哈希表中,让后让该单词的词频为1
if(!flag_equ){
strcpy(hash[y%MAX_STORE].word,temp_word);
hash[y%MAX_STORE].count=1;
arr[l]=y; //该数组是用来存储已经添加到哈希表的单词的key
l++;
n++; //单词计数器
}
j = 0;
}
memset(temp_word, 0, sizeof(temp_word)); //重置数据缓冲区
}
}
}
//通过冒泡排序按首字母排序单词
int temp;
for(x=0;x<n;x++)//循环排序部分
for(y=0;y<n-x-1;y++){
// 通过arr存储的key来找到单词,让后对比单词的ASCLL来进行排序
if(strcmp(hash[arr[y]%MAX_STORE].word,hash[arr[y+1]%MAX_STORE].word)>0){
// 这里交换的是单词的key在arr数组的位置,而不是单词的key
temp = arr[y];
arr[y] = arr[y+1];
arr[y+1] = temp;
}
}
//创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。
fileWrite = fopen(“OutFile5.txt”,”w”);
//写入单词数量
fprintf(fileWrite,”%d\n”,n);
// 通过循环按照arr数组中key的顺序将单词和词频写入文件
for(x=0;x<n;x++)
fprintf(fileWrite,”%s %d\n”,hash[arr[x]%MAX_STORE].word,hash[arr[x]%MAX_STORE].count);
num = n;
n=0;
fclose(fileWrite); //关闭数据流
}
/*功能菜单*/
void function_Menu(int f){
linkNode *p = linkList->next;
// HashNode *q;
BiNode *p1,*p2; //声明两个结点指针
float ASL = 0; //散列表专用的ASl – Σ( ̄。 ̄ノ)
char str[30]; //用户查找的单词
printf(“\n”);
printf(“\t/*******基于不同策略的单词统计和检查系统*******/\n”);
printf(“\n”);
if(f==1){
printf(“\t ────基于顺序表的顺序查找──── \n”);
} else if(f==2){
printf(“\t ────基于链表的顺序查找──── \n”);
} else if(f==3){
printf(“\t ────基于折半查找──── \n”);
}else if(f==4){
printf(“\t ────基于二叉排序树的查找──── \n”);
}else{
printf(“\t ────基于开放地址法的哈希查找──── \n”);
}
printf(“\n”);
printf(“1、词频统计 \n”);
printf(“2、单词查找 \n”);
printf(“3、返回上一级 \n”);
printf(“请按相应的数字键进行选择:”);
getchar();
char choose = getchar();
switch (choose)
{
case ‘1’:
//词频统计
switch (f) {
case 1:
wordFrequencyCount_1();
printf(“%-34s系统->词频统计并写入成功!\n%-34s”,””,””);
system(“pause”);
system(“CLS”);
break;
case 2:
wordFrequencyCount_2();
printf(“%-34s系统->词频统计并写入成功!\n%-34s”,””,””);
system(“pause”);
system(“CLS”);
break;
case 3:
wordFrequencyCount_3();
printf(“%-34s系统->词频统计并写入成功!\n%-34s”,””,””);
system(“pause”);
system(“CLS”);
break;
case 4:
wordFrequencyCount_4();
printf(“%-34s系统->词频统计并写入成功!\n%-34s”,””,””);
system(“pause”);
system(“CLS”);
break;
case 5:
wordFrequencyCount_5();
printf(“%-34s系统->词频统计并写入成功!\n%-34s”,””,””);
system(“pause”);
system(“CLS”);
break;
break;
default:
break;
}
break;
case ‘2’:
//单词查找
switch (f) {
case 1:
num=12;
printf(“————————-单词查找————————\n”,””);
printf(“———->请输入要查找的单词:”);
scanf(“%s”,&str);
start = clock();
Sleep(1000);
for(x=0;x<num;x++){
if(strcmp(str,sqList[x].word)==0){
finish = clock();
printf(“———->此单词的词频为: %d次 \n”,sqList[x].count);
printf(“———->查找该单词所花的时间:%d秒\n”,(int)(finish-start)/CLOCKS_PER_SEC);
printf(“———->平均查找长度:%.1f\n”,(float)(num+1)/2);
break;
}
if(strcmp(str,sqList[x].word)!=0&&x==num-1){printf(“———->查找失败\n”,””);}
}
printf(“%-34s”,””);
system(“pause”);
break;
case 2:
printf(“————————单词查找————————-\n”,””);
printf(“———->请输入要查找的单词::”,””);
scanf(“%s”,&str);
start = clock();
Sleep(1000);
while(p){
if(strcmp(str,p->word)==0){
finish = clock();
printf(“———->此单词的词频为: %d次 \n”,p->count);
printf(“———->查找该单词所花的时间:%d秒\n”,(int)(finish-start)/CLOCKS_PER_SEC);
printf(“———->平均查找长度:%.1f\n”,(float)(num+1)/2);
break;
}
if(strcmp(str,p->word)!=0&&p->next==NULL){
printf(“———->查找失败\n”,””);
}
p = p->next;
}
system(“pause”);
break;
case 3:
printf(“————————单词查找————————-\n”,””);
printf(“———->请输入要查找的单词:”,””);
scanf(“%s”,&str);
start = clock();
Sleep(1000);
x = 0;
y = num;
k = (x+y)/2;
while(x<=y){
k = (x+y)/2;
if(strcmp(str,sqList[k].word)==0){
finish = clock();
printf(“———->此单词的词频为: %d次 \n”,sqList[x].count);
printf(“———->查找该单词所花的时间:%d秒\n”,(int)(finish-start)/CLOCKS_PER_SEC);
printf(“———->平均查找长度:%.1f\n”,(float)(num+1)/2);
break;
}else if(strcmp(str,sqList[k].word)>0){
x=k+1;
}else if(strcmp(str,sqList[k].word)<0){
y=k-1;
}
}
if(strcmp(str,sqList[k].word)!=0){
printf(“———->查找失败\n”,””);
}
system(“pause”);
break;
case 4:
printf(“————————单词查找————————-\n”,””);
printf(“———->请输入要查找的单词:”,””);
scanf(“%s”,&str);
start = clock();
Sleep(1000);
p1 = tree;
while(strcmp(str,p1->word)!=0&&p1){
if(strcmp(str,p1->word)>0){p1 = p1->rchild;}
if(strcmp(str,p1->word)<0){
p1 = p1->lchild;
}
}
if(strcmp(str,p1->word)==0){
finish = clock();
printf(“———->此单词的词频为: %d次 \n”,p1->count);
printf(“———->查找该单词所花的时间:%d秒\n”,(int)(finish-start)/CLOCKS_PER_SEC);
printf(“———->平均查找长度:%.1f\n”,(float)log(num+1)/log(2));
}
if(strcmp(str,p1->word)!=0){
printf(“———->查找失败\n”,””);
}
system(“pause”);
break;
case 5:
printf(“————————单词查找————————-\n”,””);
printf(“———->请输入要查找的单词:”,””);
scanf(“%s”,&str);
start = clock();
Sleep(1000);
x = strlen(str);
y = 0;
bool flag;
for(i=0;i<x;i++){
y+=str[i];
}
ASL = 0.5*(1+MAX_STORE/((MAX_STORE-num)*1.0));//开放地址法ASL计算
while(strcmp(hash[y%MAX_STORE].word,str)!=0){
y++;
len++;
if(y>=MAX_STORE){
printf(“———->查找失败\n”,””);
break;
}
}
if(strcmp(hash[y%MAX_STORE].word,str)==0){
finish = clock();
printf(“———->此单词的词频为: %d次 \n”,hash[y%MAX_STORE].count);
printf(“———->查找该单词所花的时间:%d秒\n”,(int)(finish-start)/CLOCKS_PER_SEC);
printf(“———->平均查找长度:%.1f\n”,(float)ASL);
}
printf(“%-34s”,””);
system(“pause”);
break;
default:
break;
}
break;
case ‘3’:
if(f==1||f==2){
sequentialSearch_Menu();
}else if(f==3){
linearTable_Menu();
}else{
break;
}
default:
break;
}
system(“CLS”);
main_Menu();
}
/*顺序查找菜单*/
void sequentialSearch_Menu(){
printf(“\n”);
printf(“\t/*******基于不同策略的单词统计和检查系统*******/\n”);
printf(“\n”);
printf(“\t ────顺序查找──── \n”);
printf(“\n”);
printf(“1、基于顺序表的顺序查找 \n”);
printf(“2、基于链表的顺序查找 \n”);
printf(“3、返回上一级 \n”);
printf(“请按相应的数字键进行选择:”);
getchar();
char choose = getchar();
switch (choose)
{
case ‘1’:
f=1;
function_Menu(f);
break;
case ‘2’:
f=2;
function_Menu(f);
break;
case ‘3’:
linearTable_Menu();
default:
printf(“输入错误请重新输入:”);
sequentialSearch_Menu();
break;
}
system(“CLS”);
main_Menu();
}
/*线性表查找菜单*/
void linearTable_Menu(){
printf(“\n”);
printf(“\t/*******基于不同策略的单词统计和检查系统*******/\n”);
printf(“\n”);
printf(“\t ────基于线性表的查找──── \n”);
printf(“\n”);
printf(“1、顺序查找 \n”);
printf(“2、折半查找 \n”);
printf(“3、返回上一级 \n”);
printf(“请按相应的数字键进行选择:”);
getchar();
char choose = getchar();
switch (choose)
{
case ‘1’:
sequentialSearch_Menu();
break;
case ‘2’:
f=3;
function_Menu(f);
break;
case ‘3’:
break;
default:
break;
}
system(“CLS”);
main_Menu();
}
//系统界面
void main_Menu(){
int choice = -999; //用户的选择
printf(“\t/*******基于不同策略的单词统计和检查系统*******/\n”);
printf(“\t \n”);
printf(“1、基于线性表查找 \n”);
printf(“2、基于二叉排序的查找 \n”);
printf(“3、基于哈希表的查找 \n”);
printf(“4、退出 \n”);
printf(“请选择(1-4):”);
scanf(“%d”,&choice);
switch(choice){
case 1:
linearTable_Menu();
break;
case 2:
f=4;
function_Menu(f);
break;
case 3:
f=5;
function_Menu(f);
break;
case 4:
printf(“%-34s系统->退出成功,欢迎下次使用!\n”,””);
exit(0);
default:
printf(“%-34s系统->输入有误!\n”,””);system(“pause”);
break;
}
}
int main()
{
main_Menu();
return 0;
}
文章出处登录后可见!